Click the "Xiaobai Learns Vision" above, select "Star" or "Top"
Heavyweight content delivered at the first time
Introduction
With the rapid development of deep learning, the explosive growth of model parameters has put higher demands on the memory capacity of GPUs. How to train models on GPUs with small memory capacity has always been a concern. This article briefly analyzes some common memory-saving strategies based on the MMCV open-source library.
0 Preface
The memory-saving strategies in PyTorch discussed in this article include:
-
Mixed Precision Training -
Large Batch Training or Gradient Accumulation -
Gradient Checkpointing
1 Mixed Precision Training
Mixed Precision Training, officially known as Automatic Mixed Precision (AMP), is commonly referred to as FP16. The principles of AMP, its source code implementation, and how to use AMP with one line of code in MMCV have been analyzed in detail in previous articles. For specific links, see:
OpenMMLab: Detailed Analysis of torch.cuda.amp: Automatic Mixed Precision
https://zhuanlan.zhihu.com/p/348554267
OpenMMLab: The Correct Way to Use Mixed Precision Training AMP in OpenMMLab
https://zhuanlan.zhihu.com/p/375224982
Since the previous two articles have been analyzed in detail, this article will only briefly describe the principles and specific usage.
Considering that the gradient magnitudes during training are mostly very small, training defaults to FP32 format. If training can be conducted directly in FP16 format, theoretically it can reduce memory usage by half, thereby accelerating training and allowing for larger batch sizes. However, training directly in FP16 may cause overflow issues, leading to NaN or failed parameter updates. AMP was introduced to solve this problem, and its core idea is mixed precision training + dynamic loss scaling:
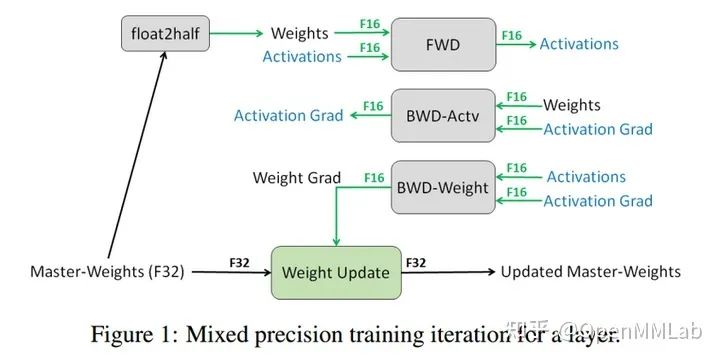
-
Maintain a copy of the model with FP32 numerical precision -
At each iteration
-
Copy and convert to FP16 model -
Forward propagation (with FP16 model parameters), at this time weights and activations are both FP16 -
Loss multiplied by scale factor s -
Backward propagation (with FP16 model parameters and gradients), at this time gradients are also FP16 -
Parameter gradients multiplied by 1/s -
Use FP16 gradients to update FP32 model parameters
Using AMP in MMCV is divided into two situations:
-
Using MMCV’s AMP in upstream libraries such as MMDetection -
The user simply wants to call AMP in MMCV without relying on upstream libraries
(1) How to Use MMCV’s AMP in Upstream Libraries
Taking MMDetection as an example, the usage is very simple; just set in the configuration:
fp16 = dict(loss_scale=512.) # Static scale
# Dynamic scale fp16 = dict(loss_scale='dynamic')
# Flexibly enable dynamic scale fp16 = dict(loss_scale=dict(init_scale=512.,mode='dynamic'))
The three different settings have very similar performance on most models. If you do not want to set loss_scale, you can simply use loss_scale='dynamic'
(2) Calling AMP in MMCV
Directly calling AMP in MMCV usually means that the user may have AMP functionality supported in other libraries or their own codebase. It should be emphasized that PyTorch officially started supporting AMP only from version 1.6 and later, while MMCV’s AMP supports version 1.3 and later. If you want to use AMP in versions 1.3 or 1.5, using MMCV is a very good choice.
To use the AMP functionality in MMCV, simply follow these steps:
-
Apply the auto_fp16 decorator to the model’s forward function -
Set the model’s fp16_enabled to True to enable AMP training, otherwise it will not take effect -
If AMP is enabled, configure the corresponding FP16 optimizer settings Fp16OptimizerHook -
At different training moments, call Fp16OptimizerHook. If you are using the Runner module in MMCV, simply input the parameters from step 3 into the Runner -
(Optional) If you want certain operations to be forced to run in FP32, you can introduce the force_fp32 decorator at the corresponding locations
# 1 Apply to the forward function
class ExampleModule(nn.Module):
@auto_fp16()
def forward(self, x, y): return x, y # 2 If AMP is enabled, add the enabling flag
model.fp16_enabled = True
# 3 Configure Fp16OptimizerHook
optimizer_config = Fp16OptimizerHook( **cfg.optimizer_config, **fp16_cfg, distributed=distributed)
# 4 Pass to runner
runner.register_training_hooks(cfg.lr_config, optimizer_config, cfg.checkpoint_config, cfg.log_config, cfg.get('momentum_config', None)) # 5 Optional
class ExampleModule(nn.Module):
@auto_fp16()
def forward(self, x, y): features=self._forward(x, y) loss=self._loss(features,labels) return loss def _forward(self, x, y): pass @force_fp32(apply_to=('features',)) def _loss(features,labels) : pass
Note that force_fp32 must be effective; it still requires fp16_enabled to be True to take effect.
2 Large Batch Training (Gradient Accumulation)
Large Batch Training is also known as gradient accumulation strategy. The typical training process for PyTorch in one iteration is:
y_pred = model(xx)
loss = loss_fn(y_pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
In the case of gradient accumulation, the common training process in one iteration is:
y_pred = model(xx)
loss = loss_fn(y_pred, y)
loss = loss / cumulative_iters
loss.backward()
if current_iter % cumulative_iters==0: optimizer.step() optimizer.zero_grad()
The core idea is to accumulate gradients from the previous iterations and then uniformly update parameters, thereby achieving the effect of a larger batch size. It is important to note that if the model includes layers that consider batch information, such as Batch Normalization (BN), there may be slight performance differences.
For details, please refer to:
https://github.com/open-mmlab/mmcv/pull/1221
The gradient accumulation function has been implemented in MMCV, and the core code is located in mmcv/runner/hooks/optimizer.py. Like AMP, it is implemented using hooks. The usage is similar to AMP; just replace Fp16OptimizerHook from the first section with GradientCumulativeOptimizerHook or GradientCumulativeFp16OptimizerHook. The core implementation is as follows:
@HOOKS.register_module()
class GradientCumulativeOptimizerHook(OptimizerHook):
def __init__(self, cumulative_iters=1, **kwargs): self.cumulative_iters = cumulative_iters self.divisible_iters = 0 # Remaining training iterations divisible by cumulative_iters self.remainder_iters = 0 # Remaining accumulation counts self.initialized = False def after_train_iter(self, runner): # Only needs to run once if not self.initialized: self._init(runner) if runner.iter < self.divisible_iters: loss_factor = self.cumulative_iters else: loss_factor = self.remainder_iters loss = runner.outputs['loss'] loss = loss / loss_factor loss.backward() if (self.every_n_iters(runner, self.cumulative_iters) or self.is_last_iter(runner)): runner.optimizer.step() runner.optimizer.zero_grad()
def _init(self, runner): residual_iters = runner.max_iters - runner.iter self.divisible_iters = ( residual_iters // self.cumulative_iters * self.cumulative_iters) self.remainder_iters = residual_iters - self.divisible_iters self.initialized = True
It is important to understand the meanings of divisible_iters and remainder_iters:
(1) Training from Scratch
At this time, when starting training, iter=0, with a total of max_iters=102 iterations, and the gradient accumulation count is 4. Since 102 cannot be divided by 4, the last 102-(102 // 4)*4=2 iterations are extra and need to be considered. In the last 2 training iterations, loss_factor cannot be divided by 4, but by 2, which is the most reasonable approach. Here, remainder_iters=2, divisible_iters=100, and residual_iters=102.
(2) Resuming Training
Assuming that training is interrupted in the middle of gradient accumulation, and then resumed, the iter is not 0. Since the optimizer object needs to be reinitialized, to ensure that the remaining non-accumulated training iterations can be calculated correctly, residual_iters needs to be recalculated.
3 Gradient Checkpointing
Gradient checkpointing is a method that trades training time for memory. Its core principle is to recompute the intermediate activation values of the neural network during backpropagation without storing them during the forward pass. The corresponding functionality has been implemented in the torch.utils.checkpoint package. The brief implementation process is: the forward function passed to checkpoint during the forward phase runs in _torch.no_grad_ mode and only saves input parameters and the forward function, and during the backward phase, it recalculates the forward output values.
The specific usage is very simple; taking ResNet’s BasicBlock as an example:
def forward(self, x): def _inner_forward(x): identity = x out = self.conv1(x) out = self.norm1(out) out = self.relu(out) out = self.conv2(out) out = self.norm2(out) if self.downsample is not None: identity = self.downsample(x) out += identity return out # The x.requires_grad check is very necessary
if self.with_cp and x.requires_grad: out = cp.checkpoint(_inner_forward, x) else: out = _inner_forward(x) out = self.relu(out) return out
self.with_cp being True indicates that the gradient checkpointing function should be enabled.
When using checkpoint, the following points need to be noted:
-
The first layer of the model cannot use checkpoint, or in other words, not all inputs in the forward input can have requires_grad set to False, because its internal implementation relies on the requires_grad property of the input to determine whether the output should return gradients. Usually, the first layer input is the image tensor, which typically has requires_grad set to False. If you use checkpoint in the first layer, it means that this forward function will not have any gradients, which means there will be no parameter updates, making it unnecessary to use. For details, see https://discuss.pytorch.org/t/use-of-torch-utils-checkpoint-checkpoint-causes-simple-model-to-diverge/116271. If checkpoint is used in the first layer, PyTorch will print None of the inputs have requires_grad=True. Gradients will be Nonwarning. -
For layers like dropout that have randomness in the forward pass, ensure preserve_rng_state is set to True (default is True, so no need to worry). Once the flag is set to True, the RNG state will be stored during forward and read during backpropagation, ensuring consistent outputs for two forward passes. If you are sure you do not need to save the RNG, you can set preserve_rng_state to False to skip some unnecessary execution logic. -
For other considerations, please refer to the official documentation https://pytorch.org/docs/stable/checkpoint.html#
The core implementation is as follows:
class CheckpointFunction(torch.autograd.Function):
@staticmethod def forward(ctx, run_function, preserve_rng_state, *args): # Check if input parameters need gradients check_backward_validity(args) # Save necessary state ctx.run_function = run_function ctx.save_for_backward(*args) with torch.no_grad(): # Run once in no_grad mode outputs = run_function(*args) return outputs
@staticmethod def backward(ctx, *args): # Read input parameters inputs = ctx.saved_tensors # Stash the surrounding rng state, and mimic the state that was # present at this time during forward. Restore the surrounding state # when we're done. rng_devices = [] with torch.random.fork_rng(devices=rng_devices, enabled=ctx.preserve_rng_state): # Detach current nodes that do not need to be considered detached_inputs = detach_variable(inputs) # Rerun once with torch.enable_grad(): outputs = ctx.run_function(*detached_inputs) if isinstance(outputs, torch.Tensor): outputs = (outputs,) # Compute gradients for this subgraph torch.autograd.backward(outputs, args) grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else inp for inp in detached_inputs) return (None, None) + grads
4 Experimental Validation
To verify whether the above strategies can indeed save memory, the mmdetection library was used for validation, with the basic environment as follows:
GPU: GeForce GTX 1660
PyTorch: 1.7.1
CUDA Runtime: 10.1
MMCV: 1.3.16
MMDetection: 2.17.0
(1) Base
-
Dataset: PASCAL VOC -
Algorithm: RetinaNet, corresponding configuration file: retinanet_r50_fpn_1x_voc0712.py -
To prevent the learning rate from being too large and causing NaN during training, the learning rate should be set to 0.01/8=0.00125 -
Batch size set to 2
(2) Mixed Precision AMP
On the basis of the base configuration, simply add the following configuration:
fp16 = dict(loss_scale=512.)
(3) Gradient Accumulation
On the basis of the base configuration, replace optimizer_config with the following:
# Accumulate 2 times
optimizer_config = dict(type='GradientCumulativeOptimizerHook', cumulative_iters=2)
(4) Gradient Checkpointing
On the basis of the base configuration, simply enable the with_cp flag in the backbone section:
model = dict(backbone=dict(with_cp=True), bbox_head=dict(num_classes=20))
Each experiment iterates a total of 1300 times, recording memory usage and total training time.
| Configuration | Memory Usage (MB) | Training Duration |
|---|---|---|
| Base | 2900 | 7 minutes 45 seconds |
| Mixed Precision AMP | 2243 | 36 minutes |
| Gradient Accumulation | 3177 | 7 minutes 32 seconds |
| Gradient Checkpointing | 2590 | 8 minutes 37 seconds |
-
Comparing base and AMP, it can be found that since the experimental GPU does not support AMP, it can only save memory while the speed will be particularly slow. If the GPU supports AMP, it can achieve both memory savings and speedup in training. -
Comparing base and gradient accumulation, it can be found that with the same batch size, accumulating gradients 2 times is equivalent to doubling the batch size, but memory usage does not increase much. If the batch size is halved, it can achieve roughly half the memory savings under the same batch size. -
Comparing base and gradient checkpointing, it can be found that it can save some memory, but training time will increase slightly.
From the above simple experiments, it can be concluded that AMP, gradient accumulation, and gradient checkpointing can indeed reduce memory usage to varying degrees, and these three strategies are orthogonal and can be used simultaneously.
5 Conclusion
This article briefly describes three memory-saving strategies integrated in MMCV that can be enabled with just one line of configuration. These three strategies are commonly used and mature. As the model size continues to grow, many new strategies have emerged, such as model parameter compression, dynamic memory optimization, using CPU memory for temporary storage, and the latest ZeroRedundancyOptimizer supported by PyTorch 1.10 in distributed scenarios, etc.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "Xiaobai Learns Vision" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of "Xiaobai Learns Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Community Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat number below to join the group, with remarks: "Nickname + School/Company + Research Direction", e.g., "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, it will not be approved. After successfully adding, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~