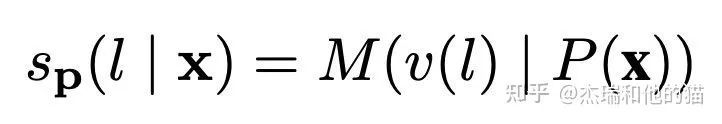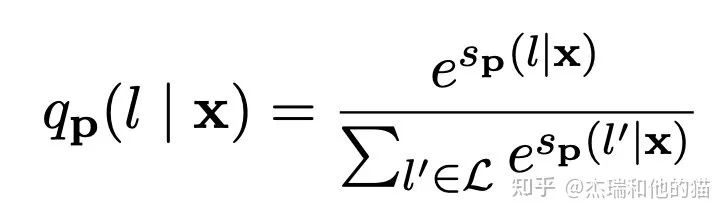MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate and doctoral students, university teachers, and corporate researchers.The community’s vision is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Reprinted from | Xixiaoyao’s Cute HouseAuthor|Jerry and His Cat @ ZhihuIn recent years, the NLP academic field has developed rapidly, from the recent popularity of contrastive learning to the even hotter prompt learning. As we know, data annotation largely determines the upper limit of AI algorithms and is very costly. Both contrastive learning and prompt learning focus on solving few-shot learning, allowing models to perform well even without labeled data. This article mainly introduces the ideas of prompt learning and currently commonly used methods.Zhihu link:https://zhuanlan.zhihu.com/p/595178668
Table of Contents
1. What are the training paradigms of NLP? 2. Why is prompt learning needed? 3. What is prompt learning? 4. Common prompt learning methods 5. Conclusion
1. What are the training paradigms of NLP?
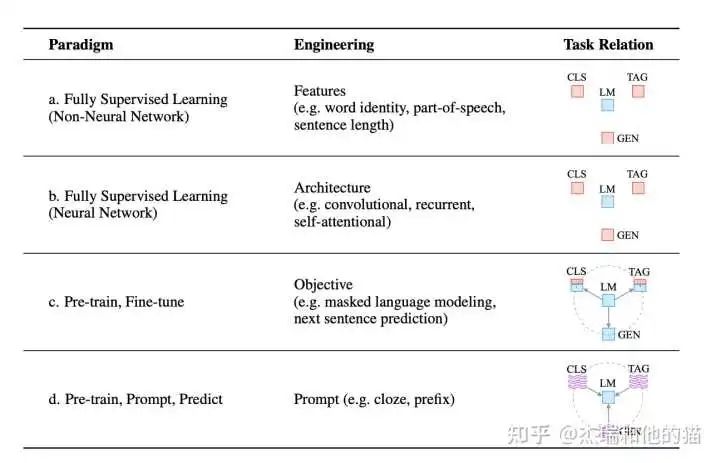
Currently, the academic community generally divides the development of NLP tasks into four stages, namely the four paradigms of NLP:
The first paradigm: based on “traditional machine learning models,” such as tf-idf features + Naive Bayes and other machine algorithms;
The second paradigm: based on “deep learning models,” such as word2vec features + LSTM and other deep learning algorithms, which improve model accuracy compared to the first paradigm and reduce the workload of feature engineering;
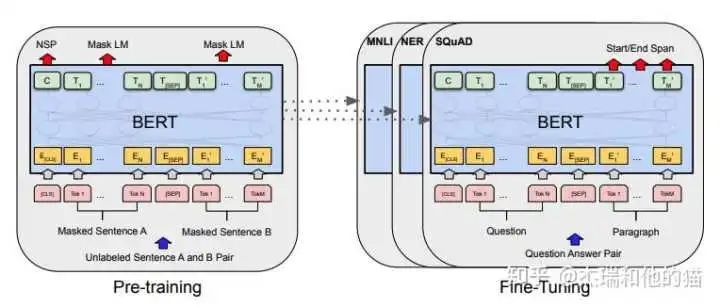
The third paradigm: based on “pre-trained models + fine-tuning,” such as BERT + fine-tuning for NLP tasks, which significantly improves model accuracy compared to the second paradigm, but the model also becomes larger; however, good models can be trained on small datasets;
The fourth paradigm: based on “pre-trained models + Prompt + Prediction,” such as BERT + Prompt, which significantly reduces the amount of training data required for model training compared to the third paradigm.
Throughout the NLP field, you will find that the entire development is moving towards higher accuracy, less supervision, and even unsupervised directions, while Prompt Learning is currently the latest and hottest research achievement in this direction.
2. Why is prompt learning needed?
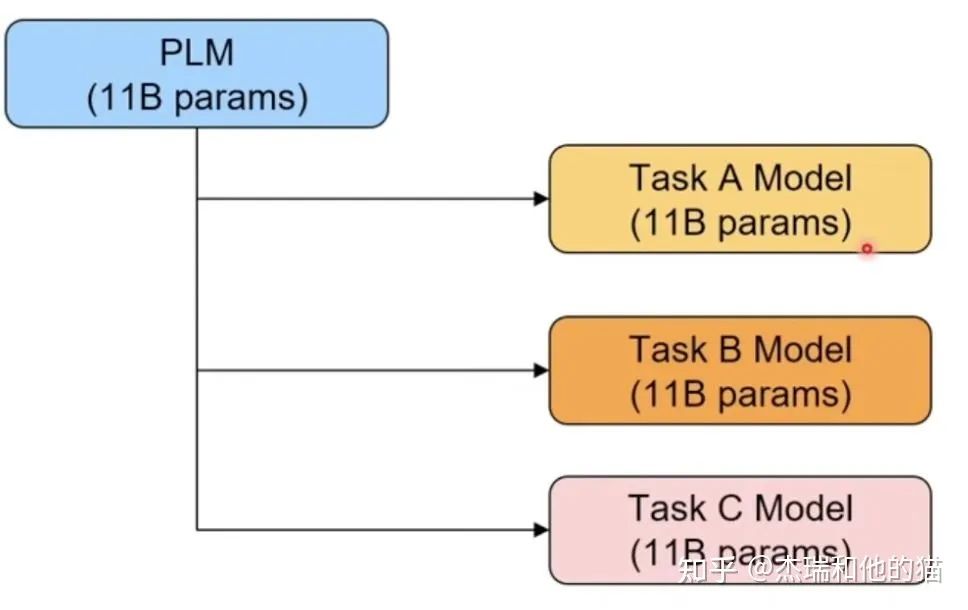
To propose a good method, it must be used to “solve the defects or shortcomings of another method.” So let’s start with its previous paradigm, which is the pre-trained model PLM + fine-tuning paradigm, commonly used is BERT + fine-tuning:This paradigm aims to better apply pre-trained models to downstream tasks, requiring fine-tuning of model parameters using downstream data. First, the model during “pre-training adopts training forms: autoregressive and autoencoding, which has a huge gap with the downstream task forms,” which cannot fully utilize the capabilities of the pre-trained model itself, inevitably leading to: needing more data to adapt to the new task form —> poor few-shot learning ability, prone to overfitting.There is a gap between upstream and downstream task forms. Secondly, the current pre-trained model parameters are becoming larger and larger. Fine-tuning a model for a specific task and then deploying it in online services can also lead to a significant waste of deployment resources.Model specificity for specific tasks leads to excessively high deployment costs.
3. What is prompt learning?
First, we should have the “consensus” that there is a lot of knowledge in pre-trained models; the pre-trained model itself has few-shot learning capabilities. The In-Context Learning proposed by GPT-3 also effectively proves that in zero-shot and few-shot scenarios, the model can achieve good results without any parameters, especially in the recent popular GPT-3.5 series, including ChatGPT.
The Essence of Prompt Learning
Unify all downstream tasks into pre-training tasks; “using specific templates, convert downstream task data into natural language forms,” fully tapping the capabilities of the pre-trained model itself. Essentially, it is about designing a template that fits the upstream pre-training task, through the design of the template to “exploit the potential of the upstream pre-trained model,” allowing the upstream pre-trained model to perform downstream tasks well with minimal labeled data. The key includes three steps:
Design the task of the pre-trained language model
Design input template styles (Prompt Engineering)
Design label styles and the method for the model’s output mapping to labels (Answer Engineering)
The Forms of Prompt Learning
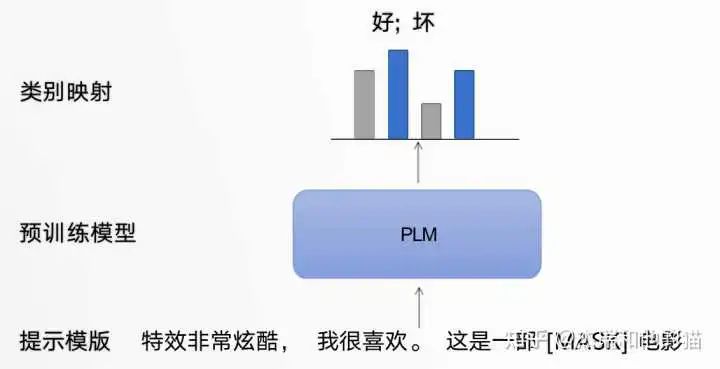
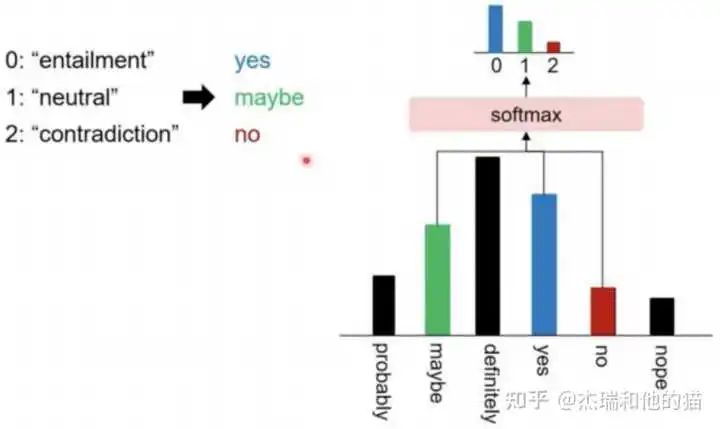
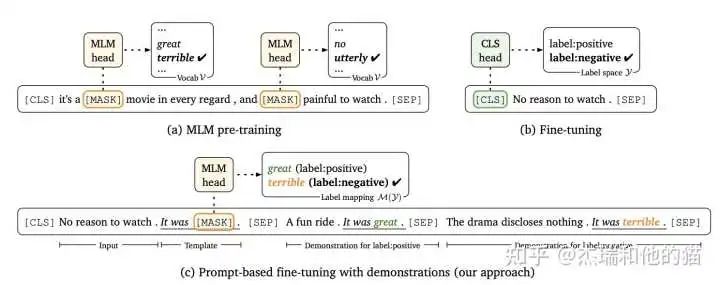
Taking the movie review sentiment classification task as an example, the model needs to classify based on the input sentence: Original input: The special effects are very cool, I like it. Prompt input: “Prompt Template 1”: The special effects are very cool, I like it. This is a [MASK] movie; “Prompt Template 2”: The special effects are very cool, I like it. This movie is very [MASK]. The role of the prompt template is to convert the training data into natural language forms and mask at appropriate positions to stimulate the capabilities of the pre-trained model.
The prompt learning template framework category mapping/Verbalizer: select appropriate prediction words and map these words to different categories.Category mapping through constructing prompt learning samples, only requires a small amount of data for Prompt Tuning to achieve good results, demonstrating strong zero-shot/few-shot learning capabilities.
4. Common Prompt Learning Methods
1. Hard Template Method
1.1 Hard Template – PET (Pattern Exploiting Training) PET is a classic prompt learning method, similar to previous examples, modeling the problem as a cloze task and optimizing the final output word. Although PET also “optimizes the parameters of the entire model,” it requires “less data” compared to traditional fine-tuning methods. The modeling method: previously the model only needed to model P(l|x) (l is label), but now it adds Prompt P and label mapping (the author calls it verbalizer), so this problem can be updated to:
Where M represents the model, s corresponds to the logits of the word generated under a certain prompt. Then through softmax, the probability can be obtained:The author also added “MLM loss” during training for joint training.The specific approach:
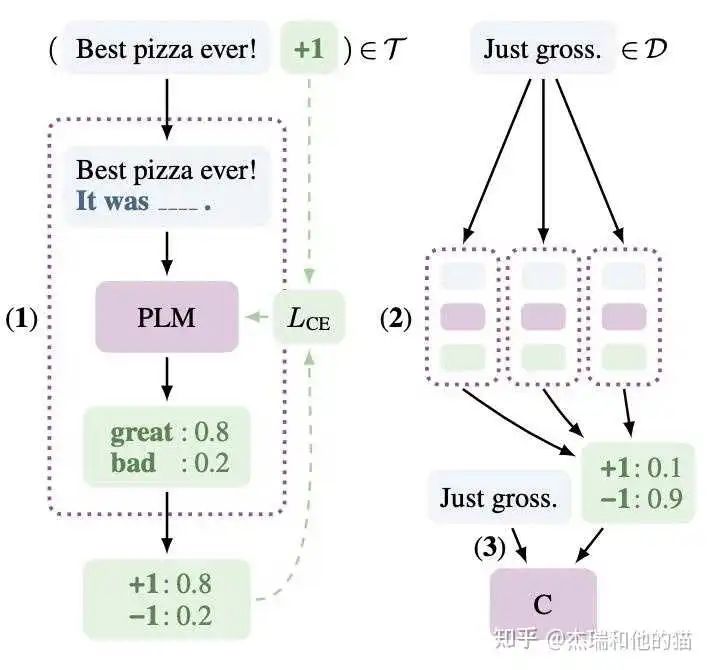
Train a model for each prompt on a small amount of supervised data;
For unsupervised data, integrate the prediction results of multiple prompts from the same sample, using averaging or weighting (assigning weights based on accuracy), and then normalize to obtain a probability distribution as the soft label for unsupervised data;
Fine-tune a final model on the obtained soft label.
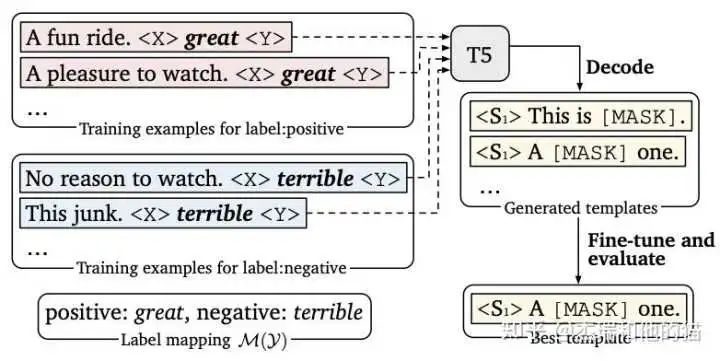
1.2 Hard Template – LM-BFF LM-BFF is a work by Chen Tianqi’s team, proposing Prompt Tuning with demonstration & Auto Prompt Generation based on Prompt Tuning.
“Defects of Hard Template Methods”: Hard templates rely on two methods: manual design based on experience & automated search. However, manually designed templates are not necessarily better than automatically searched ones, and the readability and interpretability of automated searches are also not strong.The experimental results in the figure above show that for prompts, changing a single word in the prompt can lead to significant differences in experimental results, providing directions for subsequent optimization, such as simply giving up hard templates and optimizing prompt token embedding instead.
2. Soft Template Method
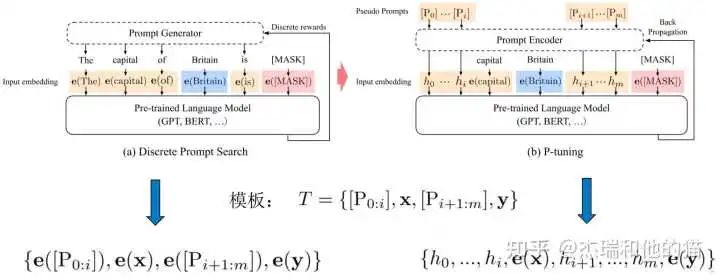
2.1 Soft Template – P Tuning no longer designs/searches hard templates but directly inserts several optimizable Pseudo Prompt Tokens at the input end, “automatically seeking knowledge templates” in continuous space:
Does not rely on manual design
Only a small number of parameters need to be optimized, avoiding overfitting (can also fully fine-tune, degrading to traditional fine-tuning)
Traditional discrete prompts directly map each token of the template T to the corresponding embedding, while P-Tuning maps the Pi (Pseudo Prompt) in the template T to a “trainable parameter hi.” The “key optimization point” lies in replacing the hard prompt of natural language with a trainable soft prompt; using a bidirectional LSTM to represent the sequence of pseudo tokens in the template T; introducing a few natural language prompt anchor characters (Anchor) to improve efficiency, such as the “capital” in the figure above. P-Tuning is a hybrid of hard and soft forms, not entirely soft. The specific approach:
Initialize a template: The capital of [X] is [mask]
Replace input: Replace [X] with the input “Britain,” predicting the capital of Britain
Select one or more tokens in the template as soft prompts
Feed all soft prompts into LSTM to obtain the “hidden state vector h” for each soft prompt
Feed the initial template into BERT’s Embedding Layer, replacing the token embeddings of all soft prompts with h, then predicting the mask.
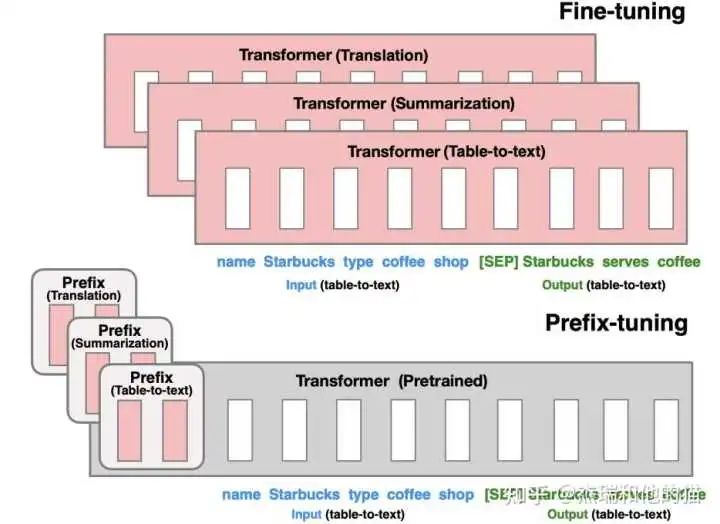
Core conclusion: Based on full data, large models: only fine-tune the parameters related to the prompt, achieving performance comparable to fine-tuning. Code: https://github.com/THUDM/2.2 Soft Template – Prefix Tuning P-tuning updates the method of prompt token embedding, optimizing fewer parameters. Prefix tuning aims to optimize more parameters to improve effectiveness without bringing excessive burden. Although prefix tuning was proposed for generative tasks, it has an enlightening impact on the subsequent development of soft prompts.
Optimize the Prompt token embedding at each layer, not just the input layer. From the figure above, it can be seen that the prefix is added before each layer of the transformer. The characteristic is that the prefix is not a real token but a “continuous vector” (soft prompt). During Prefix-tuning training, the parameters of the transformer are frozen, only the parameters of the Prefix are updated. Only one copy of the large transformer and the learned task-specific prefix need to be stored, resulting in very small overhead for each additional task.For autoregressive models, the approach based on the autoregressive model shown in the figure above is as follows:
Input represented as Z = [ prefix ; x ; y ]
Prefix-tuning initializes a trained matrix P to store prefix parameters
Token in the prefix part, parameter selection is designed training matrix, while parameters for other tokens are fixed and are the parameters of the pre-trained language model.
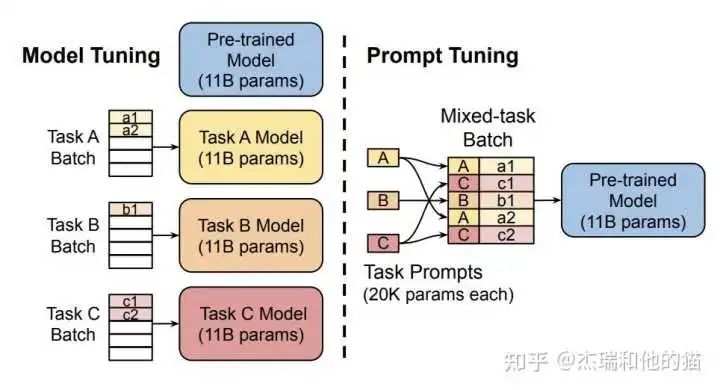
Core conclusion: Prefix-tuning in generative tasks, full data, large models: only fine-tune the parameters related to the prompt, achieving performance comparable to fine-tuning.Code:https://github.com/XiangLi1999/PrefixTuning2.3 Soft Template – Soft Prompt TuningSoft Prompt Tuning validated the effectiveness of the soft template method and proposed: fixing the base model and effectively utilizing task-specific Soft Prompt Tokens can greatly reduce resource consumption, achieving the generality of large models.A simplification of Prefix-tuning, fixing the pre-trained model, only adding “k” additional learnable tokens to the input of downstream tasks. This method can achieve performance comparable to traditional fine-tuning under the premise of large-scale pre-trained models.Code:https://github.com/kipgparker/soft-prompt-tuning
5. Conclusion
Components of Prompt Learning
Prompt templates: Constructing cloze or prefix generation templates based on the use of pre-trained models.
Category mapping/Verbalizer: Selecting appropriate category mapping words based on experience.
Summary of Typical Prompt Learning Methods
Hard template methods: manually designed/automatically constructed templates based on discrete tokens 1) PET 2) LM-BFF
Soft template methods: no longer pursuing the intuitive interpretability of templates but directly optimizing Prompt Token Embedding, which are vectors/trainable parameters 1) P-tuning 2) Prefix Tuning
Subsequently, attempts will be made in classification and information extraction tasks using Prompt Learning, with ongoing updates…Technical Group Invitation
△ Long press to add assistant
Scan the QR code to add assistant WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue System)to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by machine learning and natural language processing scholars from home and abroad. It has now developed into a well-known community for machine learning and natural language processing, aimed at promoting progress between the academic and industrial sectors of machine learning and natural language processing, as well as enthusiasts.The community can provide an open communication platform for practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.