
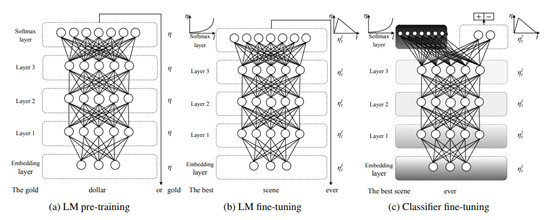
-
Uses an AR model instead of an AE model to mitigate the negative impacts of masking
-
Dual-stream attention mechanism
-
Introduces transformer-xl
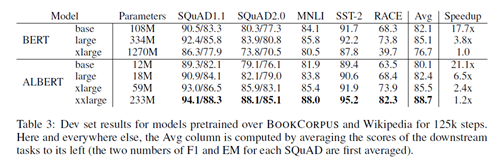
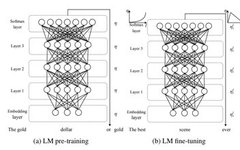
Uses an AR model instead of an AE model to mitigate the negative impacts of masking
Dual-stream attention mechanism
Introduces transformer-xl