
1. Understanding the Principle of Attention Mechanism
The Attention mechanism, in simple terms, refers to the output y at a certain moment and its attention on various parts of the input x. Here, attention represents weights, indicating the contribution of each part of the input x to the output y at that moment. Based on this, let’s briefly understand self-attention and context-attention mentioned in the Transformer model.
(1) Self-attention: The input sequence is the same as the output sequence, meaning it calculates its own attention, computing the attention weights of the sequence to itself.
(2) Context-attention: This refers to encoder-decoder attention. For example, in a machine translation model, it calculates the attention weights of each word in the encoder sequence to each word in the decoder sequence.
2. Attention Calculation Methods

1. Content-based Attention
Paper: Neural Turing Machines
Paper Link: https://arxiv.org/pdf/1410.5401.pdf
The similarity measure for attention is based on cosine similarity:
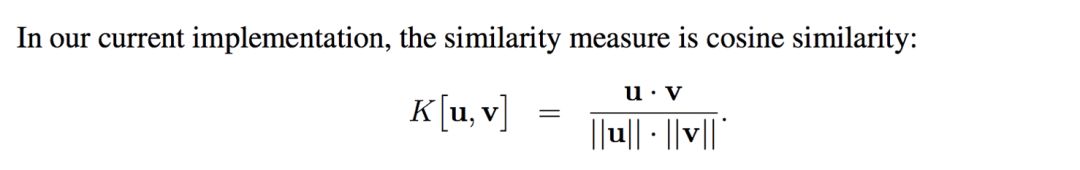
2. Additive Attention
Paper: Neural Machine Translation By Jointly Learning to Align and Translate
Paper Link: https://arxiv.org/pdf/1409.0473.pdf
A detailed introduction to the attention implementation process in this paper is provided below, but will not be discussed here.
3. Location-Based Attention, General Attention, Dot-Product Attention
Paper: Effective Approaches to Attention-based Neural Machine Translation
Paper Link: https://arxiv.org/pdf/1508.04025.pdf
A detailed introduction to the attention implementation process in this paper is provided below, but will not be discussed here.
4. Scaled Dot-Product Attention
Paper: Attention is All You Need
Paper Link: https://arxiv.org/pdf/1706.03762.pdf
The Attention mechanism mentioned in the familiar Transformer is introduced below.
3. Evolution and Development of Attention
1. Introduction of Attention Mechanism in Seq2Seq
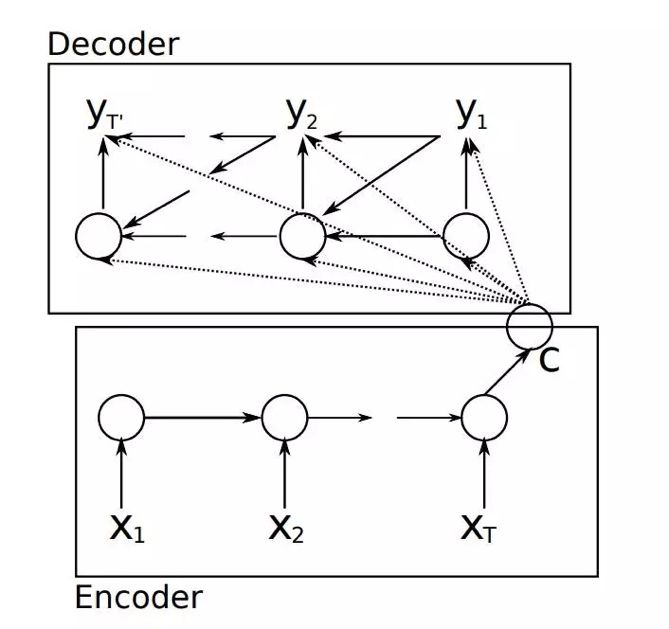
First, the attention mechanism is commonly used in seq2seq models. In the first figure, the traditional seq2seq model does not distinguish or identify the output y against the input sequence x1, x2, x3… In the second figure, we introduce the attention mechanism, where the weight of each output word y is influenced differently by the input X1, X2, X3…, and this weight is calculated by Attention. Therefore, the Attention mechanism can be viewed as a coefficient for attention distribution, calculating the influence of each input item on the output weight.
(Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation paper screenshot)
(NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE paper screenshot)
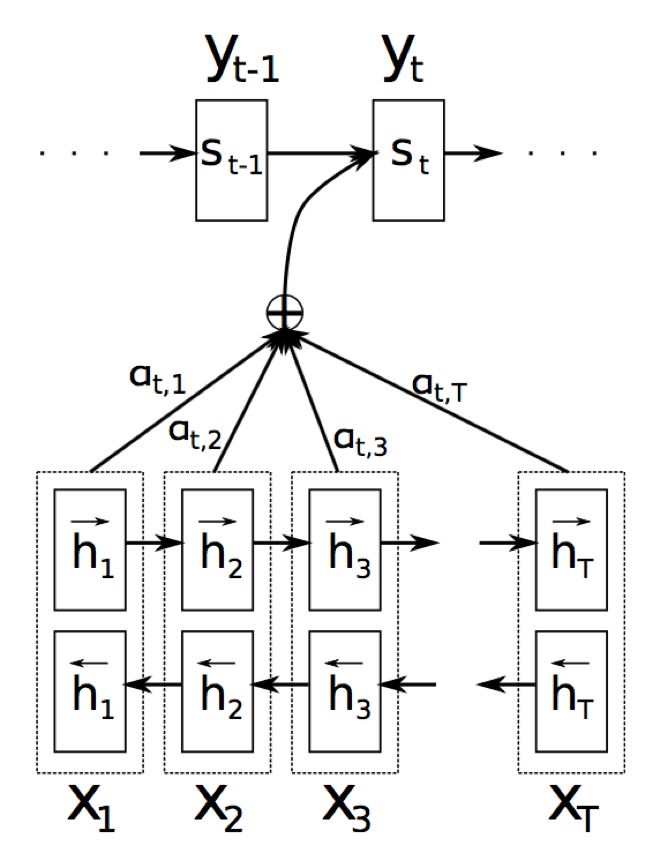
Let’s introduce the attention implementation process shown in the figure above.
(1) First, use a bidirectional RNN structure to obtain the hidden layer states (h1, h2, …, hn)
(2) If the current decoder state is St-1, calculate the influence of each input position hj on the current position i.
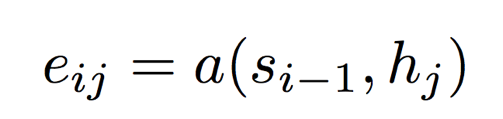
There are many ways to compute attention, such as dot product, weighted dot product, or summation.
(3) Apply softmax to eij to normalize and obtain the attention weight distribution, as shown below.
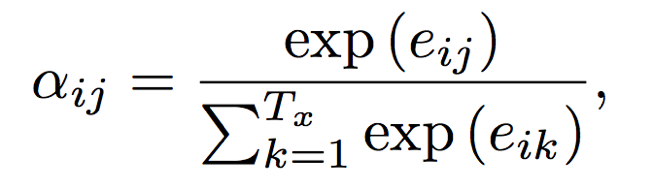
(4) Use aij for weighted summation to obtain the corresponding context vector.
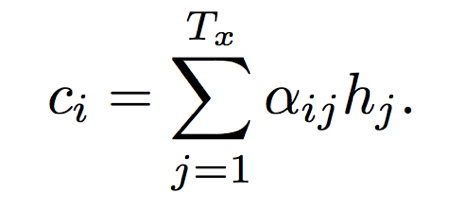
(5) Calculate the final output.
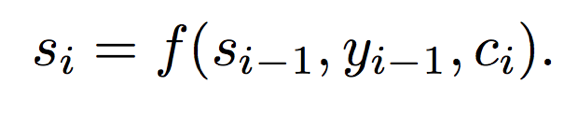
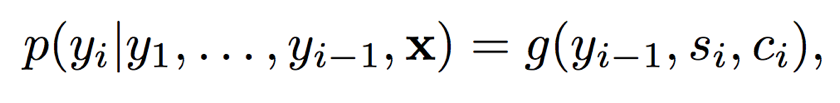
2. Soft Attention and Hard Attention
(Show, Attend and Tell: Neural Image Caption Generation with Visual Attention paper)
Soft attention is parameterized, differentiable, and can be embedded directly into the model for training. The seq2seq model above utilizes soft attention; hard attention is a stochastic process, requiring Monte Carlo sampling methods to estimate the gradient for backward propagation. Currently, more research and applications tend to prefer soft attention due to its direct differentiability for gradient backpropagation; a general understanding is sufficient.
3. Global Attention and Local Attention
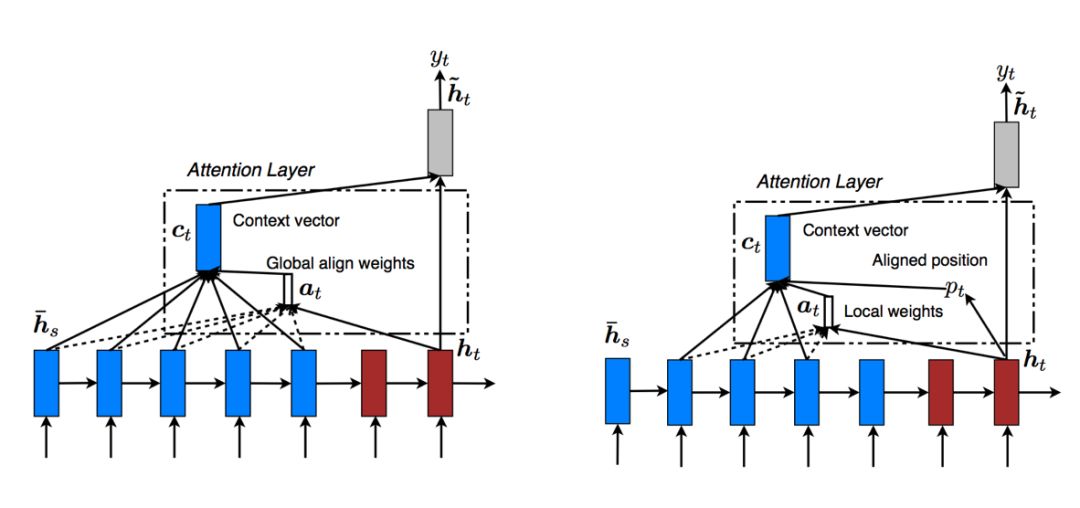
(Effective Approaches to Attention-based Neural Machine Translation screenshot)
The left image is Global Attention, and the right image is Local Attention.
Global Attention and Local Attention share commonalities, such as during the decoding phase of a translation model, both use the top-layer hidden state ht of LSTM as input, aiming to obtain a context vector ct to capture source information to aid in predicting the current word. The difference lies in how the context vector ct is obtained, while the subsequent steps are shared, first obtaining the attention hidden state from the context and hidden layer information:
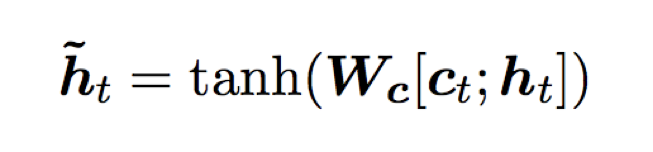
Then, the attention hidden state is used to obtain the prediction distribution through softmax.
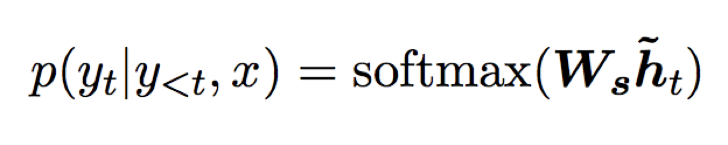
Next, let’s introduce how Global Attention and Local Attention obtain the context vector ct.
(1) Global Attention
Global Attention considers all hidden states of the encoder when calculating the context vector ct. The attention vector is obtained by comparing the current target hidden state ht with each source hidden state hs:
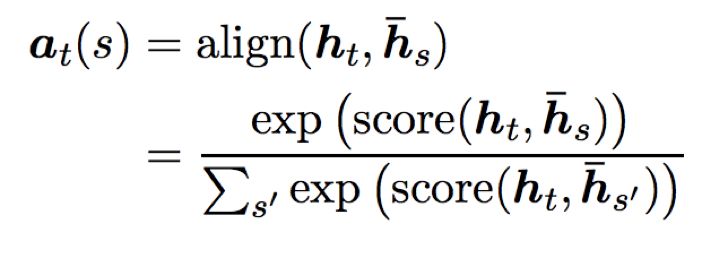
The calculation methods between ht and hs can adopt the following approaches:
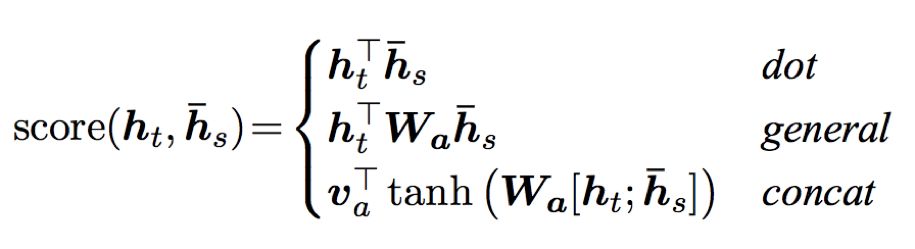
Currently, attention scores can also be calculated based on location:
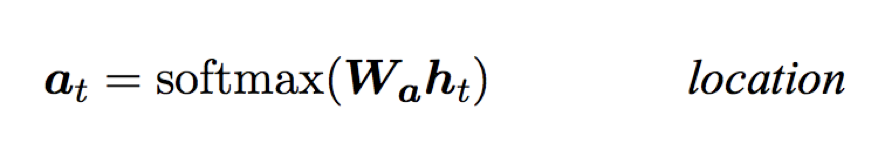
(2) Local Attention
The disadvantage of Global Attention is that it requires focusing on all words in the source sequence for each target word, consuming resources. Therefore, the idea of Local Attention is to select only a portion of source words for predicting the context vector ct for each target word. Specifically, at time t, the model first generates an alignment position pt for each target word. The context vector ct is computed as a weighted average of the source hidden states within the window [pt -D, pt +D]; D is chosen empirically. Unlike the global method, the local alignment vector at is of fixed dimension, i.e., ∈ ℝ2D+1.
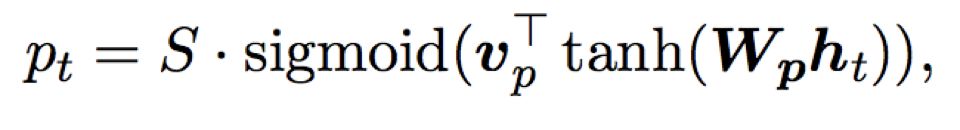
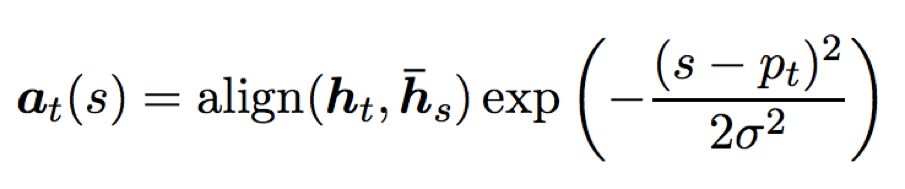
4. Attention in Transformer
Briefly discuss Scaled Dot-Product Attention and Multi-Head Attention used in Transformer. For detailed content, refer to the author’s previous articles: Understanding Transformer Model Details and Tensorflow Implementation, PyTorch Implementation of Transformer Model.
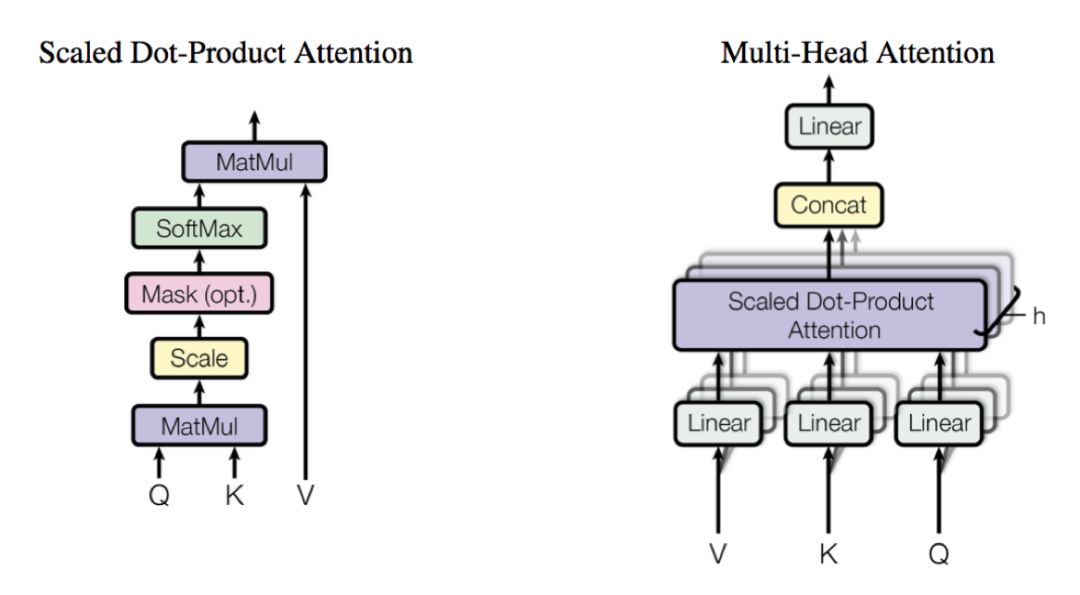
(Attention is All You Need paper screenshot)
Scaled Dot-Product Attention: calculates the weight coefficients of matrix V through matrices Q and K.
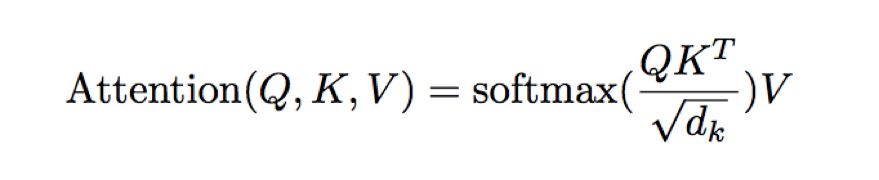
Multi-Head Attention: Multi-head attention projects Q, K, V into h sets of Q, K, V through a linear mapping, each calculating Scaled Dot-Product Attention, and finally combining them. The purpose of Multi-Head Attention is to extract features more comprehensively.
5. Related Papers on Attention Combination
(1) Hierarchical Attention Networks for Document Classification
(2) Attention-over-Attention Neural Networks for Reading Comprehension
(3) Multi-step Attention: Convolutional Sequence to Sequence Learning
(4) Multi-dimensional Attention: Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion Terms
6. Application Areas of Attention
(1) Machine Translation
(2) Inference of Implicit Relationships
(3) Text Summarization
4. Case Analysis of Attention
First, let’s look at the introduction of the Attention mechanism in Encoder-Decoder, such as in machine translation.
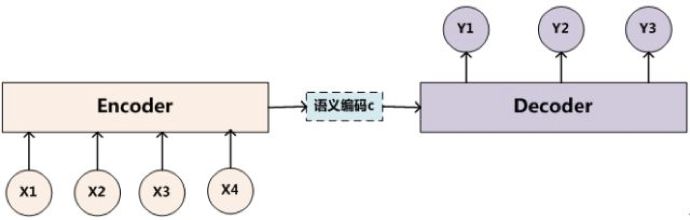
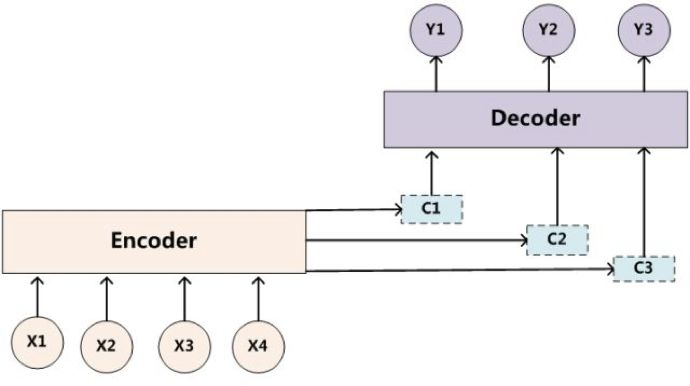
Each output word Y is influenced differently by the inputs X1, X2, X3, X4, and this weight is calculated by Attention.
Thus, the Attention mechanism can be viewed as a coefficient for attention distribution, calculating the influence of each input item on the output weight.
The following image illustrates the actual weight calculation process of the Attention mechanism in machine translation.
First, the original data is transformed through matrices to obtain the Q, K, V vectors, as shown in the following image.
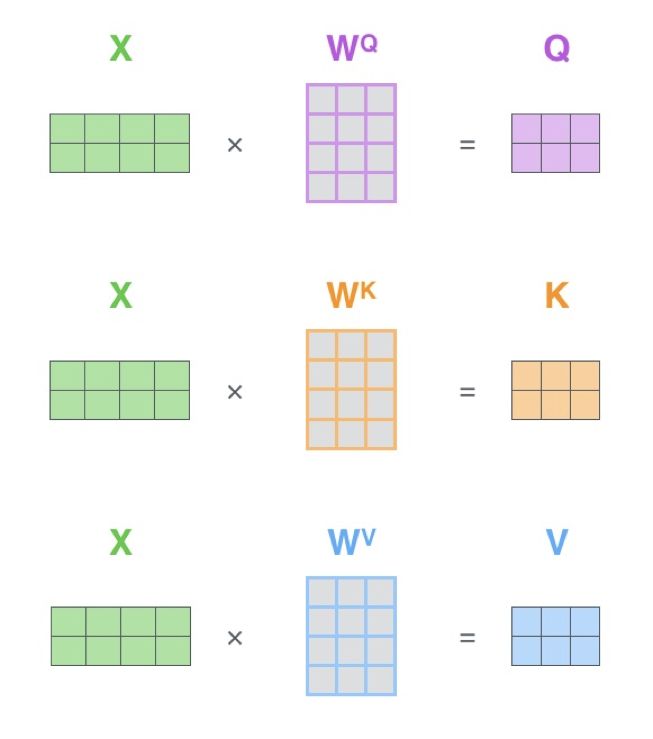
Taking the word “Thinking” as an example, first multiply the q vector of “Thinking” with the k vectors of all words using the formula below:
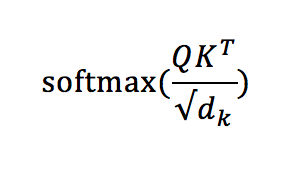
This obtains the contribution weights of each word to the word “Thinking”. Then, multiply the obtained weights with the v vectors of each word to get the final output vector for “Thinking”.
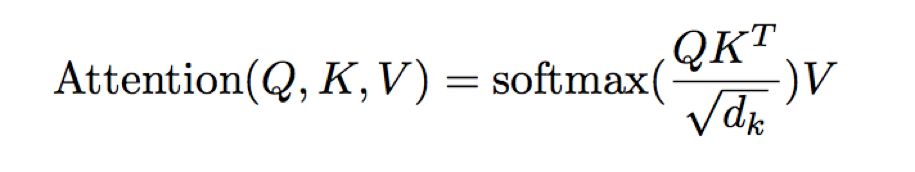
The purpose of scaling in Attention is to accelerate the computation of neural networks.
5. Analysis of Attention Mechanism Implementation
1. Implementation of Attention Mechanism in Hierarchical Attention Network
The HAN structure includes Word encoder, Word attention, Sentence encoder, and Sentence attention, which contain both word attention and sentence attention.
Explanation: h is the output of the hidden layer GRU. Set three random variables w, b, us. First, perform a fully connected transformation followed by the activation function tanh to obtain ui. Then, calculate the product of us and ui to compute the softmax output a. Finally, after obtaining the weight a, multiply it with h to get the final output through the attention mechanism. The left image shows the word attention calculation formula, and the right image shows the sentence attention calculation formula.
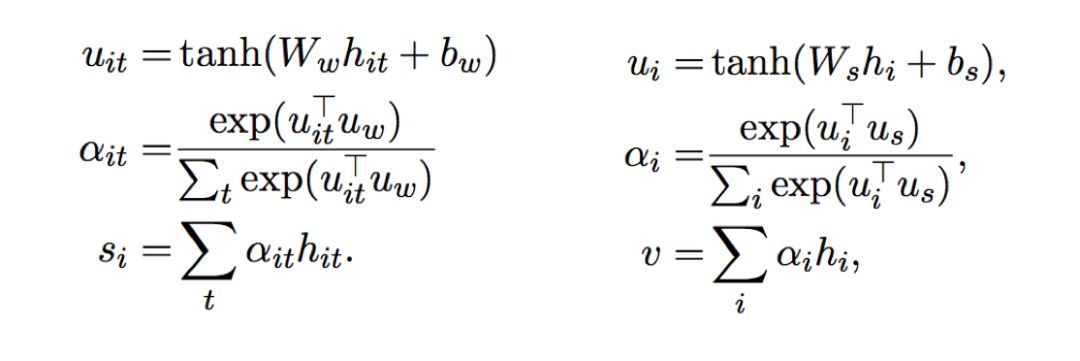
The core code for the Attention implementation in HAN is as follows:
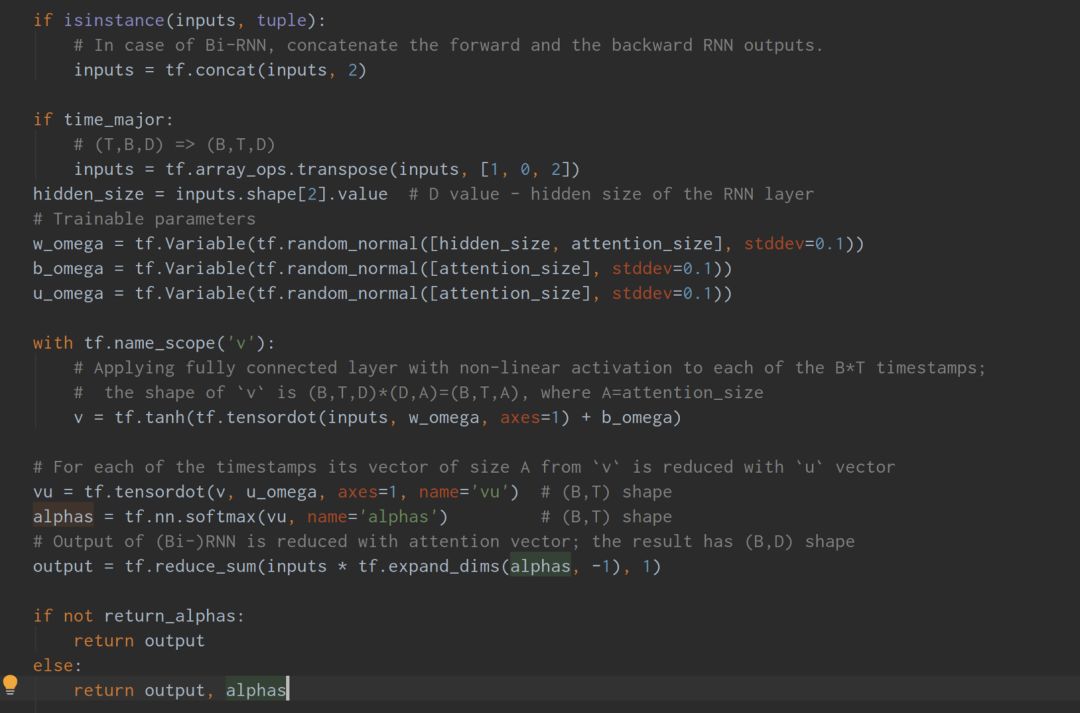
The role of the mask in attention is to prevent messages from being backpropagated. Below, let’s look at one implementation of the mask.

By masking the portions exceeding seq_length as False, and making the masked portions infinitely small, during backpropagation, the infinitely small reciprocal becomes 0, preventing message backpropagation.
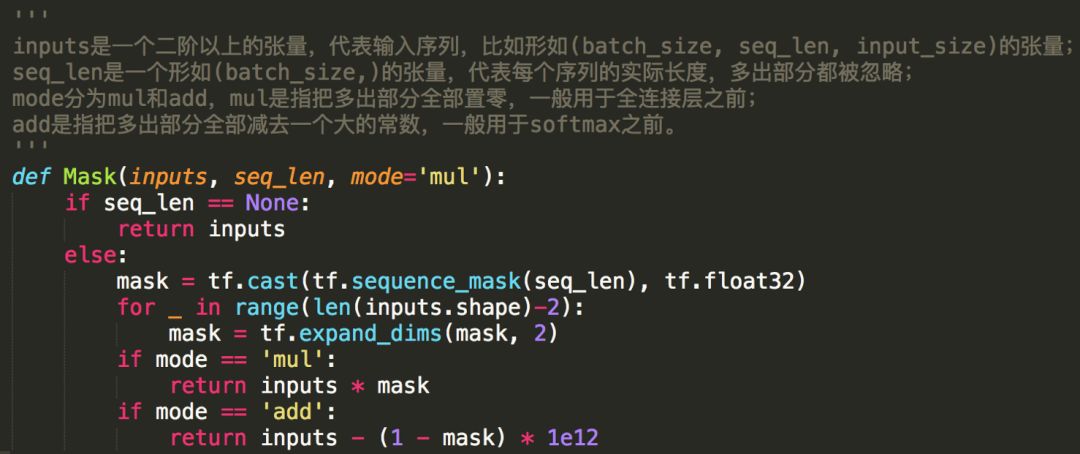
Here is another implementation of the mask, using both add and multiply methods as described above.
2. Implementation of Multi-Head Attention in Transformer
Refer to previous articles: Understanding Transformer Model Details and Tensorflow Implementation.
Previous Highlights:
Brief Overview of Optimization Theoretical Knowledge in Machine Learning
Implementing a Neural Network Multi-classifier by Yourself
PyTorch Implementation of Transformer Model
Comprehensive Guide to Ten Pre-trained Models in NLP
Understanding Bias and Variance in Machine Learning
FastText Principles and Text Classification Practice, Enough with This One Article
Understanding Transformer Model Details and Tensorflow Implementation
Quick Reading of GPT, GPT2, Bert, Transformer-XL, XLNet Papers
Machine Learning Algorithm Section: Proof of Maximum Likelihood Estimation for Least Squares Method Rationality
Word2vec, Fasttext, Glove, Elmo, Bert, Flair Training Word Vector Tutorial + Data + Source Code

Don’t sneakily read this; if it’s useful, give it a thumbs up!