Introduction
Text analysis has traditionally been dominated by qualitative methods, with the two most common being interpretive close reading and systematic qualitative coding. Both are limited by human reading speed, making them unsuitable for analyzing extremely large corpora. Currently, two popular quantitative text analysis methods are semantic network analysis and topic modeling. While both make it possible to analyze large-scale text data, they fall short in capturing the multidimensional relationships between words.
This article introduces an emerging computational method—word embedding, which embeds the vector representation of words from high-dimensional sparse vectors into relatively low-dimensional continuous vector spaces, enabling a detailed analysis of the relationships between words.
1. Basic Principles of Word Embedding
Unlike text analysis methods based on word frequency statistics, the core of word embedding lies in representing words based on the global semantic information of the text. By utilizing the contextual information of words in large-scale texts, it maps text vocabulary to low-dimensional vector spaces to achieve vectorized representations of words, preserving the semantic associations while satisfying the algebraic properties of vectors.
1. Representation Methods of Word Vectors
Word vectors are fundamental to Natural Language Processing (NLP). The representation methods for word vectors include discrete representation methods (such as one-hot encoding) and distributed representation methods.
One-hot encoding is the most basic word vector method, using a vector with dimensions equal to the size of the vocabulary to represent words in the text, where only the entry corresponding to the word is 1 and all other entries are 0. This leads to a fatal weakness of sparse matrices and dimensionality disaster, and the word vectors derived from one-hot encoding are orthogonal to each other, making it impossible to capture relationships between word vectors.
Distributed representation methods represent the semantics of words through context. The distributed hypothesis is also the core logic behind word embedding technology—words with similar contexts have similar meanings. Distributed representation includes methods based on co-occurrence matrices and language models, with one of the most notable methods being the Word2Vec model proposed by Mikolov et al. in 2013[1].
2. Word2Vec Model
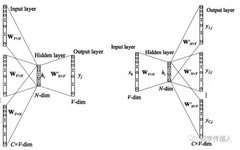
The Word2Vec model is one of the most widely used word embedding algorithms, consisting of two neural network architectures—CBOW (Continuous Bag-of-Words) and SG (Skip-gram). As shown in the figure below, both CBOW and SG consist of an input layer, an output layer, and a hidden layer. The CBOW model predicts the center word based on the context vocabulary, while the SG model infers its context vocabulary using the center word. Through the parameter matrix of the hidden layer, the context word vectors of the center word (represented by one-hot encoding) are transformed into low-dimensional real-valued vectors (i.e., word vector results)[2].
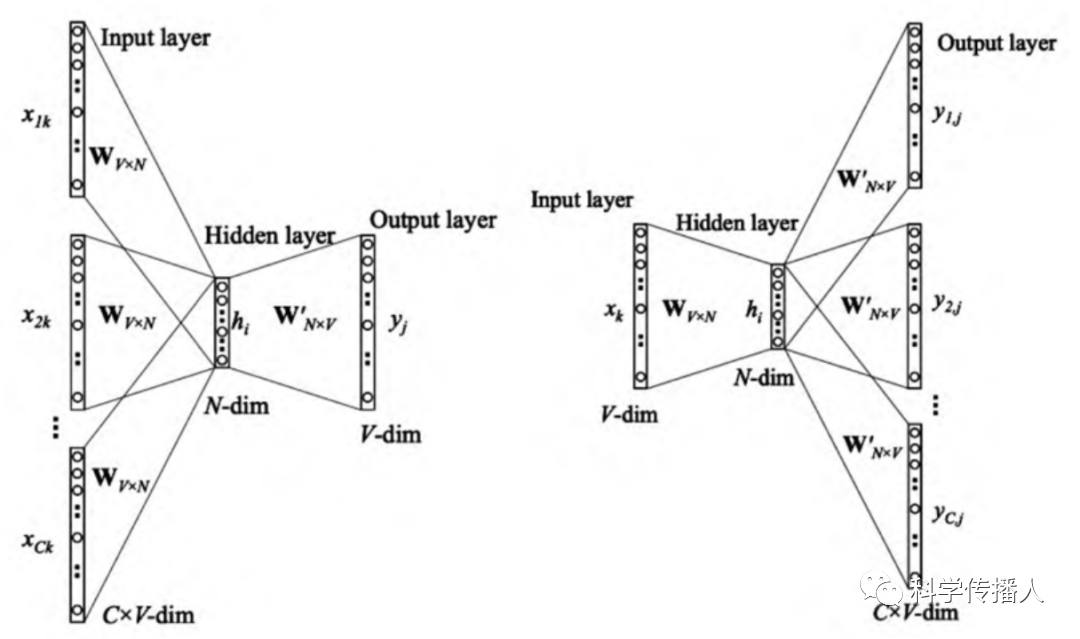
Figure 1 The Principles of CBOW and SG in the Word2Vec Model
3. Characteristics of Word Embedding
Word embedding can achieve dimensionality reduction of word vectors while also reflecting semantic information. Word vectors satisfy the operational rules of vectors, and the operational logic aligns with the real semantic logic of words. For example, “man is to woman as king is to queen” can be derived using the following vector calculation:
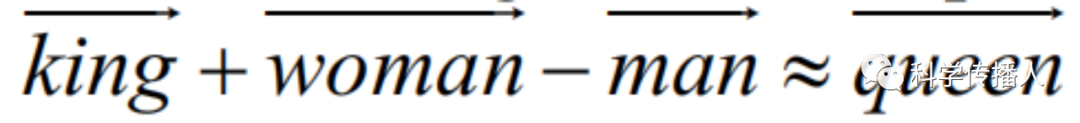
The distance between words in the embedding space can be evaluated using “cosine similarity”, which is the cosine of the angle between two word vectors. The range of cosine similarity is [-1,1], where a value of 0 indicates no semantic relationship between the two words, and values closer to 1 indicate a stronger correlation, with the sign indicating positive or negative correlation.
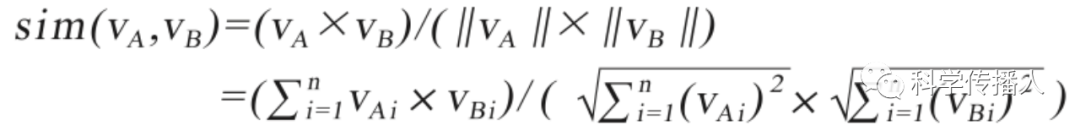
2. Applications of Word Embedding in Social Science Research
Word embedding technology can achieve in-depth exploration of cultural information across time and cultures, thus being widely used in social science research, such as social bias, cultural cognition, semantic evolution, and relational networks. This article selects three articles that use the Word2Vec word embedding model to study different topics, introducing different usage methods and research results of word embedding.
1. The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings
The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings[3]
The article by Kozlowski et al. (2019) proposes word embedding as an important tool for studying culture, using the concept of social class as an example to demonstrate the cultural implications of social class in the English-speaking world over the past century.
The authors identify seven cultural dimensions of class, such as wealth, employment, prestige, education, and cultivation, with each dimension constructed from the difference in vectors of multiple semantically related antonym pairs (Figure A). The projection of a word vector onto a “cultural dimension” vector is equivalent to the cosine value of the angle between the two (Figure B), allowing a word to be located along multiple cultural dimensions simultaneously (Figure C).

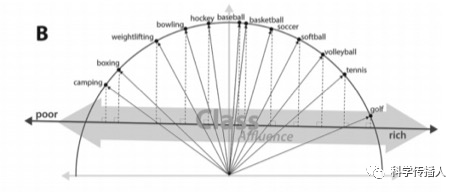
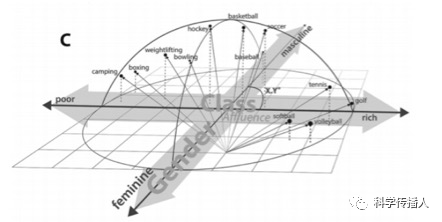

Swipe to see more

Figure 2 Construction of Cultural Dimensions of Class
The article focuses on analyzing the associations between the wealth dimension and other dimensions to reveal the cultural implications of class. The results indicate that the relationship between wealth and employment is the weakest, while the relationship with cultivation and status is the closest, suggesting that the external symbols of class are more visible than the production relations. Furthermore, the relationship between education and wealth has become increasingly close, confirming the prominent role of education in socio-economic achievement and wealth accumulation.
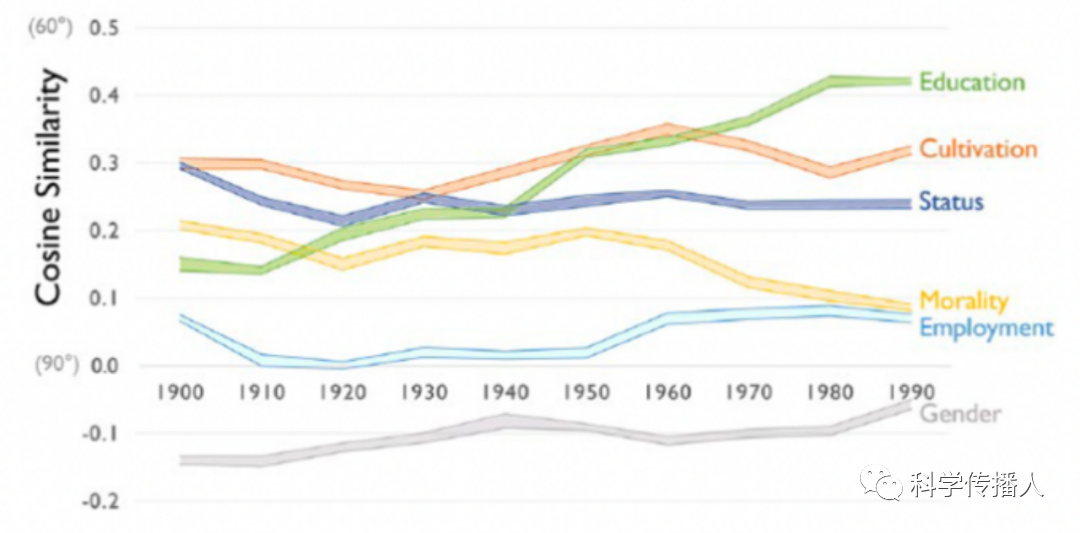
Figure 3 Correlation between Wealth and Other Dimensions
2. Gender Bias in Music
Quantifying cultural change: Gender bias in music[4]
The article by Boghrati et al. (2023) utilizes Word2Vec to explore the implicit gender bias in the lyrics of over 250,000 American pop songs over the past fifty years. The authors calculate the cosine similarity between male and female words and ability-related words, using the arithmetic mean of the difference in cosine similarity to calculate gender bias (as shown in the formula below), where values greater than 0 indicate bias towards males and values less than 0 indicate bias towards females.
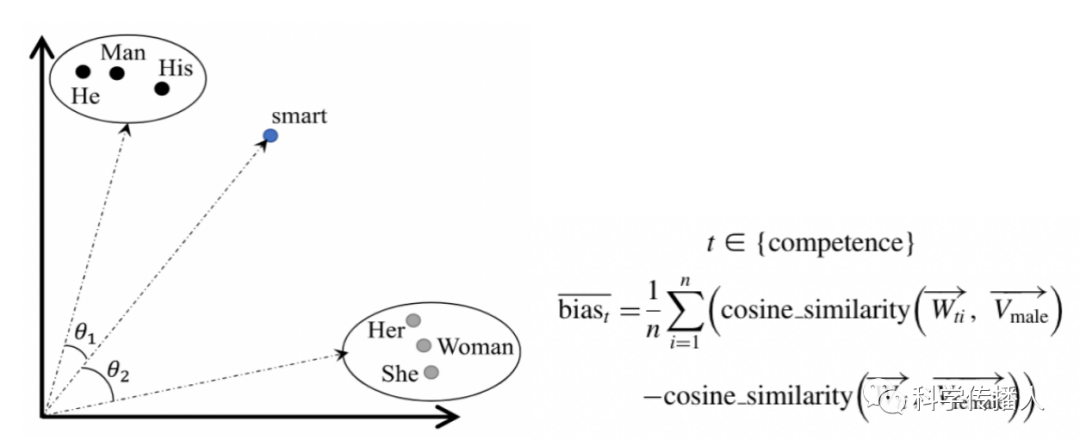
Figure 4 Calculating Gender Bias through Cosine Similarity
The results in Figure 5 indicate that females are less likely to be associated with ability in songs, although this bias has decreased, it still exists.
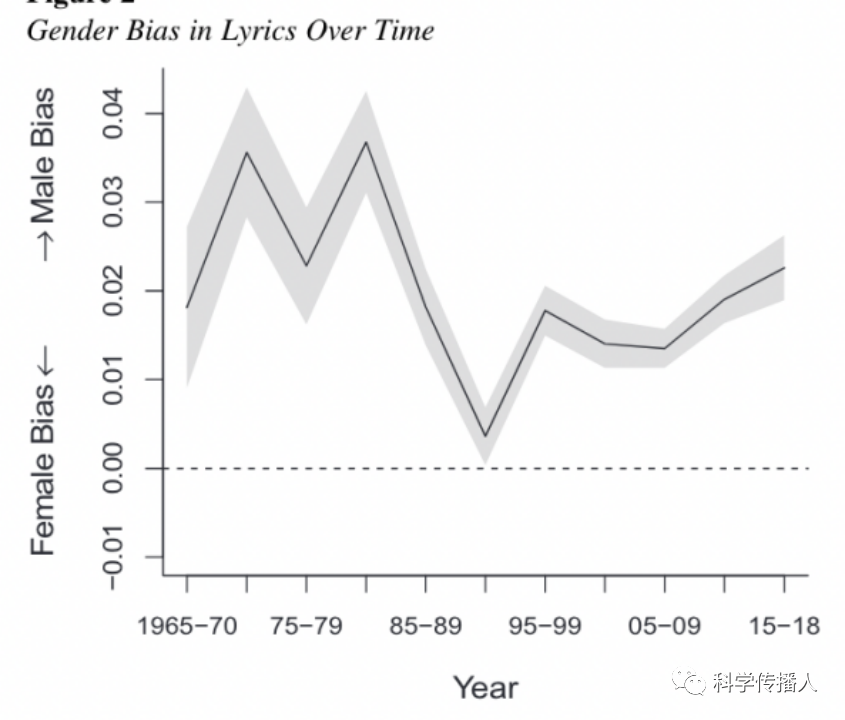
Figure 5 Gender Bias in Lyrics
3. The Prevalence of Two Hypotheses about COVID-19 Origins in News Media
Prevalence in news media of two competing hypotheses about COVID-19 origins[5]
The article by Rozado et al. (2021) studies the prevalence of two competing hypotheses regarding the origins of COVID-19 (natural emergence hypothesis and lab leak hypothesis) in news reporting. The authors first track the frequency evolution of different COVID-related keywords over time, finding that throughout most of 2020, the natural emergence hypothesis was favored in news media content; starting from May 2021, the prevalence of the lab leak hypothesis in media discourse significantly increased.
To illustrate the relationship between the two hypotheses and COVID-19, the authors used word embedding models to calculate the cosine similarity between natural emergence-related phrases and lab leak-related phrases with COVID and coronavirus (as shown in Figure 6). From the first row, it can be seen that the association between COVID-19 and natural emergence-related words such as pangolins, civets, bats, and seafood markets was most prominent in February 2020, followed by a decline and fluctuations; from the second row’s first two graphs, it can be seen that the association between COVID-19 and “lab leak” related words significantly increased starting in May 2021, with previous peaks as well. Thus, word embedding more intricately depicts the changing relationships between COVID-19 and the two hypotheses in news reporting over time.
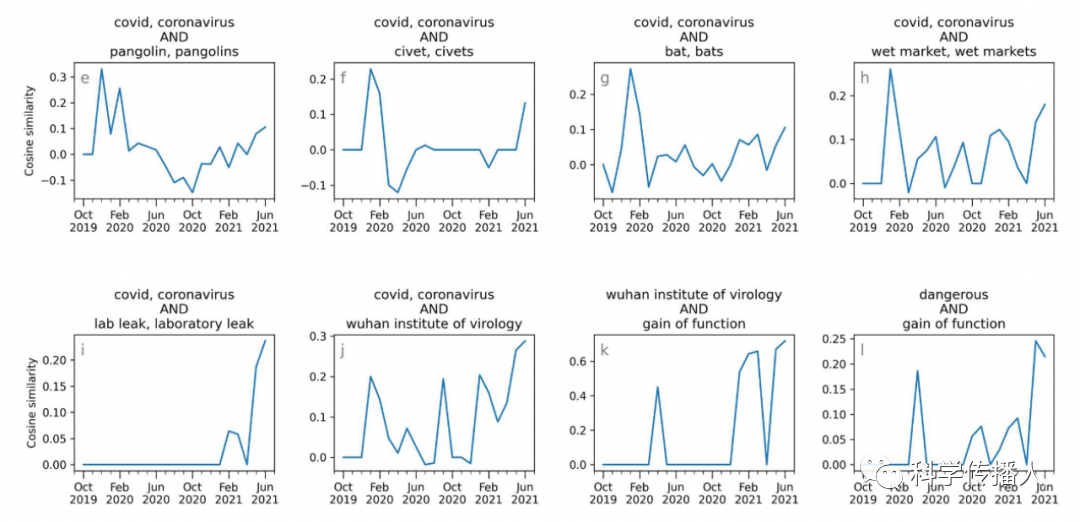
Figure 6 Cosine Similarity of Two Origin-Related Phrases with COVID-19-Related Words
3. Advantages and Challenges of Word Embedding Methods
Word embedding methods can efficiently and automatically process large-scale text data, extracting features based on the inherent distribution patterns of the text, thereby reducing reliance on subjective judgment processes and resulting in more objective outcomes. The geometric relationships between word vectors can largely explain the real relationships between words and concepts, enabling in-depth exploration of cultural information across time and cultures.
However, word embedding depends on the volume of the corpus, requiring training on relatively large corpora for effective model training. For small-scale text corpora, the training results of the model are limited. Additionally, word embedding cannot automatically identify the most important dimensions for a given semantic system or social process, so the choice of analysis dimensions should be based on theoretical considerations. Moreover, analyzing Chinese texts requires prior “word segmentation”; for certain specific domains, such as specialized academic articles or classical literature, the content and structure of the text differ significantly from standard training corpora, making word segmentation face certain difficulties, thus affecting model training outcomes.
References
[1] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[2] Ran, Y., Li, Z., Liu, J., et al. The expansion of social science research methods in the era of big data: Applications of text analysis based on word embedding technology. Nankai Business Review, 2022, 25(02): 47-56+79+57-58.
[3] Kozlowski, A. C., Taddy, M., & Evans, J. A. (2019). The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), 905-949.
[4] Boghrati, R., & Berger, J. (2023). Quantifying cultural change: Gender bias in music. Journal of Experimental Psychology: General.
[5] Rozado, D. (2021). Prevalence in news media of two competing hypotheses about COVID-19 origins. Social Sciences, 10(9), 320.
Author | Lin Yujing, Graduate Student, School of Journalism and Communication, Tsinghua University
Reviewed by | Jin Jianbin, Chen Huimin, Zhu Ziyi
Edited by | He Yuxuan, Luo Xinyi
