

Source | Zhihu
Link | https://zhuanlan.zhihu.com/p/78850152
Author | Ailuo Yue
Editor | Machine Learning Algorithms and Natural Language Processing WeChat Official Account
This article is for academic sharing only. If there is any infringement, please contact us for removal.
1 Why Propose the Attention Mechanism

The paper link is as follows
Neural Machine Translation by Jointly Learning to Align and Translatearxiv.org
Here I will briefly explain the meaning of this passage: The authors speculate that the bottleneck for improving the performance of the basic encoder-decoder model is the use of a fixed-length vector C in the encoder-decoder model.
The biggest flaw of the basic seq2seq model is that the only connection between the encoder and decoder is a fixed-length semantic vector C. This means that the encoder has to compress the information of the entire sequence into a fixed-length vector.
This approach has two drawbacks: first, the semantic vector cannot fully represent the information of the entire sequence. For example, in machine translation, if the sentence to be translated is relatively long, the fixed-length vector C may not be able to hold that much information. Secondly, the information carried by earlier inputs may be diluted or overwritten by later inputs. The longer the input sequence, the more severe this phenomenon becomes. As a result, if the decoder does not obtain sufficient information from the input sequence at the beginning, the accuracy of decoding will naturally be compromised.
To improve the basic seq2seq model, the authors proposed the attention mechanism. The basic seq2seq model is introduced here; if unclear, you can refer to it.
Ailuo Yue: Analyzing the Principles of Seq2seq + Implementation in TensorFlowzhuanlan.zhihu.com
2 Analysis of the Attention Mechanism
Attention is a mechanism that forces the model to learn to focus on specific parts of the input sequence during decoding, rather than relying solely on the hidden vector C of the decoder’s LSTM.
The core idea of attention: on each step of the decoder, use a direct connection to the encoder to focus on a particular part of the source sequence.
The following images are from Stanford CS224n course materials.
https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture08-nmt.pdfweb.stanford.edu
① Get attention score
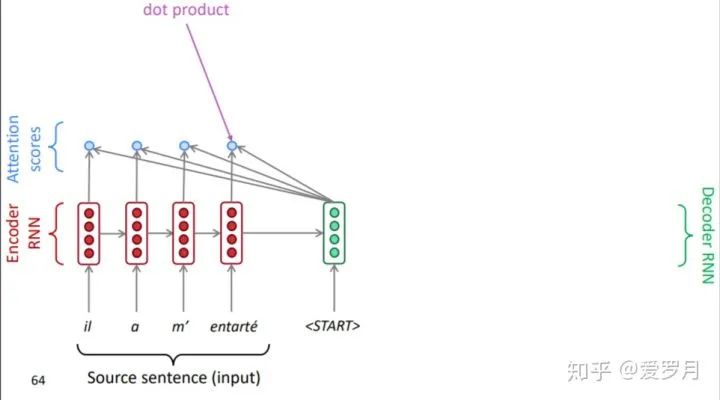

On timestep t of the decoder, we can get the attention score for this step. That is
. The choice of the function
is varied, but generally, the most commonly used is one of the following.
I am a bit lazy, so I will borrow this formula from others. Just look at
and
correspondingly.
Note: The formula images are sourced from
Yuanche.Sh: A Comprehensive Diagram of Seq2Seq Attention Modelzhuanlan.zhihu.com
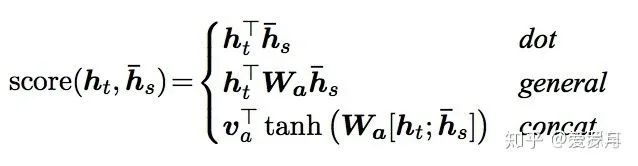
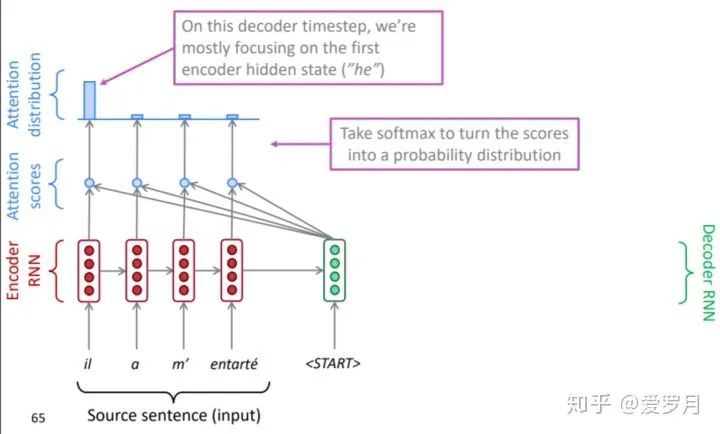
② Normalize the using a softmax (attention distribution)
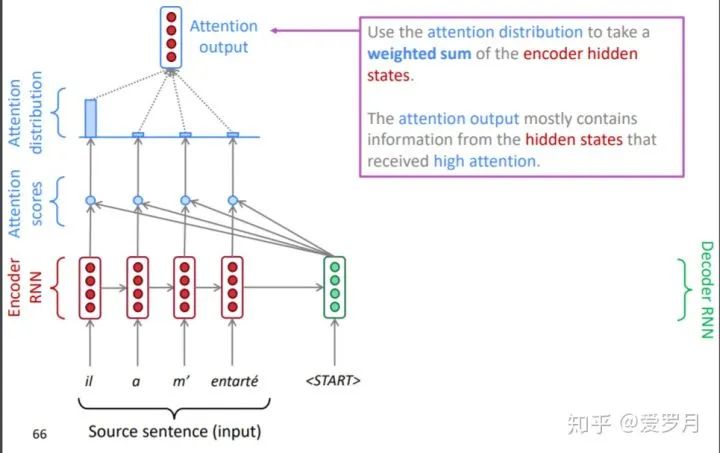

③ Compute the attention output
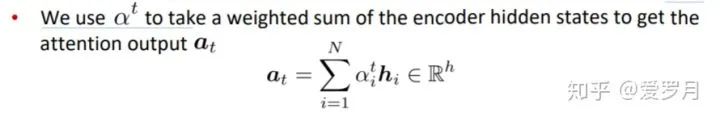
In the paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE, the attention output is denoted as , everyone can refer to it.
④ Decoding as seq2seq
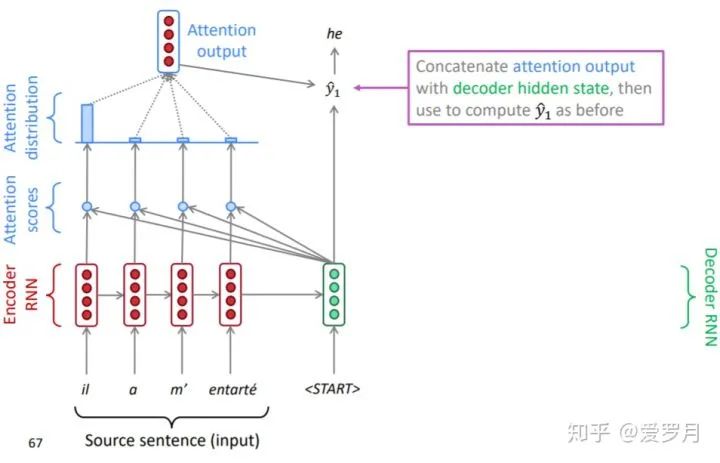

As we can see, the attention mechanism allows each time step of the decoder to input different vectors
.
The main idea of the attention mechanism is as described above. For deeper insights, you can take a closer look at the paper.
3 Soft Alignment

By putting the attention weights into a matrix (rows = input sequence, columns = output sequence), we would have access to the alignment between the words from the English and French sentences (I won’t translate this part).
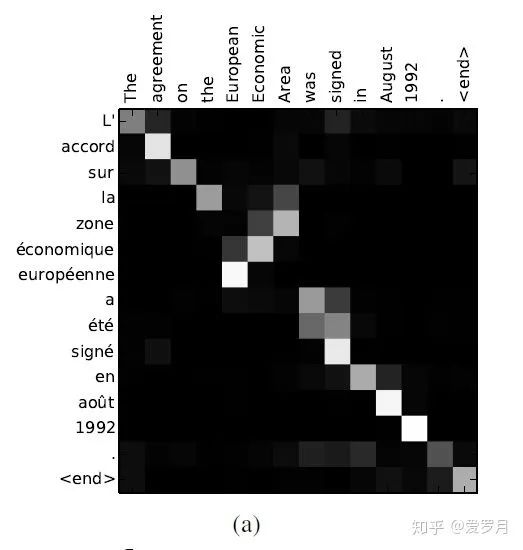
From the alignment in Figure (a), it can be seen that the alignment of English and French words is largely monotonic.
4 Summary

5 Additional Information
Recently, I wrote another article that I think is very helpful for beginners in attention, here’s a link.
Ailuo Yue: Global Attention / Local Attentionzhuanlan.zhihu.com
6 References
https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture08-nmt.pdfweb.stanford.edu
Seq2Seq with Attention and Beam Searchguillaumegenthial.github.io
Neural Machine Translation by Jointly Learning to Align and Translatearxiv.org
Important! The Yizhen Natural Language Processing Academic WeChat Group has been established
You can scan the QR code below, and the assistant will invite you to join the group for discussion.
Note: Please modify the remark to [School/Company + Name + Direction] when adding.
For example — HIT + Zhang San + Dialogue System.
Group owner, please consciously avoid business promotion. Thank you!

Recommended Reading:
The Differences and Connections between Fully Connected Graph Convolutional Networks (GCN) and Self-Attention Mechanisms
A Complete Guide for Beginners on Graph Convolutional Networks (GCN)
Paper Review [ACL18] Component Syntax Analysis Based on Self-Attentive