MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP graduate students, university teachers, and corporate researchers.The vision of the community is to promote communication between the academic and industrial circles of natural language processing and machine learning, as well as enthusiasts, especially the progress of beginners.
Source | Xixiaoyao’s Cute Selling House
Author | Xiao Yi
Today, I will introduce a recent work by Google that addresses the long text processing problem of the Transformer. In the native Transformer, the complexity of attention is quadratic in relation to the input sequence length, which limits its ability to handle long texts. In simple terms, the solution proposed in this paper is to use the Transformer as a recurrent unit in an RNN.
The difference from traditional RNNs is: in a traditional RNN encoder, each recurrent unit is responsible for encoding a token, while in this paper, each recurrent unit encodes a text segment of length w, and each unit is implemented using the same Transformer Block. In this way, each segment can encode information from previous texts in a manner similar to RNNs.The idea is simple, but there are some challenges in the specific implementation. Next, we will introduce the Block-Recurrent Transformer proposed in this paper.Paper Title: BLOCK-RECURRENT TRANSFORMERSPaper Link: https://arxiv.org/pdf/2203.07852.pdf
1
『Sliding Attention Mechanism』
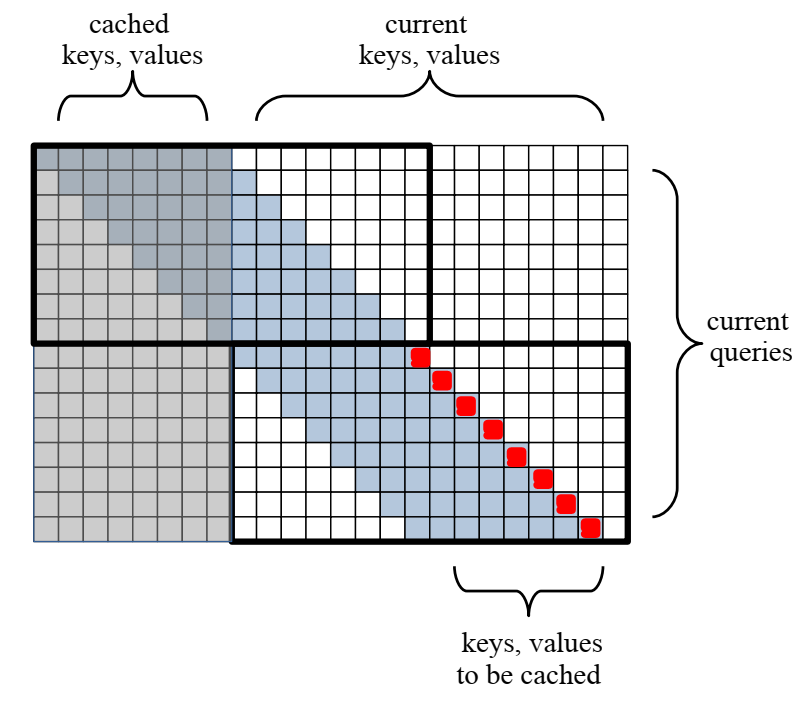
First, let’s look at the attention range of each block. This paper employs a sliding window attention mechanism, a technique specifically designed for long document scenarios. Due to the excessive length of the text, it is difficult for each token to attend to all tokens in the entire text. In the sliding window attention mechanism: each token only needs to attend to its previous w tokens. In this paper, the sliding window length w is equal to the text length W that each recurrent unit needs to process, i.e., W=w.In the example above, assuming the window length is 8; correspondingly, the input text is also divided into segments of length 8, which are processed by the Transformer blocks. The light blue area in the figure indicates the attention range.The two black boxes in the figure correspond to two Transformer blocks. The 8 red markers represent the 8 tokens that the block in the lower right corner needs to process. It can be seen that the attention matrix size for each block is 2WxW. Therefore, for an input of length N, the attention complexity of the entire model is O(N).
2
『Recurrent Unit』
Next, let’s take a look inside each Transformer block to see how the recurrence is implemented.▲Traditional RNN StructureSimilar to traditional RNNs, each recurrent unit:
Input is input embeddings and current state
Output is output embeddings and next state
Therefore, the two core questions we need to understand here are: how are these two outputs obtained in the Block-Recurrent Transformer?
Vertical Direction: How to Obtain Output Embeddings?
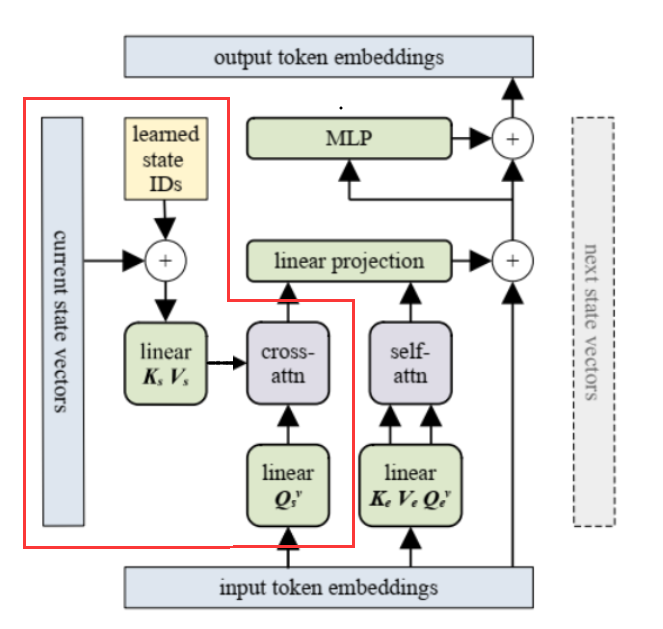
The following figure shows the process of obtaining output embeddings.▲Vertical Direction: How to Obtain Output EmbeddingsSimilar to a traditional Transformer layer, the difference is concentrated in the part marked by the red box. In this part, to integrate the current state information provided by the previous recurrent unit, a cross attention is performed between input embeddings and current state vectors. On the other hand, input embeddings will also go through a self-attention layer. These two parts are concatenated and fused together through a linear layer.
Horizontal Direction: How to Obtain Next State?
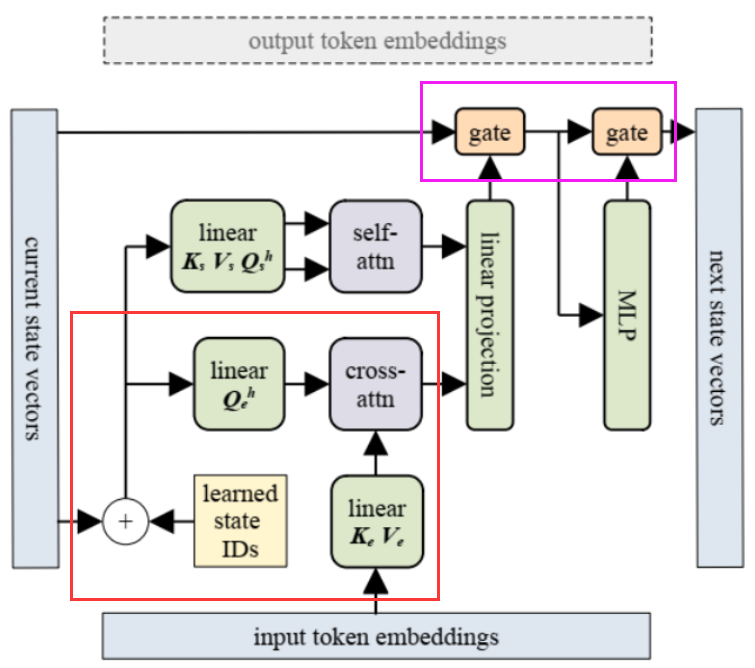
The following figure shows the process of obtaining the next state.▲Horizontal Direction: How State is Passed Between Recurrent UnitsUnlike traditional Transformers, the differences are marked by the red and pink boxes. The red part, similarly, uses cross attention to integrate input embeddings and current state vectors. The pink part replaces the residual layer originally in the Transformer with two gates. These two gates function similarly to the forget gate in LSTMs, controlling the retention of information from the previous state.
How to Stack Vertically in Multiple Layers?
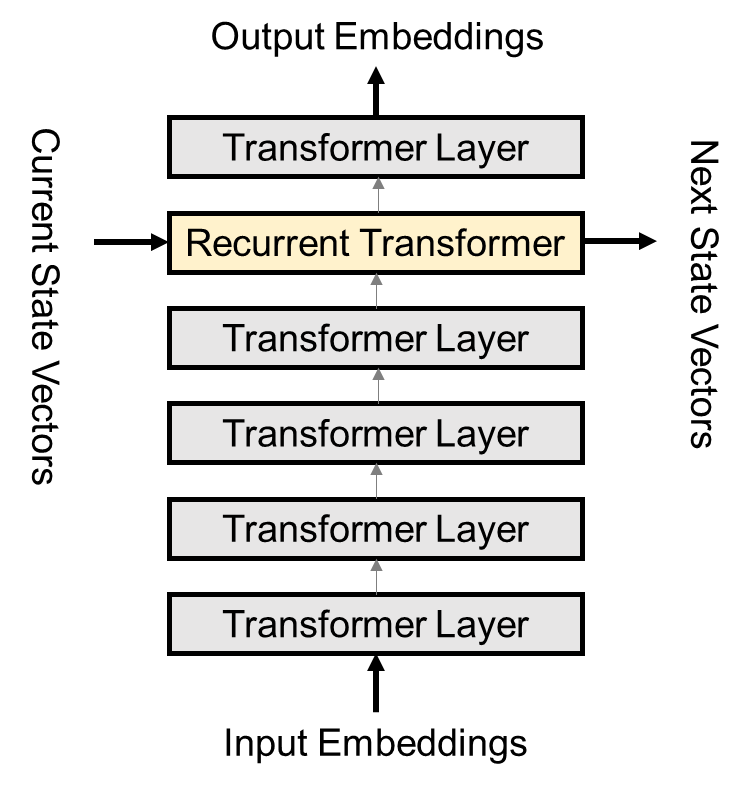
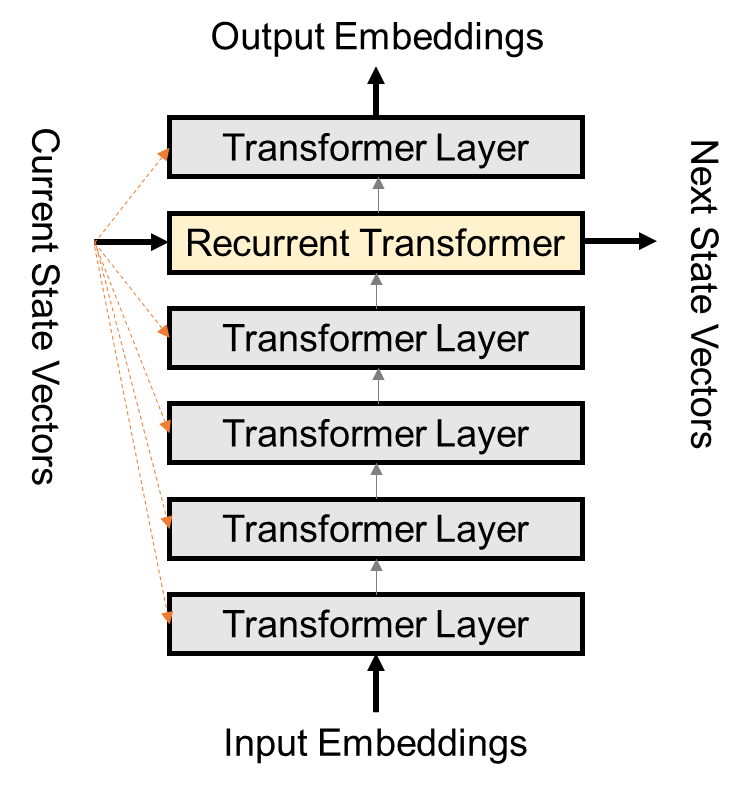
Finally, there is one more question. We all know that traditional Transformer Encoders are usually stacked with multiple Transformer Layers. That is the significance of Nx in the figure below. So, how is vertical stacking achieved in the Block-Recurrent Transformer?▲Traditional Transformer EncoderThe paper discusses two methods: Single Recurrent Layer and Feedback.▲Single Recurrent LayerThe implementation of Single Recurrent Layer (SRL) is relatively simple. I made a simple diagram as shown above. The multiple layers stacked vertically are mostly ordinary Transformer Layers; only one layer receives the current state in the horizontal direction and performs a recurrent operation. This method has a relatively low computational complexity, equivalent to adding one more layer of computation on top of a regular Transformer. That is to say, if 12 layers are stacked vertically, it is equivalent to the computational load of stacking 13 layers of a regular Transformer.▲FeedbackFeedback builds on SRL, where the current state is also broadcast to other Transformer Layers. These layers will fuse the information of the current state using cross attention. In experiments, Feedback showed a slight performance improvement over SRL, but it has more model parameters and the training time increased significantly by 35-40%.
3
『Experiments』
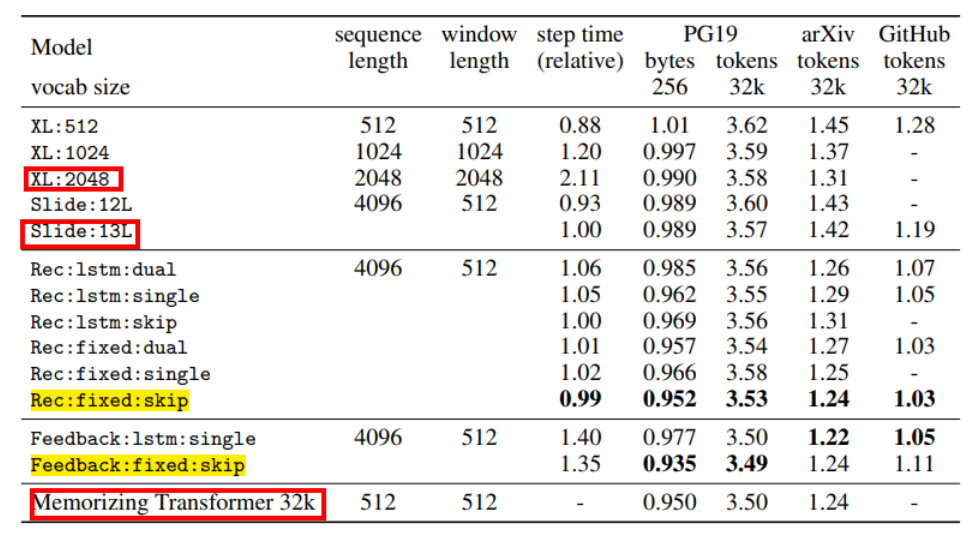
Experiments were conducted on three long text datasets: PG19, arxiv, and Github. The evaluation task was autoregressive language modeling, with perplexity as the metric. The results are shown in the figure below.The yellow highlights indicate the two variants of the method proposed in this paper, which achieved SOTA results.The red boxes outline three important baselines. Among them, the first two baselines are two variants of the classic long document processing model Transformer-XL. It can be seen that the performance of the method in this paper is significantly better than theirs.The last line, the Memorizing Transformer, is also a Google work that was recently accepted by ICLR’2022. Its basic idea is: when encoding long texts, the model reads down while storing all previously seen tokens in a database; when reading the current segment, it finds similar content in the database using kNN and interacts with the current content during encoding.It can be seen that the performance of this model is actually not much different from that of the method in this paper, but the complexity is much higher, and the computation delay is also longer. Although… however, the step time of the Memorizing Transformer is not explicitly stated in the table. I personally feel this is somewhat inappropriate.
4
『Conclusion』
、The idea in this paper is actually quite simple: to use the Transformer as a recurrent unit in RNNs to solve the long text problem. I believe that many people must have thought of similar ideas. I have indeed seen similar previous works, but their model complexity and performance are inferior to those in this paper.For this paper, just having an idea is definitely not enough; many issues must be resolved, including:
How to pass information between adjacent blocks in a way that fits the Transformer
The model design must also consider minimizing computational complexity, ensuring that operations can be parallelized rather than serialized
Lastly, there are some engineering implementation issues. For example, will the model training encounter gradient vanishing problems like traditional RNNs? If so, how to solve it? This aspect was not covered in this article. The original text indeed proposed some methods to improve the stability of model training.
From a macro idea to actual implementation, there is still a long distance. So we cannot easily say that the idea of a paper is “too simple”.References[1] Memorizing Transformers https://arxiv.org/abs/2203.08913Technical Exchange Group Invitation
△Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply to join Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community (Machine Learning Algorithms and Natural Language Processing) is a civil academic community jointly built by scholars in natural language processing from home and abroad. It has developed into a well-known natural language processing community, including 10,000-person top conference exchange group, AI selection, AI talent exchange and AI academic exchange and other well-known brands, aimed at promoting progress between the academic and industrial circles of machine learning and natural language processing and enthusiasts.The community can provide an open communication platform for the further education, employment, and research of relevant practitioners. We welcome everyone to follow and join us.