Author: Jay Chou from Manchester
mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model

This article aims to deeply analyze the key improvements of Mistral 7B and Mistral 8X7B.
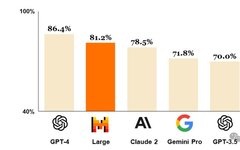
Mistral AI is an AI company co-founded in Paris by three former employees of DeepMind and Meta. In September 2023, Mistral AI launched its first foundational large model, Mistral 7B, which immediately outperformed any open-source 7B model of similar parameter count at the time, even surpassing the best 13B parameter model – Llama 2 – 13B across all evaluation benchmarks, and excelling in inference, mathematics, and code generation compared to Llama 34B. More excitingly, in December of the same year, Mistral AI quickly launched the mixture of experts model Mistral 8x7b (there have been rumors that GPT-4 is also a combination of 8 expert models, and the release of Mistral 8 x 7b provides a possibility close to GPT-4 performance), which outperformed or matched Llama 2 70B and GPT-3.5 in all evaluated benchmarks. Additionally, in February of this year, Mistral continued to release their Mistral – large – 2402, whose performance is shown in Figure 1, indicating its capabilities are already very close to GPT-4 and have surpassed GPT-3.5 and other comparable models. However, since the specific technical paper has not yet been published, the author will not elaborate further.
 ▲Figure 1 | Comparison of GPT-4, Mistral Large (pre-trained), Claude 2, Gemini Pro 1.0, GPT 3.5, and LLaMA 2 70B on MMLU (Measuring Large-scale Multi-task Language Understanding) ©️【Deep Blue AI】compiled
▲Figure 1 | Comparison of GPT-4, Mistral Large (pre-trained), Claude 2, Gemini Pro 1.0, GPT 3.5, and LLaMA 2 70B on MMLU (Measuring Large-scale Multi-task Language Understanding) ©️【Deep Blue AI】compiled

Original paper for Mistral 7B: https://arxiv.org/pdf/2310.06825.pdf
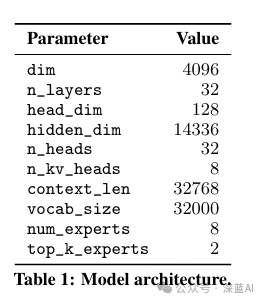
Mistral 7B, as the first foundational large model launched by Mistral AI, borrowed many improvements from its predecessor LLaMa2, adopting GQA (Grouped Query Attention) and RoPE (Rotary Position Embedding). On this basis, Mistral AI further addressed the long text problem using SWA (Sliding Window Attention Mechanism), as shown in Figure 2, where Mistral 7B’s text length has reached 32K, while LLaMa2 only has 4K, and LLaMa1 only has 2K.
▲Figure 2 | Parameters of the Mistral 7B model ©️【Deep Blue AI】compiled
The author compared Mistral7B with various parameter versions of LLaMa, and the results are shown in Figure 3. It can be seen that Mistral 7B surpasses Llama 2-13B on all metrics and outperforms Llama 1-34B in most benchmark tests. Notably, Mistral 7B demonstrated exceptional performance in code, mathematics, and reasoning benchmark tests, closely approaching the code performance of Code-Llama-7B without sacrificing performance on non-code benchmark tests.
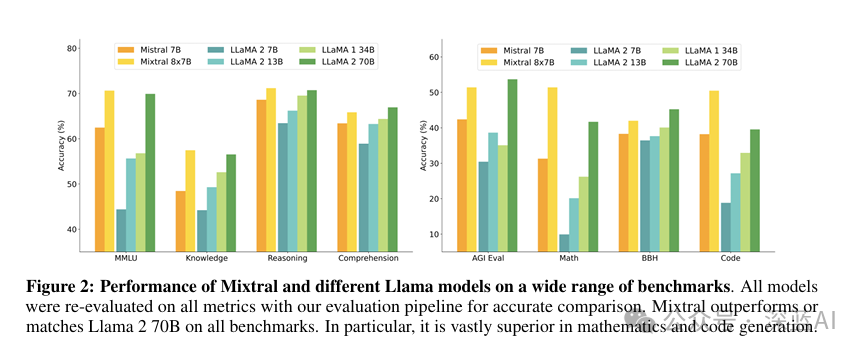 ▲Figure 3 | Performance of Mistral 7B and different Llama models on various benchmarks ©️【Deep Blue AI】compiled
■Core 1: Sliding Window Attention SWA
▲Figure 3 | Performance of Mistral 7B and different Llama models on various benchmarks ©️【Deep Blue AI】compiled
■Core 1: Sliding Window Attention SWA
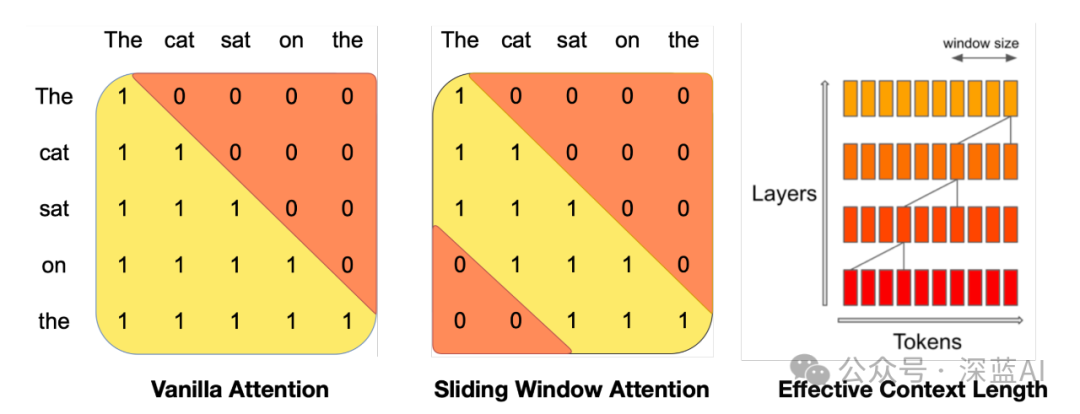 ▲Figure 4 | Comparison between basic self-attention and sliding window attention ©️【Deep Blue AI】compiled
Sliding Window Attention SWA is the most prominent innovation of Mistral 7B compared to the LLaMa series, primarily addressing the long text problem. Assuming everyone is familiar with the attention mechanism, as shown in Figure 4, when calculating vanilla attention, the attention values of every token in the generated sentence are computed. However, for long texts, in most cases, the closer the tokens are, the more relevant they are likely to be, so theoretically, it is not necessary to calculate the attention values for all tokens. Based on this, SWA was proposed, where it is important to note:
▲Figure 4 | Comparison between basic self-attention and sliding window attention ©️【Deep Blue AI】compiled
Sliding Window Attention SWA is the most prominent innovation of Mistral 7B compared to the LLaMa series, primarily addressing the long text problem. Assuming everyone is familiar with the attention mechanism, as shown in Figure 4, when calculating vanilla attention, the attention values of every token in the generated sentence are computed. However, for long texts, in most cases, the closer the tokens are, the more relevant they are likely to be, so theoretically, it is not necessary to calculate the attention values for all tokens. Based on this, SWA was proposed, where it is important to note:
1) When facing this sequence: The cat sat on the.
2) If it is standard attention, when calculating the last token “the”, it needs to compute the inner product of the query corresponding to “the” with the keys corresponding to every token in the previous context, which requires calculating 5 attentions. When the sequence length is very long, this computation is quite significant.
3) However, if it is sliding window attention, then when calculating the last token “the”, it only needs to compute the inner product of the query corresponding to “the” with the keys corresponding to the previous N (where N is the window length) tokens.
It can be seen that SWA indeed simplifies many computation steps, but if each token only focuses on the attention of the previous N tokens, will there be a loss of accuracy? The author actually provides an explanation in the original text, as shown in Figure 4: As long as the transformer layers are deep enough, even if the window size is only 4, through this 4-layer transformer structure, I can still see the range of the farthest 4 * 4 = 16 tokens. Therefore, the loss of accuracy is not significant.
■Core 2: Grouped Query Attention GQA
As shown in Figure 2, in addition to some common parameters, we can find an n_kv_heads, what is this? Similar to LLaMa2, Mistral 7B also uses GQA (Grouped Query Attention). Here, n_heads=32 indicates a total of 32 heads, and n_kv_heads=8 indicates that each group of kv shares 4 groups of queries. This may still be a bit difficult to understand, so the author will explain it in detail.
The original MHA (Multi-Head Attention) has the same number of heads for Q, K, and V, corresponding one-to-one. Each time attention is performed, head1’s QKV can perform its own computation, and the outputs of each head can be summed up. MQA (Multi-Query Attention) retains the original number of Q heads, but only has one KV, meaning all Q heads share a group of K and V heads, hence the name Multi-Query. This principle was adopted by LLaMa1. It is evident that while this improves speed, the accuracy decreases significantly due to the shared KV. Thus, in LLaMa2 and Mistral, GQA achieves a trade-off between performance and computation by grouping a certain number of heads to share a group of KV, avoiding the significant drop in accuracy seen with MQA while also improving speed compared to NHA.(For specific details about GQA, please refer to the previous article: Understanding the LLAMA (Llama) Series)
The mystery from earlier is revealed: it indicates that in Mistral’s GQA, a group of KV shares 4 groups of Q.
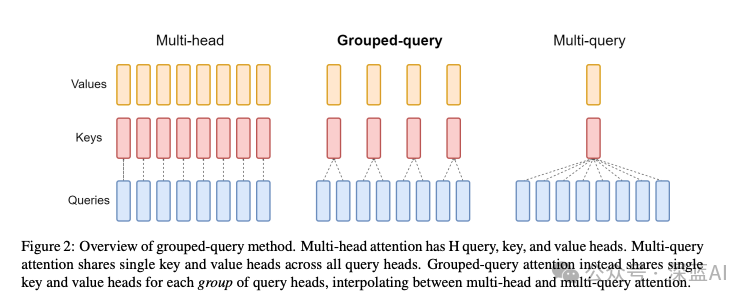 ▲Figure 5 | Mechanism of MHA & GQA & MQA ©️【Deep Blue AI】compiled
■Core 3: Rotary Position Embedding RoPE
Lastly, Mistral is also equipped with RoPE (Rotary Position Embedding) – its core idea is to achieve relative position encoding through absolute position encoding, thus addressing the issue of context disconnection caused by long LLM contexts. This concept combines the convenience of absolute position encoding while also representing the relative positional relationships between different tokens. Figure 6 illustrates the mechanism of RoPE, which differs from the original Transformers where the positional embedding and token embedding are summed. RoPE multiplies the position encoding with the query (or key).
▲Figure 6 | RoPE Mechanism Diagram ©️【Deep Blue AI】compiled
Specifically, when performing position encoding on the sequence, unlike standard Transformers, LLaMa’s position encoding applies RoPE to Q and K in each Attention layer, rather than performing position encoding once before the Transformer Block. This means that each time attention is calculated, position encoding must be applied separately to Q and K. For a deeper understanding of RoPE, Su has metaphorically compared RoPE to a type of β-ary encoding.
▲Figure 5 | Mechanism of MHA & GQA & MQA ©️【Deep Blue AI】compiled
■Core 3: Rotary Position Embedding RoPE
Lastly, Mistral is also equipped with RoPE (Rotary Position Embedding) – its core idea is to achieve relative position encoding through absolute position encoding, thus addressing the issue of context disconnection caused by long LLM contexts. This concept combines the convenience of absolute position encoding while also representing the relative positional relationships between different tokens. Figure 6 illustrates the mechanism of RoPE, which differs from the original Transformers where the positional embedding and token embedding are summed. RoPE multiplies the position encoding with the query (or key).
▲Figure 6 | RoPE Mechanism Diagram ©️【Deep Blue AI】compiled
Specifically, when performing position encoding on the sequence, unlike standard Transformers, LLaMa’s position encoding applies RoPE to Q and K in each Attention layer, rather than performing position encoding once before the Transformer Block. This means that each time attention is calculated, position encoding must be applied separately to Q and K. For a deeper understanding of RoPE, Su has metaphorically compared RoPE to a type of β-ary encoding.

Article address for Mistral8 x 7B: https://arxiv.org/pdf/2401.04088.pdf
Figure 7 shows the parameter table of Mixtral-8x7B. Compared to the parameter table of Mistral 7B in Figure 2, two parameters, num_experts and top_k_experts, have been added. This unveils the mystery of Mixtral-8x7B – it combines 8 Mistral 7B models into a MoE expert network (Mixture of Experts), where for different tasks or each token, a router selects the most suitable 2 experts to solve different tasks (details about the MoE network will be introduced in the following text).
▲Figure 7 | Parameters of the Mistral 8x7b model ©️【Deep Blue AI】compiled
The original authors of the paper compared Mixtral-8x7B with the Llama 2 series and the GPT-3.5 base model. Mixtral matched or outperformed Llama 2-70B and GPT-3.5 in most benchmark tests.
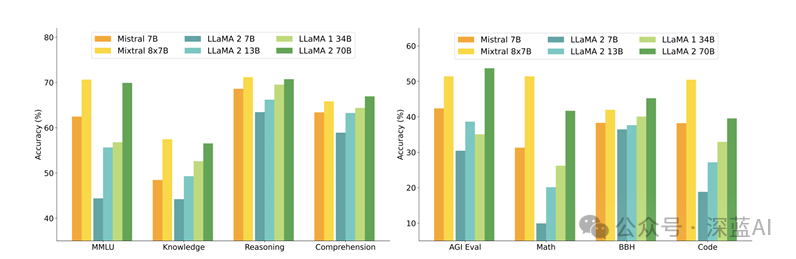
▲Figure 8 | Performance comparison of LLaMA2-70B, GPT-3.5 & Mistral 8x7B on different tasks ©️【Deep Blue AI】compiled
MoE (Mixture-of-Experts) was first proposed in 1991 by Michael Jordan and Geoffrey Hinton in the paper Adaptive Mixtures of Local Experts. Its core idea is that a network model structure has multiple branches, each branch representing an expert. Each expert specializes in a certain area, and when a specific task arises, a gate or router selects which expert(s) to compute, allowing each expert to focus more on a specific field while reducing the interference of different domain data on weight learning. This bears some resemblance to ensemble learning, where the outputs of multiple models are weighted and combined to obtain the final output.
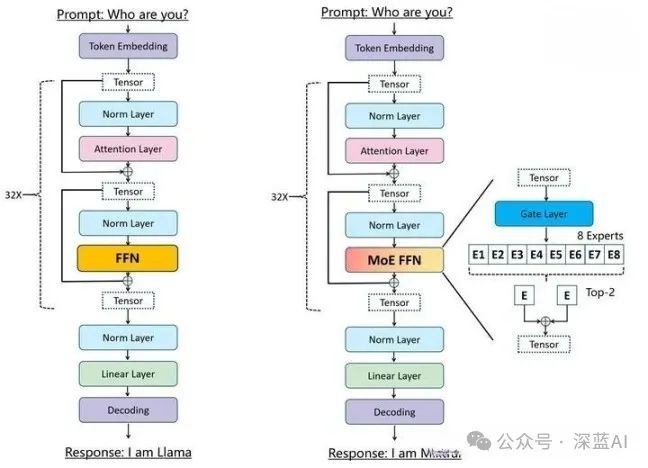 ▲Figure 9 | Transformer architecture in Mixtral-8x7B & LLaMA ©️【Deep Blue AI】compiled
▲Figure 9 | Transformer architecture in Mixtral-8x7B & LLaMA ©️【Deep Blue AI】compiled
Unlike the transformer architecture in LLaMA, as shown in Figure 9, the architecture in Mixtral-8x7B directly replaces the FFN architecture with the MOE FFN architecture. After the tensor from the Norm layer passes through a gate or router (which is essentially a linear layer), it determines the weights of these 8 experts. To save computational resources, we can actively add weight sparsity, simply put, if some experts have small weights g≈0, their outputs do not need to be computed; only those with larger weights are calculated. If the author uses softmax on the Top-K (in Mixtral-8x7B, k = 2) logits of the linear layer, using a lower k value (like one or two) allows for faster training and inference compared to activating many experts. Why not just select the top experts? The initial assumption is that to allow the gate to learn how to route to different experts, it is necessary to route to more than one expert; hence at least two experts need to be selected. Finally, the output is multiplied by the weights and summed to obtain the final output of the MOE FNN.The relevant formula is:
Moreover, it should be noted that although Mixtral-8x7B is an expert network composed of 8 7B models, its parameters are not 8 * 7 = 56 B but rather 46.7B. This is because only the MOE FNN is independently parameterized in each layer; other components, such as attention, are shared among the experts. Therefore, the parameter size is only 46B instead of 56B.

This time, the author mainly introduced the two foundational large models launched by Mistral AI, namely: Mistral -7B and Mistral – 8x7B. Among them, Mistral -7B is benchmarked against LLaMA2, adding the SWA (Sliding Window Attention) mechanism to achieve performance comparable to LLaMA2-13B.
In addition, Mistral – 8x7B, as the first open-source model that can match the performance of GPT-3.5 and LLaMA2-70B, has shocked the audience upon its release and has also provided some “evidence” for the rumors that GPT-4 is based on a MoE architecture. As of the writing of this article, Mistral AI has continued to release the Mistral-Large-2402 open-source version, which is even closer to GPT-4.
I hope the above content helps everyone understand these two large models, and I also look forward to Mistral AI bringing better open-source large models.
[References]
https://blog.csdn.net/v_JULY_v/article/details/135176583
https://zhuanlan.zhihu.com/p/684922663
https://kexue.fm/archives/9675

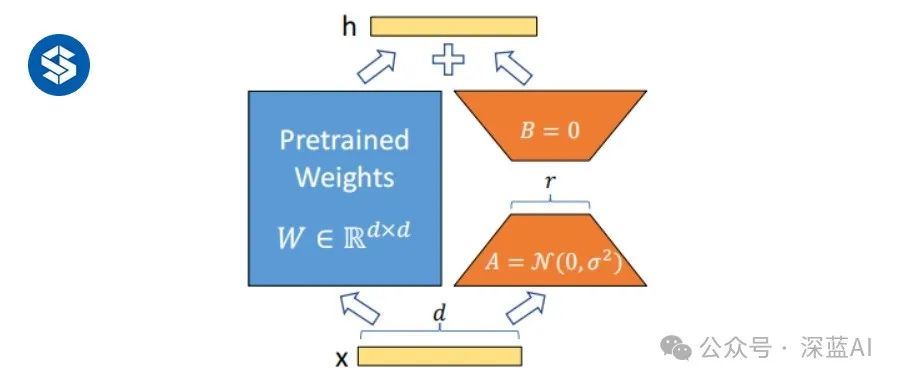
Efficient Fine-tuning Method for Quantized Large Models: QLoRA
2024-04-19
3D-VLA: Bridging the Gap Between 3D Perception and Action Through Embodied Generative World Models
2024-04-09

[Deep Blue AI] is recruiting authors long-term. We welcome anyone who wants to transform their research and technical experiences into writing to share with more people for reading and discussion. If you want to join, please click the tweet below for details👇
Deep Blue Academy’s author team is strongly recruiting! Looking forward to your joining.
[Deep Blue AI]‘s original content is created with the personal effort of the author team. We hope everyone adheres to original rules and cherishes the authors’ hard work. For reprints, please privately message the backend for authorization, and when publishing, be sure to indicate that it comes from[Deep Blue AI]WeChat official account, otherwise legal action will be taken for infringement.
*Click to view, save, and recommend this article*