This article is reproduced from Computer Vision WorkshopSemantic Segmentation PapersSemantic image segmentation is one of the fastest growing fields in computer vision, with a wide range of applications. In many areas, such as robotics and autonomous vehicles, semantic image segmentation is crucial as it provides the necessary context to take action based on pixel-level understanding of the scene.There are several levels of understanding for an image:
- Classification, which categorizes the most representative objects in an image into a class;
- Classification with localization, an extension of the classification task that uses bounding boxes to frame objects in classification;
- Object detection, which classifies and localizes multiple different types of objects;
- Semantic segmentation, which classifies and localizes every pixel in the image;
- Instance segmentation, an extension of semantic segmentation where different objects of the same type are treated as separate objects;
- Panoptic segmentation, which combines semantic segmentation and instance segmentation, assigning a class label to all pixels and independently segmenting all object instances.
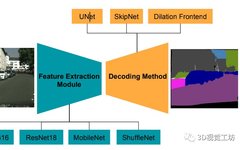
[1] Comparative Study of Real-Time Semantic Segmentation for Autonomous DrivingA Comparative Study of Real-time Semantic Segmentation for Autonomous DrivingThis paper constructs a real-time semantic segmentation framework, providing several example encoders including VGG16, Resnet18, MobileNet, and ShuffleNet, along with decoders including SkipNet, UNet, and dilated front-end. The framework is extensible, allowing for the addition of new encoders and decoders.Classification of semantic segmentation methods:[2] Analysis of Efficient CNN Design Techniques for Semantic SegmentationAnalysis of efficient CNN design techniques for semantic segmentationSimilar to the previous one, both are encoder-decoder structures:Simple Encoder:Handling scale of objectsa) Cross channel filtersb) Cross layer connectionsc) Wider bank of filtersd) Split branching and summation joiningQuantization:Using TensorFlow or Nvidia TensorRT to quantize the float32 computation of the neural network to int8 computation for acceleration, directly training the neural network with int8 computation.Efficient Structure Design Principles1. Balance model size and accuracy by constraining structural hyperparameters: increase network depth, reduce the number of channels input to each convolution layer, decrease the resolution of input images.2. Reduce redundant convolution kernels: kernel decomposition (a 7×7 convolution layer decomposed into three 3×3 convolution layers, a kxk convolution layer decomposed into a 1xk convolution layer and a kx1 convolution layer).3. Calibrate convolution kernels with activation functions (CReLU).Use symmetric calibration convolution kernels (G-CNN).Convolution Design1. 1×1 convolution for dimensionality reduction, reducing the number of input channels for convolution.2. Group convolution.3. Depth-wise Separable convolution.Experimental Results:[3] Real-Time Semantic Image Segmentation via Spatial SparsityReal-time Semantic Image Segmentation via Spatial SparsityFor a typical two-input fully convolutional network, spatial sparsity is introduced, demonstrating that inference speed can be improved without too much loss in accuracy;It shows that by using spatial sparsity, with in-column and cross-column links, and removing residual units, the computational overhead can be reduced by 25 times, sacrificing a bit of accuracy.Three typical methods:Below is the framework proposed in this paper:[4] ENet: A Deep Neural Network Architecture for Real-Time Semantic SegmentationENet: A Deep Neural Network Architecture for Real-Time Semantic SegmentationENet is a segmentation framework designed for mobile devices, its main structure is as shown in the following bottleneck module.Its model architecture is as follows:1. To reduce kernel calls and memory operations, no bias is used in any projections, as cuDNN uses separate kernels for convolution and bias addition. This approach has no impact on accuracy.2. Batch normalization is used between each convolution layer and subsequent non-linear layers.3. In the decoder, max unpooling is used instead of max pooling, and bias-free spatial convolution is used instead of padding.4. In the last upsampling module, pooling indices are not used because the initial block operates on three channels of the input image, while the final output has C feature maps (the number of segmentation object classes).[5] ICNet for Real-Time Semantic Segmentation on High-Resolution ImagesICNet for Real-Time Semantic Segmentation on High-Resolution ImagesICNet uses cascaded image inputs (i.e., low, medium, and high-resolution images), adopting cascaded feature fusion units and using cascaded label supervision during training.ICNet includes three branches:1. A low-resolution branch to obtain semantic information, inputting an image of 1/4 the size of the original into PSPNet, with a downsampling rate of 8, producing feature maps of 1/32 the size of the original image.2. Medium and high-resolution branches for recovering and refining rough predictions, the middle and bottom branches in Figure 2, obtaining high-quality segmentation.3. The high-resolution branch uses lightweight CNNs (green dashed box, bottom and middle branches); the feature maps output from different branches are fused using cascaded feature fusion units, accepting tiered label supervision during training.Cascaded Feature Fusion:[6] Speeding up Semantic Segmentation for Autonomous DrivingSpeeding up Semantic Segmentation for Autonomous DrivingThis architecture includes ELU activation functions, a squeeze-like encoder, subsequent parallel dilated convolutions, and a decoder with a segmentation module similar to sharp mask.The encoder is an improved SqueezeNet architecture designed as a low-latency network for image recognition while maintaining the accuracy of AlexNet.[7] Efficient ConvNet for Real-time Semantic SegmentationEfficient ConvNet for Real-time Semantic SegmentationThe Efficient ConvNet model overall structure follows the encoder-decoder structure.The entire model consists of 23 layers, with layers 1-16 as the Encoder and layers 17-23 as the Decoder.The encoding part includes downsampling processes for layers 1, 2, and 8, as well as feature extraction from the remaining layers. The Non-bt-1D and Downsample constructions are as follows:[8] ERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic SegmentationERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic SegmentationThe REFNet follows the encoder-decoder structure, and its detailed structure is as shown in the table.The entire network contains 23 layers, with layers 1-16 as Encoder and layers 17-23 as Decoder.The downsampler block is inspired by another real-time semantic segmentation network, Enet, and much of the inspiration for this paper also comes from Enet:For example, the initial image input of 1024X512X3, the left side undergoes a 3X3 convolution with a stride of 2, resulting in 16 channels,while the right side undergoes MaxPooling to obtain 3 channels, and after a concat operation, it results in 16 channels, ultimately transforming the image to 512X256X16, and then the Relu activation function is applied to pass to the next layer.The advantage lies in performing the operation to reduce the input image size from the very beginning, as there is a lot of redundancy in the visual information, which saves a lot of computation.[9] Efficient Dense Modules of Asymmetric Convolution for Real-Time Semantic SegmentationEfficient Dense Modules of Asymmetric Convolution for Real-Time Semantic SegmentationThe model framework is as follows:The main modules include Downsampling Block, EDA Block, and the final Projection Layer. The EDA Block includes multiple EDA modules. The structure of the EDA module is as follows:It includes two groups of asymmetric conv, the first group is normal conv, and the second group is dilated conv. This asymmetric conv can reduce the computation by 33% and only brings a slight performance drop.For the design of the network structure, the initial block of ENet is used as the downsampling block, and it is divided into two modes, represented as follows:This downsampling block allows the network to have a larger receptive field for collecting contextual information. In the end, the feature size becomes 1/8 relative to the full-resolution input image, while other networks like SegNet have a feature size of 1/32.[10] ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic SegmentationESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic SegmentationThe principle: The ESP Module is based on the principle of convolution decomposition, decomposing standard convolution into two steps:1) Point-wise convolutions2) Spatial pyramid of dilated convolutionsThe ESP operation is efficient and can be used at different spatial levels of CNNs (mainly relative to ASP).Theoretically, the ESP module is more efficient than Inception and ResNext modules. Additional experimental results indicate that under the same hardware and computational conditions, the ESP module also outperforms the currently best-performing MobileNet and ShuffleNet.The ESP module:Due to the use of dilated convolutions with a large receptive field, the phenomenon of gridding artifacts occurs, as shown in the figure below. This paper proposes using the HFF method to solve this problem by sequentially stacking feature maps starting from the output of the smallest dilated convolution kernel. This approach does not introduce any new parameters, and the computational load does not increase significantly, but it effectively improves the grid effect.[11] ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural NetworkESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural NetworkCompared to the first version, its features are as follows:1) Replacing the point-wise convolutions of the original ESPNet with group point-wise convolutions;2) Replacing the dilated convolutions of the original ESPNet with depth-wise dilated convolution;3) Adding HFF between depth-wise dilated separable convolutions and point-wise (or 1 × 1) convolutions to eliminate gridding artifacts;4) Using group point-wise convolution to replace K point-wise convolutions;5) Adding average pooling to incorporate input image information into EESP;6) Using concatenation instead of element-wise addition operation;Its overall framework is shown in the figure:[12] Concentrated-Comprehensive Convolutions for Lightweight Semantic SegmentationConcentrated-Comprehensive Convolutions for lightweight semantic segmentationThe first stage uses two depth-wise asymmetric convolutions to compress information from neighboring pixels. The second stage utilizes dilated convolutions that are separable in depth, increasing the receptive field. By replacing the traditional ESP module with the proposed CCC module, it reduces half the parameter count and 35% of failure count without decreasing accuracy on the Cityscapes dataset compared to one of the fastest models, ESPnet.Missing localization information in dilated convolutionsThe structure of the Concentrated-Comprehensive Convolutions (CCC) module is as follows:CCC module consists of an information concentration phase and a comprehensive convolution phase. The information concentration phase uses simple convolution kernels to aggregate local feature information. The comprehensive convolution phase enlarges the receptive field to observe larger features, followed by point convolutions that mix channel information. Depth convolutions are applied to dilated convolutions to further reduce parameter size.The structure of the ESP model is as follows:[13] BiSeNet: Bilateral Segmentation Network for Real-time Semantic SegmentationBiSeNet: Bilateral Segmentation Network for Real-time Semantic SegmentationThe starting point of this paper is due to issues in previous works:1. The receptive field is too small 2. Loss of spatial informationAbout Spatial InformationSpatial information mainly refers to local detail information of the image, especially for images rich in edges. Due to the large scale of convolution networks, they generally require smaller input image sizes, necessitating cropping or resizing of the original image, which results in a loss of detailed spatial information. By setting a Spatial Path that contains only three networks, rich spatial information can be preserved, thus integrating low-dimensional spatial detail information with high-dimensional information.Network Framework:The right side is the Feature Fusion Module (FFM):The spatial information captured by the Spatial Path encodes most of the rich detail information, while the output features of the Context Path mainly encode contextual information. The features from the two paths are not the same, so they cannot simply be weighted together; a unique feature fusion module is needed to integrate these features.Experimental Results:[14] Light-Weight RefineNet for Real-Time Semantic SegmentationLight-Weight RefineNet for Real-Time Semantic SegmentationThis paper proposes a lightweight version of RefineNet, called Light-Weight RefineNet, targeting real-time segmentation tasks, improving speed from 20FPS to 55FPS (GPU, 512*512 input, Mean IOU 81.1%, PASCAL VOC test set).Network Structure:The overall network structure of RefineNet is divided into downsampling encoder and upsampling decoder parts. The network mainly consists of 4 modules: RCU, CRP, FUSION, CLF. To lighten the network, RCU-LW, CRP-LW are used.FUSION-LW replaces the original network’s RCU, CRP, FUSION. Through subsequent experiments, the authors found that RCU has a weak effect on improving network accuracy, thus the RCU module was also removed.Why was the RCU module removed with minimal impact on accuracy?Because:(1) Although the 3*3 convolutions in the RCU module give the network a larger receptive field, the shortcut structure allows sharing of low-level and high-level features.(2) The CRP module can also obtain contextual information.It can be seen from the figure below that the RCU module has a weak effect on improving accuracy, while the CRP module significantly improves accuracy.[15] ShelfNet for Real-time Semantic SegmentationShelfNet for Real-time Semantic SegmentationThis article proposes a novel architecture—ShelfNet, utilizing multiple encoder-decoder structures to improve information flow within the network.2. The two convolution layers of the same residual block contribute weights, reducing the parameter count without affecting accuracy;3. Verified on multiple benchmarks.Model Structure:ShelfNet can be seen as a collection of FCNs. Some information flow paths are marked with different colors. Each path corresponds to an FCN (except that there are pooling layers in the ResNet backbone). The equivalence with the FCN collection allows ShelfNet to perform precise segmentation with a small neural network.[16] LadderNet: Multi-Path Networks Based on U-Net for Medical Image SegmentationLadderNet: MULTI-PATH NETWORKS BASED ON U-NET FOR MEDICAL IMAGE SEGMENTATIONModel Structure:1, 3 are the encoder branches, 2, 4 are the decoder branches, A-E are different levels of features. The entire model does not use pooling layers, but replaces them with convolution layers with a stride of 2, doubling the number of channels in the encoder part.It can be seen that this is two U-Nets connected, with two U shapes (12, 34), and the A-D levels between these two U shapes are connected by skip connections. In U-Net networks, the skip connections use fusion, meaning that channel numbers are summed, but here a direct summation mode is used (requiring the channel numbers to be the same).However, increasing more encoder-decoder branches increases parameters, making training difficult, so the authors also adopted Shared-weights residual blocks as shown in the figure.[17] SHUFFLESEG: Real-Time Semantic Segmentation NetworkSHUFFLESEG: REAL-TIME SEMANTIC SEGMENTATION NETWORKThis architecture is divided into two main modules: the encoding module responsible for feature extraction and the decoding module responsible for upsampling within the network to compute the final class probability map.1) A segmentation network based on ShuffleNet (Shufflenet: An extremely efficient convolutional neural network for mobile devices)2) The encoder uses ShuffleNet units, and the decoder integrates the structures of UNet, FCN8s, and Dilation Frontend; fast speed, not much innovation…[18] RTSeg: Real-Time Semantic Segmentation Comparative StudyRTSeg: REAL-TIME SEMANTIC SEGMENTATION COMPARATIVE STUDY1. Provides feature extraction and decoding methods, referred to as meta-architectures;2. Offers a trade-off between computational accuracy and computational efficiency;3. Shufflenet reduces gflops by 143x compared to segment;Model Structure:[19] ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-timeContextNet: Exploring Context and Detail for Semantic Segmentation in Real-timeModel Structure:ContextNet utilizes deeper networks, increasing the number of layers helps learn more complex and abstract features, thus improving accuracy, but also increases runtime. Aggregating contextual information from multiple resolutions is beneficial, combining information from multiple levels to enhance performance.Depth-wise Convolution to Improve Run-time:Depthwise separable convolutions decompose standard convolutions (Conv2d) into depthwise convolutions (DWConv), also known as spatial or channel convolutions, followed by 1×1 point convolution layers. Thus, the calculations of cross-channel and spatial correlations are independent, greatly reducing the number of parameters, resulting in fewer floating-point operations and faster execution time.ContextNet employs DWConv, using bottleneck residual blocks in the input downsampling subnet.Capturing Global and Local Context:ContextNet has two branches, one for full resolution (h×w) and the other for low resolution (e.g., h/4 w/4), where h is the height and w is the width of the input image. Each branch has different responsibilities; the latter captures the global context of the image, while the former provides detail information for higher resolution segmentation.1. To quickly extract features, semantically rich features are only extracted from the lowest possible resolution;2. Local contextual features are separated from the full-resolution input through a very shallow branch, then combined with the low-resolution results.[20] CGNet: A Light-weight Context Guided Network for Semantic SegmentationCGNet: A Light-weight Context Guided Network for Semantic SegmentationThis paper analyzes the intrinsic characteristics of semantic segmentation, proposing to learn joint features of local features and surrounding context, and further improving the joint features of global context through the CG block. Effectively utilizing local feature, surrounding context, and global context. The CG block effectively captures contextual information at various stages.The backbone of CGNet is specifically designed to enhance segmentation accuracy while reducing the number of parameters and saving memory usage. With the same number of parameters, the proposed CGNet significantly outperforms existing segmentation networks (such as ENet and ESPNet).Model Structure:In the CG block, residual learning is introduced in two ways: local residual learning (LRL) and global residual learning (GRL), as shown in the figure:[21] Design of Real-time Semantic Segmentation Decoder for Automated DrivingDesign of Real-time Semantic Segmentation Decoder for Automated DrivingThis paper adopts an encoder-decoder structure, with the encoder being an independent 10-layer VGG.Using stride 2 convolution followed by max-pooling to reduce spatial issues, thus reducing the number of hyperparameters and runtime. Clearly, this is a trade-off for segmentation accuracy, but not so for other tasks like detection and classification. Considering that the encoder is functionally independent, the decoder needs to overcome the gap in exploring spatial information by extensively learning semantic features.The design of the non-bottleneck layer is shown in the figure. It contains both 1D and 3D convolution kernels. The 1D kernel mainly extracts information from one direction at a time, while the 3D kernel primarily collects features from a larger receptive area. Next, different sized kernels are used to search for dense information, such as 3×3, 5×5, and 1×1.Then, the features extracted using different kernels are fused. This method helps summarize the semantic features collected from different receptive areas. The synthesized features are then fused with the input features into the same non-bottleneck layer. In the proposed non-bottleneck layer, multiple skip connections to the feature fusion block help handle high gradient flow, as the incoming gradients are distributed across all paths during backpropagation.We know that making the decoder wider significantly increases runtime. Therefore, regularly reducing the number of feature maps is unaffordable and exceeds the model’s budget.[22] DSNet for Real-Time Driving Scene Semantic SegmentationDSNet: DSNet for Real-Time Driving Scene Semantic SegmentationDSNet is an efficient and powerful unit and asymmetric codec architecture. It adopts a mixed dilated convolution scheme to overcome the gridding problem.Detailed structure of DSNet is shown in the table:[23] Fast-SCNN: Fast Semantic Segmentation NetworkFast-SCNN: Fast Semantic Segmentation NetworkIt is known that a larger receptive field in semantic segmentation is important for learning complex associations between target classes (i.e., global context), while spatial details in images are necessary to maintain target boundaries, requiring specific designs to balance speed and accuracy (rather than relocating classification DCNNs).Model Framework:Two-branch network, which uses a deeper branch at low resolution to capture environmental information, and a shallower branch at high resolution to learn detail information. Then, these two are fused to form the final semantic segmentation result.The main contributions of this paper:1) A real-time semantic segmentation algorithm Fast-SCNN is proposed, achieving an accuracy of 68% on high-definition images at a speed of 123.5 frames per second;2) The skip connection is adjusted, and a shallow learning to downsample module is proposed to quickly and efficiently extract low-level features through multi-branch;3) A low capacity Fast-SCNN is designed, which for small capacity networks, the effect of training for several more epochs is the same as pre-training on ImageNet.Previous pyramid pooling modules in PSPNet and atrous spatial pyramid pooling (ASPP) in DeepLab are used to encode and utilize global information. Similar to object detection, speed is an important factor in the design of semantic segmentation systems. Based on FCN, SegNet introduced a joint encoder-decoder model, one of the earliest high-efficiency segmentation models. Continuing SegNet, ENet also designed an encoder-decoder with fewer layers, reducing computational costs.Then, two-branch and multi-branch systems appeared. ICNet, ContextNet, BiSeNet, GUN learn global information on low-resolution input through a deeper branch, while learning detail information on high-resolution images through a shallower branch. However, SOTA semantic segmentation remains challenging, often requiring high-performance GPUs. Inspired by the two-branch approach, Fast-SCNN incorporates a shared shallow network to encode detail information, efficiently learning global information on low-resolution inputs.The detailed network is shown in the table:[24] An Efficient Solution for Semantic Segmentation: ShuffleNet V2 with Atrous Separable ConvolutionsAn efficient solution for semantic segmentation: ShuffleNet V2 with atrous separable convolutionsThe four starting points designed in this paper:
1. When channel widths are not equal, the memory access cost (MAC) increases, so channel widths should remain equal.
2. When improving MAC, excessive use of group convolutions should be avoided.
3. To maintain high parallelism, network fragmentation should be avoided.
4. Element-wise operations such as ReLU, Add, AddBias should not be ignored and should be minimized.
Contributions of this paper:1) Achieved SOT computational efficiency on semantic segmentation tasks using ShuffleNetV2, DPC encoder, and a brand new decoding module, reaching 70.33% mIoU on the Cityscapes test dataset;2) The proposed model and implementation are fully compatible with TensorFlow Lite, capable of running in real-time on Android and iOS mobile platforms;3) The TensorFlow network implementation and training model are open-source.The model structure is as shown in the figure above, using the ShufflenetV2 framework to extract features, then connecting to the DeepLabV3 encoder, and finally using bilinear scaling as the new decoder to generate segmentation masks. The design and modification of the network were choices validated on the ImageNet dataset.After feature extraction, a 1×1 convolution layer is used for dimensionality reduction, followed by a Dropout layer, bilinear scaling, and finally classification via ArgMax. The decoding part adopts a simple bilinear scaling operation to scale the feature map to the original image size.The detailed structure of the model is shown in the table:This article is for academic sharing only. If there is any infringement, please contact to delete the article.END