
Introduction: The Importance of Exploring Efficient Prompting Methods
In the field of artificial intelligence, large language models (LLMs) have become an important tool for natural language processing (NLP) tasks. As the scale of models continues to expand, how to efficiently utilize these models, especially in resource-constrained situations, has become an urgent problem to solve. Prompting methods as an emerging paradigm can guide models to complete specific tasks through concise instructions, but long and complex prompts often bring additional computational burdens and design challenges. Therefore, researching and developing efficient prompting methods can not only alleviate the pressure on computational resources but also enhance the adaptability and flexibility of the models. This article will explore the research progress of current efficient prompting methods and look forward to future development directions.
Paper Title: Efficient Prompting Methods for Large Language Models: A Survey
Paper Link: https://arxiv.org/pdf/2404.01077.pdf
The Generation, Evolution, and Challenges of Prompting Methods
1. The Generation and Evolution of Prompts: From Manual Design to Automated Optimization:
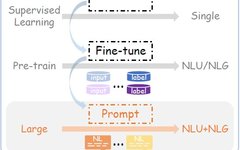
The prompting (Prompting) technology is closely related to the development of pre-trained language models (PLMs) and the advancement of large language models (LLMs). PLMs have evolved from the Transformer architecture to the BERT and GPT series models, improving the efficiency of solving specific tasks through various optimization strategies. Thus, the NLP training paradigm has undergone a transformation from fully supervised learning to pre-training and fine-tuning, and then to pre-training, prompting, and prediction (as shown in the figure below).
GPT-3 was milestone in introducing hard prompts, allowing people to interact with models in natural language without fine-tuning for few-shot learning. ChatGPT further solidified the paradigm of LLMs combined with prompting, integrating the capabilities of natural language understanding (NLU) and natural language generation (NLG), showcasing the significant capabilities of LLMs.
Prompting methods as the mainstream paradigm for adapting to specific NLP tasks have opened the door to contextual learning for LLMs, but they also bring additional computational resources required for model inference and the human effort needed for manually designing prompts, especially when using lengthy and complex prompts to guide and control LLMs’ behavior. Therefore, how to achieve efficient prompting methods has become the focus of research. The transition from relying on manually designed prompts to automated optimization not only reduces the demand for human resources but also enhances the accuracy and computational efficiency of task execution.
2. Hard Prompts and Soft Prompts
The core purpose of prompting is to achieve efficient few-shot learning without cumbersome comprehensive parameter adjustments, avoiding resource waste. The expression of prompts mainly falls into two categories, as shown in the figure below: one is discrete, directly expressed in natural language, which we call “hard prompts”; the other is continuous, learnable vectors, which we call “soft prompts”.
It is necessary to emphasize the diverse variants among hard prompts. Initially, hard prompts included concise task instructions designed for tasks like cloze tests. However, as LLMs’ understanding capabilities have continuously improved, hard prompts have evolved to include a broader range of elements, the most common being examples and reasoning chains. The following figure provides a detailed example of a hard prompt, with highlighted parts representing additional reasoning processes. The growing interest in hard prompts within the NLP community indicates a desire for human-model alignment to achieve artificial general intelligence (AGI).

3. Challenges Faced by Hard Prompts
Hard prompts have been widely used in various downstream tasks, but the more detailed prompts designed to improve task accuracy are often lengthy and complex. This survey reveals two core challenges faced by hard prompts from an efficiency perspective: lengthy prompt content and difficult prompt design, leading to increased memory requirements and decreased inference speed. Therefore, this survey delves into efficient prompting methods in LLMs.
Strategies for Efficient Computational Prompting
1. Knowledge Distillation: Compressing Prompt Content
Knowledge distillation (KD) is a classic compression method whose core idea is to guide a lightweight student model to “imitate” a better-performing, more complex teacher model. In the context of prompt compression, the goal of KD is to compress the natural language information from hard prompts into LLMs through soft prompt adjustments. For example, Askel et al. [1] (as shown in the figure below) successfully compressed a 4600-word HHH (helpful, honest, and harmless) prompt into LLMs using context distillation technology, achieving a more beneficial human-consistent effect compared to ICL.

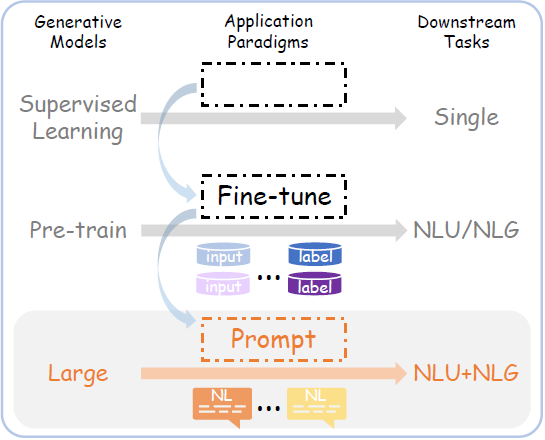
2. Encoding: Converting Text to Vectors
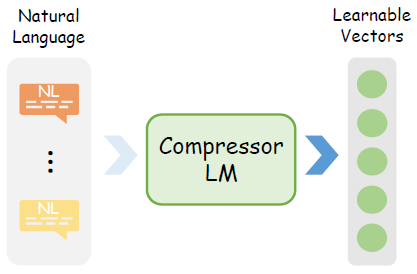
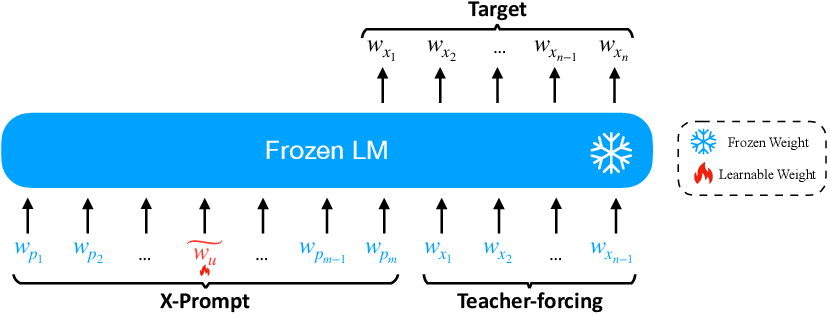
Encoding is the process of converting input text into vectors, and this text-to-vector level compression is referred to as encoding. Current encoding methods fine-tune through cross-entropy objectives, effectively compressing a large amount of information from hard prompts into a concise set of model-accessible vectors, thereby alleviating the efficiency issues brought by lengthy text. For example, Ge et al. [2] proposed extensible prompts (X-Prompt) that can encode styles that cannot be described in natural language into fictional words in an extensible vocabulary. In the figure below, the hypothetical word w̃u mixes with NL tags in X-Prompt to guide its learning. Except for w̃u, all other weights are frozen.
3. Filtering: Simplifying User Prompts
Filtering is text-to-text level compression, involving evaluating the information entropy of different vocabulary structures in prompts and filtering out redundant information as much as possible, ultimately simplifying user prompts. For example, Li et al. [3] utilized the concept of “self-information” to quantify the information amount in prompts and defined three different semantic units (words, phrases, and sentences) as filtering information units through a percentile-based filtering method, where phrase-level filtering was verified to be the most effective information retention method. The filtering results based on the introduction section of https://arxiv.org/abs/2303.07352 are shown in the figure below.

Through these strategies, the shift from manual design to automated optimization not only improves task accuracy and computational efficiency but also provides a theoretical foundation and practical guidance for future research directions.
Methods for Efficient Prompt Design
When designing efficient prompting methods, we can adopt gradient-based optimization methods and evolutionary-based optimization methods. These methods aim to automate the prompt optimization process to reduce the consumption of human resources and improve the task accuracy of LLMs. The workflow is roughly as shown in the figure below.
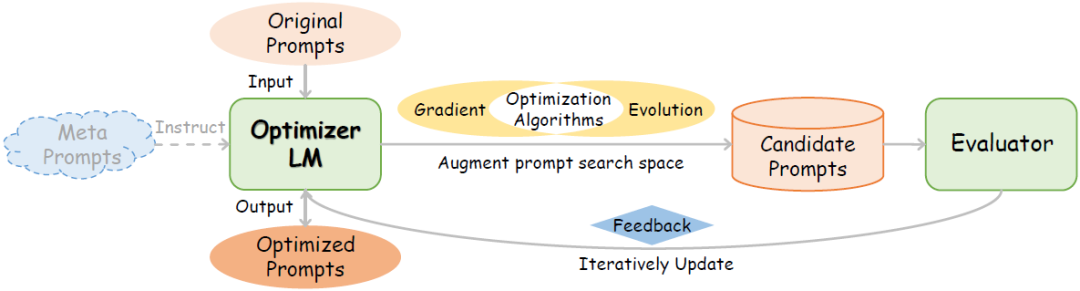
1. Gradient-Based Optimization Methods: Real Gradient Adjustment and Simulated Gradient Prompting
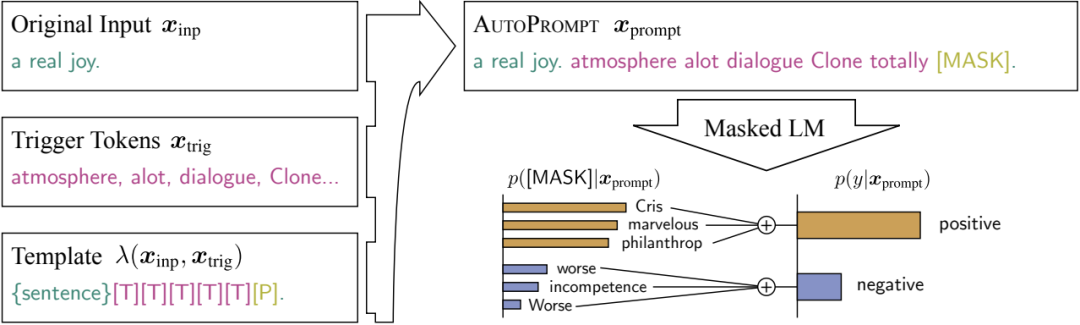
Gradient-based optimization methods mainly include real gradient adjustment and simulated gradient prompting. Real gradient adjustment is suitable for open-source models, allowing direct fine-tuning of model parameters. As shown in the figure below, the AutoPrompt [4] framework automatically selects trigger words through gradient search by constructing a prompt template containing trigger words and mask words, optimizing hard prompts.
For closed-source models, since model parameters cannot be accessed directly, researchers adopt simulated gradient prompting methods. For example, the GrIPS [5] method extends the prompt optimization space through editing operations (deletion, swapping, rewriting, adding) and uses iterative search to find the most effective prompt.

2. Evolutionary-Based Optimization Methods: Utilizing the Principle of Natural Selection
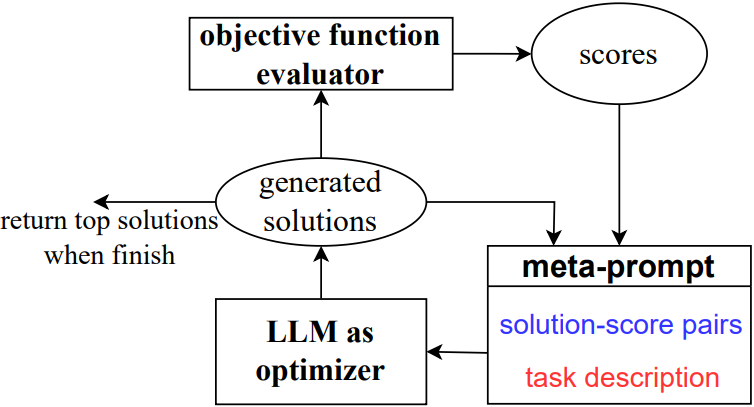
Evolutionary algorithms simulate the biological evolution process of “survival of the fittest” in nature, seeking optimization directions through the utilization of sample diversity and iterative exploration. For instance, the OPRO [6] method integrates the optimization trajectory into meta-prompts, allowing LLMs to understand the commonalities of high-scoring solutions and independently determine the best direction for optimization (as shown in the figure below).
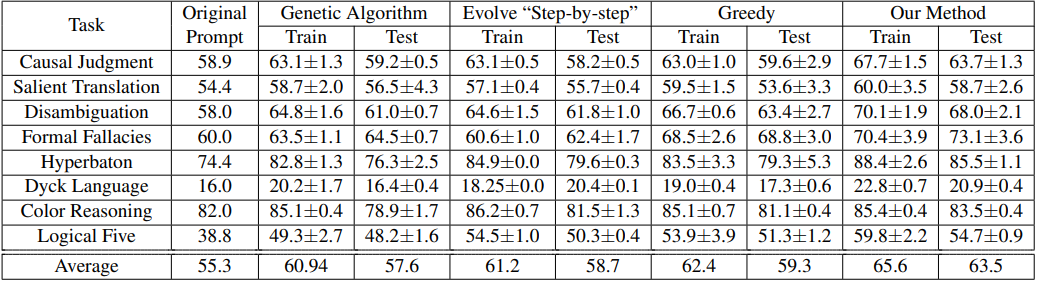
Additionally, the research by Hsieh et al. [7] focuses on the discrete optimization of long prompts by decomposing long prompts into multiple individual sentences and generating semantically similar prompts using the “beam search” algorithm to improve task performance (as shown in the table below).
Future Prompting Methods from a Theoretical Perspective: A Multi-Objective Optimization Problem
From a theoretical perspective, we can abstract efficient prompting methods as a multi-objective optimization problem, aiming to compress prompts to reduce computational complexity (Objective 1) and optimize LLM task accuracy (Objective 2). We define input as X, output as Y, and accessible parameters as Θ. Here, X is discrete, including instructions, examples, and other hard prompt components, while Θ is continuous, including the model’s own accessible parameters and the vector representation of hard prompts.
Future research directions may include:
-
Filtering X: Measuring the amount of natural language information beneficial to LLMs and filtering out redundant information as much as possible.
-
Tuning Θ: When constructing compressors, LLMs should focus on reasonable transformations across different semantic spaces, while smaller LMs should focus on constructing compressed training data.
-
Cooperative Optimization: The simultaneous optimization of hard and soft prompts has not yet emerged, and the integration of two different semantic spaces is worth further exploration, which is an important development direction for human-machine alignment to some extent.
Conclusion: Summarizing the Development and Future Directions of Efficient Prompting Methods
In this article, we reviewed efficient prompting methods for LLMs aimed at enhancing the efficiency and performance of LLMs. We outlined related work in the current field and delved into the intrinsic connections of these methods. From a theoretical perspective, we provided a deep abstraction of these methods and offered a list of open-source projects for practitioners of LLMs for quick reference in research and commercial deployment.
The development of efficient prompting methods has undergone a transition from manually designed prompts to automatically optimized prompts. In the early stages, researchers manually designed prompts to adapt to different tasks, a process that was time-consuming and labor-intensive. Over time, people began to explore gradient descent-based prompt adjustment methods, but these methods were not suitable for closed-source LLMs. Therefore, automated optimization methods based on prompt engineering (PE) have gradually gained attention. These methods typically involve searching for the best “natural language” prompts within a given search space to maximize task accuracy.
Future prompting methods may abstract efficient prompting paradigms as a multi-objective optimization problem aimed at compressing prompts to reduce computational complexity while optimizing LLM task accuracy. We can foresee that future prompt research will focus on hard prompts, as the inaccessibility of LLMs has become an irreversible trend. Future research directions may include filtering out redundant information, fine-tuning the accessible parameters of LLMs, and the cooperative optimization of hard and soft prompts.
References
[1] Amanda Askell, Yuntao Bai, Anna Chen, et al. A general language assistant as a laboratory for alignment. ArXiv preprint, abs/2112.00861, 2021. [2] Tao Ge, Jing Hu, Li Dong, et al. Extensible prompts for language models on zero-shot language style customization. 2022. [3] Yucheng Li, Bo Dong, Chenghua Lin, and Frank Guerin. Compressing context to enhance inference efficiency of large language models. In Conference on Empirical Methods in Natural Language Processing, 2023. [4] Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Eliciting knowledge from language models using automatically generated prompts. ArXiv preprint, abs/2010.15980, 2020. [5] Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. GrIPS: Gradient-free, edit-based instruction search for prompting large language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 3845–3864, Dubrovnik, Croatia, 2023. [6] Chengrun Yang, Xuezhi Wang, Yifeng Lu, et al. Large language models as optimizers. ArXiv preprint, abs/2309.03409, 2023. [7] Cho-Jui Hsieh, Si Si, Felix X. Yu, and Inderjit S. Dhillon. Automatic engineering of long prompts. ArXiv preprint, abs/2311.10117, 2023.

Scan the QR code to add assistant WeChat
About Us
