
Author: Kevin Wu Jiawen, Master of Information Technology, Singapore Management UniversityHomepage: kevinng77.github.io/Disclaimer: This article is for sharing only, copyright belongs to the original author, infringement will be deleted upon private message!Original article: https://zhuanlan.zhihu.com/p/711294388
This article outlines the key information of the Mistral series models (Mistral 7B, Mixtral 8x7B, Mixtral 8x22B, Mistral Nemo, Mistral Large 2), including their main features, highlights, and related resource links.
Mistral 7B
Official Blog: https://mistral.ai/news/announcing-mistral-7b/ Mistral 7B Paper: https://arxiv.org/abs/2310.06825The highlights of the Mistral 7B model include:
Sliding Window Attention
Mistral adopts a window size of 4096, and there are a total of 32 layers. Therefore, theoretically, when performing attention, it can collect information from approximately 131K tokens. (Although the paper mentions a window size of 4096, the max_position_embeddings in the weights provided on huggingface[1] is 32768, and in newer versions, such as mistral-7b-instruct-v0.2[2], sliding window is no longer used.)
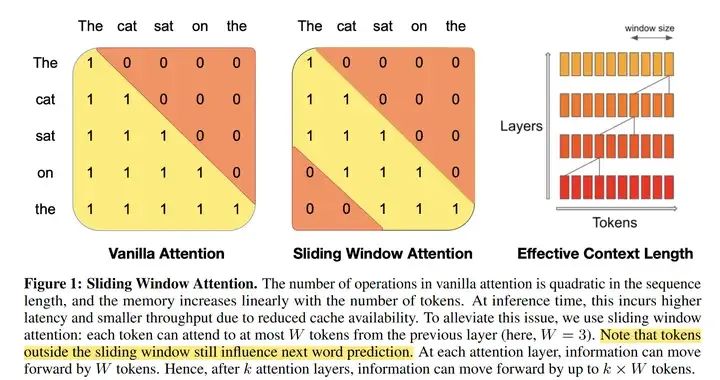
Due to the use of a fixed attention window size, we only need a cache of size W=window size. When calculating the cache for the i-th token, we only need to overwrite the hidden state at position i mod M in the cache.
Referencing the implementation of Mistral by huggingface, the Sliding Window Attention is controlled by the attention_mask:
# huggingface mistral attn mask implementationdef _update_causal_mask(self, attention_mask: torch.Tensor, input_tensor: torch.Tensor, cache_position: torch.Tensor, past_key_values: Cache,):# ... omitted unrelated code past_seen_tokens = cache_position[0]if past_key_values is not None else 0 using_static_cache = isinstance(past_key_values, StaticCache) using_sliding_window_cache = isinstance(past_key_values, SlidingWindowCache) dtype, device = input_tensor.dtype, input_tensor.device min_dtype = torch.finfo(dtype).min sequence_length = input_tensor.shape[1]# SlidingWindowCacheif using_sliding_window_cache: target_length = max(sequence_length, self.config.sliding_window)# StaticCacheelif using_static_cache: target_length = past_key_values.get_max_length()# DynamicCache or no cacheelse: target_length =( attention_mask.shape[-1]if isinstance(attention_mask, torch.Tensor) else past_seen_tokens + sequence_length + 1)if attention_mask is not None and attention_mask.dim() == 4:# in this case we assume that the mask comes already in inverted form and requires no inversion or slicingif attention_mask.max() != 0: raise ValueError('Custom 4D attention mask should be passed in inverted form with max==0`') causal_mask = attention_maskelse: causal_mask = torch.full((sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device) exclude_mask = torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)if self.config.sliding_window is not None:if not using_sliding_window_cache or sequence_length > self.config.sliding_window: exclude_mask.bitwise_or_( torch.arange(target_length, device=device) <= (cache_position.reshape(-1, 1) - self.config.sliding_window)) causal_mask *= exclude_mask causal_mask = causal_mask[None, None, :, :].expand(input_tensor.shape[0], 1, -1, -1)if attention_mask is not None: causal_mask = causal_mask.clone()# copy to contiguous memory for in-place editif attention_mask.dim() == 2: mask_length = attention_mask.shape[-1] padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :] padding_mask = padding_mask == 0 causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill( padding_mask, min_dtype)return causal_maskGQA (Grouped Query Attention)
Paper: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints Abs: https://arxiv.org/abs/2305.13245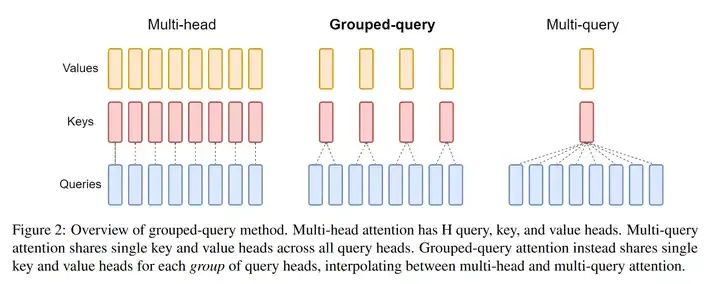
Grouped-query attention points out that Multi-Query Attention[3] improves inference speed but may greatly reduce response quality. Therefore, based on the above image, GQA balances inference speed and quality.
Below are the experimental results from the GQA paper. It is worth noting that after converting the original MHA checkpoint to GQA weights, additional pre-training was conducted:

Additionally, when using GQA, some models of Mistral and Llama2 seem to use 8 kv heads.
Why is everyone using MQA and GQA now?[4] The article mentions that one of the points where MQA and GQA achieve significant acceleration is due to the strong limitations of GPU memory. Since both MQA and GQA reduce the amount of data read in memory and decrease the waiting time for computational units, the improvement in inference speed is much faster than expected.
Mixtral 8*7B
Paper: https://arxiv.org/abs/2401.04088 Huggingface model weights: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 Official Blog: https://mistral.ai/news/mixtral-of-experts/ Huggingface model code: https://github.com/huggingface/transformers/blob/main/src/transformers/models/mixtral/modeling_mixtral.py Basic of Mixture of Experts model (recommended): https://huggingface.co/blog/zh/moeAccording to the official ratings, Mixtral 8*7 is comparable to GPT3.5.
-
• Release Date: December 2023
-
• Model Size: 8 expert MLP layers, a total of 45B size.
-
• Training: In addition to pre-training, Mixtral MOE has also open-sourced a version fine-tuned with SFT + DPO.
-
• Model Performance:
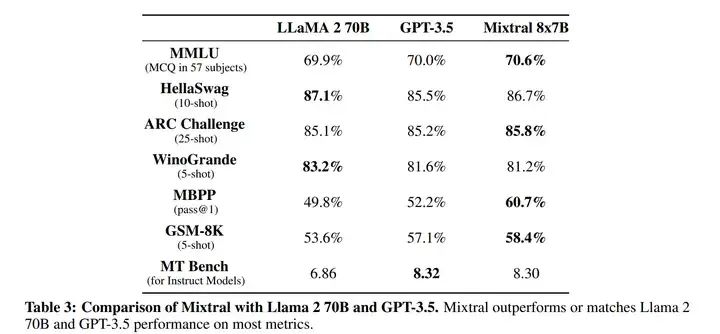
-
• Architecture: The MOE architecture of Mixtral is similar to the traditional transformer decoder layer, where only the FFN layer is regarded as an independent expert, while other model parameters are shared. Roughly, the parameters are:
Comparing the implementations of Mixtral and Mistral in huggingface, the difference is that Mixtral replaces the FFN in the traditional transformer decoder layer with block_sparse_moe.
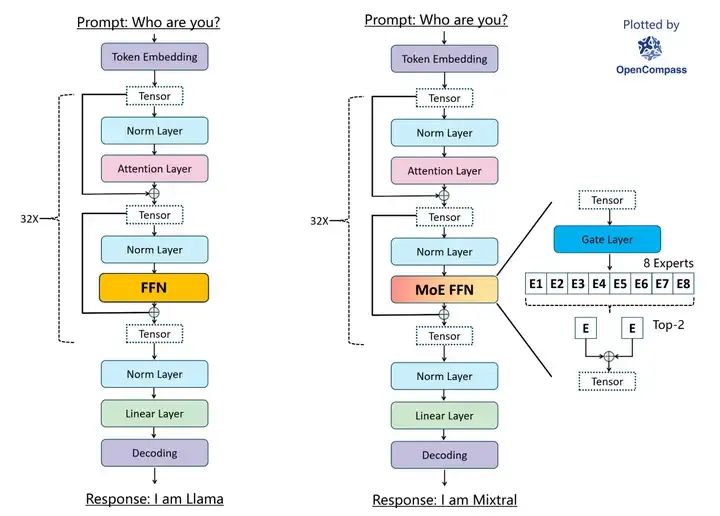
Main Logic
G(x)=Softmax(TopK(x⋅Wgate))final hidden states=∑i=0n−1G(x)i⋅Ei(x)
Where Ei(x) represents the corresponding network of the expert, specifically displayed in the implementation of MixtralBlockSparseTop2MLP in huggingface. In Mixtral, 8 experts are used, and the top 2 experts are selected for inference for each token. For example, for the input sentence “Hello, today,” the top 2 experts will be selected to be responsible for the prediction of each token. Therefore, during the inference of “Hello, today,” there is a probability that all experts will participate in the computation, which can be referred to in the implementation of MixtralSparseMoeBlock.

The Mixtral paper mentions that there is no obvious pattern in expert allocation across different topics (such as ArXiv papers, biology, and philosophy documents), only showing marginal differences in DM mathematics, which may be due to the synthetic nature of their dataset and limited coverage of natural language. The router exhibits some structured behavior on certain syntactic structures (e.g., Python’s self), and consecutive tokens are usually assigned to the same expert.
Core Code of Mixtral in Huggingface
class MixtralDecoderLayer(nn.Module):def __init__(self, config:MixtralConfig, layer_idx:int):super().__init__()self.hidden_size = config.hidden_sizeself.self_attn = MIXTRAL_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)self.block_sparse_moe =MixtralSparseMoeBlock(config)self.input_layernorm =MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.post_attention_layernorm =MixtralRMSNorm(config.hidden_size, eps=config.rms_norm_eps)def forward( hidden_states: torch.Tensor, attention_mask:Optional[torch.Tensor]=None,# omitted parameters ..)->Tuple[torch.FloatTensor,Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]: residual = hidden_states hidden_states =self.input_layernorm(hidden_states) hidden_states, self_attn_weights, present_key_value =self.self_attn(# omitted parameters ) hidden_states = residual + hidden_states residual = hidden_states hidden_states =self.post_attention_layernorm(hidden_states)# Mixtral replaces hidden_states = self.FFN(hidden_states) with: hidden_states, router_logits =self.block_sparse_moe(hidden_states) hidden_states = residual + hidden_states outputs =(hidden_states,)return outputsImplementation of block_sparse_moe in huggingface (omitting some minor code):
class MixtralSparseMoeBlock(nn.Module):def __init__(self, config):super().__init__()self.hidden_dim = config.hidden_sizeself.ffn_dim = config.intermediate_sizeself.num_experts = config.num_local_expertsself.top_k = config.num_experts_per_tokself.gate = nn.Linear(self.hidden_dim,self.num_experts, bias=False)self.experts = nn.ModuleList([MixtralBlockSparseTop2MLP(config)for _ in range(self.num_experts)])self.jitter_noise = config.router_jitter_noisedef forward(self, hidden_states: torch.Tensor)-> torch.Tensor: batch_size, sequence_length, hidden_dim = hidden_states.shape hidden_states = hidden_states.view(-1, hidden_dim) router_logits =self.gate(hidden_states)# (batch * sequence_length, n_experts) routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float) routing_weights, selected_experts = torch.topk(routing_weights,self.top_k, dim=-1) routing_weights /= routing_weights.sum(dim=-1, keepdim=True)# casting back to the input dtype routing_weights = routing_weights.to(hidden_states.dtype) final_hidden_states = torch.zeros((batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device)# One hot encode the selected experts to create an expert mask# this will be used to easily index which expert is going to be solicited expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2,1,0)# Loop over all available experts in the model and perform the computation on each expertfor expert_idx in range(self.num_experts): expert_layer =self.experts[expert_idx] idx, top_x = torch.where(expert_mask[expert_idx])# Index the correct hidden states and compute the expert hidden state for# the current expert. We need to make sure to multiply the output hidden# states by `routing_weights` on the corresponding tokens (top-1 and top-2) current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)# current_state: shape (n_i, hidden_dim)# All lengths of current_state sum to batch * sequence_length current_hidden_states = expert_layer(current_state)* routing_weights[top_x, idx,None]# However `index_add_` only supports torch tensors for indexing so we'll use# the `top_x` tensor here. final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype)) final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)return final_hidden_states, router_logitsWhere: MixtralBlockSparseTop2MLP looks like this:
class MixtralBlockSparseTop2MLP(nn.Module):def __init__(self, config:MixtralConfig):super().__init__()self.ffn_dim = config.intermediate_sizeself.hidden_dim = config.hidden_sizeself.w1 = nn.Linear(self.hidden_dim,self.ffn_dim, bias=False)self.w2 = nn.Linear(self.ffn_dim,self.hidden_dim, bias=False)self.w3 = nn.Linear(self.hidden_dim,self.ffn_dim, bias=False)self.act_fn = ACT2FN[config.hidden_act]def forward(self, hidden_states): current_hidden_states =self.act_fn(self.w1(hidden_states))*self.w3(hidden_states) current_hidden_states =self.w2(current_hidden_states)return current_hidden_statesRegarding inference, based on the model parameter size of 45B, if using fp16 for inference, at least 90GB of GPU memory is required, while 30GB is sufficient when using 4-bit. The generation speed of quantization can be referenced in this redis[5] comment, approximately as follows:
| Inference Precision | Device | Speed tokens/s |
| Q4_K_M | Single card 4090 + 7950X3D | 20 |
| Q4_K_M | 2 x 3090 | 48.26 |
If you have over 100GB of GPU memory, you can quickly set up a testing API using vllm:
docker run --gpus all \
-e HF_TOKEN=$HF_TOKEN -p 8000:8000 \
ghcr.io/mistralai/mistral-src/vllm:latest \
--host 0.0.0.0 \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--tensor-parallel-size 2 # 100+GB GPU memory \
--load-format pt # needed since both `pt` and `safetensors` are availableNvidia TensorRT-LLM[6] blog records the throughput test of Mixtral 8*7B (input and output sequence lengths of 128):
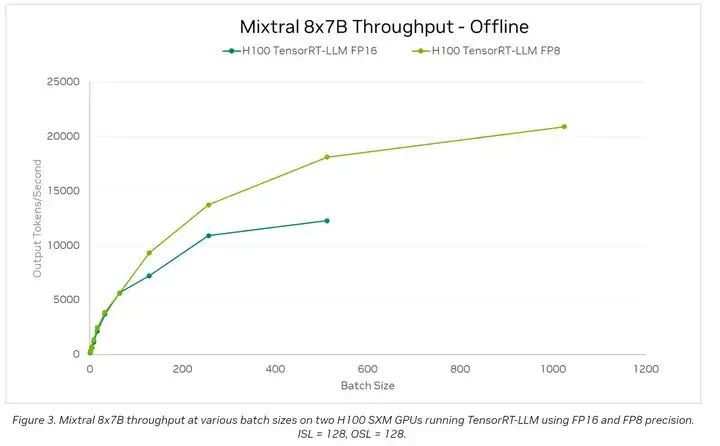
The article does not provide the throughput when the sequence lengths are at their maximum, but based on the data in the above image, it can be speculated that deploying 2 H100 to serve users with 8*7B should yield an average throughput greater than 7500 tokens/second. According to the power cost calculation of H100, generating 1M tokens consumes about 0.02 kWh.
Mixtral 8*22B
Official Blog: https://mistral.ai/news/mixtral-8x22b/ Huggingface open-source model: https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1-
• Architecture: The architecture is the same as that of Mixtral 8*7B, and the model used in huggingface is MixtralForCausalLM, but the parameters of 22B are slightly larger, and notably, the context window has been upgraded from 32k to 65k, and the vocab_size is also larger.
-
• Supports function calling, but no specific training details for function calling have been disclosed.
-
• Its mathematical and coding capabilities significantly surpass those of Llama2 70B.
-
• It seems to have poor support for Chinese.
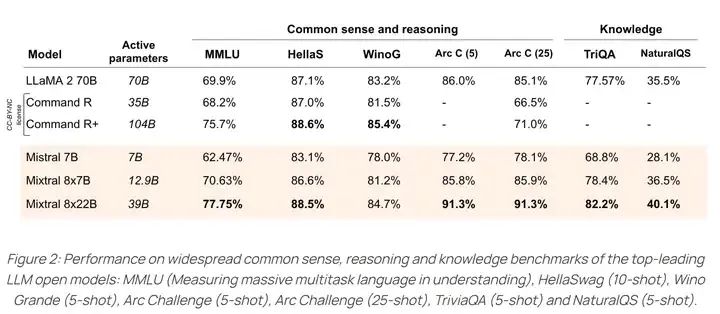
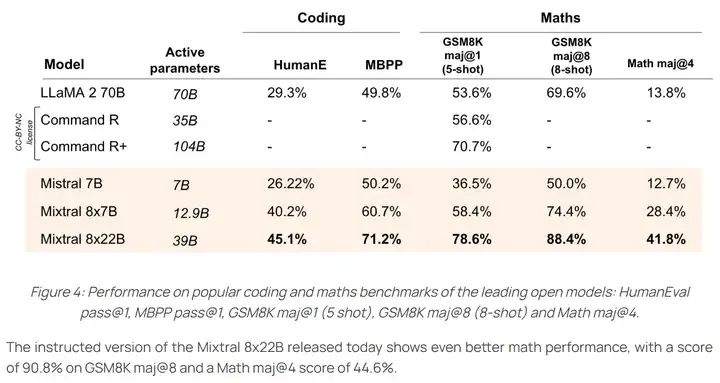
The models open-sourced by the Mistral team focus on coding and math capabilities, and the Mixtral series of models perform well in this regard:
Mistral Nemo
Official Blog: https://mistral.ai/news/mistral-nemo/ Huggingface model weights: https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407Mistral Nemo also uses the MistralForCausalLM architecture. The difference from Mistral 7B is that the hidden_size of Mistral Nemo changes from 4096 to 5120; max_position_embeddings changes to 1024000, num_hidden_layers increases to 40, vocab_size increases to 131072, and sliding window is not used.
Additionally, Mistral Nemo supports function calling and uses Tekken as a tokenizer, which is more efficient than SentencePiece (the official description states it is ~30% more efficient at compressing, though it is unclear in which aspect it is efficient).
NVIDIA mentioned in this blog[7] that Mistral Nemo is designed to be compatible with a single NVIDIA L40S, NVIDIA GeForce RTX 4090, or NVIDIA RTX 4500 GPU. The model was trained using Megatron-LM[8] with 3,072 H100 80GB GPUs.
However, loading the entire Mistral Nemo using FP16 requires 23GB of GPU memory. If you want to run the full context window size, in addition to quantization, offload or other methods will be needed for inference.
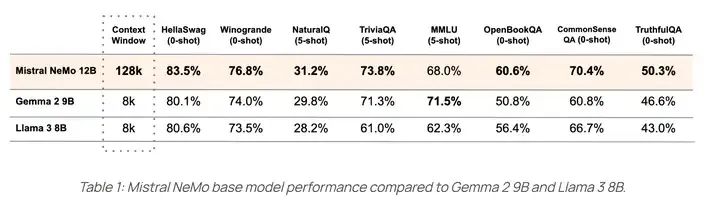
However, it seems unfair for the Mistral team to compare the 12B model with other 8B models:
Mistral Large 2
Official Blog: https://mistral.ai/news/mistral-large-2407/ Huggingface model weights: https://huggingface.co/mistralai/Mistral-Large-Instruct-2407Mistral Large 2 has 123B parameters and focuses on multilingual and coding capabilities. It adopts the same architecture as Mistral 7B, and in huggingface, MistralForCausalLM is also used; notably, the context window size is 131072, and sliding window is not used. It also supports function calling.
Recently, shortly after the release of Llama 3.1, Mistral Large 2 was compared with others:
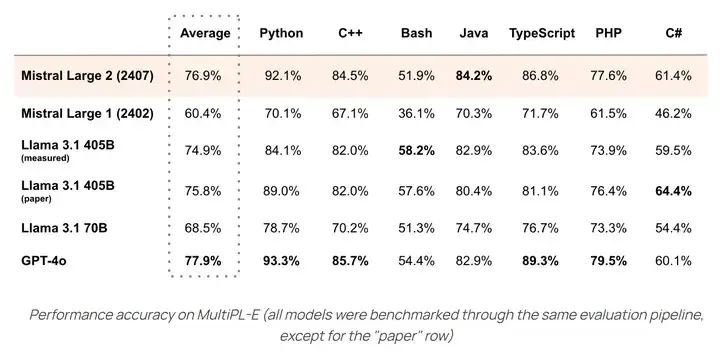
In terms of coding capability, Mistral Large 2 performs better on average than Llama 3.1.
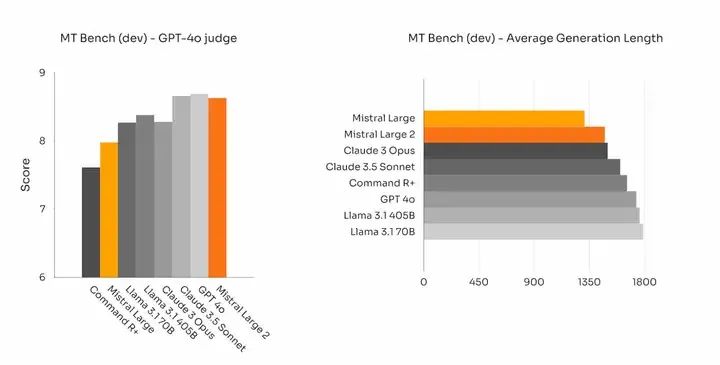
In addition to coding and mathematics, it also scores higher than Llama 3.1 on MT Bench, with an average response length shorter than that of Llama 3.1.
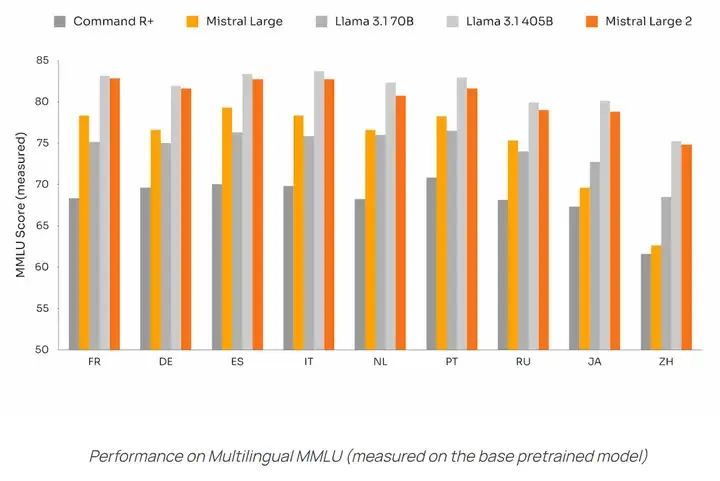
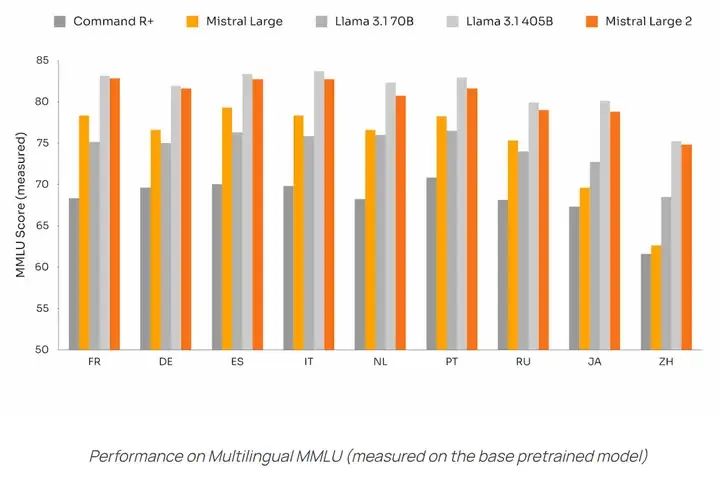
At the same time, the Chinese language capability has significantly improved compared to the previous generation Mistral large:
Reference Links
[1] Weights on huggingface: https://huggingface.co/mistralai/mathstral-7B-v0.1/blob/main/config.json[2] mistral-7b-instruct-v0.2: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/blob/main/config.json[3] Multi-Query Attention: https://arxiv.org/pdf/1911.02150.pdf[4] Why is everyone using MQA and GQA now?: https://zhuanlan.zhihu.com/p/647130255[5] This redis: https://www.reddit.com/r/LocalLLaMA/comments/18jslmf/tokens_per_second_mistral_8x7b_performance/?rdt=57036[6] TensorRT-LLM: https://developer.nvidia.com/blog/achieving-high-mixtral-8x7b-performance-with-nvidia-h100-tensor-core-gpus-and-tensorrt-llm/?ncid=so-twit-928467/[7] This blog: https://blogs.nvidia.com/blog/mistral-nvidia-ai-model/[8] Megatron-LM: https://github.com/NVIDIA/Megatron-LM
For reference links, click the bottom left corner to read the original article. For academic sharing only, please delete immediately if there is any infringement.
Editor / Garvey
Reviewed / Fan Ruiqiang
Checked / Garvey
Click below
Follow us