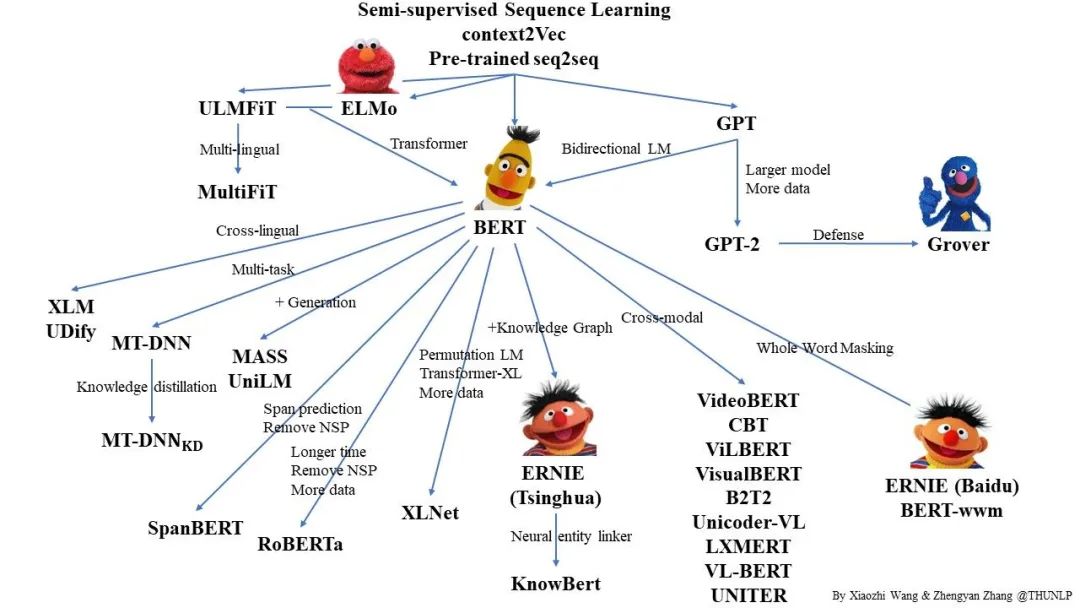
Since BERT was proposed in 2018, it has gained significant success and attention. Based on this, various related models have been proposed in academia to improve BERT. This article attempts to summarize and organize these models.
MT-DNN
MT-DNN (Multi-Task DNN) was proposed by Microsoft in the 2019 paper “Multi-Task Deep Neural Networks for Natural Language Understanding”.The model structure is as follows:The overall model is an MTL (Multi-Task Learning) framework, where the underlying Shared layers reuse BERT’s structure, shared across all tasks, while the top Task-specific layers are unique to individual tasks. Overall, it is not much different from BERT, with the only distinction being in the Pre-training phase where MT-DNN incorporates multi-task training to learn better text representations (as shown in the image).Advantages of MTL:
Tasks with limited labeled data can leverage labeled data from other similar tasks.
Reduces overfitting for specific tasks, acting as a regularization effect.
MT-DNN introduces four different types of tasks and designs corresponding loss functions:Single-Sentence Classification: Uses the output corresponding to [CLS] in the layer, with a loss function of cross-entropy;Text Similarity: Uses the output corresponding to [CLS] in the layer, with a loss function of MSE (modeled as a regression problem);Pairwise Text Classification: Outputs are followed by a SAN (Stochastic Answer Network), with a loss function of cross-entropy;Relevance Ranking: Uses the output corresponding to [CLS] in the layer, with a loss function adopting LTR training paradigm.The Pre-training portion of MT-DNN consists of two phases: In the first phase, BERT’s training method (MLM+NSP) is used to learn the parameters of the Shared layers; in the second phase, MTL is used to learn the parameters of both the Shared layers and Task-specific layers, with the paper employing nine GLUE tasks at this point. Detailed training steps are described as follows:In the paper, the authors used as the initialization for the Shared layers, proving that even without a fine-tuning phase, MT-DNN performs better than .Overall, the improvement of MT-DNN over BERT comes from MTL and a special output module (the output module and loss function design are more complex).
XLNet
XLNet was proposed by CMU and Google in the 2019 paper “XLNet: Generalized Autoregressive Pretraining for Language Understanding”.The paper mentions two pre-training methods: AR (autoregressive language modeling) and AE (denoising autoencoding). The former is represented by ELMo and the GPT series, while the latter is represented by BERT.Both methods have their drawbacks:
AR: Only utilizes information from unidirectional context (either forward or backward).
AE (specifically referring to BERT here): The [MASK] placeholder introduced during the pre-training phase does not exist during the fine-tuning phase; if a single sequence has multiple [MASK] positions, BERT assumes they are independent, which is not true.
To address the issues faced by BERT, XLNet made the following improvements:
The training objective for pre-training was adjusted to PLM (Permutation Language Modeling), implemented using a Two-Stream Self-Attention mechanism and sampling possible permutations.
The model structure employs Transformer-XL, which resolves the Transformer’s unfriendliness towards long documents.
Utilizes higher quality and larger scale corpora.
RoBERTa
RoBERTa was proposed by the University of Washington and Facebook in the 2019 paper “RoBERTa: A Robustly Optimized BERT Pretraining Approach”.Key improvements of RoBERTa include:1. Longer training time: Larger training data (16GB -> 160GB), larger batch size (256 -> 8K);2. Removal of the NSP task, with the input format modified to FULL-SENTENCES;3. Input granularity: Changed from character-level BPE to byte-level BPE;
4. Masking mechanism: Changed from static masking to dynamic masking:
Static masking: Randomly masks during the data preprocessing phase only once, with the masking method unchanged for each data point across epochs;
Dynamic masking: Randomly masks during training, with the masking method varying across epochs.
SpanBERT
SpanBERT was proposed by the University of Washington and Princeton University in the 2019 paper “SpanBERT: Improving Pre-training by Representing and Predicting Spans”.The model structure is as follows:Key improvements of SpanBERT include:1. Span Masking: First, sample the length of the span based on a geometric distribution (resampling if greater than 10), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;2. Span Boundary Objective (SBO): For each token within the span, in addition to the original MLM loss, add the SBO loss, i.e.:3. Single-Sequence Training: Eliminated the NSP task, using a long sentence to replace the original two sentences.
ALBERT
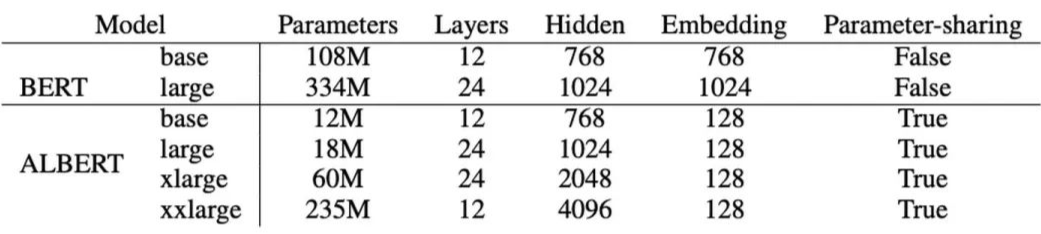
ALBERT was proposed by Google in the 2019 paper “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations”.The starting point of ALBERT is that if the model parameters continue to grow, two types of problems will arise: GPU/TPU OOM; model performance degradation. Based on this, ALBERT considers reducing the model parameters.Key improvements of ALBERT include:1. Factorized embedding parameterization: In previous models, (E is vocabulary embedding size, H is hidden size), this would cause an increase in E when H is increased, leading to a quadratic increase in parameters. ALBERT decouples E and H, adding a matrix after embedding, allowing for an increase in H while keeping E constant. In this case, the parameter count is reduced from to , with more significant effects when is used;2. Cross-layer parameter sharing: Each layer’s parameters in the Transformer Encoder are shared, meaning each layer reuses the same set of parameters;3. Inter-sentence coherence loss: Replaces NSP with SOP (sentence-order prediction), i.e. extracting two consecutive sentences from the same document as positive samples, and swapping their order as negative samples (NSP’s negative samples come from two different documents);4. Utilizes larger training data and removes Dropout (as the authors found the model still did not overfit).The parameter counts of ALBERT and BERT under different configurations are as follows:The performance and training time of ALBERT and BERT under different configurations are as follows:Note that here Speedup refers to training time rather than inference time, as ALBERT’s optimizations mainly focus on reducing parameter counts, which can speed up training, but the number of model layers remains unchanged, so inference time is unaffected.
MASS
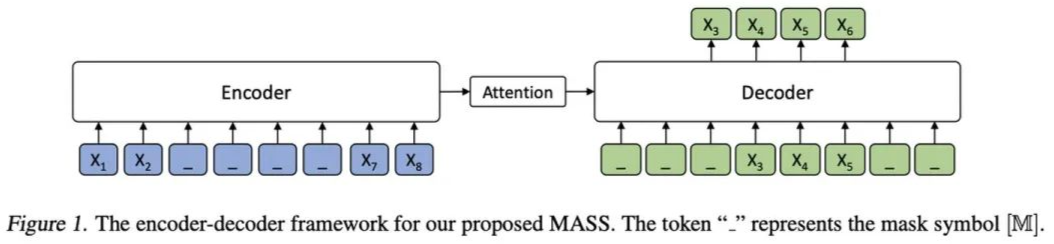
MASS was proposed by Microsoft in the 2019 paper “MASS: Masked Sequence to Sequence Pre-training for Language Generation”.Models like BERT, based on pre-training and fine-tuning, have achieved great success in NLU (Natural Language Understanding) tasks. Conversely, NLG (Natural Language Generation) tasks, such as neural machine translation (NMT), text summarization, and conversational response generation, often face a shortage of training data (paired data).Therefore, pre-training on a large amount of unpaired data followed by fine-tuning on a small amount of paired data is also beneficial for NLU tasks. However, directly adopting a BERT-like pre-training structure (using only encoder or decoder) is not advisable, as NLG tasks typically rely on an encoder-decoder framework. Based on this, the paper proposes a pre-training method suitable for NLG tasks—MASS.Unlike pre-training solely on the encoder or decoder, MASS allows for joint pre-training of both, structured as follows:Overall based on Transformer, the tokens masked in the Encoder are continuous, while the Decoder masks the tokens in the Encoder that are not masked, predicting the tokens that were masked in the Encoder.The paper mentions that by controlling the length k of the masked tokens in the Encoder, BERT and GPT can be seen as special cases of MASS:Pre-training:
Since NMT involves cross-languages, data from four different languages was used, with a language embedding added to each token in the Encoder and Decoder inputs.
In the Encoder, the number of masked tokens is 50% of the sequence length, randomly selecting a starting point, using the masking method similar to BERT (80% replaced with [M], 10% replaced with other random tokens, 10% unchanged).
In the Decoder, the masked tokens are removed, while the positional encoding of the unmasked tokens remains unchanged.
Fine-tuning:
As with conventional Seq2Seq tasks.
UNILM
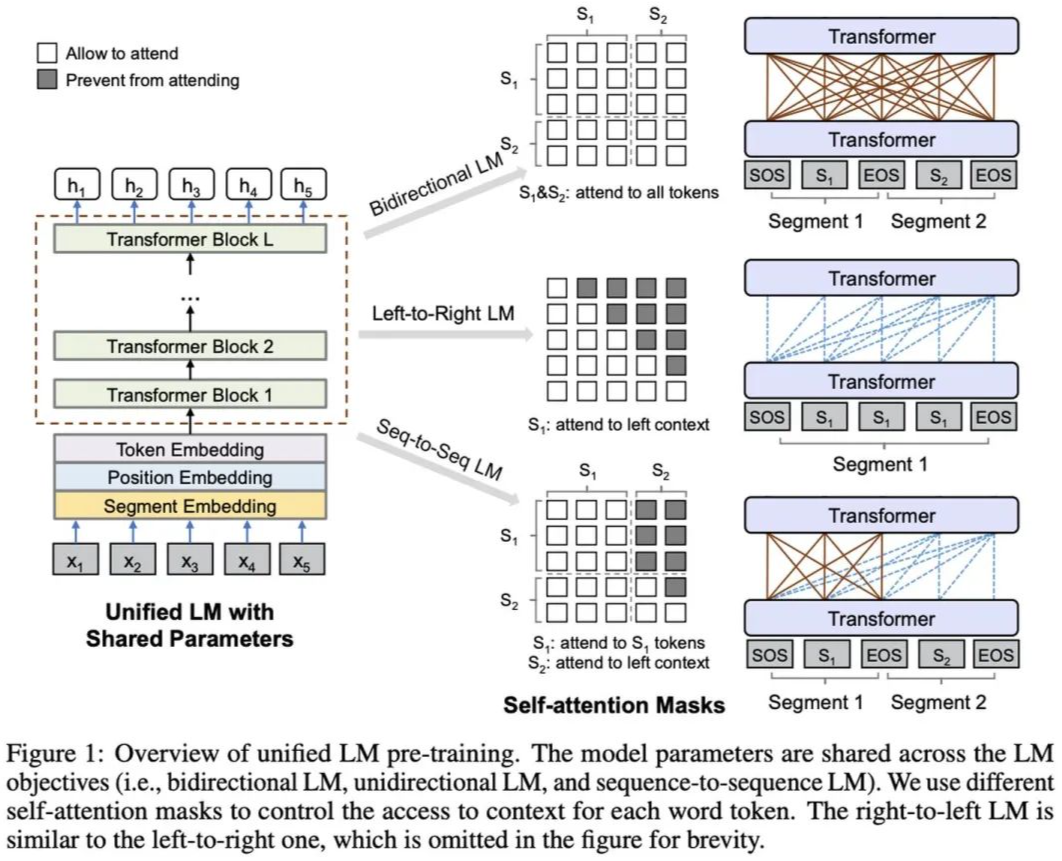
UNILM was proposed by Microsoft in the 2019 paper “Unified Language Model Pre-training for Natural Language Understanding and Generation”.UNILM is a pre-training framework that can be applied simultaneously to NLU and NLG tasks, based on a parameter-sharing Transformer, jointly pre-training three types of unsupervised language modeling objectives: Unidirectional LM (left-to-right & right-to-left), Bidirectional LM, and Sequence-to-Sequence LM. After pre-training, UNILM can be fine-tuned (task-specific layers can be added if necessary) to adapt to different types of downstream tasks.The model structure is as follows:Pre-training:
For different types of LM objectives, different segment embeddings are used for distinction.
For all types of LM objectives, the pre-training task is a cloze task; the distinction is that different LMs can utilize different contexts: For Unidirectional LM, the context is single-sided tokens (left side or right side); for Bidirectional LM, the context is tokens from both sides; for Sequence-to-Sequence LM, the context consists of all tokens from the source sequence and the left-side tokens from the target sequence. Different contexts are achieved through corresponding mask matrices.
For Bidirectional LM, the NSP task is included.
For Sequence-to-Sequence LM, during the pre-training phase, both the source and target sequences can be masked.
In a batch, 1/3 of the time uses Bidirectional LM, 1/3 of the time uses Sequence-to-Sequence LM, 1/6 of the time uses left-to-right Unidirectional LM, and 1/6 of the time uses right-to-left Unidirectional LM.
80% of the time, a token is masked, and 20% of the time, a bigram or trigram is masked.
Fine-tuning:
For NLU tasks, similar to BERT.
For NLG tasks, if it is a Seq2Seq task, only the tokens in the target sequence are masked.
The advantages of UNILM include:
The unified pre-training process allows a single Transformer to use shared parameters and architectures for different types of language models, alleviating the need to separately train and manage multiple language models.
Parameter sharing makes the learned text representations more generalizable, as they are jointly optimized for different language modeling objectives (each utilizing context differently), which mitigates overfitting on any single language model task.
In addition to applications in NLU tasks, UNILM, when used as a Sequence-to-Sequence LM, can naturally be applied to NLG tasks, such as abstractive summarization and question answering.
BART
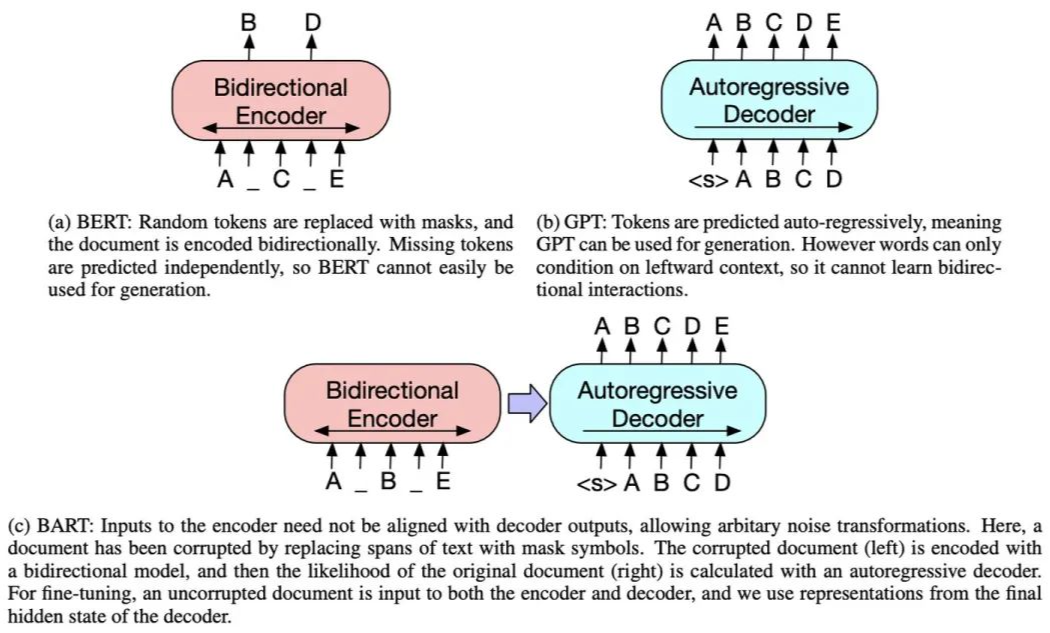
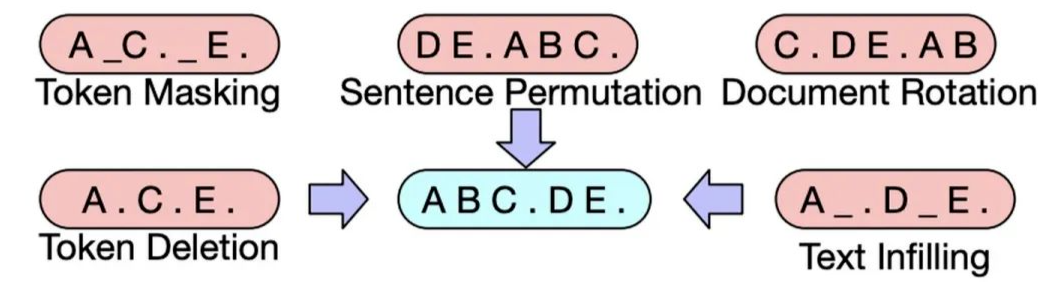
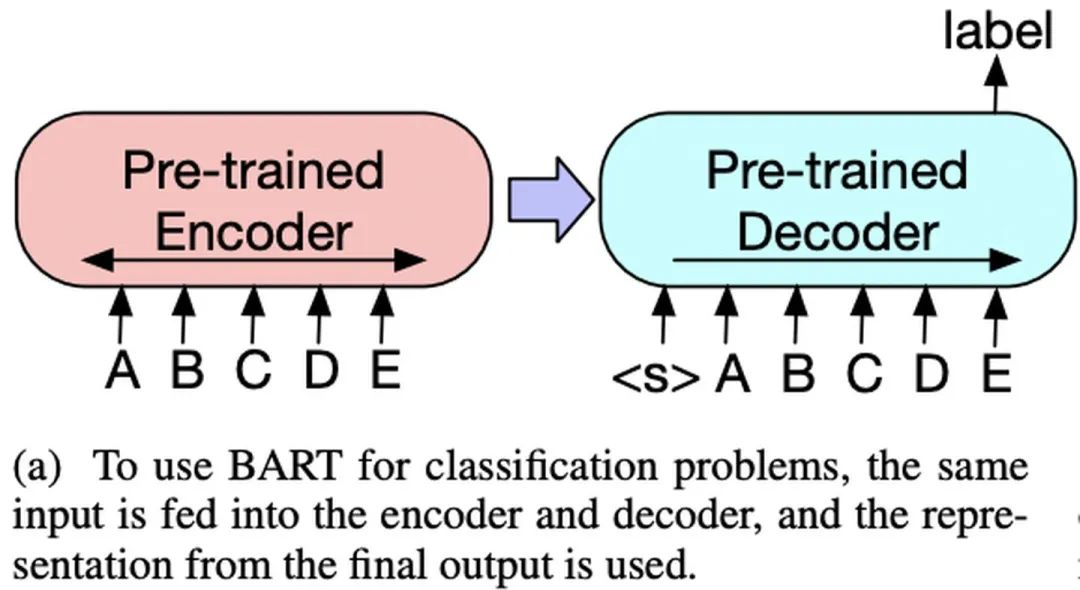
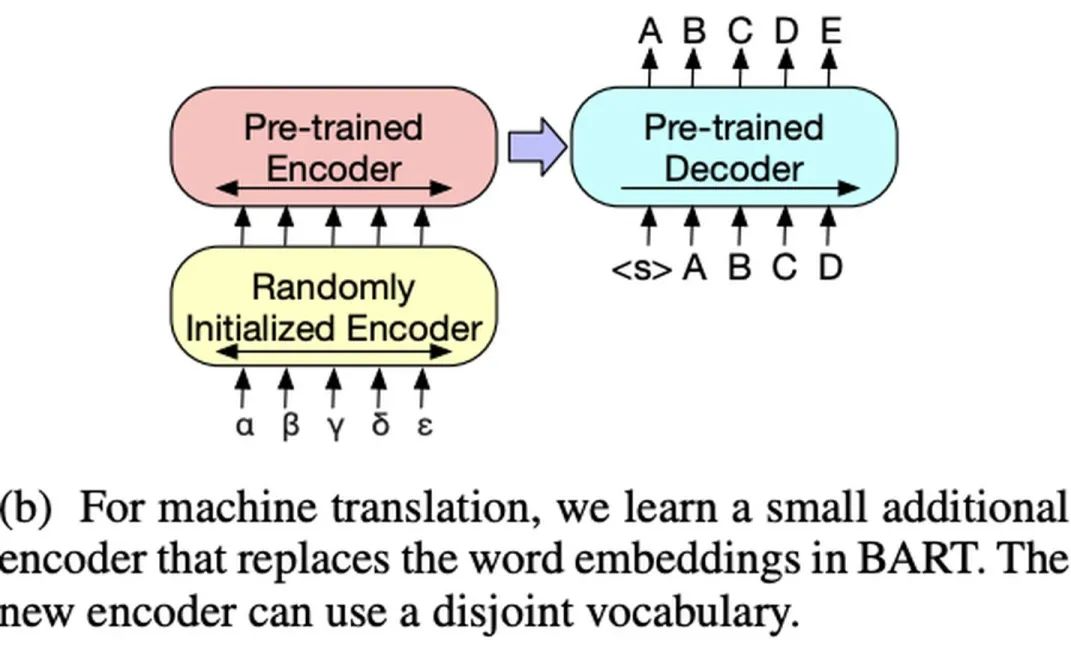
BART was proposed by Facebook in the 2019 paper “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension”.BART adopts the Transformer Seq2Seq framework, similar to MASS, except that its pre-training task is: Inputting corrupted text at the Encoder end and restoring the original text at the Decoder end.The model structure is as follows:There are several ways to corrupt the text (which can be combined):Fine-tuning:
Sequence Classification Tasks:
Token Classification Tasks: Input the complete document into the Encoder and Decoder, using the top hidden state of the Decoder as the representation for each token for classification.
Sequence Generation Tasks: As per conventional Seq2Seq tasks.
Machine Translation: An additional Encoder structure (randomly initialized) is added, serving as a replacement for the embedding layer of the pre-trained Encoder.
How can more quality content reach the audience with a shorter path, reducing the cost of finding quality content for readers? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly may serve as a bridge to facilitate the collision of scholars and academic inspiration from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university laboratories or individuals to share various quality content on our platform, which can be latest paper interpretations, learning insights, or technical materials. Our only goal is to make knowledge truly flow.
📝 Submission Standards:
• Submissions must be original works, and authors must provide personal information (name + school/work unit + degree/position + research direction).
• If the article is not a first release, please remind us during submission and attach all published links.
• PaperWeekly defaults every article to be a first release, and will add an “original” tag.
• All article images should be sent separately in an attachment.
• Please leave an immediate contact method (WeChat or phone) so we can communicate with the author during editing and publishing.
🔍
Now, you can also find us on “Zhihu”
Enter the Zhihu homepage and search for “PaperWeekly”
Click “Follow” to subscribe to our column.
About PaperWeekly
PaperWeekly is an academic platform that recommends, interprets, discusses, and reports cutting-edge research papers in artificial intelligence. If you research or work in the AI field, feel free to click “Group Chat” in the WeChat public account backend, and our assistant will bring you into the PaperWeekly group chat.


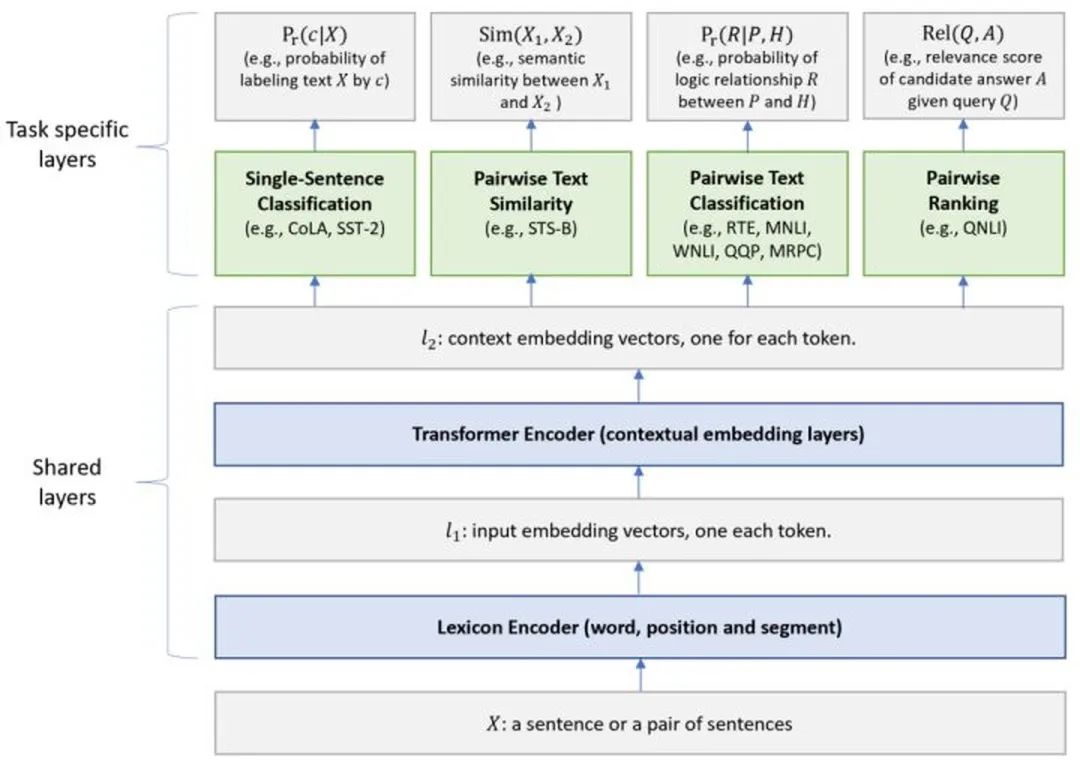
 layer, with a loss function of cross-entropy;
layer, with a loss function of cross-entropy; layer, with a loss function of MSE (modeled as a regression problem);
layer, with a loss function of MSE (modeled as a regression problem); layer, with a loss function adopting LTR training paradigm.
layer, with a loss function adopting LTR training paradigm.
 as the initialization for the Shared layers, proving that even without a fine-tuning phase, MT-DNN performs better than
as the initialization for the Shared layers, proving that even without a fine-tuning phase, MT-DNN performs better than  .
.


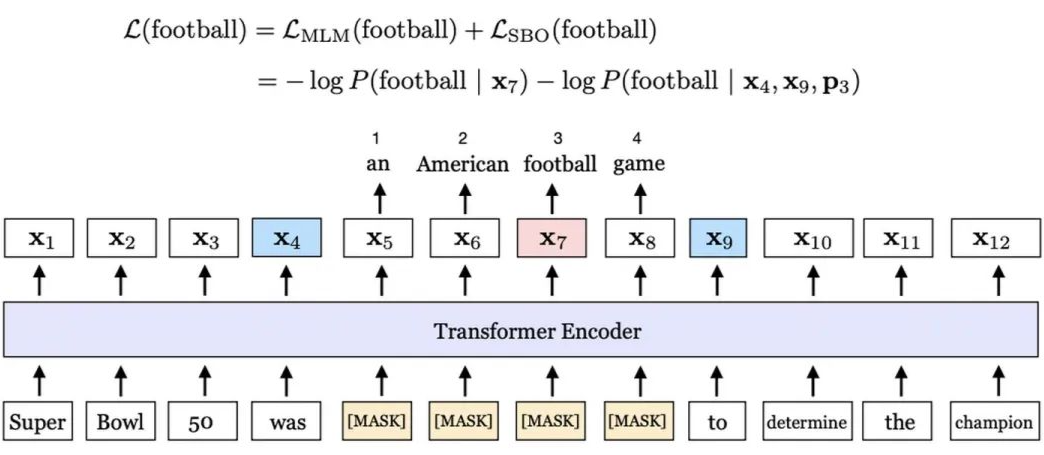
 (resampling if greater than 10), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;
(resampling if greater than 10), then randomly select a starting point based on a uniform distribution, and finally mask the tokens within the span starting from the starting point; note that this process will be repeated until the number of masked tokens reaches a threshold, such as 15% of the input sequence;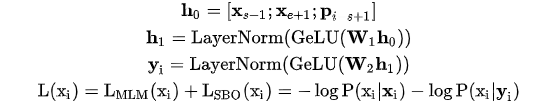

 (E is vocabulary embedding size, H is hidden size), this would cause an increase in E when H is increased, leading to a quadratic increase in parameters. ALBERT decouples E and H, adding a
(E is vocabulary embedding size, H is hidden size), this would cause an increase in E when H is increased, leading to a quadratic increase in parameters. ALBERT decouples E and H, adding a  matrix after embedding, allowing for an increase in H while keeping E constant. In this case, the parameter count is reduced from
matrix after embedding, allowing for an increase in H while keeping E constant. In this case, the parameter count is reduced from  to
to  , with more significant effects when
, with more significant effects when  is used;
is used;