Produced by Big Data Digest
After the explosive popularity of ChatGPT, the AI community has entered a “hundred model battle.” Recently, Nathan Lambert, a machine learning scientist at Huggingface, organized the current strengths of large models from an open-source perspective in a blog post, offering many profound insights.
What this looks like is instead of taking the giant scorecard that GPT4 was touted on, you take 10-50% as the targets for an open-source model and beat GPT4.
Open-source models should not aim to surpass GPT4 in all aspects, but rather focus on gaining an advantage in specific areas (accounting for 10-50% of total metrics).
As for the reasons, he mentioned that language models have great diversity in reasoning ability, predictive ability, and control level. Merely “aiming” to reproduce ChatGPT may just be a cultural goal and is not necessary.
Additionally, he noted that OpenAI’s success has an element of luck, which the open-source community may not be able to replicate.
The following is a Chinese translation, with modifications made by the digest team without changing the original meaning.
Before the release of ChatGPT, everyone thought that language models were merely research projects for scholars, with very rough usability and cost scalability, resulting in models being difficult to use and deploy. After the release of ChatGPT, suddenly, everyone expected that the language models “waiting in the lab” could perform as excellently as ChatGPT. In reality, this expectation is unrealistic; language models exhibit great diversity in reasoning ability, predictive ability, and control level, and we are currently in a preliminary exploration stage. Therefore, reproducing ChatGPT is more of a cultural goal and is not necessary.
Next, the open-source community may develop large language models (LLMs) with more specific functionalities for specific needs, but these models may not match GPT4 in overall capabilities. Open-source models will not attempt to surpass GPT4 in all aspects but will focus on gaining advantages in specific areas (accounting for 10-50% of total metrics). In other metrics, open-source models may lag behind rather than match GPT4. The differences manifest in several aspects:
Different Models and Data Starting Points: When ChatGPT became a hot topic, GPT-3 was not yet open-source. Now, the standards for data have improved significantly, along with RLHF (Reinforcement Learning from Human Feedback), which is a proven technical implementation.
In the development process of foundational models, the key is to use data and infrastructure to create smaller foundational models, then fine-tune parameters to improve performance in a specific small domain. Then, the final large model is trained. Clearly, the current models and infrastructure are leading a series of experimental paths that are different from OpenAI’s a few years ago.
Different Datasets and Evaluations: Currently, the progress of many open-source projects depends on GPT4’s evaluation of models. However, it is evident that OpenAI did not evaluate based on the actual performance of the language models it was developing when making internal decisions, leading to different evaluation methods and styles. Thanks to different datasets and evaluation methods, open-source teams can receive feedback on their models faster, reducing the waiting time between model completion and release.
Different Teams: It is said that the team structures at OpenAI and Google are very modular, with each small team responsible for a part of the model. This leads to the historical development of GPT models along a very narrow path, with each team continuously iterating and optimizing their part. In contrast, in the open-source field, many small teams are experimenting and replicating various different ideas, making it easier to discern “which methods are reliable and effective and which are just lucky successes.” To be honest, OpenAI’s success has an element of luck that may not be replicable by the open-source community.
Therefore, under the above viewpoints, the scarcity of foundational models may create more innovative space for the open-source community, while companies may achieve stable progress by continuously optimizing existing models. Clearly, the development path of the LLaMA project has validated this trend.
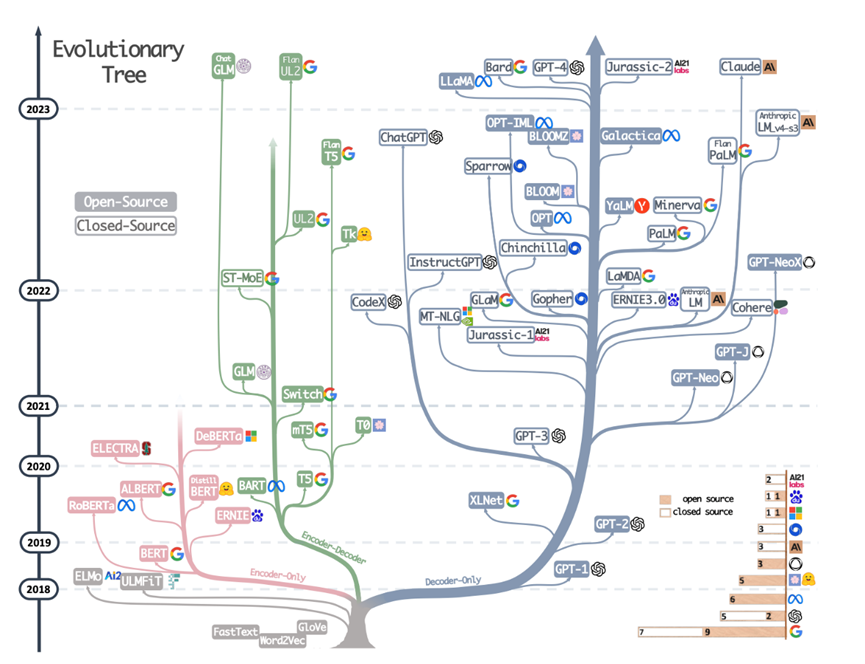 Caption: The evolution tree of large language models: models on the same branch have a closer relationship. Transformer-based models are displayed in non-gray: decoder-only models in the blue branch, encoder-only models in the pink branch, and encoder-decoder models in the green branch. The vertical position of the models on the timeline indicates their release dates. Open-source models are represented by solid squares, while closed-source models are represented by hollow squares. The stacked bar chart in the lower right corner shows the number of models from various companies and institutions.
Although we hope to reproduce models like ChatGPT, we should accept the gaps. Even companies investing tens of millions of dollars in computing power may experience 2-4 times differences in actual computing capabilities (such as AWS GPU or TPU) in their training throughput.
OpenAI and Google have already addressed these issues. Because they generate tremendous synergy when optimizing each link of the entire tech stack. It is precisely this presence of synergy that makes it difficult for us to reach the technological level of large companies like OpenAI and Google in a short period.
In the current environment, several different types of participants will influence the competitive direction of large language model development in the coming months. We are currently in a resource-rich era, so how these participants view success actually depends on their relative gaps with other participants in the industry. The most interesting comparisons among these participants are: a) how they train models, b) how they use these models, c) who is using these models.
1. Vertical Technology Companies: These are the pioneers of the large language model movement, such as OpenAI, who train models themselves and utilize these results. However, apart from text output, it seems that everything else is “kept secret.” This is a relatively monotonous and innovation-lacking development path.
2. Horizontal Large Technology Companies: These companies use models for internal services, but the inference process can occur in a distributed environment, such as users generating videos on edge devices. These companies hope that the open-source model will be widely disseminated and integrate the optimizations of popular systems into their ecosystems. I expect that Meta will continue to open machine learning models, but due to their limitations in information dissemination, their iteration speed will not be as fast as that of fully open open-source projects.
3. Open Source Forces: Many people participate in training models, and even more people use these models for various commercial and non-commercial tasks. Due to higher update frequency (rapid development, with more independent teams involved), the open-source field is likely to continue to be the core driving force behind the development of large language models.
4. Academia: In academia, researchers may focus on developing new methods to achieve more results or improve performance limits from fewer resources.
Among the last three groups (horizontal large tech companies, open-source field, and academia), they will share and integrate technological achievements with each other, making the development paths appear intertwined at the initial stage.
Of course, some companies have overlaps or blurred areas between these categories, often exhibiting characteristics of the different groups mentioned above.
Before discussing projects like Vicuna and Koala, which are academic and have made significant progress, we should recognize that these achievements are largely driven by the rapidly changing environment rather than just continuous contributions from the core academic community. The vast majority of scholars will focus on showcasing results in areas like the latest human feedback or fine-tuning techniques rather than regularly releasing top models.
Digest Note: Vicuna and Koala are both open-source large models based on the LLaMA model.
Currently, we are transitioning from instruction fine-tuning (IFT) to fully human feedback-based reinforcement learning (RLHF) for open models. Clearly, in the future, not all organizations that successfully apply RLHF will be able to release models with strong instruction/chat tuning capabilities.
To be honest, at this stage, I find it somewhat unclear regarding the current academic community. Before the product phase of large language models, the development of AI research was relatively stable.
There are rumors that before the emergence of ChatGPT, research in natural language processing (NLP) had gradually declined, with only fine-tuning work on GPT-3 remaining. The current attention and research boom regarding large language models is not a new phenomenon; this enthusiasm has merely accelerated the process of NLP research gradually focusing on areas like large language model fine-tuning.
After large language models became a research hotspot, collaborative research between academia and industry may still continue in previous ways. However, for researchers who are not involved in these special collaborations (who actually make up the majority), they may choose different research approaches.
In other words, the work of independent academic researchers is likely to largely indicate the trends of development in this field.
Although the academic system has many flaws, it does indeed regularly produce insights. Now, with the growth of the field in industrial and open-source competition, people will begin to explore how to conduct large language model research beyond merely fine-tuning the OpenAI API. However, new research incentives (such as substantial AI safety funding for LLM research) will take time to yield results.
Decreasing Reproduction Hype
I have been trying to find more reasons to support open-source language models and research, rather than just sticking to “we have always done it this way” and “accountability,” as companies will quickly compromise on these two points.
The counterfactual analysis I would like to conduct is: would the release of ChatGPT and GPT-4 along with complete technical papers diffuse the currently prevalent hype in society? When the process becomes opaque, it becomes easier for companies and opinion leaders to manipulate emotion-based rather than reality-based dissemination trends.
Openness and reproducibility have become increasingly rare topics, and I hope more teams are willing to openly share the progress of large language models so that our societal discourse can be more fact-based.
https://www.interconnects.ai/p/llm-development-paths
People who click “View” have all become more attractive!
Caption: The evolution tree of large language models: models on the same branch have a closer relationship. Transformer-based models are displayed in non-gray: decoder-only models in the blue branch, encoder-only models in the pink branch, and encoder-decoder models in the green branch. The vertical position of the models on the timeline indicates their release dates. Open-source models are represented by solid squares, while closed-source models are represented by hollow squares. The stacked bar chart in the lower right corner shows the number of models from various companies and institutions.
Although we hope to reproduce models like ChatGPT, we should accept the gaps. Even companies investing tens of millions of dollars in computing power may experience 2-4 times differences in actual computing capabilities (such as AWS GPU or TPU) in their training throughput.
OpenAI and Google have already addressed these issues. Because they generate tremendous synergy when optimizing each link of the entire tech stack. It is precisely this presence of synergy that makes it difficult for us to reach the technological level of large companies like OpenAI and Google in a short period.
In the current environment, several different types of participants will influence the competitive direction of large language model development in the coming months. We are currently in a resource-rich era, so how these participants view success actually depends on their relative gaps with other participants in the industry. The most interesting comparisons among these participants are: a) how they train models, b) how they use these models, c) who is using these models.
1. Vertical Technology Companies: These are the pioneers of the large language model movement, such as OpenAI, who train models themselves and utilize these results. However, apart from text output, it seems that everything else is “kept secret.” This is a relatively monotonous and innovation-lacking development path.
2. Horizontal Large Technology Companies: These companies use models for internal services, but the inference process can occur in a distributed environment, such as users generating videos on edge devices. These companies hope that the open-source model will be widely disseminated and integrate the optimizations of popular systems into their ecosystems. I expect that Meta will continue to open machine learning models, but due to their limitations in information dissemination, their iteration speed will not be as fast as that of fully open open-source projects.
3. Open Source Forces: Many people participate in training models, and even more people use these models for various commercial and non-commercial tasks. Due to higher update frequency (rapid development, with more independent teams involved), the open-source field is likely to continue to be the core driving force behind the development of large language models.
4. Academia: In academia, researchers may focus on developing new methods to achieve more results or improve performance limits from fewer resources.
Among the last three groups (horizontal large tech companies, open-source field, and academia), they will share and integrate technological achievements with each other, making the development paths appear intertwined at the initial stage.
Of course, some companies have overlaps or blurred areas between these categories, often exhibiting characteristics of the different groups mentioned above.
Before discussing projects like Vicuna and Koala, which are academic and have made significant progress, we should recognize that these achievements are largely driven by the rapidly changing environment rather than just continuous contributions from the core academic community. The vast majority of scholars will focus on showcasing results in areas like the latest human feedback or fine-tuning techniques rather than regularly releasing top models.
Digest Note: Vicuna and Koala are both open-source large models based on the LLaMA model.
Currently, we are transitioning from instruction fine-tuning (IFT) to fully human feedback-based reinforcement learning (RLHF) for open models. Clearly, in the future, not all organizations that successfully apply RLHF will be able to release models with strong instruction/chat tuning capabilities.
To be honest, at this stage, I find it somewhat unclear regarding the current academic community. Before the product phase of large language models, the development of AI research was relatively stable.
There are rumors that before the emergence of ChatGPT, research in natural language processing (NLP) had gradually declined, with only fine-tuning work on GPT-3 remaining. The current attention and research boom regarding large language models is not a new phenomenon; this enthusiasm has merely accelerated the process of NLP research gradually focusing on areas like large language model fine-tuning.
After large language models became a research hotspot, collaborative research between academia and industry may still continue in previous ways. However, for researchers who are not involved in these special collaborations (who actually make up the majority), they may choose different research approaches.
In other words, the work of independent academic researchers is likely to largely indicate the trends of development in this field.
Although the academic system has many flaws, it does indeed regularly produce insights. Now, with the growth of the field in industrial and open-source competition, people will begin to explore how to conduct large language model research beyond merely fine-tuning the OpenAI API. However, new research incentives (such as substantial AI safety funding for LLM research) will take time to yield results.
Decreasing Reproduction Hype
I have been trying to find more reasons to support open-source language models and research, rather than just sticking to “we have always done it this way” and “accountability,” as companies will quickly compromise on these two points.
The counterfactual analysis I would like to conduct is: would the release of ChatGPT and GPT-4 along with complete technical papers diffuse the currently prevalent hype in society? When the process becomes opaque, it becomes easier for companies and opinion leaders to manipulate emotion-based rather than reality-based dissemination trends.
Openness and reproducibility have become increasingly rare topics, and I hope more teams are willing to openly share the progress of large language models so that our societal discourse can be more fact-based.
https://www.interconnects.ai/p/llm-development-paths
People who click “View” have all become more attractive!




