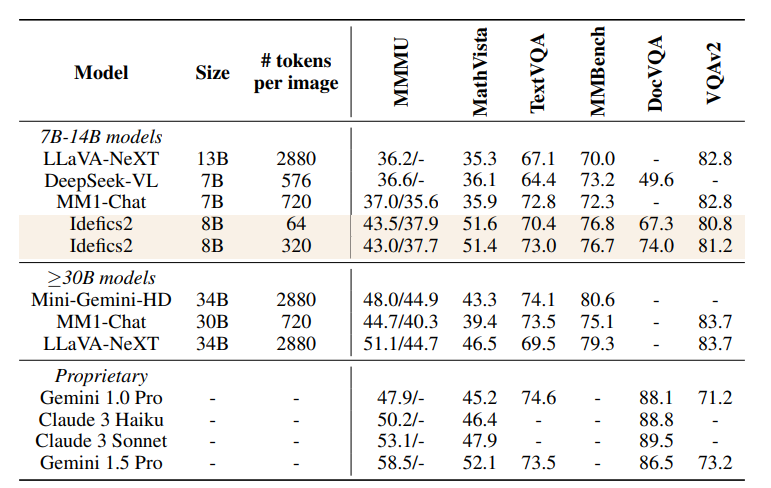
MLNLP community is a well-known machine learning and natural language processing community, covering domestic and international NLP master’s and doctoral students, university teachers, and corporate researchers.Community Vision is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for the progress of beginners.Reprinted from | 夕小瑶科技说Author | 谢年年There are many effective tricks when constructing multimodal large models, such as using cross-attention mechanisms to integrate image information into language models, or directly combining the image hidden state sequences with the text embedding sequences as inputs to the language model.However, the reasons why these tricks are effective and their computational efficiency are often explained very roughly or lack sufficient experimental verification.The Hugging Face team recently conducted extensive experiments to verify which tricks are truly effective in building multimodal large models, leading to a series of highly valuable conclusions that even overturn commonly used views in previous literature.Based on these validated effective tricks, the team open-sourced an 8B parameter visual model—Idefics2, which is the best-performing model of its size, outperforming models four times its size on certain benchmark tests, comparable to the closed-source model Gemini 1.5 Pro.In addition, Idefics2 has also undergone specialized dialogue training, performing exceptionally well during user interactions.For example, analyzing the data in the table and performing correct calculations:
Finding the required information in a resume and organizing it in JSON format:Interpreting memes also looks decent:
This meme depicts a young girl in a yellow raincoat, seemingly walking through a grassy area. She is holding a yellow object, possibly a toy or a device. The background of the photo is a green field with trees in the distance. The text on the meme reads, ‘I finished work the day before my vacation.’ This indicates that the girl is excitedly leaving work early before the holiday starts, symbolizing her joy as she runs happily through the field. The girl’s energetic pose combined with the concept of ‘work’ creates a relaxed and relatable scene for viewers who may also be looking forward to a vacation.
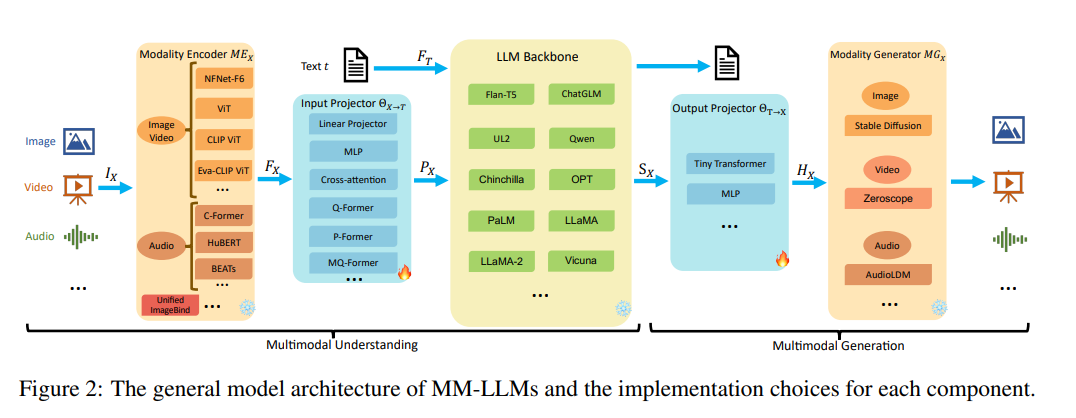
First, let’s briefly understand the components of multimodal large models.Generally, the training of the entire multimodal large model can be divided into two steps: multimodal understanding and multimodal generation, as shown in the figure below. Multimodal understanding includes three parts: multimodal encoder, input projection, and the backbone of the large model, while multimodal generation includes output projection and multimodal generator. Typically, during the training process, the parameters of the multimodal encoder, generator, and large model remain fixed and are not used for training; the main focus of optimization will be on the input and output projections.▲ Source: “MM-LLMs: Recent Advances in MultiModal Large Language Models”This article mainly focuses on the multimodal understanding capability, thus emphasizing the multimodal encoder and input projection parts.
Are Common Tricks in Building Multimodal Large Models Really Effective?
The Impact of Modal Encoders on Performance
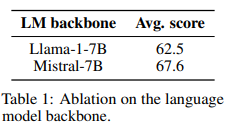
Multimodal large models use pre-trained modal encoders to extract features from visual inputs and use the language model backbone to extract features from text inputs. So what is the impact of choosing different visual and text models on the final performance?The author fixed the size of the pre-trained modules, the data used for multimodal pre-training, and the number of training updates. Under the cross-attention architecture, as the model upgrades, its performance significantly improves in visual-language benchmark testing.As shown in Table 1, replacing the language model LLaMA-1-7B with Mistral-7B improved performance by 5.1 percentage points.
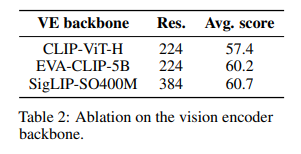
Additionally, switching the visual encoder from CLIP-ViT-H to SigLIP-SO400M improved performance by 3.3 percentage points in benchmark testing, as shown in Table 2:
Conclusion: For fixed parameters, the quality of the language model backbone has a greater impact on the final VLM performance than the visual model backbone.
Which is Better: Fully Autoregressive Architecture or Cross-Attention Architecture?
The purpose of input projection is to connect the pre-trained visual and language modules, aligning visual and text inputs. There are two mainstream methods:
Cross-Attention: Encoding the image through the visual module and injecting the image embeddings and text embeddings into different layers of the language model through cross-attention blocks.
Fully Autoregressive Architecture: The output of the visual encoder is directly concatenated with the text embedding and the entire sequence is input to the language model. The visual sequence can be compressed to improve computational efficiency.
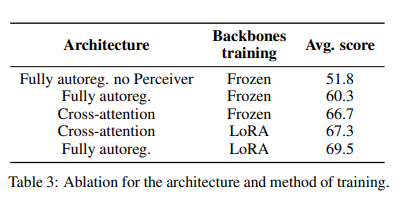
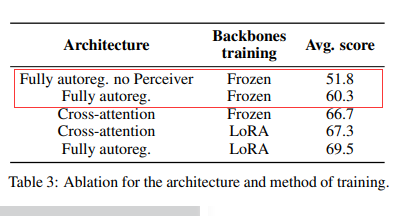
To evaluate the advantages and disadvantages of the two architectures, the author froze the unimodal modules and only trained newly initialized parameters (one side using cross-attention, the other side using modal projection and pooling), and compared them under a fixed training data volume. The high-frequency alternating arrangement of cross-attention blocks and language model layers can enhance visual-language performance. Following this setup, the cross-attention architecture has an additional 1.3 billion trainable parameters (totaling 2 billion), and the computation increases by 10% during inference. Under these conditions, the performance of the cross-attention architecture improved by 7 percentage points compared to the fully autoregressive architecture, as shown in rows two and three of the table below.In the total parameters, the fully autoregressive architecture accounts for about 15%, while the cross-attention architecture accounts for about 25%. This low ratio may limit the expressive power of the training. The author unfroze all parameters (including newly initialized and pre-trained unimodal module parameters) to compare the two architectures. To prevent the training loss of the fully autoregressive architecture from diverging, the LoRA method was used to adjust the pre-trained parameters while fully fine-tuning the newly initialized parameters, and the experimental results are shown in the last two rows of the table above.This method significantly improved training stability: the fully autoregressive architecture’s performance improved by 12.9 percentage points, while the cross-attention architecture improved by 0.6 percentage points. Therefore, under the condition of increased adjustable parameters, the fully autoregressive architecture is more cost-effective.
Conclusion 1: When the unimodal pre-training modules are frozen, the performance of the cross-attention structure is better than that of the fully autoregressive structure. However, once the unimodal networks are unfrozen and trained, despite more parameters in the cross-attention structure, the fully autoregressive architecture exhibits better performance.
Conclusion 2: Under the fully autoregressive architecture, directly unfreezing the pre-trained modules may lead to instability in the training process. Using LoRA technology can effectively increase the model’s expressiveness while maintaining training stability.
More Image Tokens, Stronger Performance?
Previous studies typically passed all hidden states of the visual encoder directly to the modal projection layer and input them to the language model without pooling operations, resulting in a massive number of tokens per image, thereby increasing training costs. Research [2,3] indicates that increasing the number of visual tokens can enhance performance, but the author found that when using more than 64 visual tokens, performance did not improve further. The author speculates that in a theoretically unlimited training and data scenario, more tokens might improve performance, but at a cost that is unacceptable in real-world scenarios.To address this issue, the author introduced a trainable Transformer pooler (such as Perceiver) to reduce the sequence length of each image’s hidden states. This method improves model performance while reducing the number of tokens. As shown in the table below, this method improved scores by an average of 8.5 points compared to methods without pooling and reduced the number of tokens required per image from 729 to 64.
Conclusion: Using a trainable pooler to reduce the number of visual tokens significantly improves computational efficiency during training and inference while enhancing downstream task performance.
Does Fixed Image Aspect Ratio and Resolution Impact Performance?
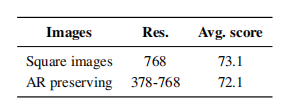
Visual encoders (like SigLIP) are usually trained on fixed-sized square images. Adjusting the image size changes its original aspect ratio, which can be problematic for certain tasks (such as reading long texts). Moreover, training solely at a single resolution has limitations: low resolution may overlook critical visual details, while high resolution reduces training and inference efficiency. Allowing the model to handle images of different resolutions enables users to flexibly adjust computational resources as needed.Visual encoders (like SigLIP) are typically trained on fixed square images, and resizing can change the aspect ratio, affecting tasks like long text reading. Additionally, different resolutions have their pros and cons: low resolution misses details, while high resolution decreases efficiency. Thus, allowing different resolution inputs can flexibly adjust computational resources.This article attempts to send images directly in chunks to the visual encoder without adjusting their size or changing their aspect ratio. During training on fixed-size low-resolution square images, pre-trained position embeddings were inserted, and LoRA parameters were used to adjust the visual encoder. The results are shown in the table below:
It can be seen that the strategy of fixing the aspect ratio (AR preserving) maintains task performance while releasing computational flexibility. There is no need to uniformly adjust to high resolution, saving GPU memory and allowing on-demand image processing.
Conclusion: Using pre-trained visual encoders on fixed-sized square images to preserve the original aspect ratio and resolution accelerates training and inference while reducing memory consumption without compromising performance.
What is the Impact of Training on Split Sub-images?
Multiple papers indicate that splitting images into sub-images and then connecting them with the original image can enhance downstream task performance, but at the cost of a significant increase in the number of image tokens that need to be encoded.During the instruction fine-tuning phase, the author expanded each image into a list containing the original image and four cropped images. Thus, the model can process either a single image (64 visual tokens) or an enhanced image set (totaling 320 visual tokens) during inference, as shown in the table below:
This strategy is particularly effective for benchmarks like TextVQA and DocVQA, which require high resolution to extract text from images. Even splitting only 50% of the training images did not affect performance.
Conclusion: Splitting images into sub-images during training can enhance computational efficiency during inference and improve performance. The improvement in performance is especially notable for tasks involving reading text in images.
Building Idefics2—An Open Advanced Visual Language Foundation Model
After discussing the factors affecting the performance of visual models, the author trained an open 8B parameter visual language model—Idefics2. Below, we will elaborate on the model construction, dataset selection, and training phase process.
1. Multi-Stage Pre-training
We started with SigLIP-SO400M and Mistral-7B-v0.1 and pre-trained Idefics2 on three types of data.
Cross-Image-Text Document
The data source uses the OBELICS dataset, which has been filtered and cleaned. This is an open cross-image-text document dataset that contains 350 million images and 115 billion text tokens. The long document design of OBELICS allows the language model to learn to handle any number of cross images and texts while maintaining performance.
Image-Text Pairs
Next, it is necessary to train the model using image-text pairs to learn the correspondence between images and their related texts. This article uses high-quality manually annotated image-text pair data from PMD and synthetic annotated data from the LAION COCO version, where images are annotated by models trained on COCO, resulting in less noise. A high-recall NSFW classifier was also used for filtering.
PDF Documents
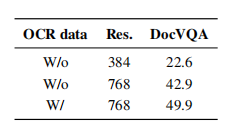
To overcome the shortcomings of VLM in extracting text from images and documents, the author trained the Idefics2 model using 19 million industry documents from OCR-IDL, 18 million pages of PDFA6 data, and added Rendered Text to enhance recognition of diverse fonts and richly colored texts. The results in the table below show that this setup significantly improves the model’s ability to read documents and extract images.
Training Process
To improve computational efficiency, pre-training was conducted in two stages. In the first stage, the maximum image resolution was set to 384 pixels, allowing an average batch size of 2048 (covering 17,000 images and 25 million text tokens). 70% of the data was based on the OBELICS dataset (maximum sequence length of 2048), and 30% was from the image-text pair dataset (maximum sequence length of 1536).In the second stage, PDF documents were introduced, increasing the resolution to 980 pixels while maintaining the global batch size but reducing the single-machine batch size, using gradient accumulation to compensate for additional memory. In terms of sample allocation, OBELICS accounted for 45% (maximum sequence length of 2048), image-text pairs accounted for 35% (maximum sequence length of 1536), and PDF documents accounted for 20% (maximum sequence length of 1024). At the same time, images were randomly enlarged to cover different sizes.
Model Evaluation
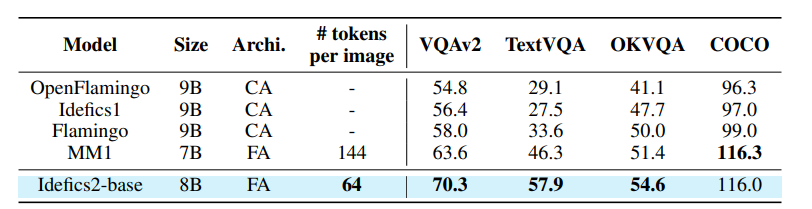
This article selects VQAv2, TextVQA, OKVQA, and COCO for model evaluation. As shown in the table below:
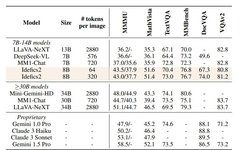
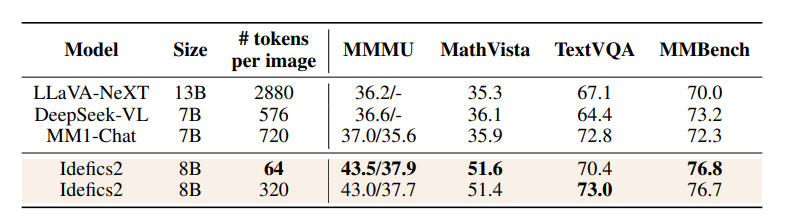
Despite the fewer tokens per image in Idefics2, its efficiency allows it to outperform the current best foundational visual language models. Particularly in understanding text within images, Idefics2 shows significant advantages. The following image demonstrates Idefics2-base recognizing handwritten fonts.
2. Instruction Fine-Tuning
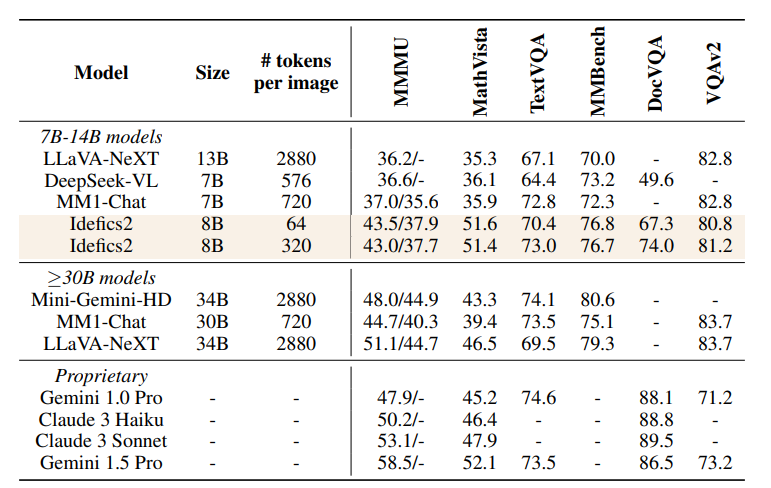
During the instruction fine-tuning phase, The Cauldron—a large collection of 50 visual-language datasets covering a wide range of tasks such as visual question answering, counting, captioning, text transcription, and document understanding—was created. The dataset adopts a shared question/answer format, building multi-turn dialogues for multiple question/answer pairs. Additionally, a pure text instruction dataset was added to teach the model to follow complex instructions and solve mathematical and arithmetic problems.A variant of LoRA, DoRA, was used to fine-tune the base model. During fine-tuning, only the loss of the answer part of the Q/A pairs was computed, and various strategies like NEFTune were employed to add noise to the embeddings to reduce overfitting risk. Then, the image resolution was randomly adjusted, and multi-turn interactions were randomly shuffled to input examples into the model.The evaluation results shown in the table indicate that Idefics2 performs excellently on benchmarks such as MMMU, MathVista, TextVQA, and MMBench, demonstrating not only higher computational efficiency during inference but also outperforming visual language models of similar size (LLaVA-Next, DeepSeek-VL, MM1-Chat).Idefics2’s performance is comparable to that of state-of-the-art models four times its size, and it can even compete with the closed-source model Gemini 1.5 Pro on benchmarks like MathVista and TextVQA.
3. Dialogue Scene Optimization
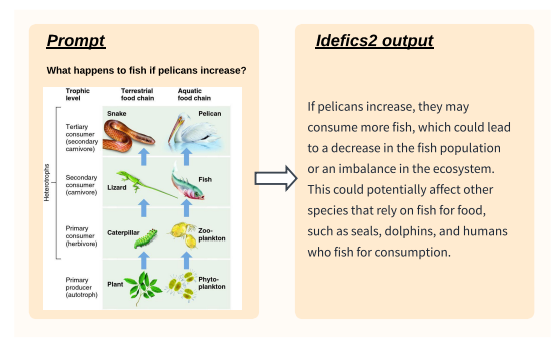
Evaluation benchmarks often expect very brief answers, but humans tend to prefer longer generations when interacting with models. Idefics2 may struggle to accurately follow expected formats of instructions, finding it challenging to balance the “length” and “shortness” of generated responses.Therefore, after instruction fine-tuning, the author further trained Idefics2 on dialogue data. Idefics2 underwent several hundred steps of fine-tuning on LLaVA-Conv and ShareGPT4V.User feedback shows that in many interactions, Idefics2-chatty significantly outperformed the version that had only undergone instruction fine-tuning. Below are some generation examples:▲ Describing an AI-generated image▲ Answering questions based on scientific charts
Conclusion
This article explores the effectiveness of commonly used tricks in the literature when building multimodal large models through detailed experiments, arriving at a series of valuable conclusions. Moreover, the author has practically applied these useful techniques to successfully build a high-performance 8B parameter visual language model—Idefics2. Among models of equal size, Idefics2 exhibits state-of-the-art performance and higher inference efficiency, providing important references for the research of multimodal large models.
References
[1] Karamcheti, S., S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh (2024). Prismatic vlms: Investigating the design space of visually-conditioned language models. [2] Vallaeys, T., M. Shukor, M. Cord, and J. Verbeek (2024). Improved baselines for data-efficient perceptual augmentation of llms. [3] Mm1: Methods, analysis & insights from multimodal llm pre-training.Technical Exchange Group Invitation
△ Long press to add the assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)to apply for joining the Natural Language Processing/Pytorch technical exchange group
About Us
MLNLP Community is a grassroots academic community jointly established by domestic and international scholars in machine learning and natural language processing. It has developed into a well-known machine learning and natural language processing community, aimed at promoting progress between the academic and industrial sectors of machine learning and natural language processing.The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.