
Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/339123850
Author | Ma Dong Shen Me
Editor | Machine Learning Algorithms and Natural Language Processing WeChat Public Account
This article is for academic sharing only. If there is any infringement, please contact us to delete it.
1. Why are there so many methods to compute similarity in attention?

The above image lists two classic styles of attention types and their corresponding similarity computation methods. Different similarities are designed based on different tasks. To put it simply, if an author of a paper finds that a certain type of similarity calculation works better for a specific type of task, we can adopt their approach when handling similar tasks later. However, whether it is truly suitable and the effectiveness must be tested ourselves.
2. Can we directly calculate similarity scores on embeddings?
Some attention mechanisms I have seen, aside from self-attention, use RNN or CNN structures to process text problems. They typically obtain a mapped vector V after embedding and passing through the RNN or CNN structure, and the attention is calculated based on V. The question arises: can we directly compute scores on embeddings?
This can be seen in attention word embedding:
https://zhuanlan.zhihu.com/p/161999947
Unfortunately, here the embedding undergoes a dense layer mapping before proceeding, which is very similar to self-attention. It shows that if RNN or CNN structures are not used, DNN structures will also be employed for mapping…
3. Following the second point, why do we need to perform dense layer mapping on embeddings before computing attention in self-attention? Why can’t we directly compute attention on embeddings???
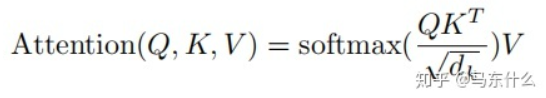
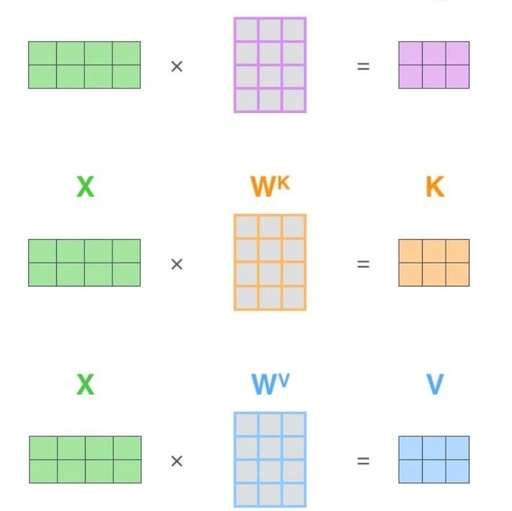
In this formula, q, v, and k come from embeddings but are not embeddings; they are derived from three dense layers to obtain q, v, k.
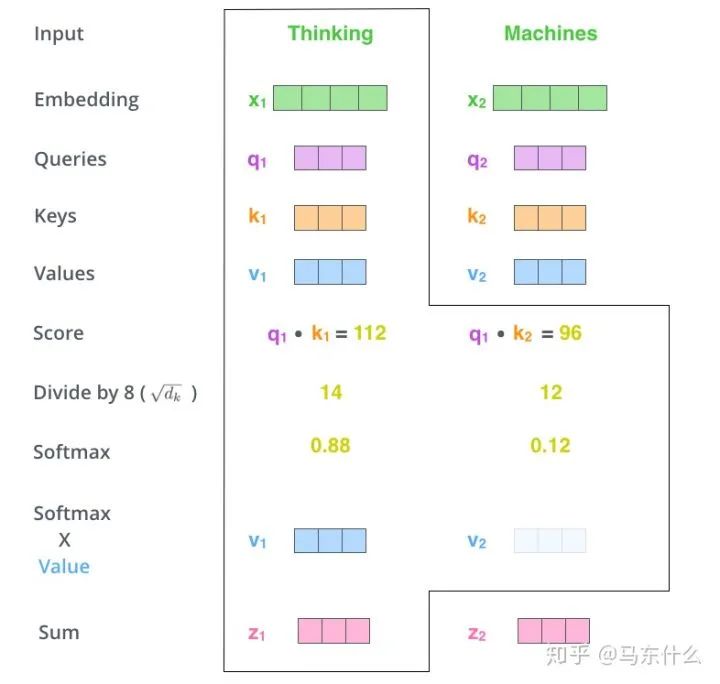
Note here that x to q, v, k is as follows:
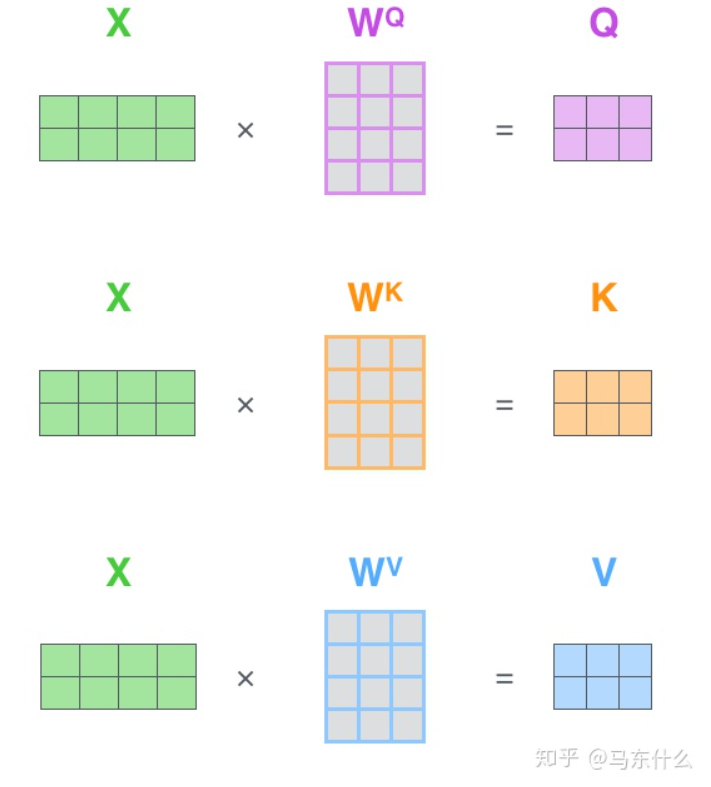
Why are there three matrices for wq, wk, wv???
Regarding the function of these three projection layers (as referred to in the paper):
1.
https://ai.stackexchange.com/questions/23332/what-is-the-weight-matrix-in-self-attention
For the multi-head mechanism, if these three mapping layers are not used, the input parts of each multi-head would be identical. By using these three mapping layers, each head in the multi-head corresponds to different wq, wk, wv matrices, which helps enhance the diversity of feature extraction within the model.
2.
https://jalammar.github.io/illustrated-transformer/
From this brilliant article:
The first step in computing self-attention is to create three vectors from each encoder’s input vector (in this case, each word’s embedding). Thus, for each word, we create a query vector, a key vector, and a value vector. By multiplying the embedding by the three matrices we train during the training process, we can create these vectors. Note that the dimensions of these new vectors are smaller than those of the embedding vector. They are dimensioned at 64, while the embedding and encoder input/output vectors are dimensioned at 512. They do not have to be smaller; this is an architectural choice that keeps most of the multi-head attention calculations constant.
By mapping through dense layers, we can flexibly control the sizes of q, v, k, which can also serve as a dimensionality reduction effect (for example, here converting a 512 embedding into 64-dimensional q, v, k).
3.
http://peterbloem.nl/blog/transformers
Every input vector i is used in three different ways in the self-attention operation:
-
It is compared to every other vector to establish the weights for its own output i
-
It is compared to every other vector to establish the weights for the output of the j-th vector j
-
It is used as part of the weighted sum to compute each output vector once the weights have been established.
In self-attention, each input vector is used in three different ways:
1. It is compared to all other vectors to establish weights for its own output i, corresponding to the query.
2. It is compared to all other vectors to establish weights for the j-th vector j, corresponding to the key.
3. Once weights are established, it is used as part of the weighted sum to compute each output vector, corresponding to the value.
These roles are often called the query, the key, and the value (we’ll explain where these names come from later). In the basic self-attention we’ve seen so far, each input vector must play all three roles. We make its life a little easier by deriving new vectors for each role by applying a linear transformation to the original input vector. In other words, we add three k×k weight matrices q, k, v and compute three linear transformations of each xi, for the three different parts of self-attention.
These roles are often referred to as query, key, and value. So far in basic self-attention, each input vector must play all three roles, and we create three new vectors corresponding to the three roles by applying linear transformations to the original input vector. In other words, for the three different parts of self-attention, we add three weight matrices q, k, v and compute three linear transformations of each xi:
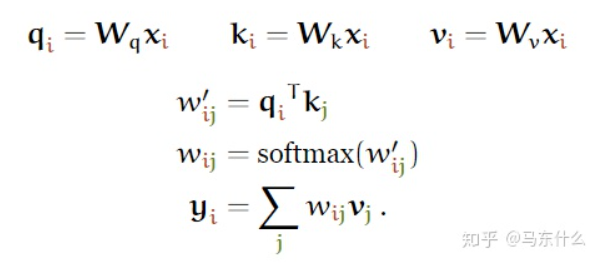
This gives the self-attention layer some controllable parameters and allows it to modify the incoming vectors to suit the three roles they must play.
This provides the self-attention layer with controllable parameters and allows it to modify the incoming vectors to fit the three roles they must play.
4.
https://medium.com/lsc-psd/introduction-of-self-attention-layer-in-transformer-fc7bff63f3bc
For every inputx, the words inxare embedded into vectoraas Self-Attention input.
This part was also discussed with experts, and a reasonable answer was obtained:
When a word acts as a query, key, and value, it should have different representations. If q, v, k are not used, a word would be identical as both query and key, which is counterintuitive. The original embedding space reflects semantic relationships, where semantically similar words are close together, and a word overlaps with itself. After transforming through qvk, it moves to a new space for dot product calculations. This new space focuses more on learning attention. It is also possible to perform dot products in the original embedding space, but this assumes that semantically similar words have higher attention, and the original embedding would yield strong attention results when compared with itself, which would weaken the attention relevance with other related positions. However, if transformed to a new space, semantic similarity does not necessarily imply high attention; (in the embedding space, it reflects semantic similarity, and self-dot product will certainly have the highest similarity. The purpose of setting qvk is to create a new space specifically for learning the attention mechanism. In this space, a high dot product indicates high attention, but does not mean high semantic similarity. This strengthens the attention mechanism’s calculation results for other contexts.)
5.

The original text did not provide detailed explanations for q, v, k, just stating that they did it and achieved great results… It’s quite unreasonable, haha.
4. Self-attention seems to resemble using DNN for attention.
Like attention-based models, the current open-source materials generally use RNN or CNN as components to extract features from the original embedding to obtain certain representations, such as the hidden state of RNN or the high-order features extracted after convolution calculations of CNN. Attention calculations are performed on these high-level representations. In contrast, self-attention uses simple dense layers to map the original embedding to new representations, and then performs attention calculations on this new representation, which formally resembles using DNN to assist in attention.
Download 1: Four Essentials
Reply "Four Essentials" in the backend of the Machine Learning Algorithms and Natural Language Processing WeChat public account to obtain learning materials for TensorFlow, Pytorch, Machine Learning, and Deep Learning!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing WeChat public account to obtain 195 NAACL papers + 295 ACL 2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Machine Learning Algorithms and Natural Language Processing discussion group has officially been established!
There are abundant resources in the group, welcome everyone to join and learn!
Extra benefits! Resources on Deep Learning and Neural Networks, official Chinese tutorials for Pytorch, Python for Data Analysis, Machine Learning notes, official Chinese documentation for Pandas, Effective Java (Chinese version), and 20 other welfare resources.
How to obtain: After entering the group, click on the group announcement to get the download link. Please modify the remark to [School/Company + Name + Direction] when adding.
For example - HIT + Zhang San + Dialogue System.
Please avoid adding if you are a business owner or WeChat reseller. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Summary of Network Structure Design and Modality Fusion Methods
Awesome Adversarial Machine Learning Resource List