

Introduction
Recently, while reviewing the papers I had previously studied in depth, I found that some notes were still very valuable. I made some minor adjustments and am publishing them for everyone to see.
LLama3 is a paper from a few months ago, but each reading still brings new insights. This article discusses key points, adding some of my own thoughts and practices to each technical aspect.
Overall Overview
As shown in the figure above, the entire training process of Llama3 in the pure text modality is divided into the following main stages:
-
Pre-Training: mainly includes:Pre-training, long text pre-training, and annealing pre-training three stages.
-
Post-Training: mainly includes:SFT and DPO two stages.
For the multi-modal part, it mainly includes the following stages,this part is not very mature, so we will skip it for now:
-
Multi-modal encoder pre-training: training the image encoder and speech encoder.
-
Vision adapter training: using an adapter to combine the image encoder with the pretrained language model.
-
Speech adapter training:
Model Architecture
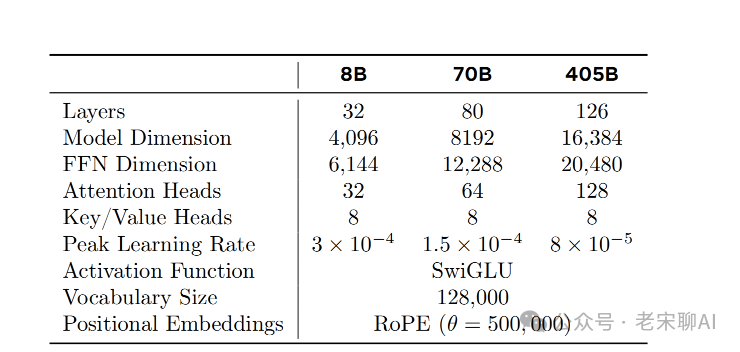
There is no significant difference from llama1 and llama2; the improvement mainly comes from:data quality, data diversity, and training scale.
-
GQA:8 key-value heads to enhance inference speed and reduce kv-cache.
-
Using attention masks to prevent self-attention between different documents. Experiments found no significant impact in normal pt (4k, 8k), but it is crucial for long text CPT.
-
Vocabulary: 128k. Among them, 100k comes from tiktoken, and an additional 28k supports non-English. The additional 28k tokens do not affect English tokenization and can improve compression rate and downstream performance. Tests show a significant improvement in compression rate for Chinese compared to llama2, but it is still far behind qwen.
-
Positional Encoding: ROPE, with the basic frequency hyperparameter set to 500000, which allows the model to better support context.
Pretrain
Pre-Training Data
The scale of PT data is15.6T, covering knowledge up to 2023.
Web Data
-
PII and safety filtering: multiple filters were designed to filter out data related to unsafe content and PII content.
-
Text Extraction and cleaning: Extracting text from HTML. The paper found thatmarkdown data harms model performance, so all markdown formats were removed.
-
De-Duplication:
-
url-level de-duplication: URL de-duplication was performed across the entire dataset.
-
document-level de-duplication: global minHash was used to remove duplicate documents.
-
line-level de-duplication: ccNet was used for de-duplication. In a bucket of 30 million, lines appearing more than 6 times were removed.
-
Heuristic filtering: a set of rules was designed to filter low-quality and repetitive text:
-
Using n-gram coverage ratio to remove duplicate content, such as: logging, error. These lines can be very long and cannot be removed through line-level de-duplication.
-
Using dirty word counting to filter out some adult websites.
-
Using token-distribution Kullback-Leibler distribution to filter out data containing too many outlier tokens.
-
Model-based quality filtering: A quality classifier was trained, using Distill Roberta to score each document’s quality to determine if it belongs to high-quality data.
-
Code and reasoning data:
-
Building a domain-specific pipeline to extract code and math web pages.
-
Using DistilledRoberta to train a code classifier and a math classifier.
-
Multilingual data:
-
Using fasttext classifier to distinguish 176 languages.
-
Performing document-level and line-level de-duplication within each language category.
-
Using rules and models to remove low-quality documents.
-
Training a quality ranking model to ensure high quality of multilingual data.
Determining the data mix
The data ratio in the pre-training data is a very core topic.
-
Knowledge classification: Classifying data to determine the ratio of each category. For example, reducing the sampling ratio of art and entertainment in the actual ratio.
-
Scaling laws for data mix: Verifying data mix on small models and transferring it to large models for better performance.
-
Data mix summary:50% general knowledge, 25% mathematical and reasoning tokens, 17% code tokens, 18% multilingual tokens.
Annealing Data
The paper found that addinghigh-quality code and math data during the annealing phase can improve performance on key benchmarks.
After training annealing on llama3 8B, performance improved by 24% and 6.4% on GSM8K and MATH respectively, but the improvement on the 405B model was negligible, indicating that the 405B model itself possesses strong contextual and reasoning abilities, without the need for specific domain annealing to enhance performance.
The paper later evaluates data quality through annealing training.
Scale Laws
It is worth discussing separately. I will write a separate article on this topic later.
Pre-Training Recipe
3.1 Initial Pre-Training: 405B
-
Learning rate: cosine learning rate schedule, learning rate=8 * 10-5, linear warm up=8000 steps, decaying to 8*10-7 after 1200000 training steps.
-
Batch size: using a stepwise batch size to enhance training stability and reduce loss spikes.
-
Initially using a low batch size to enhance training stability, 4M tokens, text length 4096.
-
After pre-training exceeds 252M, the batch size increases to 8M, text length 8192.
-
After 2.87T, the batch size increases to 16M.
-
Data mix:
-
Increasing the proportion of non-English data to enhance multilingual performance.
-
Upsampling math to improve the model’s mathematical performance.
-
Adding more recent data.
-
Downsampling low-quality data.
3.2 Long Context Pre-Training
Supported length: 128K, training token count: 800B.
Using six stages to gradually increase text length from 8K to 128K. In each stage of training, the model’s performance is evaluated to determine whether it has successfully adapted at that length. The evaluation focuses on two aspects:
-
short-context evaluations: evaluating whether performance is normal on short texts
-
needle in a haystack: evaluating whether performance is reasonable on large document searches
3.3 Annealing:
In the last 40M tokens, the learning rate is gradually decayed to 0, training length 128k.In the annealing phase, the proportion of high-quality data is increased.
My thoughts on Pretrain
Currently, there is no significant difference in Pretrain among major companies, and the competition for foundational models has basically ended. The open-source Qwen in China has already outperformed many closed-source teams from large companies. Alibaba’s open-source quality is still very reliable. It is foreseeable that the future competition will no longer be on foundational models; now, whoever has the cards, whoever has the data, is the boss. I have high hopes for Alibaba and ByteDance.
Post-Training
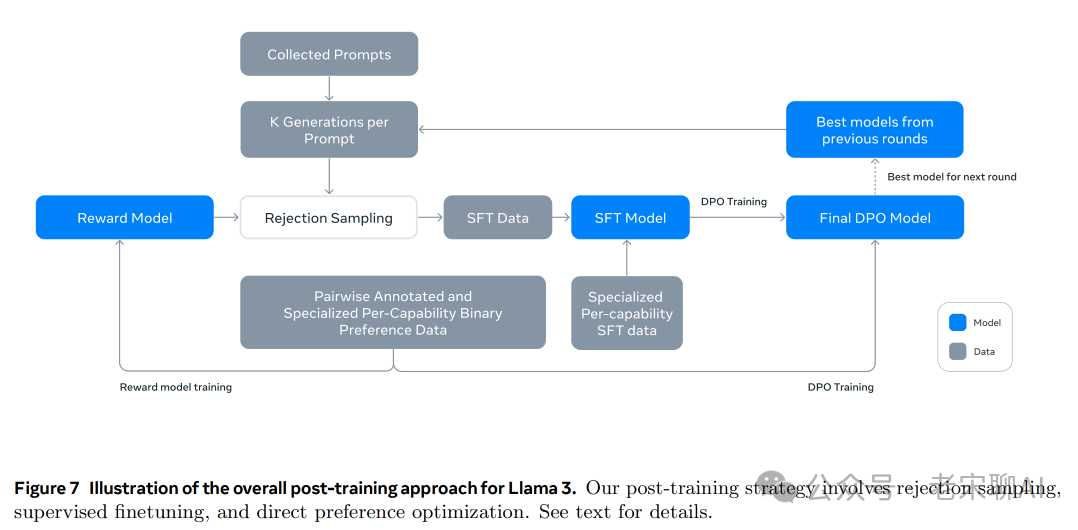
The entire Post-Training phase is as shown in the figure above, mainly theSFT stage andDPO stage iterative optimization process.
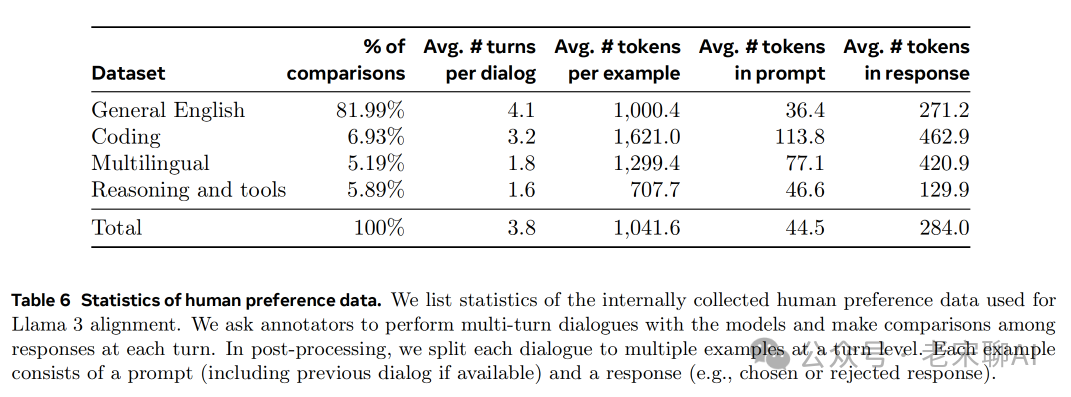
Preference Data:
-
For each prompt, different models generate two answers. Different models can be trained using different data combinations and alignment methods to increase data diversity.
-
Annotators classify the chosen response and rejected response into four levels: significantly better, better, slightly better, marginally better.
-
Annotators edit the chosen response to obtain better answers. edited > chosen > rejected.
-
Preference data is roughly classified as shown in the table above.
-
In the improvement process of each training round, the complexity of prompts is increased to target the weaknesses of the model. In each round of post-training, all preference data is used for Reward Model training, but only the latest batch of data is used for DPO.
-
Note: In Reward Model training, samples marked as: significantly better and better are used for training, while data from the other two categories is discarded.
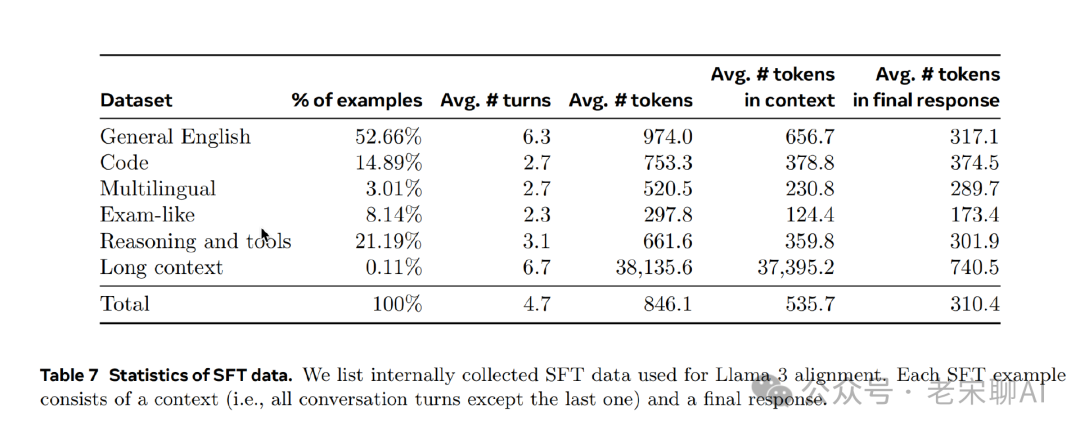
SFT Data
Data comes from three sources:
-
From user prompts and rejection-sampled generated answers
-
Specific domain synthetic data
-
A small amount of manually organized annotated data
The final statistics of the SFT data used are as follows:
2.1 Rejection sampling
-
For a prompt, the best model samples k (10-30) responses
-
Using the reward model to rank these prompt-response pairs and select the best answer
2.2 SFT Data Quality Processing and Filtering
Since most of the data is model-generated, quality control and filtering are necessary.
Data Cleaning:
-
Some data contains excessive punctuation and emojis.
-
Answers contain excessive apologies, such as: I’m sorry, I apologize.
Data Pruning: using models to filter out low-quality data.
-
Topic Classification:Classifying using LLama3, including primary classification: mathematical reasoning, secondary classification: geometry and trigonometry.
-
Quality Scoring:
-
RM Model:Scoring with the RM model, considering the top 25% of data as high-quality data.
-
Llama-based score:Referencing Deita, scoring data from different dimensions. For code, scoring from Bug Identification and User Intention. For English data, scoring from Accuracy, Instruction Following, Tone/Presentation.
-
Difficulty scoring:
-
InsTag:Using Llama3 70B to tag; the more tags, the more complex it is considered.
-
Llama3:Referencing Deita, directly using Llama3 for complexity scoring.
-
Semantic deduplication:Using RoBERTa for clustering, then sorting within each category usingquality score * difficulty score for ranking.
Capabilities
Optimizing for specific domain data, mainly including: Code, math and reasoning, Long context, tool use, factuality, steerability.
3.1 Code
Generated2.7M of synthetic data.
-
Synthetic data generation: execution feedback. Directly using synthetic data generated by llama3 405B in training has not helped training results and may even have negative effects. Therefore, using execution feedback to synthesize data:
-
Problem description generation:Collecting/generating a large number of programming problem descriptions and categorizing them by topic to ensure diversity.
-
Solution generation:Using prompts to generate answers with llama3. Note: Asking the model to explain its reasoning process can improve answer quality;
-
Correctness analysis:Answers generated by the model may not be correct, so additional methods are needed to ensure generation quality:
-
Static analysis: directly running code through a compiler to check for syntax errors in the answers. For example: code style, typos, variable omissions, etc.
-
Unit test generation and execution: writing some unit tests to check for runtime errors, etc.
-
Error feedback and iterative self-correction:If an answer fails to run, we design prompts to modify the answer based on error messages, such as stderr errors and unit test failures. Ultimately, only data from all tests can be used as SFT data.
-
Fine-tuning and iterative improvement:Iterative fine-tuning through the above processes gradually improves model performance.
-
Synthetic data generation: programming language translation.Experiments found that the model performs well on mainstream languages like Python/C++, but poorly on niche languages like TypeScript/PHP. This is mainly due to the very little niche language data included in the training data. Using Llama3 to convert answers from mainstream languages to niche languages, as shown in the figure below:
-
Synthetic data generation: back-translation.
3.2 Multilinguality
-
2.4% human annotations
-
Data from other NLP tasks: converting open-source NLP tasks into dialog data.
-
Rejection sampled data: first generating some answers with the model, then using the reward model to select the answers.
-
Translated data:
3.3 Math and Reasoning
Current challenges:
-
Lack of prompts: there are relatively few complex math prompts or questions.
-
Lack of ground truth chain of thought: a lack of real COT annotated data.
-
Incorrect intermediate steps: using model-generated COT data may have issues in the intermediate processes.
-
Teaching models to use external tools:
-
Discrepancy between training and inference:
3.4 Long Context
Expanding from 8k to 128k.
If short SFT data is used to fine-tune the model, it will significantly degrade the model’s long text capabilities.
Using LLama3 to synthesize data in the following areas:
-
Question Answering:
Summarization: using Llama3 to summarize 8k documents to generate data.
Long Context code reasoning:
Then applying the above methods to generate data for 16k, 32k, 64k, and 128k.
Ratio:0.1% long context data combined with short text data can balance the overall results.
Using only short texts in DPO will not negatively impact long text performance after SFT.
Some thoughts on Post-Pretrain
After the competition for foundational models has ended, the next competition will be in applications, and the competition at the application level will focus more on: incremental pre-training, SFT, synthetic data, RLHF, and several other aspects.
Finally
I believe that the wave triggered by ChatGPT has reached its mid-stage, and the next competition will be even more intense. Ultimately, most applications will be determined by large companies and some niche unicorns.
To join the technical group, please add the AINLP assistant on WeChat (id: ainlp2)
Please note your specific direction + related technologies used
About AINLP
AINLP is an interesting and AI-focused natural language processing community, specializing in the sharing of technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and job experience sharing, etc. Welcome to follow! To join the technical group, please add the AINLP assistant on WeChat (id: ainlp2), noting your work/research direction + purpose of joining the group.