
This article mainly introduces prompt design, supervised fine-tuning of large language models (SFT), and the application of LLM in the mobile Tmall AI shopping assistant project.

In summary, it can be broken down into the following steps:
-
Preprocess text: The input text for ChatGPT needs to be preprocessed.
-
Input encoding: ChatGPT encodes the preprocessed text into the neural network using a multi-layer transformer encoder structure.
-
Predict output: ChatGPT predicts the next most likely token sequence by predicting each token in turn, using the softmax function for probability prediction.
-
Output decoding: ChatGPT takes the predicted token sequence as input, decodes it through a multi-layer transformer decoder structure, and finally outputs the model’s response.
-
Repeat steps 3 and 4: ChatGPT continues to output the predicted token sequence while processing input until it encounters a stop symbol or reaches the maximum output length.
Algorithm Core — Transformer
Composed of Encoder and Decoder
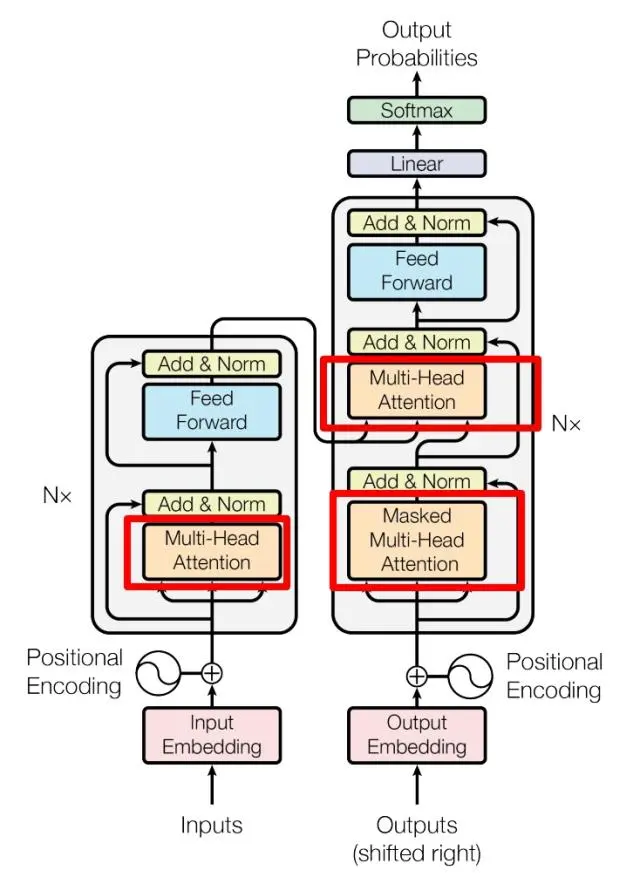
Encoding and decoding animation

It seems different from what I want to share today. Add a specific constraint, and then?

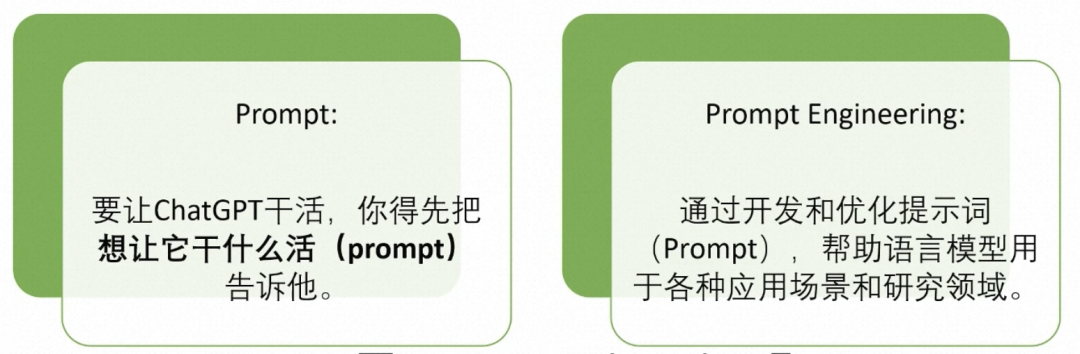
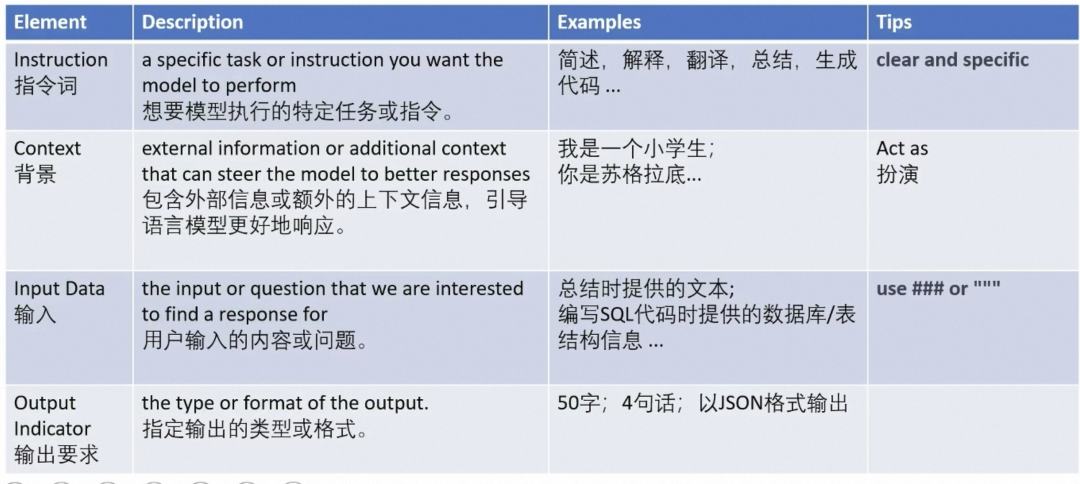
1. Clear, specific, avoid vague terms
| bad case | good case |
| Product descriptions should not be too short, a few sentences are fine, and not particularly many | Use 3 to 5 short phrases to describe the product |
|
Write a poem for mobile Tmall
|
Write a four-line ancient poem for mobile Tmall, imitating Li Bai’s “Early Departure from Baidi City”
|


| bad case | good case |
| Summarize the following content in one sentence. You should provide as clear and specific instructions as possible to express what you want the model to do. This will guide the model towards the expected output and reduce the likelihood of receiving irrelevant or incorrect responses. Do not confuse writing a clear prompt with writing a brief prompt. In many cases, longer prompts provide more clarity and context, which can lead to more detailed and relevant outputs. |
Summarize the following content enclosed in three quotes into one sentence: The text to be summarized is: ”’ You should provide as clear and specific instructions as possible to express what you want the model to do. This will guide the model towards the expected output and reduce the likelihood of receiving irrelevant or incorrect responses. Do not confuse writing a clear prompt with writing a brief prompt. In many cases, longer prompts provide more clarity and context, which can lead to more detailed and relevant outputs. ”’ |
3. Specify output format
| bad case | good case |
|
Generate three fictional book titles, including their authors and genres.
|
Generate three fictional book titles, including their authors and genres. Provide in JSON list format, including the following keys: book_id, title, author, genre
|


4. Role-playing, use terms like role-play or act to inform the model of a specific persona or role in the conversation
| bad case | good case |
|
Sell me a men’s facial cleanser
|
system: I want you to act as a professional shopping guide. You can use your e-commerce knowledge and shopping skills to vividly introduce and promote products to customers. user: Sell me a men’s facial cleanser
|


Enable context in-context learning by providing several examples in the prompt (here is only one example, one-shot)

▐ Chain of Thought (CoT)
Chain of Thought (CoT) is an improved prompting strategy used to enhance LLM performance in complex reasoning tasks, such as arithmetic reasoning, common sense reasoning, and symbolic reasoning.
| one-shot | CoT |
|
model input: Q: Xiao Ming has 5 balls, and he bought 2 baskets, each containing 3 balls. How many balls does he have now? A: The answer is 11 Q: Xiao Hua has 23 apples, they used 20 for lunch, and bought 6 more. How many apples are left now? model output:
|
model input: Q: Xiao Ming has 5 balls, and he bought 2 baskets, each containing 3 balls. How many balls does he have now? A: Xiao Ming starts with 5 balls, buys 6 balls in total from 2 baskets, totaling 11 balls. The answer is 11 Q: Xiao Hua has 23 apples, they used 20 for lunch, and bought 6 more. How many apples are left now? model output:
|


The above examples stimulate the potential of large models well. Are there problems that prompt techniques cannot solve?
The answer is yes, some real-time problems and knowledge gaps during model training cannot be addressed.
▐ Search API & GPT

"""Web search results:{web_results}
Current date:{current_date}
Instruction: Summarize the user query using the given web search results
User Query: {query}
Response language: {reply_language}"""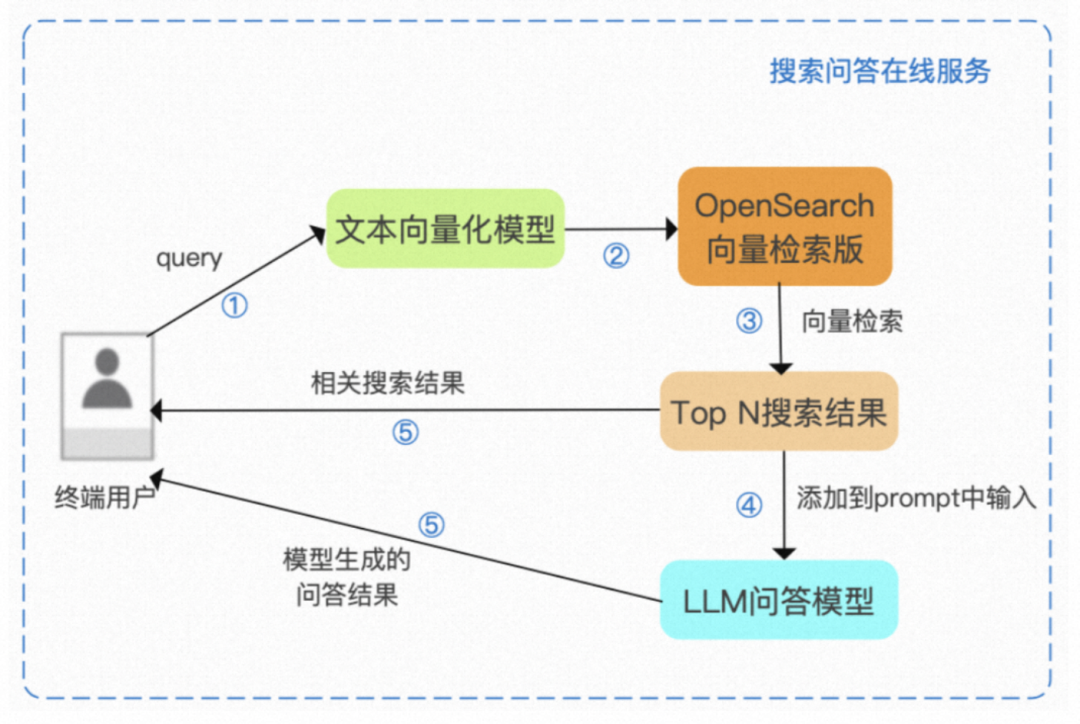
The functionality of large model agents, where the model analyzes the problem, selects the appropriate tools, and ultimately solves the problem.
The role of the ReAct method is to coordinate the LLM model with external information acquisition and interact with other functions. If the LLM model is the brain, then the ReAct framework is the hands, feet, and senses of this brain.
| Key Concepts | Description |
| Thought | Generated by the LLM model, it is the basis for the LLM’s actions. |
| Act | Act refers to the specific behavior the LLM determines it needs to perform. |
| Obs | The LLM framework’s acquisition of external input. |
Answer the following questions as best as possible, using tools: {tool name and description} Use the following format to answer: Question: The question you must answer
Thought: You should keep thinking consistently about how to solve the problem.
Action: {tool name}. Choose only one tool for each action, tool list: {tool name and description}
Input: {parameters to pass when calling the tool}
Observation: {results returned by the third-party tool}
【Thought-Action-Input-Observation】 Loop N times
Thought: Finally, output the final result
Final Result: Output the final result for the original questionStart! Question: What is the tallest building in Shanghai? What is the square of its height?
Thought: I need to know the tallest building in Shanghai and then perform calculations.
Action: Search API
Observation: 632 meters
Thought: I need to calculate the square of the height of Shanghai's tallest building and then get the result.
Action: Calculator
Input: 632^2
Observation: 399424
Thought: Final Result: The tallest building in Shanghai is 632 meters tall, and its height squared is 399424
Supervised Fine-tuning (SFT) of Large Models
▐ Pre-training vs Fine-tuning
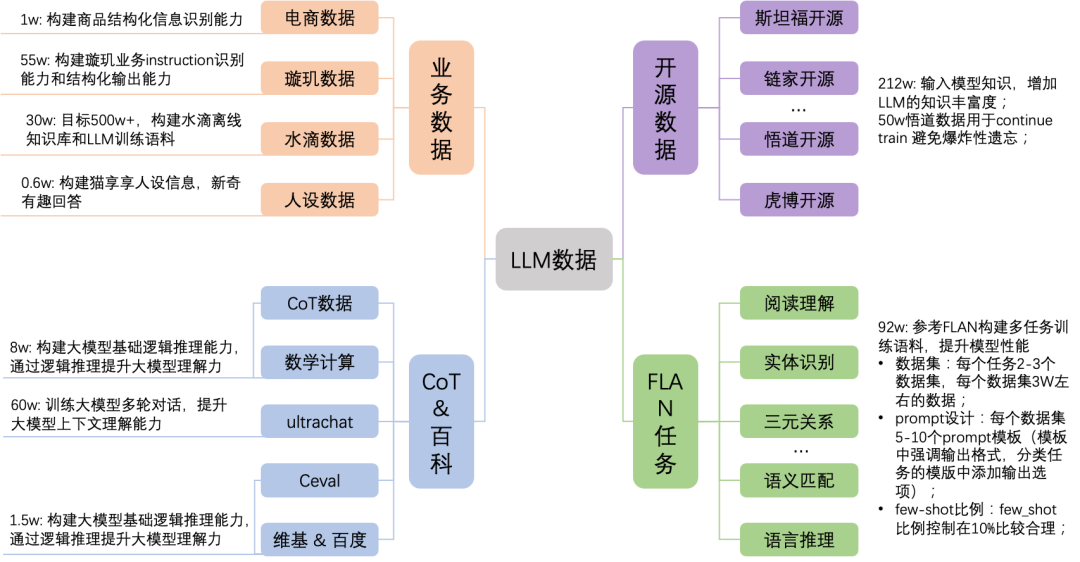
Where does the business data come from?
-
Manual annotation
-
Seed data + self-instruct (constructed with GPT-3.5)
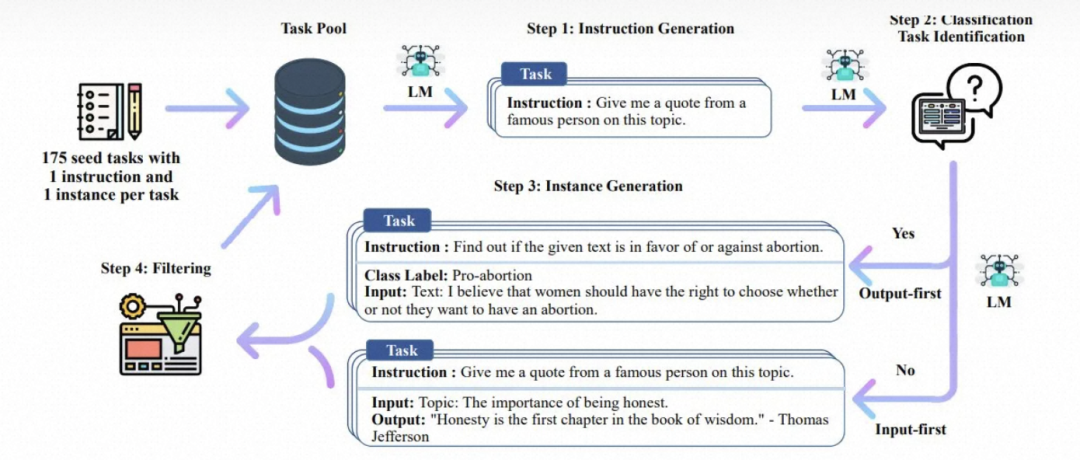
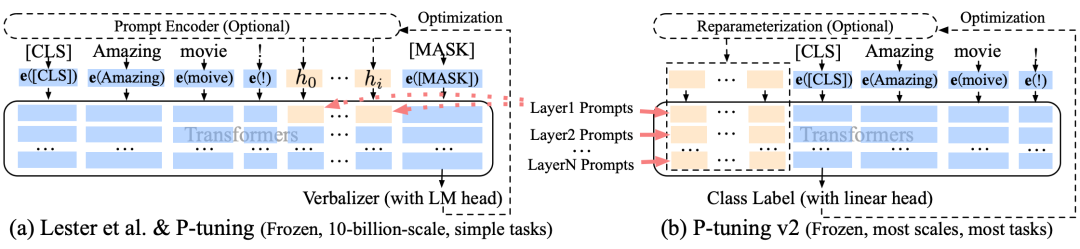
P-tuning: Converts prompts into learnable embedding layers and uses MLP + LSTM to process prompt embeddings.
P-tuning V2: Adds trainable prompts at every layer, only training the parameters of the prompt part while keeping the language model’s parameters unchanged.
▐ LoRA
Low-rank Adaptation of LLM allows for adapting large models to downstream tasks while only training a small number of parameters to achieve good results. It is a compensatory solution when computational resources are limited.

▐ LoRA vs Full Parameter Fine-tuning
The advantage of LoRA is its lightweight and low resource consumption. However, its downside is that the number of parameters involved in training is limited, ranging from millions to tens of millions, which in experiments shows slightly worse performance compared to full fine-tuning.
▐ C-Eval Evaluation
C-Eval, completed by Shanghai Jiao Tong University, Tsinghua University, and the University of Edinburgh, constructs a Chinese knowledge and reasoning test set covering four major directions: humanities, social sciences, engineering, and other disciplines, with 52 subjects (calculus, linear algebra, etc.), from middle school to graduate school and professional exams, totaling 13,948 questions.
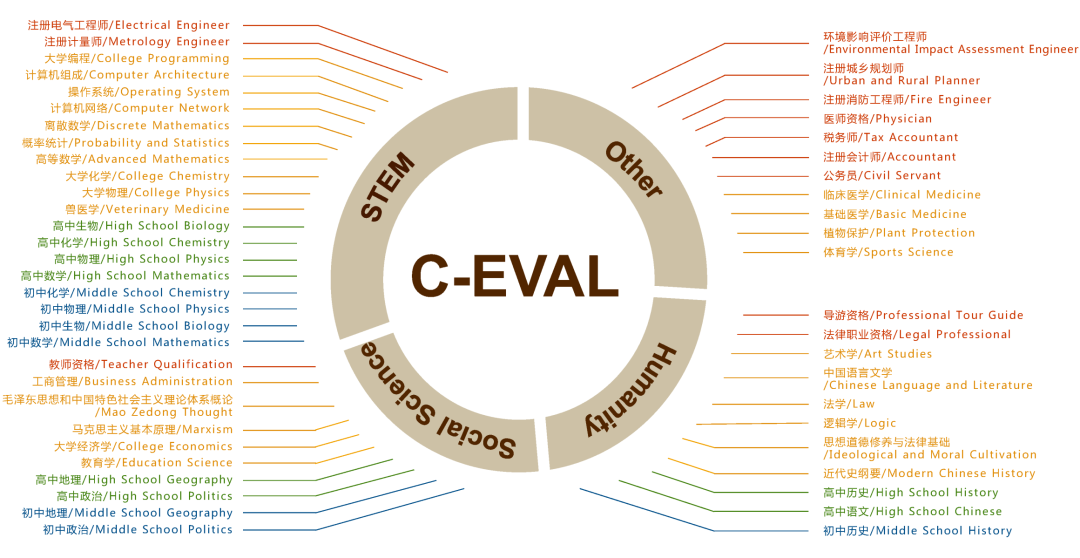
C-Eval believes: For a model to be strong, it must first have extensive knowledge, and then reason based on that knowledge, which represents a model’s ability to perform complex and difficult tasks.


▐ Project Background
“AI image” Xuanji serves as a personal shopping assistant, conducting user understanding and product guidance in interactive dialogues.
▐ Algorithm Framework
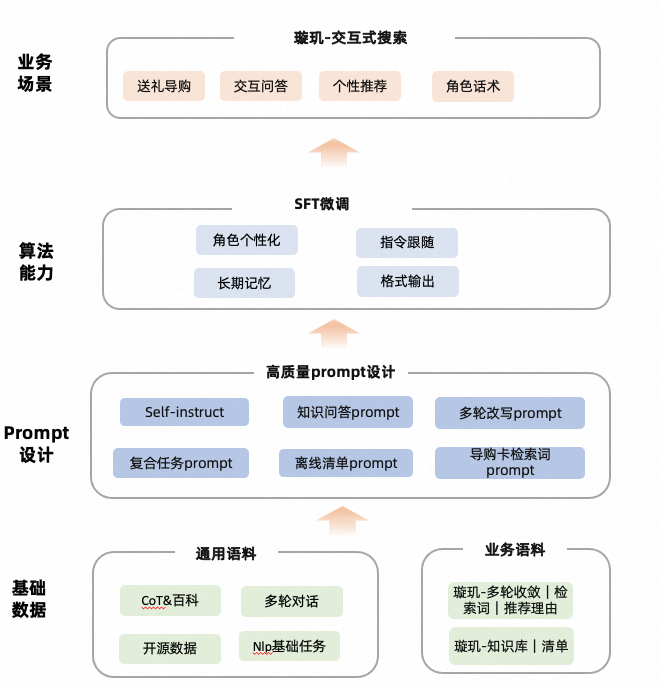
▐ Corpus Collection
-
Collect e-commerce seed questions: internal conversation logs, collect mobile Tmall sug seed questions:
-
Question generalization: Clearly define scenario problem definitions, design prompts through core queries of Tmall, seed questions, etc., and supplement question collection through GPT;
-
Manual annotation: Annotate high-quality corpus;
-
Self-instruction: Expand new instructions based on existing manual annotations through the prompt (few-shot) method. Use GPT to obtain more training corpus to solve the bottleneck of annotator efficiency.
▐ Model Training
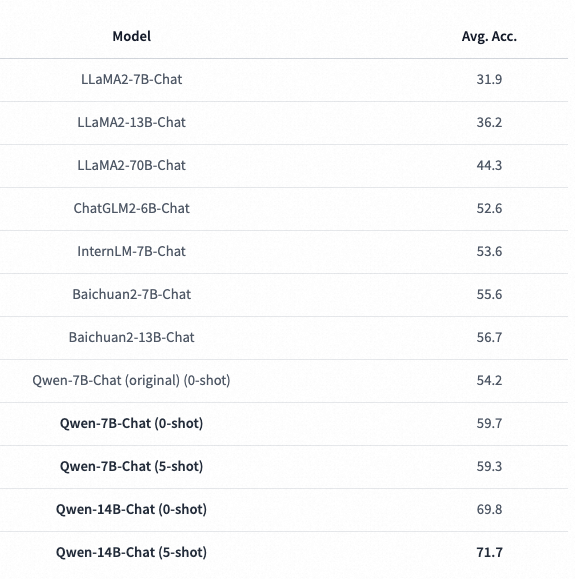
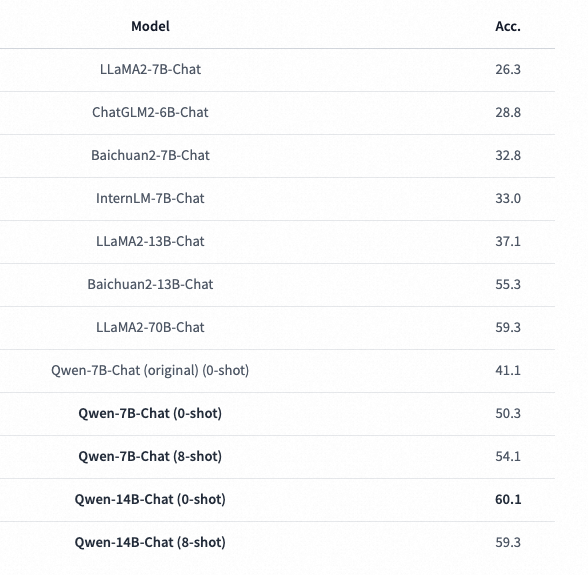
Training platform: AOP/Xingyun/PAI
Based on the Qwen-14B model base from DAMO Academy, additional training data in the e-commerce field is added for the Xuanji product to enhance the model’s knowledge in e-commerce, safety, and shopping guidance.
params="--stage sft \--model_name_or_path /data/oss_bucket_0/Qwen_14B_Chat_ms_v100/ \--do_train \--dataset_dir data \--dataset xuanji \--template chatml \--finetuning_type full \--output_dir file_path \--overwrite_cache \--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 5 \--save_strategy epoch \--save_steps 10000 \--learning_rate 2e-6 \--num_train_epochs 3.0 \--warmup_ratio 0.15 \--warmup_steps 0 \--weight_decay 0.1 \--fp16 ${fp16} \--bf16 ${bf16} \--deepspeed ds_config.json \--max_source_length 4096 \--max_target_length 4096 \--use_fast_tokenizer False \--is_shuffle True \--val_size 0.0 "pai -name pytorch112z-project algo_platform_dev-Dscript='${job_path}' -DentryFile='-m torch.distributed.launch --nnodes=${workerCount} --nproc_per_node=${node} ${entry_file}'-DuserDefinedParameters="${params}"-DworkerCount=${workerCount}-Dcluster=${resource_param_config}-Dbuckets=${oss_info}${end_point}Training intermediate process
▐ Model Deployment & Invocation
-
DAMO Academy Qianwen
# For prerequisites running the following sample
import dashscopefrom dashscope import Generationfrom http import HTTPStatus
dashscope.api_key = 'your-dashscope-api-key'
response_generator = Generation.call( model='model_name', prompt=build_prompt([ {'role':'system','content':'content_info'}, {'role':'user', 'content':'query'} ]), stream=True, use_raw_prompt=True, seed=random_num)
for resp in response_generator: # when stream, you need to get the result through iteration if resp.status_code == HTTPStatus.OK: print(resp.output) else: print('Failed request_id: %s, status_code: %s, \
code: %s, message:%s' % (resp.request_id, resp.status_code, resp.code, resp.message))
# Result: # {"text": "汝亦来", "finish_reason": "null"}# {"text": "汝亦来哉,幸会。\n\n汝可", "finish_reason": "null"}# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生", "finish_reason": "null"}# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生」,不知可否?", "finish_reason": "null"}# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生」,不知可否?", "finish_reason": "stop"}-
Whale Private
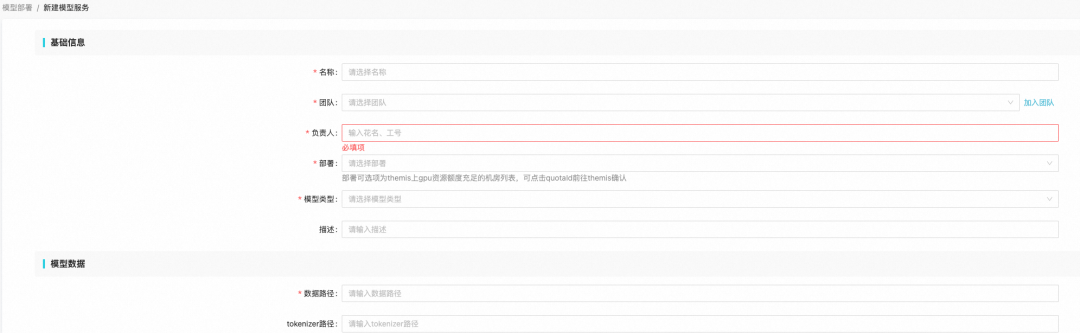
Model management:
from whale import TextGenerationimport json
# Set apiKey# Do not specify base_url for pre-release or production
TextGeneration.set_api_key("api_key", base_url="api_url")
# Set parameters during model generation
config = {"pad_token_id": 0, "bos_token_id": 1, "eos_token_id": 2, "user_token_id": 0, "assistant_token_id": 0, "max_new_tokens": 2048, "temperature": 0.95, "top_k": 5, "top_p": 0.7, "repetition_penalty": 1.1, "do_sample": False, "transformers_version": "4.29.2"}prompt = [ { "role": "user", "content": "content_info" }]
# Request modelresponse = TextGeneration.call( model="model_name", prompt=json.dumps(prompt), timeout=120, streaming=True, generate_config=config)
# Process streaming resultsfor event in response: if event.status_code == 200: print(event.finished) if event.finished is False: print(event.output['response'], end="") else: print('error_code: [%d], error_message: [%s]' % (event.status_code, event.status_message))-
EAS
With EAS, separate code and model files for LLM service deployment, providing streaming output based on HTTP protocol. The model is stored on OSS.
▐ Model Evaluation
Basic capability evaluation: Assess the model’s performance in Chinese and English, reasoning, and knowledge Q&A abilities on public evaluation sets.
Business evaluation: Primarily based on manual evaluation of business tasks, with 150 evaluation questions for each large model task.
Experience issues: Acquire logs through buried points and conduct regular reviews.

1.https://www.semanticscholar.org/paper/Attention-is-All-you-Need-Vaswani-Shazeer/204e3073870fae3d05bcbc2f6a8e263d9b72e776
2.https://huggingface.co/Qwen/Qwen-14B-Chat
3.https://github.com/yuanzhoulvpi2017/zero_nlp
4.https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
5.https://www.bilibili.com/video/BV1jP411d7or/?spm_id_from=333.337.search-card.all.click
6.https://arxiv.org/pdf/2305.08322v1.pdf
7.https://zhuanlan.zhihu.com/p/630111535?utm_id=0
8.https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
9.https://github.com/tatsu-lab/stanford_alpaca

Team Introduction