

Author丨Zhou Peng
Affiliation丨Tencent
Research Direction丨Natural Language Processing, Knowledge Graph


Background
Method
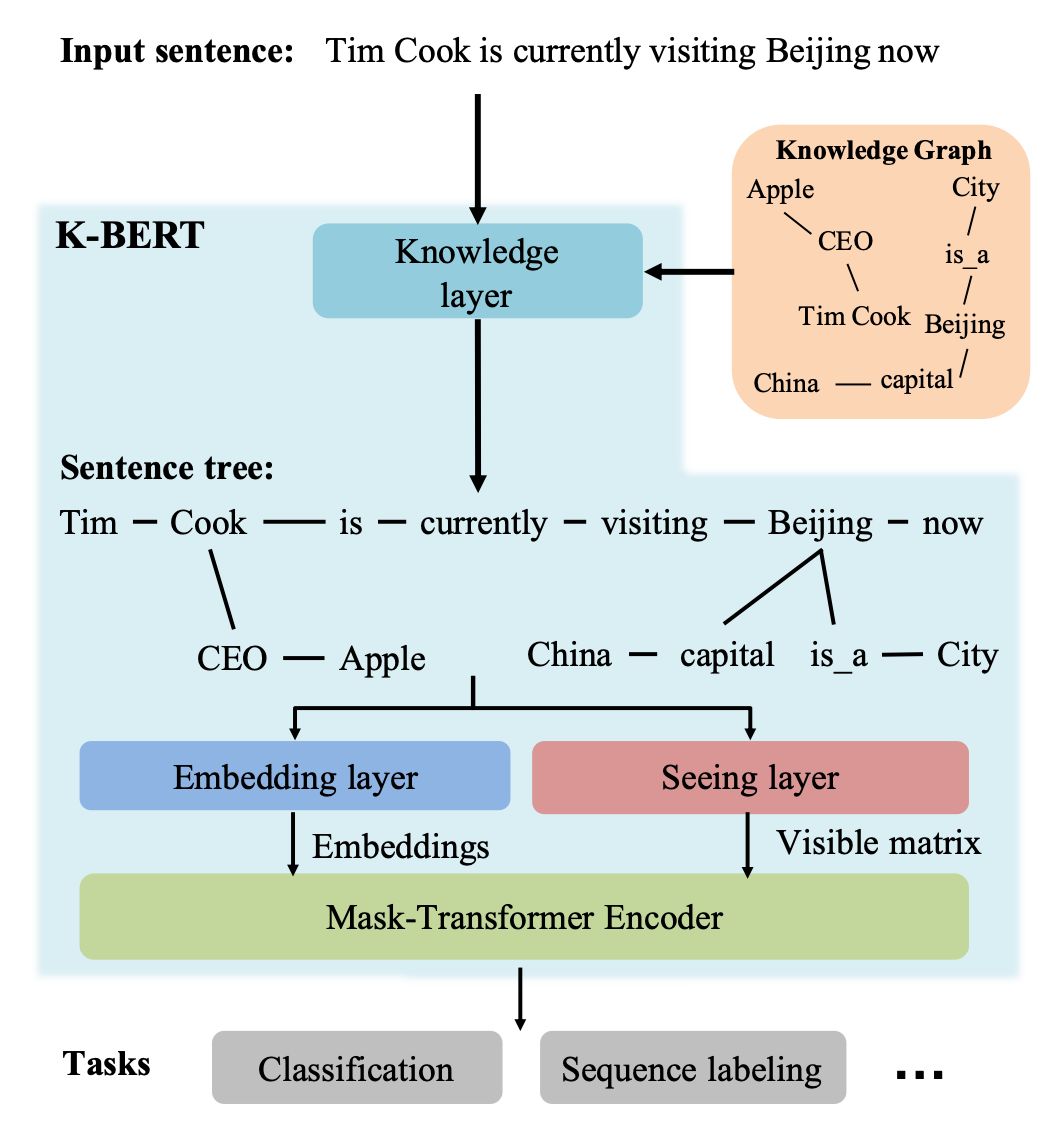
▲ Figure 1. Overall Architecture of K-BERT
After obtaining the sentence tree, a problem arises. Traditional BERT-like models can only process sequential structures of sentence input, while the graph structure of the sentence tree cannot be directly input into the BERT model. If we force the sentence tree to be flattened into a sequence for model input, it will inevitably lead to the loss of structural information. Here, K-BERT proposes a clever solution called soft position and visible matrix. Let’s take a closer look at the specific implementation method.
As we know, before inputting a sentence sequence into BERT, a position encoding is added to each token in the sequence, indicating the position of the token in the sentence, for example, “Tim(0) Cook(1) is(2) currently(3) visiting(4) Beijing(5) now(6)”. Without position encoding, the BERT model has no sequential information, equivalent to a bag-of-words model.
In K-BERT, the sentence tree is first flattened. For example, after flattening the sentence tree in Figure 2, it becomes “[CLS] Tim Cook CEO Apple is currently visiting Beijing capital China is_a City now”.
▲ Figure 2. Soft Position and Hard Position
Clearly, the flattened sentence is messy and hard to read; K-BERT uses soft position encoding to restore the sequential information of the sentence tree, i.e., “[CLS](0) Tim(1) Cook(2) CEO(3) Apple(4) is(3) visiting(4) Beijing(5) capital(6) China(7) is_a(6) City(7) now(6)”, where we can see that the position encoding for “CEO(3)” and “is(3)” is both 3 because they both follow “Cook(2)”.
However, just using soft positions is not enough, as it might lead the model to mistakenly believe that Apple (4) follows is (3), which is incorrect. The biggest highlight of K-BERT lies in the Mask-Transformer, which uses the visible matrix to introduce the structural information from the graph or tree structure into the model.
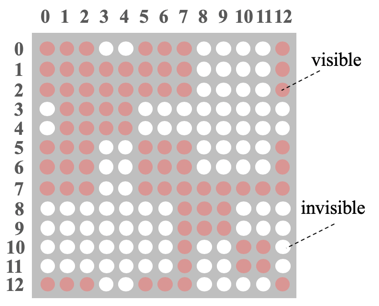
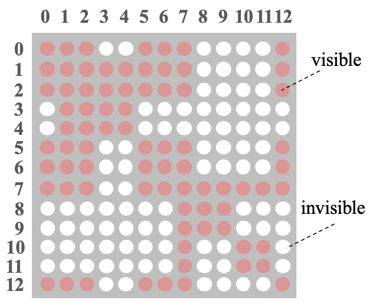
Recalling BERT’s Self-attention, the embedding of a word comes from its context. The core idea of Mask-Transformer is to let the embedding of a word come only from the context of its same branch, while words from different branches do not influence each other. This is achieved through the visible matrix; the visible matrix corresponding to the sentence tree in Figure 2 is shown in Figure 3, where there are a total of 13 tokens, resulting in a 13*13 matrix, with red indicating that the two corresponding tokens are visible to each other, and white indicating that they are not.
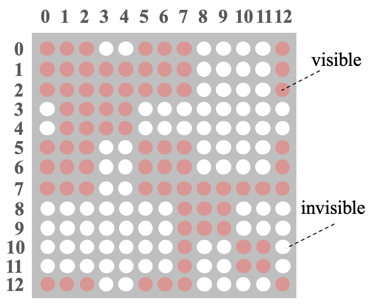
▲ Figure 3. Visible Matrix
Now that we have the visible matrix, how should it be used? It’s quite simple: it’s the Mask-Transformer. For a visible matrix M, the values of the mutually visible red points are set to 0, while the mutually invisible white points are set to negative infinity, and then M is added to the softmax function calculating self-attention, as shown in the following formula.
The above formula is a simple modification of the self-attention in BERT, adding M while the rest remains unchanged. If two words are mutually invisible, their influence coefficient S[i,j] will be 0, meaning there is no influence between their hidden states h. This way, the structural information of the sentence tree is input into BERT.
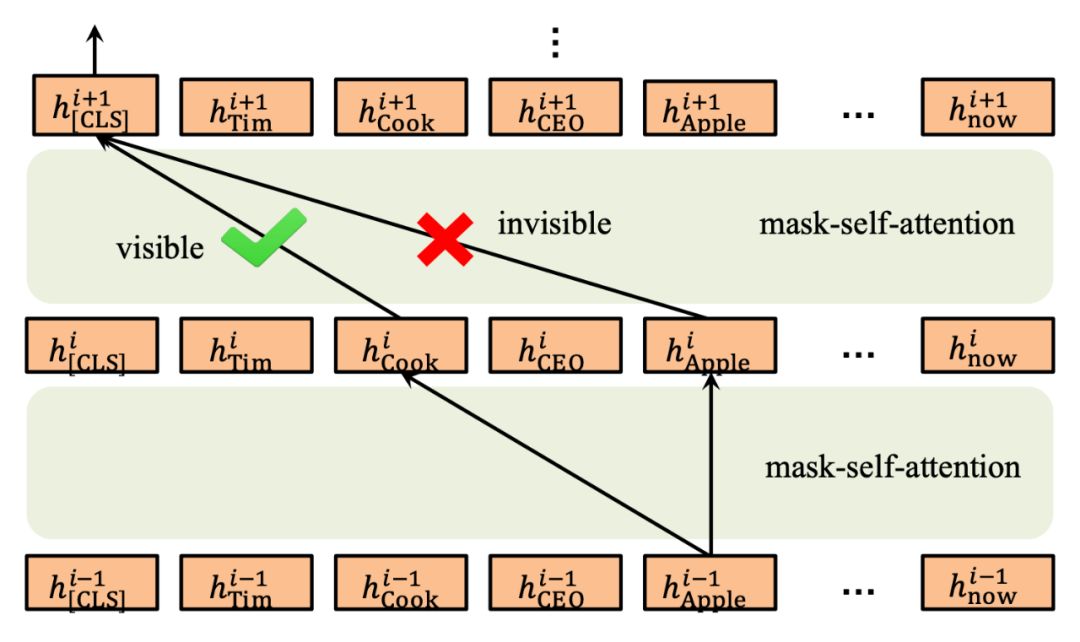
In summary, the process of Mask-Transformer receiving the sentence tree as input is shown in Figure 5.
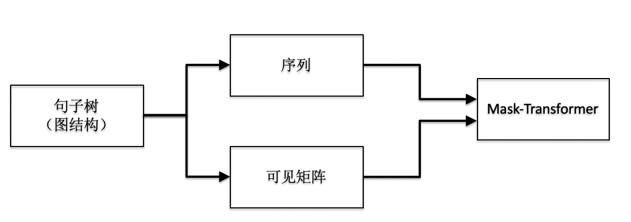
▲ Figure 5. Input Process of Sentence Tree
In fact, it corresponds to the structural diagram in the original paper, as shown in Figure 6, where a sentence tree is represented using a token sequence for content and a visible matrix for structural information.
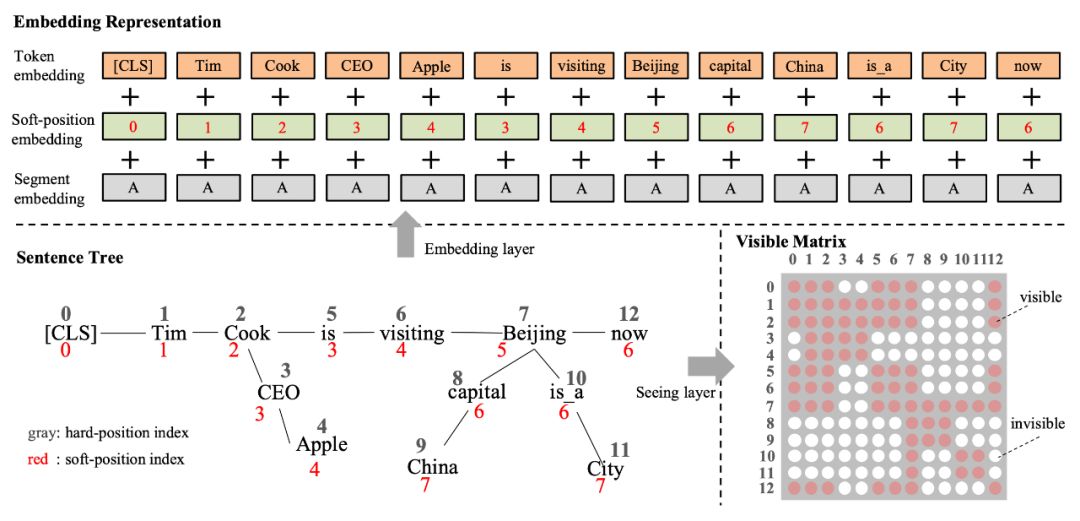
▲ Figure 6. Conversion of Sentence Tree into Embedding Representation and Visible Matrix
As seen in Figure 6, besides the soft positions and visible matrix, the other structures remain consistent with Google BERT, which gives K-BERT a great feature—Compatibility with BERT-like model parameters. K-BERT can directly load publicly available pre-trained BERT models such as Google BERT, Baidu ERNIE, and Facebook RoBERTa without the need for additional pre-training, saving users a significant amount of computational resources.
Experimental Results
Next, let’s look at the experimental results of K-BERT. First, this paper utilized three knowledge graphs: CN-DBpedia, HowNet, and a self-built medical knowledge graph (MedicalKG). The evaluation tasks were divided into two categories: open-domain tasks and specialized domain tasks. There are a total of 8 open-domain tasks, namely Book review, Chnsenticorp, Shopping, Weibo, XNLI, LCQMC, NLPCC-DBQA, and MSRA-NER. The experimental results are shown in the following tables.
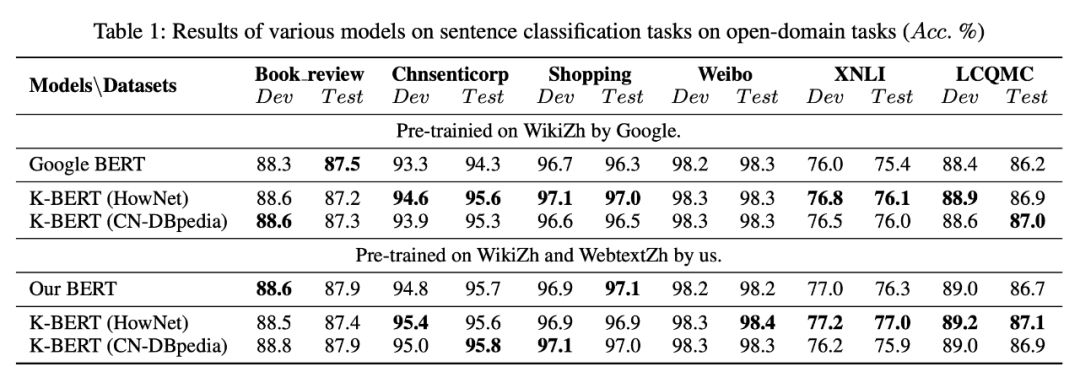
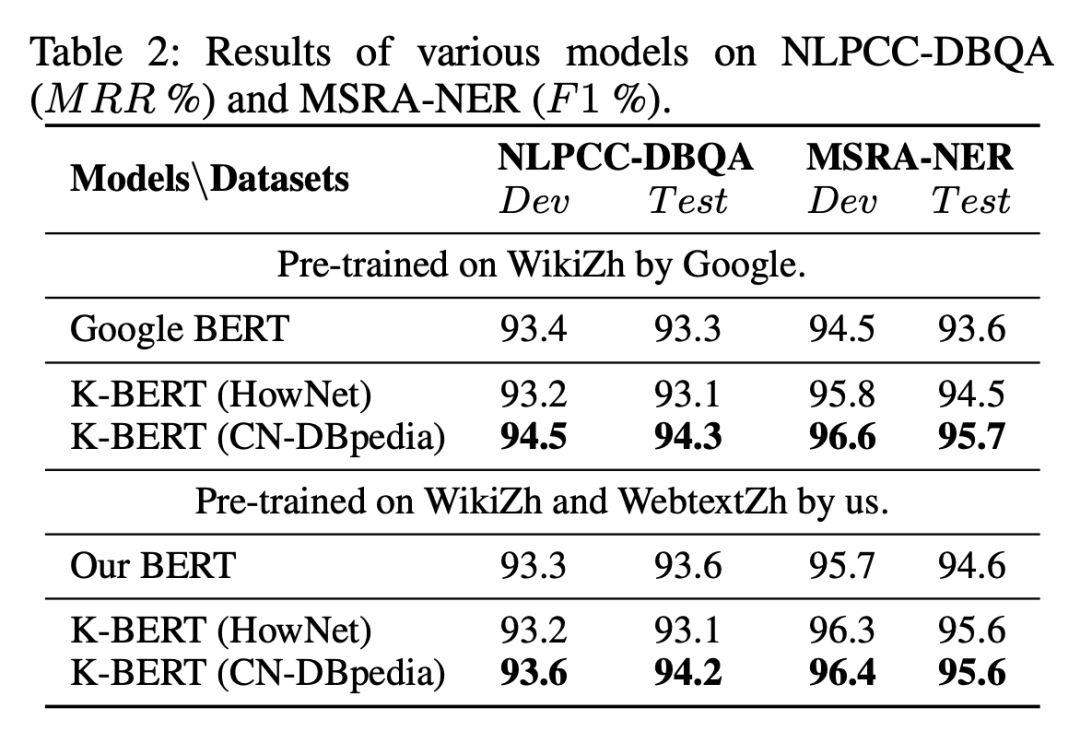
It can be seen that K-BERT has a slight improvement over Google BERT on open-domain tasks, but the enhancement is not significant. The possible reason is that open-domain tasks do not require background knowledge.
To test the effect on tasks requiring “background knowledge,” researchers used four specific domain tasks: financial Q&A, legal Q&A, financial entity recognition, and medical entity recognition. The experimental effects are shown in the figure below.
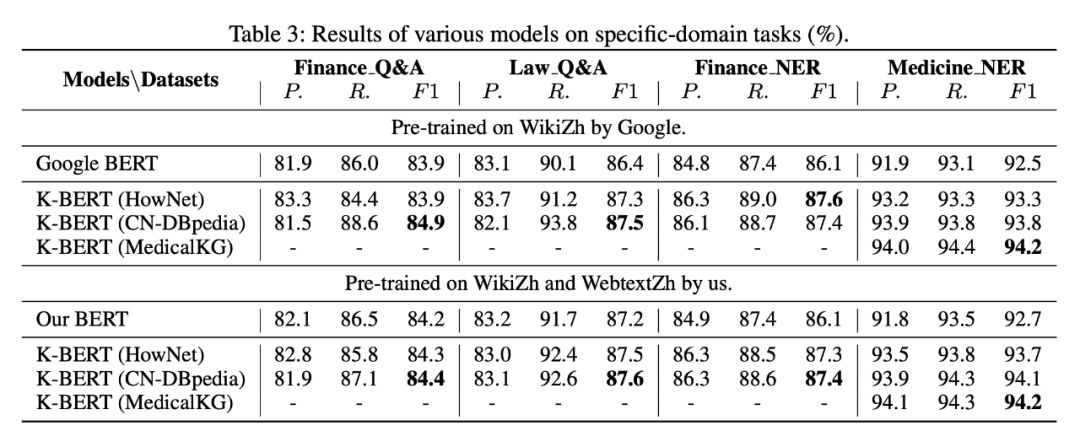
It can be seen that the performance on specific domain tasks is quite good, as these tasks require a high level of background knowledge. Overall, knowledge graphs are suitable for enhancing tasks that require background knowledge, while the effect on open-domain tasks that do not require such knowledge is often not significant.
This work has been included in AAAI-2020. The researchers also pointed out that there are still many issues with K-BERT that need to be resolved, such as how to enhance the model’s robustness when the quality of the knowledge graph is poor, and how to eliminate erroneous associations caused by polysemy during entity linking. The researchers hope to bring structured knowledge graphs into the NLP community, but much effort is still needed. K-BERT is not yet perfect and will continue to be updated in the future; everyone is welcome to follow its progress.
Postscript
References
[1] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[2] Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; and Liu, Q. 2019. ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129.
[3] Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; and Xiao, Y. 2017. CN-DBpedia: A never-ending Chinese knowledge extraction system. International conference industrial, engineering and other applications applied intelligent systems 428–438.
[4] Dong, Z.; Dong, Q.; and Hao, C. 2006. Hownet and the computation of meaning.

Click the title below for more content:
-
AAAI 2020 | Semantically Aware BERT (SemBERT)
-
From Word2Vec to BERT
-
Recent Knowledge Graph Papers Worth Reading, Summarized Here
-
Post-BERT Era NLP Pre-trained Models
-
Does BERT’s Success Depend on Spurious Statistical Cues?
-
Looking at Versatile Self-Attention from Three Major Conference Papers
 #Submission Channel#
#Submission Channel#
Let Your Paper Be Seen by More People
How can more quality content reach readers through shorter paths, reducing the cost of readers seeking quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly may serve as a bridge to facilitate the collision of scholars and academic inspirations from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university labs or individuals to share various quality content on our platform, which can be interpretations of the latest papers, learning experiences, or technical insights. Our only goal is to let knowledge flow.
📝 Submission Standards:
• The manuscript must be an original work by the individual, and the author’s personal information (name + school/work unit + degree/position + research direction) must be indicated.
• If the article is not a first release, please remind us during submission and attach all published links.
• PaperWeekly assumes every article is a first release and will add an “original” label.
📬 Submission Email:
• Submission Email: [email protected]
• All article illustrations should be sent separately as attachments.
• Please leave immediate contact information (WeChat or phone) so we can communicate with the author during editing and publishing.
🔍
Now, you can also find us on 「Zhihu」
Search for 「PaperWeekly」 on the Zhihu homepage
Click 「Follow」 to subscribe to our column
About PaperWeekly
PaperWeekly is an academic platform that recommends, interprets, discusses, and reports on cutting-edge research papers in artificial intelligence. If you are researching or working in the AI field, feel free to click 「Discussion Group」 in the WeChat public account backend, and our assistant will bring you into the PaperWeekly discussion group.

▽ Click | Read the Original Text | Download Paper & Source Code