
Report by Machine Heart
Machine Heart Editorial Team
This article conducts a controlled variable experiment on the reasoning step length of the thinking chain, finding that the reasoning step length is linearly correlated with the accuracy of the answers, and this influence mechanism even transcends the differences generated by the problem itself.
Today, the emergence of large language models (LLMs) and their advanced prompting strategies marks a significant progress in the research of language models, especially in classic NLP tasks. A key innovation among these is the Chain of Thought (CoT) prompting technique, which is well-known for its ability to solve multi-step problems. This technique follows the sequential reasoning of humans and has exhibited excellent performance across various challenges, including cross-domain, long generalization, and cross-lingual tasks. CoT and its logical, step-by-step reasoning approach provide critical interpretability in complex problem-solving scenarios.
Despite the substantial progress made by CoT, there is still no consensus in the research community regarding the specific mechanisms and effective reasons behind CoT and its variants. This knowledge gap means that improving CoT performance remains an exploratory field. This exploration mainly relies on trial and error, as there is currently a lack of systematic methodologies for enhancing CoT effectiveness, leaving researchers to rely on guesses and experiments. However, this also indicates significant research opportunities in the field: forming a deeper and more structured understanding of the internal workings of CoT. Achieving this goal could not only unveil the mysteries of the current CoT process but also pave the way for more reliable and efficient applications of this technology in various complex NLP tasks.
Researchers from Northwestern University, the University of Liverpool, and New Jersey Institute of Technology further explored the relationship between the length of reasoning steps and the accuracy of conclusions, helping deepen the understanding of how to effectively solve NLP problems. The following article investigates whether the reasoning steps are the most critical part of the prompts that drive CoT to function effectively (see Figure 1). In the experiments of this article, strict controlled variables were maintained, especially when adding new reasoning steps, ensuring that no additional knowledge was introduced. In zero-shot experiments, researchers adjusted the initial prompt from “Please think step by step” to “Please think step by step and think of as many steps as possible.” For small sample problems, researchers designed an experiment to expand the basic reasoning steps while keeping all other factors constant.

-
Paper Title: The Impact of Reasoning Step Length on Large Language Models
-
Paper Link: https://arxiv.org/pdf/2401.04925.pdf
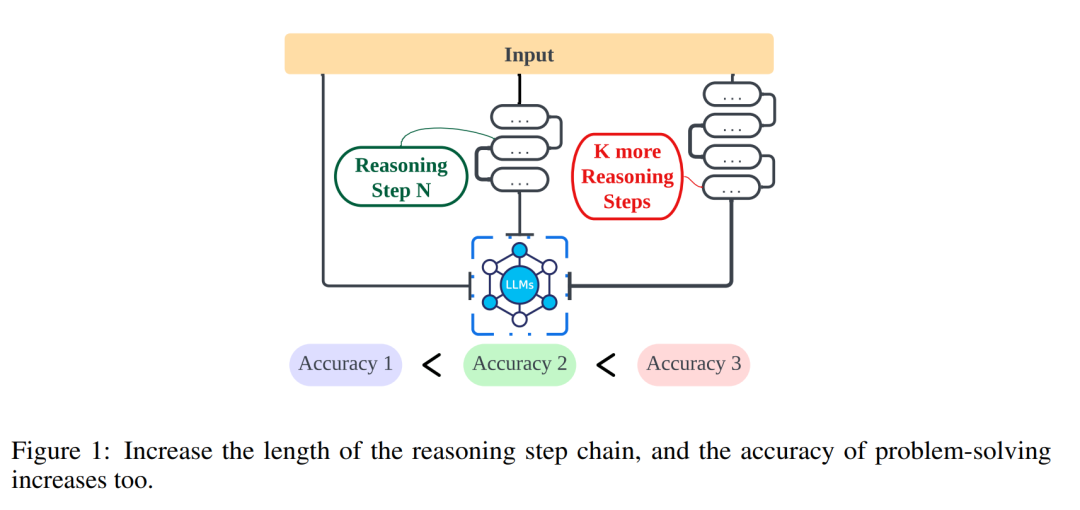
The first set of experiments in this article evaluated the improvement in reasoning performance using the Auto-CoT technique under the above strategy in both zero-shot and small-sample tasks. Subsequently, this article assessed the accuracy of different methods at different reasoning step counts. Researchers then expanded the survey subjects to compare the effectiveness of the strategies proposed in this article across different LLMs (such as GPT-3.5 and GPT-4). The results indicate that there is a significant correlation between the length of the reasoning chain and the capabilities of LLMs within a certain range. Interestingly, when misleading information was introduced into the reasoning chain, performance still improved. This leads to an important conclusion: the key factor affecting performance seems to be the length of the thinking chain, rather than its accuracy.
The main findings of this article are as follows:
-
For small sample CoT, there is a direct linear relationship between the number of reasoning steps and accuracy. This provides a quantifiable method for optimizing CoT prompts in complex reasoning. Specifically, increasing the reasoning steps in the prompt significantly enhances the reasoning capabilities of LLMs across multiple datasets. Conversely, even when retaining key information, shortening the reasoning steps significantly weakens the model’s reasoning ability.
-
Even incorrect reasoning can yield favorable results if the necessary reasoning length is maintained. For instance, in tasks like mathematical problems, intermediate numbers generated during the process are less likely to affect the final result.
-
The magnitude of the benefits generated by increasing reasoning steps is limited by the task itself: simpler tasks require fewer steps, while more complex tasks gain significant benefits from longer reasoning sequences.
-
Increasing the reasoning steps in zero-shot CoT can also significantly enhance the accuracy of LLMs.
Research Methodology
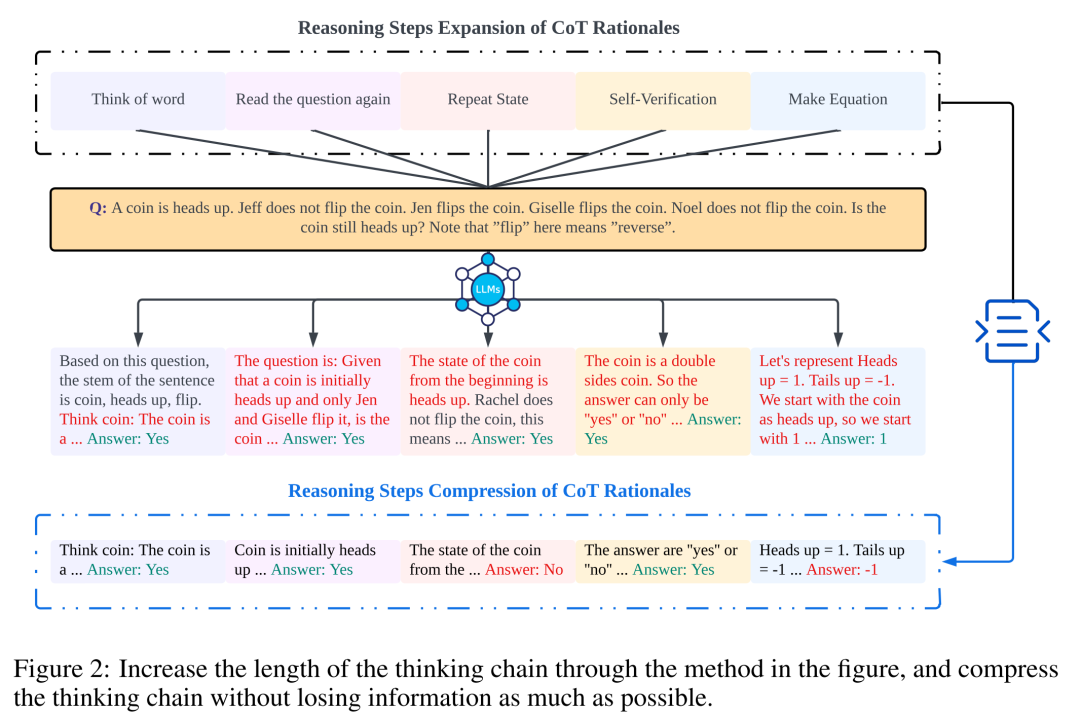
The researchers examined the relationship between the number of reasoning steps and the performance of CoT prompts through analysis. The core hypothesis of the method is that the serialized steps in the reasoning process are the most critical components of CoT prompts, enabling language models to apply more logic in reasoning when generating responses. To test this viewpoint, this article designed an experiment to sequentially expand and compress the basic reasoning steps during the CoT reasoning process while keeping all other factors unchanged. Specifically, the researchers systematically altered only the number of reasoning steps without introducing new reasoning content or removing existing reasoning content. The researchers evaluated zero-shot and few-shot CoT prompts in the following sections. The entire experimental process is illustrated in Figure 2. Through this controlled variable analysis method, the researchers clarified how CoT influences the ability of LLMs to generate logically sound responses.
Zero-shot CoT Analysis
In zero-shot scenarios, researchers modified the initial prompt from “Please think step by step” to “Please think step by step and think of as many steps as possible.” This change was made because, unlike the few-shot CoT environment, users cannot introduce additional reasoning steps during use. By altering the initial prompt, researchers guided the LLM to engage in broader thinking. The significance of this method lies in its ability to improve model accuracy without requiring the typical schemes in few-shot scenarios: incremental training or additional example-driven optimization methods. This refined strategy ensures a more comprehensive and detailed reasoning process, significantly enhancing the model’s performance under zero-shot conditions.
Few-shot CoT Analysis
This section modifies the reasoning chain in CoT by increasing or compressing reasoning steps. The goal is to study how changes in the reasoning structure affect LLM decision-making. During the expansion of reasoning steps, researchers must avoid introducing any new task-related information. Thus, the reasoning steps become the sole variable under investigation.
To this end, researchers designed the following research strategies to expand the reasoning steps of different LLM applications. The way people think about problems usually follows fixed patterns, such as repeatedly revisiting the problem to gain deeper understanding, creating mathematical equations to alleviate memory load, analyzing the meanings of words in the problem to aid comprehension of the subject, and summarizing the current state to simplify the description of the subject. Inspired by zero-shot CoT and Auto-CoT, researchers expect the CoT process to become a standardized pattern and achieve correct results by limiting the direction of CoT thinking in the prompt section. The core of this article’s method is to simulate human thinking processes and reshape the thinking chain. Table 6 presents five common prompt strategies.

-
Word Thinking: This strategy requires the model to explain words and reconstruct its knowledge base. Typically, a word has multiple meanings, and this approach allows the model to think outside the box and reinterpret words in the problem based on the generated explanations. This process does not introduce new information. In the prompt, researchers provide examples of words the model is considering, and the model will automatically select words to engage in this process based on the new problem.
-
Problem Reload: Repeatedly reading the problem reduces interference from other texts in the thinking chain. In short, it helps the model remember the problem.
-
State Repetition: Similar to repeatedly reading, adding a brief summary of the current state after a long series of reasoning helps the model simplify memory and reduces interference from other texts in CoT.
-
Self-Verification: Humans check their answers for correctness when answering questions. Therefore, before the model arrives at an answer, researchers added a self-verification process to assess whether the answer is reasonable based on some basic information.
-
Equation Preparation: For mathematical problems, creating formulas can help humans summarize and simplify memory. For problems requiring assumptions of unknowns like x, establishing equations is an essential process. Researchers simulated this process and allowed the model to attempt to create equations in mathematical problems.
Overall, the immediate strategies of this article are reflected in the model. The content shown in Table 1 is one example, and other examples of the four strategies can be found in the original paper.

Experiments and Results
The Relationship Between Reasoning Steps and Accuracy
Table 2 compares the accuracy of using GPT-3.5-turbo-1106 across eight datasets in three categories of reasoning tasks.
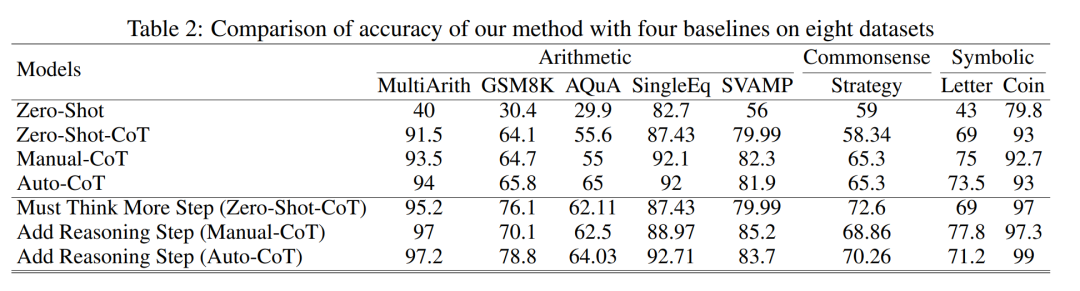
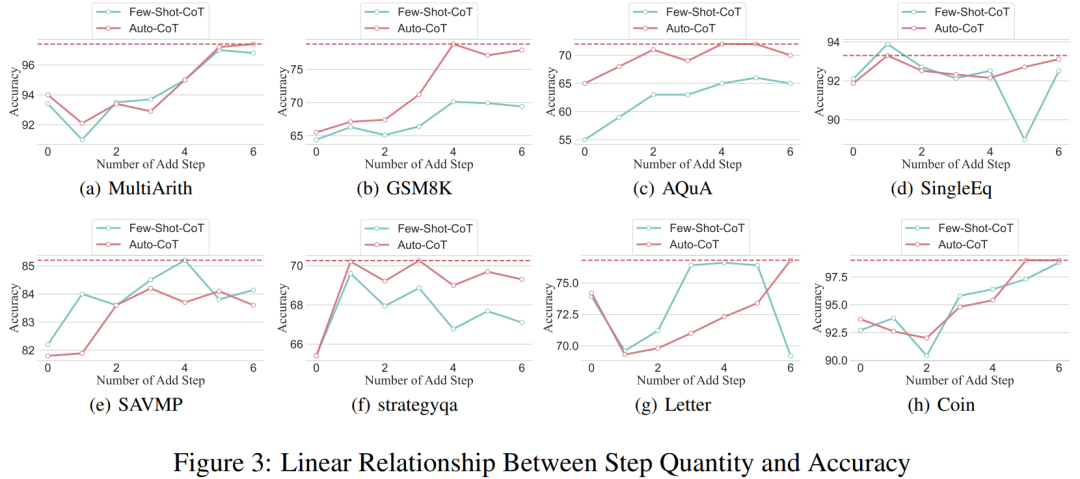
Thanks to the researchers’ ability to standardize the CoT process, they can now quantify the extent to which increasing steps in the basic CoT process improves accuracy. The results of this experiment can answer the previous question: what is the relationship between reasoning steps and CoT performance? This experiment is based on the GPT-3.5-turbo-1106 model. The researchers found that an effective CoT process, such as adding up to six additional reasoning steps in the CoT process, enhances the reasoning capabilities of large language models across all datasets. In other words, the researchers discovered a certain linear relationship between accuracy and CoT complexity.
The Impact of Incorrect Answers
Is the number of reasoning steps the only factor affecting LLM performance? The researchers conducted the following attempts. They changed one step in the prompt to an incorrect description to see if it would affect the thinking chain. For this experiment, the authors added an error to all prompts. For specific examples, please refer to Table 3.

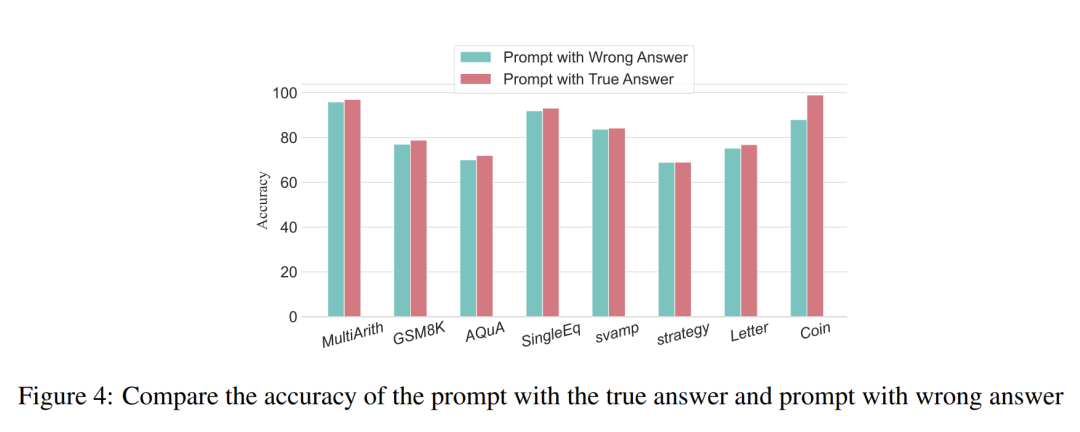
For arithmetic-type questions, even if one of the prompt results deviates, the impact on the reasoning chain during the process is minimal. Therefore, the researchers believe that when solving arithmetic-type problems, large language models learn more from the thinking pattern chains in the prompts than from individual calculations. For logical problems like coin data, a deviation in one prompt result often leads to the fragmentation of the entire thinking chain. The researchers also used GPT-3.5-turbo-1106 to complete this experiment and ensured performance based on the best number of steps for each dataset derived from previous experiments. The results are shown in Figure 4.
Compressing Reasoning Steps
Previous experiments have demonstrated that increasing reasoning steps can enhance the accuracy of LLM reasoning. So, does compressing the basic reasoning steps in small sample problems harm LLM performance? To investigate this, the researchers conducted reasoning step compression experiments and adopted the techniques outlined in the experimental setup to condense the reasoning process into Auto CoT and Few-Shot-CoT, thereby reducing the number of reasoning steps. The results are shown in Figure 5.
The results indicate a significant decline in the model’s performance, reverting to a level comparable to the zero-shot method. This result further suggests that increasing CoT reasoning steps can enhance CoT performance, and vice versa.
Performance Comparison of Different Specification Models
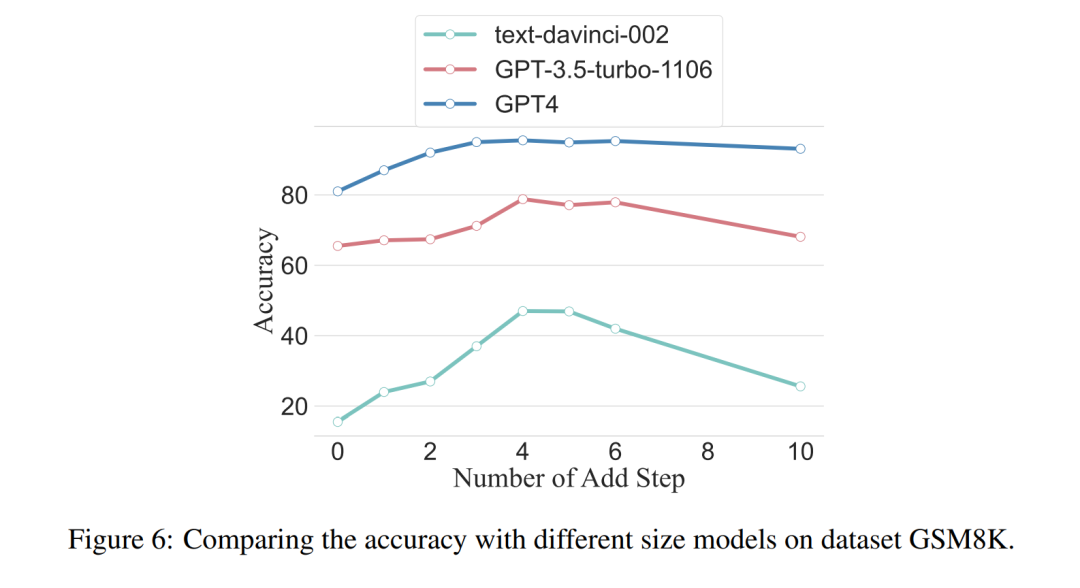
The researchers also questioned whether we could observe a scaling phenomenon, namely whether the required reasoning steps are related to the size of the LLM. They investigated the average number of reasoning steps used across various models (including text-davinci-002, GPT-3.5-turbo-1106, and GPT-4). The average reasoning steps required for each model to achieve peak performance were calculated through experiments on GSM8K. In eight datasets, this dataset exhibited the largest performance differences among text-davinci-002, GPT-3.5-turbo-1106, and GPT-4. It can be observed that the proposed strategy has the highest enhancement effect in the initially poorest performance model, text-davinci-002. The results are shown in Figure 6.
The Impact of Problems in Collaborative Work Instances
What is the impact of problems on LLM reasoning capabilities? The researchers wanted to explore whether changing the reasoning of CoT would affect its performance. Since this article primarily studies the impact of reasoning steps on performance, the researchers needed to confirm that the problems themselves did not influence performance. Therefore, the researchers chose the datasets MultiArith and GSM8K and conducted experiments with two CoT methods (auto-CoT and few-shot-CoT) in GPT-3.5-turbo-1106. The experimental methods of this article included intentional modifications to the sample problems in these mathematical datasets, such as changing the content of the problems in Table 4.

It is worth noting that preliminary observations suggest that these modifications to the problems themselves have the least impact on performance among several factors, as shown in Table 5.
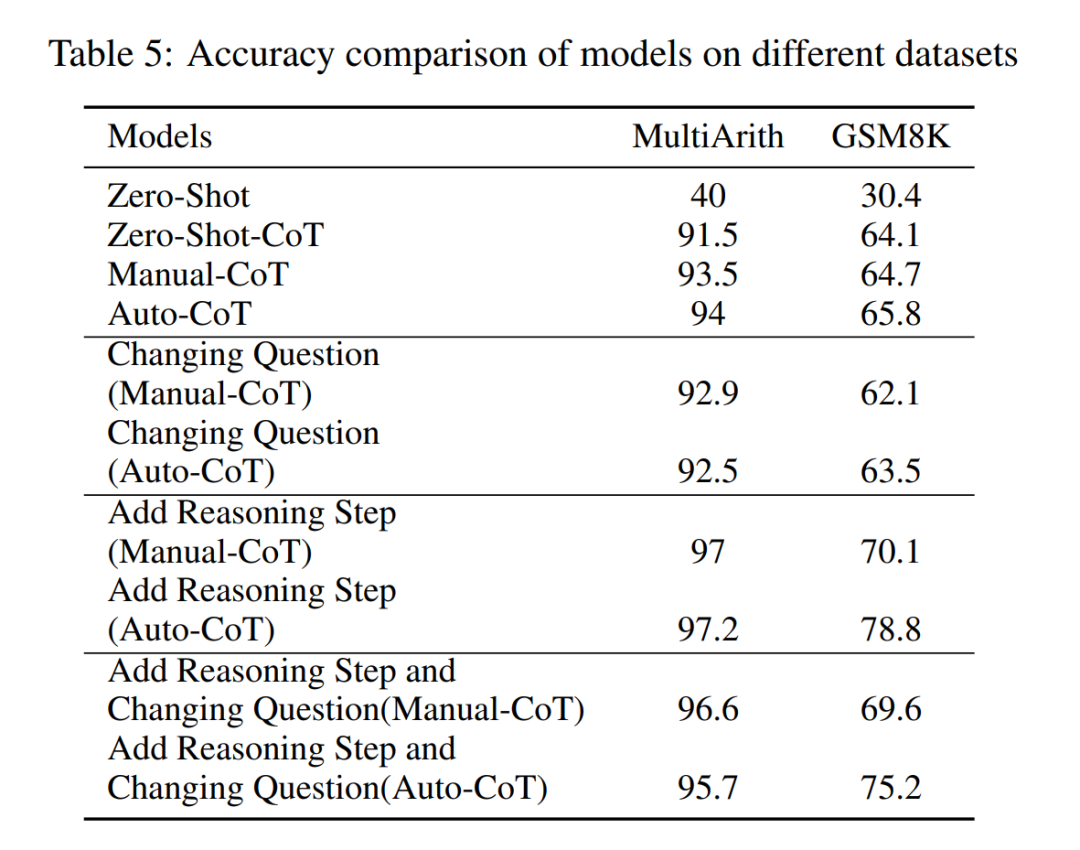
This preliminary finding suggests that the length of the steps in the reasoning process is the primary influencing factor on the reasoning capabilities of large models, while the impact of the problems themselves is not the largest.
For more details, please read the original paper.

© THE END
For reprints, please contact this public account for authorization
Submission or inquiries: [email protected]