
Originally from Data Department THU
Source CloudB Computational Thinking and Aesthetics
"How can 'humans' do what they are good at, while leaving the rest to machines.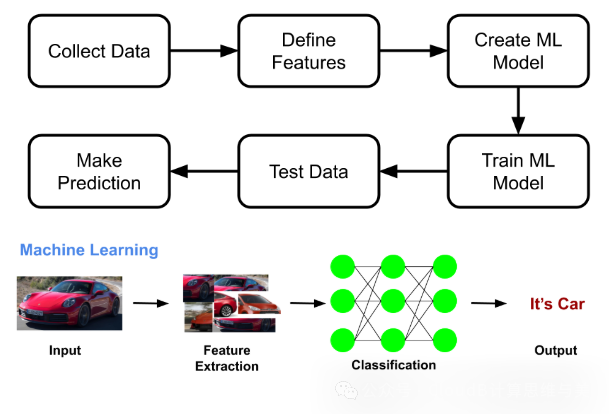
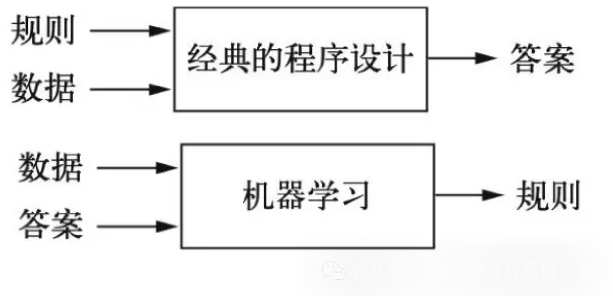
[ Introduction ] Since the 1980s, machine learning has led the development trend of artificial intelligence, shifting the contribution of artificial intelligence from human-given intelligence to machine-learned intelligence. Undoubtedly, the ability to learn and solve problems is a concentrated manifestation of intelligence. How can machines simulate this ability of humans? Practice has shown that algorithms based on a brain-level large-scale parallel architecture are more practical than those based on logical rules. “How can ‘humans’ do what they are good at, while leaving the rest to machines? From strong algorithms to strong computing power, and then to strong data, machines continuously extend and expand human capability boundaries.
Features
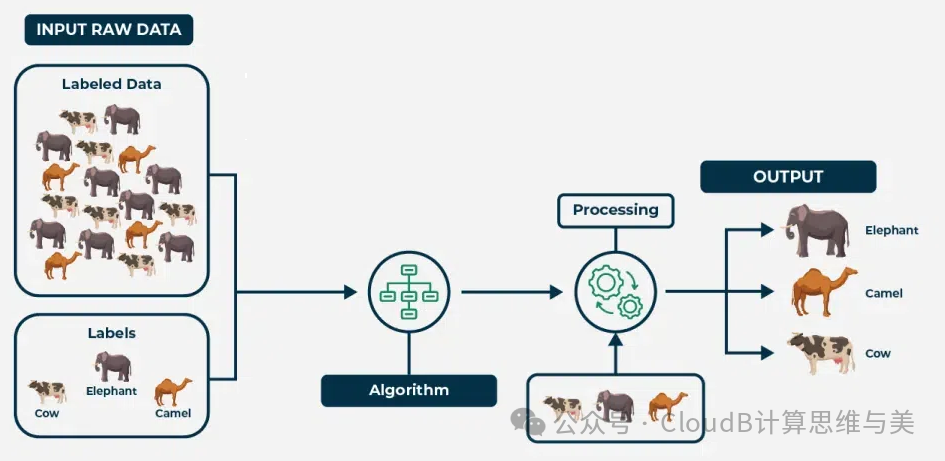
In machine learning, features are the independent, quantifiable attributes used to describe data objects. A single feature is insufficient to represent an object, so a combination of features is used in machine learning—feature vectors.
-
For predicting house prices, features include: house area, number of rooms, geographical location, year built, proximity to schools and subway stations, etc.; -
For recognizing objects in images, features include: raw image pixel values, edge detection values, color histograms, deep learning extracted quantities, etc.; -
For determining the sentiment polarity (positive/negative) of a text, features include: word frequency, word embedding generated vectors, positive/negative words, sentence length, etc.; -
For predicting future weather temperatures, features include: historical temperature values, humidity, air pressure, wind speed, season, time, etc.;
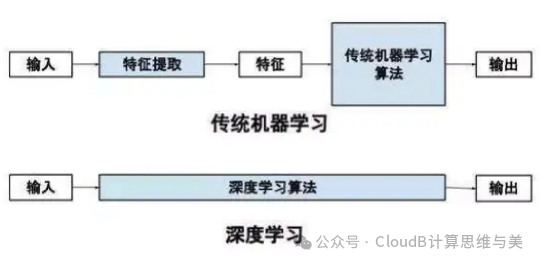
Deep learning can replace traditional feature engineering by automatically learning complex features from data, reducing the need for manual intervention. Specifically, deep learning models (especially deep neural networks) can automatically extract hierarchical features from raw data without relying on manually designed features.

End-to-end learning: the process from raw data to final output can be completely learned by the neural network. Although deep learning has become mainstream in machine learning, traditional feature engineering methods still have their value in scenarios with insufficient data or high interpretability requirements.
Limitations:
-
High data demand Deep learning typically requires a large amount of labeled data for effective training. If the data volume is insufficient, it may not adequately learn effective features. -
High training costs Training deep learning models usually requires powerful computing resources and long time. -
Poor interpretability The “black box” nature of deep learning models makes them harder to interpret than traditional methods, especially in scenarios where model decisions need to be explained, they are less transparent than traditional machine learning methods.
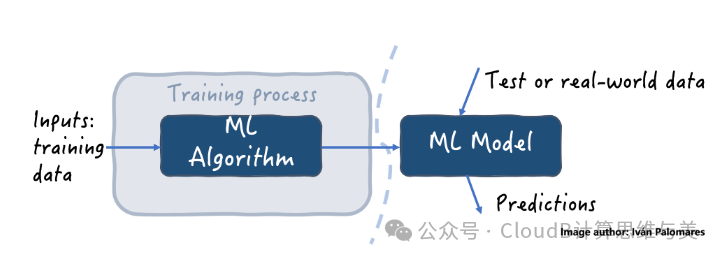
Models and Evaluation
-
Model: The mathematical description abstracted from the data; a good model depends not only on the algorithm and data but also on the task requirements. -
Strategy: Selection and comparison for different models; -
Algorithm: Specific implementation methods, such as how to optimize a mathematical problem?
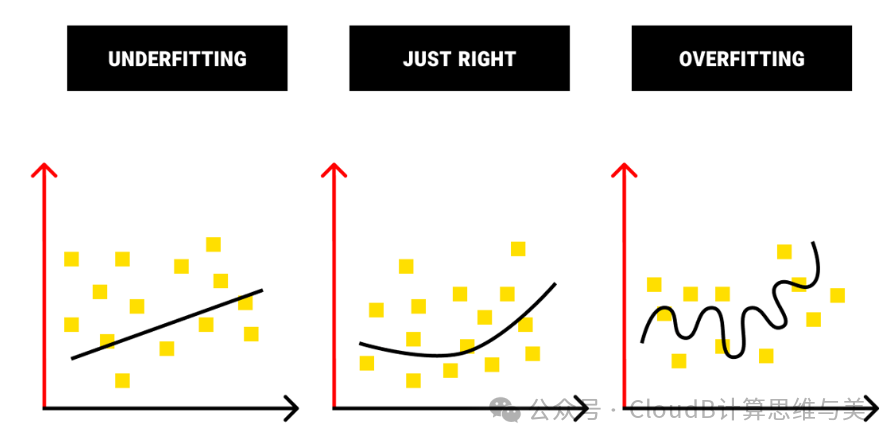
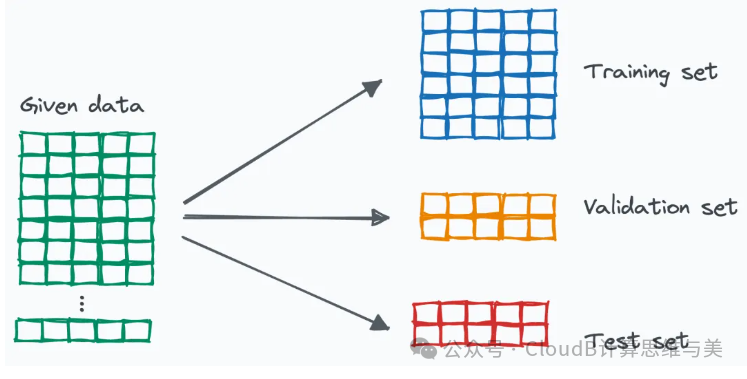
The process of performance analysis and testing for the trained model to determine how the model performs on new data. Therefore, data is usually divided into training set, validation set, and test set.
(1) Training Set, Validation Set, and Test Set
-
Training Set (Training Set) trains the parameters of the machine learning model, estimating the model; -
Validation Set (Validation Set) parameter adjustment during training; Development Set (Dev Set) selects different parameters, controlling the complexity of the model, a more flexible data evaluation set. -
Test Set (Test Set) verifies the performance of the final machine learning system, how the performance of the optimal model is;
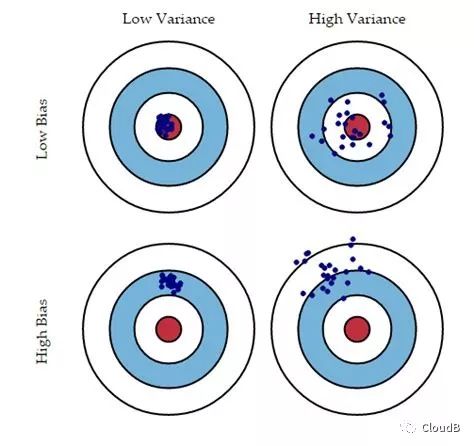

-
Bias: Bias measures the difference between the model’s predicted results and the true values, i.e., the model’s insufficient fit to the training data. -
Variance: Variance measures the model’s sensitivity to noise in the training data, i.e., the extent to which the model overfits the training data.
The bias-variance dilemma: When the model is under-trained, the model’s fitting ability is weak, bias dominates. As training deepens, the model’s fitting ability strengthens, and variance gradually dominates.
(2) Precision vs. Recall
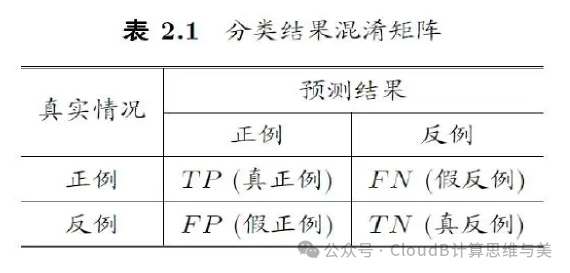
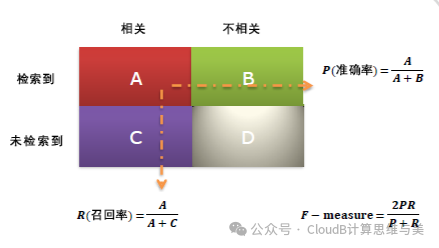


-
Precision = 1400 / (1400 + 300 + 300) = 70%
-
Recall = 1400 / 1400 = 100%
-
F1 Score = 70% * 100% * 2 / (70% + 100%) = 82.35%
-
Recall is the proportion of the target category recalled from the area of interest;
-
And the F1 Score is a comprehensive evaluation metric that reflects both metrics overall.
Optimization
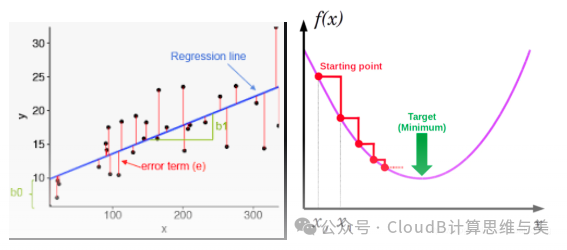
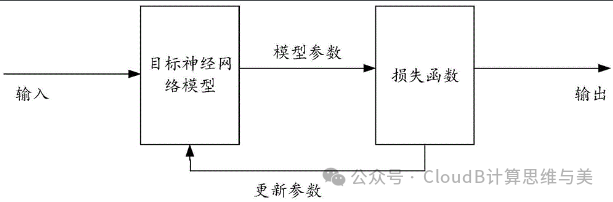
Most optimization problems in machine learning can be reduced to minimization problems, that is, finding parameters that minimize the loss function.

1. Parameter Optimization Problems
Logistic Regression: Minimize the Cross-Entropy loss function to find the optimal classification parameters.
2. Regularization Optimization Problems
To prevent overfitting, we usually add a regularization term to the objective function. For example:
-
L2 Regularization: (also known as Ridge Regression) adds the sum of squares of parameters. -
L1 Regularization: (also known as Lasso Regression): adds the sum of absolute values of parameters.
These regularization terms increase the complexity of the optimization problem, aiming to find a solution that can both fit the data and avoid overfitting.
3. Neural Network Optimization Problems
Training a neural network is also an optimization problem, typically optimized using backpropagation to adjust the weights and biases of the neural network. When training a neural network:
-
The objective function is the loss function (such as cross-entropy loss, mean squared error loss). -
The optimization process adjusts the network’s weights and biases using methods like gradient descent.
The optimization problem for neural networks often has multiple local minima or saddle points, making it more complex than traditional linear models.
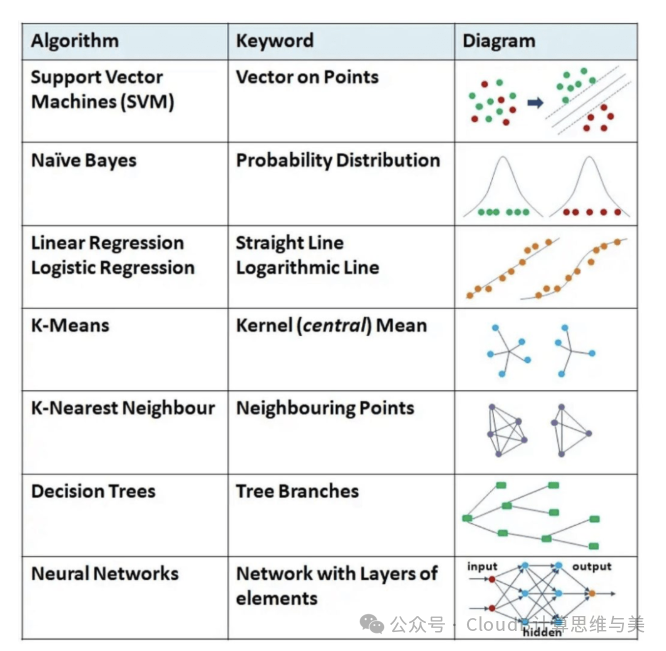
4. Support Vector Machine (SVM) Optimization Problems
The goal of SVM is to maximize the margin of the classification boundary, separating two classes of data points while minimizing classification errors. The optimization problem includes:
-
The objective function: maximizing the margin (i.e., minimizing the objective function) while satisfying certain classification accuracy. -
SVM optimization problems typically involve constraints (for example, soft margin support vector machines).
Optimization Algorithms:
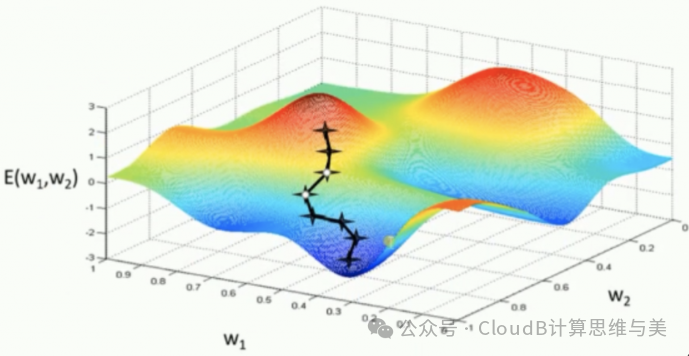
-
Gradient Descent is a common optimization method used to minimize the objective function. The algorithm adjusts parameters based on the gradient (derivative) of the loss function concerning the model parameters. -
Momentum is an improvement of gradient descent that adds “inertia” of past gradients, adjusting the direction of parameter updates to accelerate convergence and avoid oscillations. -
Adam (Adaptive Moment Estimation): Adam is a commonly used optimization algorithm that combines the advantages of gradient descent and momentum, capable of adaptively adjusting the learning rate of each parameter, widely used in deep learning.
[ Disclaimer ] The reproduction is for non-commercial educational and research purposes, solely for the dissemination of academic news information. The copyright belongs to the original author. If there is any infringement, please contact us immediately, and we will delete it promptly.
