

ALBERT Recommendation:
Although the BERT model itself is very effective, this effectiveness relies on a large number of model parameters, so the time and resource costs required to train a BERT model are very high, and such a complex model can even affect the final results. In this article, we focus on introducing a slimmed-down version of the heavyweight BERT model – ALBERT, which achieves a much smaller model through several optimization strategies, but surpasses the BERT model on datasets like GLUE and RACE.
ALBERT Paper:
Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[J]. arXiv preprint arXiv:1909.11942, 2019.
Table of Contents:
Training of Large-Scale Pre-trained Models Review of the BERT Model Several Optimization Strategies Used in ALBERT Summary of ALBERT Future (Current) Works Prospects for the NLP Field
1. Training of Large-Scale Pre-trained Models
We are witnessing a big shift in the approach in natural language understanding in the last two years.
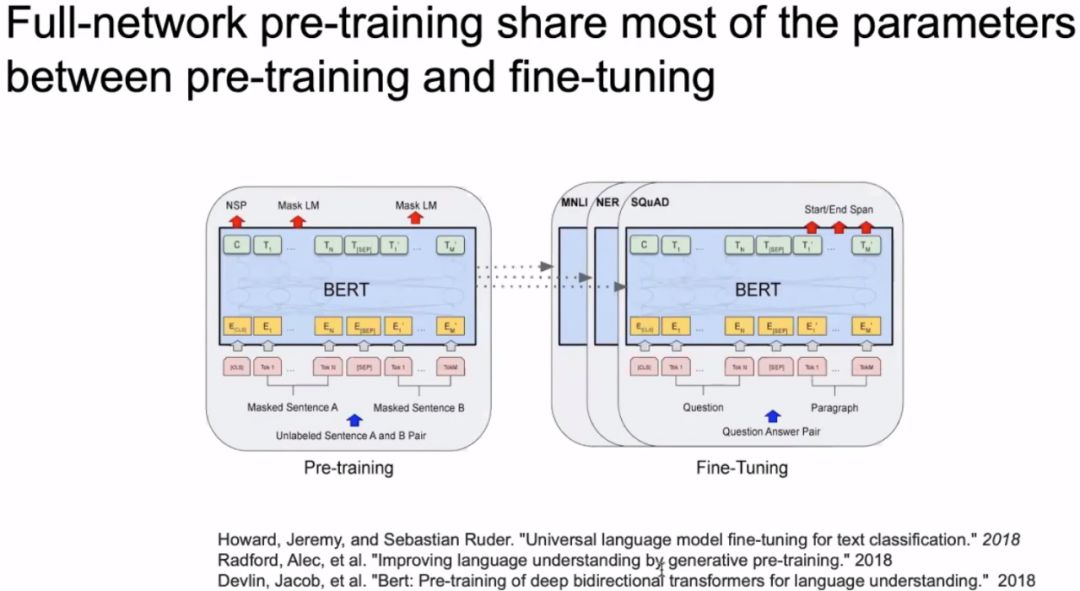
In the past two years, we have made great progress in natural language processing, with breakthroughs mainly coming from “full-network pre-training algorithms”, which include the three papers shown in the image (GPT, BERT, etc.). The idea behind full-network pre-training is that the pre-training and downstream tasks essentially share most of the parameters. Unlike previous methods such as Skip-gram and Continuous Bag of Words (CBOW), which only train the word embedding part (a smaller set of parameters), downstream tasks require adding many parameters on top of this, which necessitates a lot of training data.
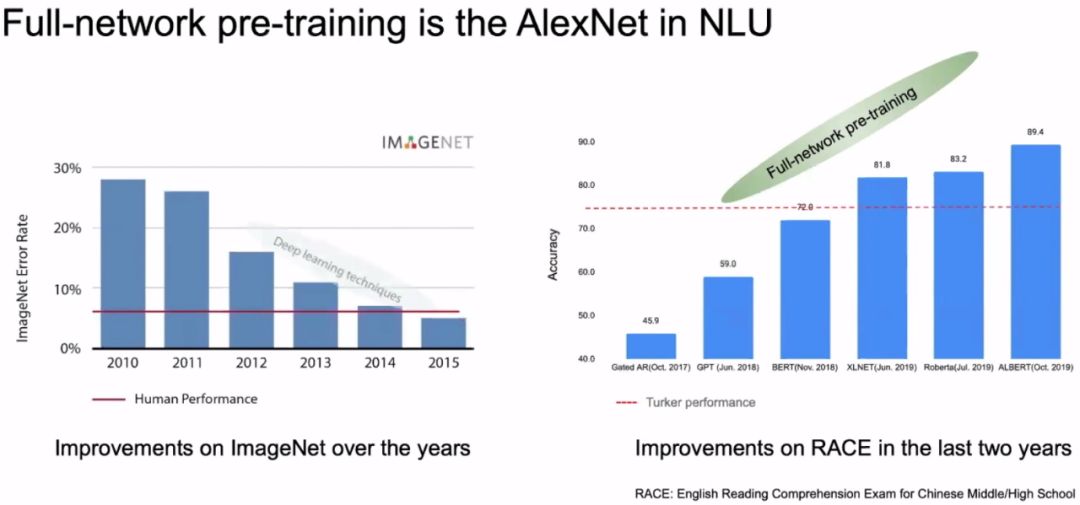
How powerful are full-network pre-trained models? Here we compare with AlexNet, which is essentially the spark that ignited artificial intelligence. The left side of the image below shows the error graph for ImageNet; in 2012, there was a sharp decline in error due to AlexNet. After that, every year, there has been a significant drop in error due to the benefits brought by deep learning. On the right side of the image, when the RACE dataset was released in 2017, the method used was local pre-training (similar to Skip-gram, CBOW), achieving an accuracy of 45.9%. In June 2018, GPT improved the accuracy to 59%, essentially achieving full-network training. Then in November of the same year, BERT raised the accuracy to 72%. Following that, XLNET achieved an accuracy of 81.8%, Roberta reached 83.2%, and ALBERT achieved an accuracy of 98.4%. Thanks to full-network pre-training, we doubled the accuracy from the original 45.9% to now 89.4%.
2. Review of the BERT Model
Can we improve Full-network pre-training models, similar to what computer vision community did for AlexNet?
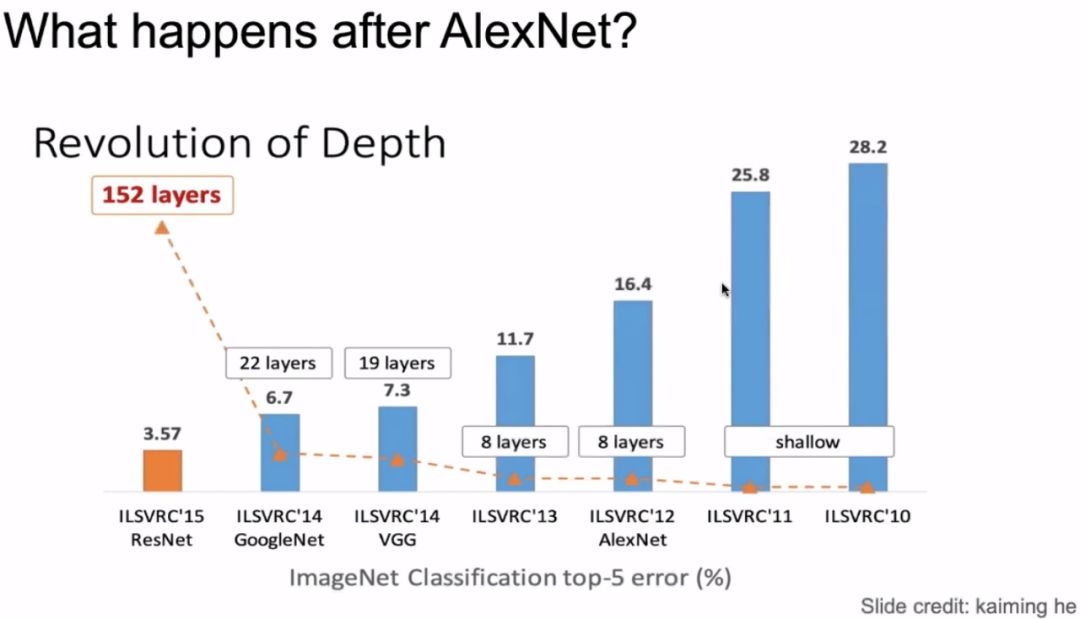
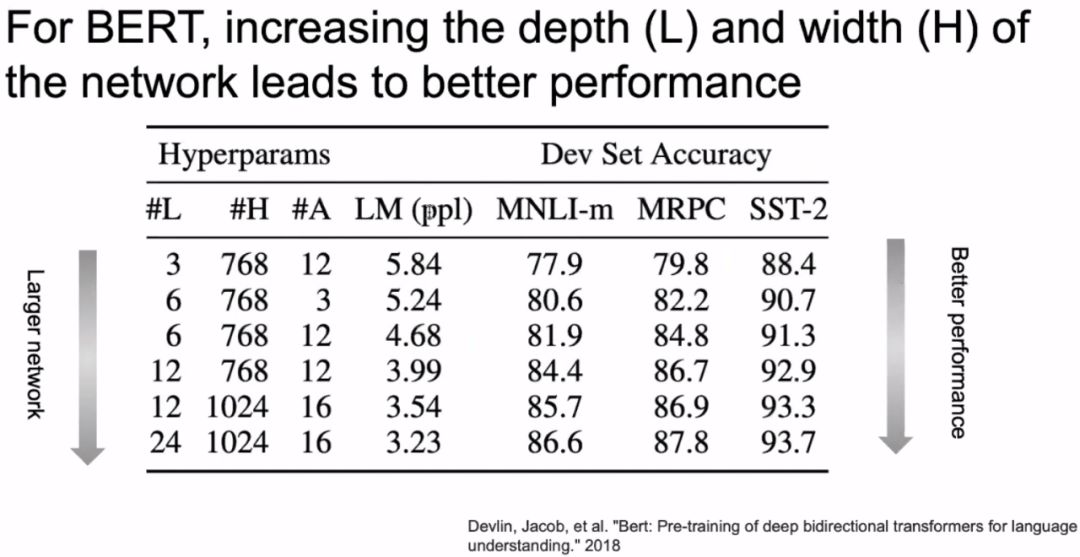
As shown in the image above, after AlexNet, most of the accuracy improvements were due to the increase in network depth. The following image, taken from the BERT paper, shows that BERT also conducted experiments on widening and deepening the network, finding that both widening and deepening the network can improve accuracy.
Thought Question: Is having a better NLU model as easy as increasing the model size?
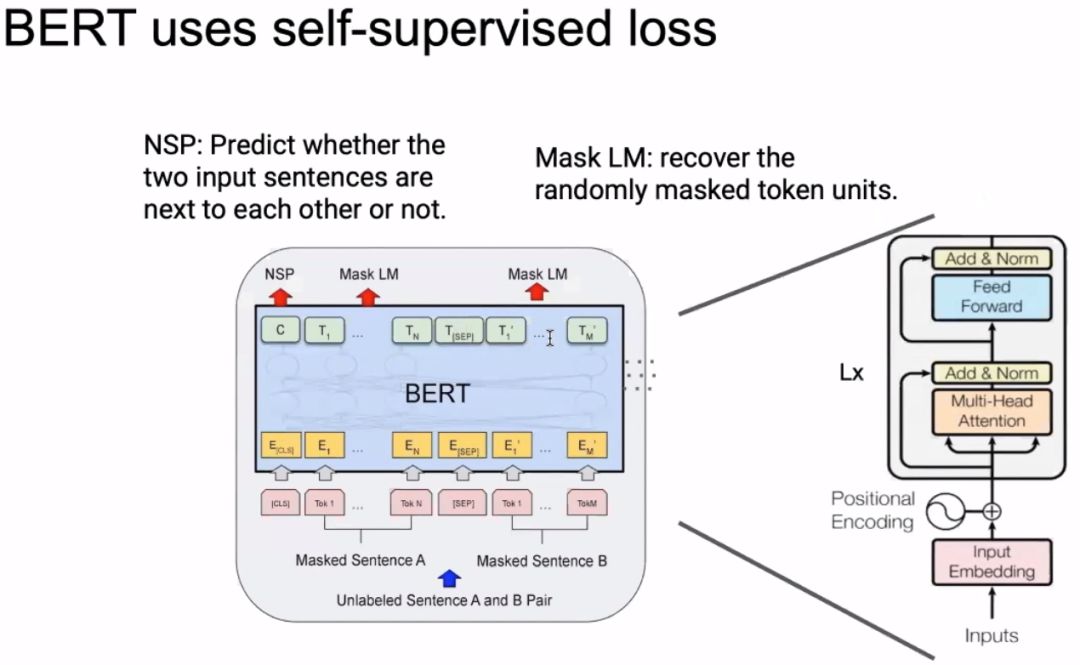
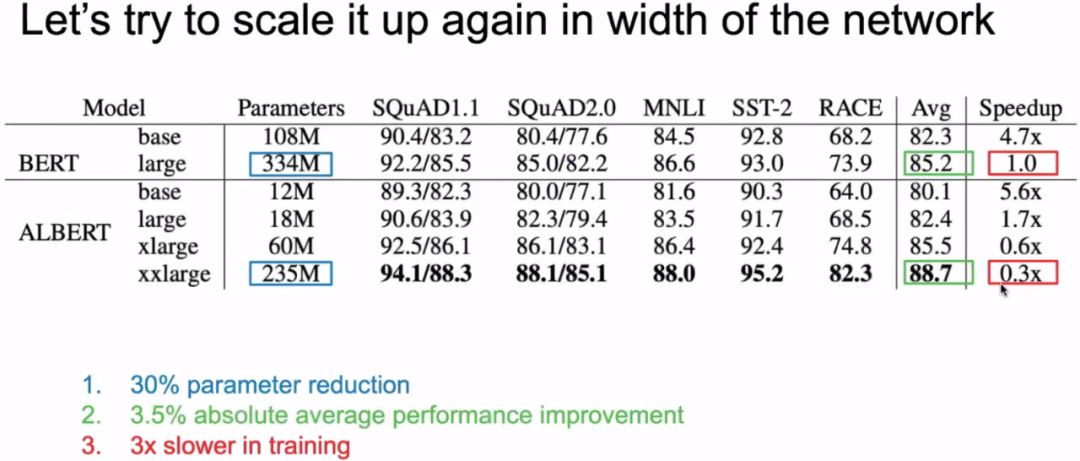
The image above gives a simple review of the BERT model. The image below shows that when we only doubled the width of BERT, the number of parameters has already reached 1.27 billion, causing memory overflow.
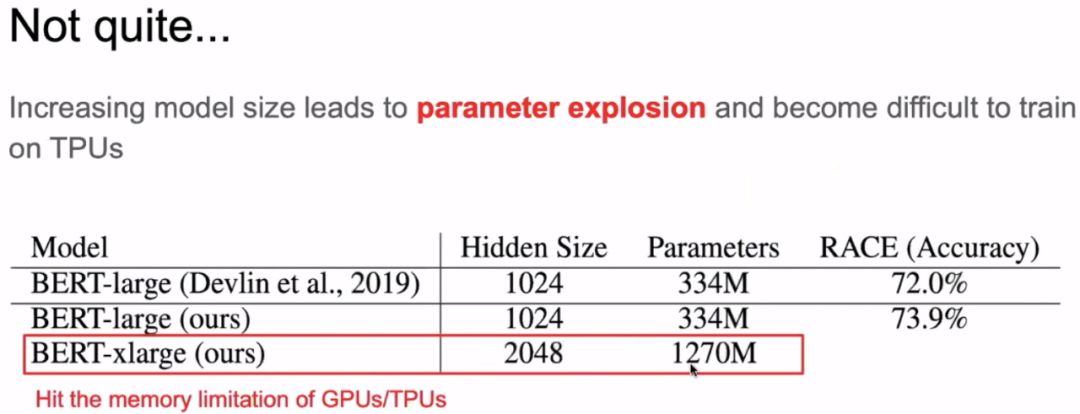
Thought Question: Can we have more efficient ways of using parameters? Can we reduce the number of parameters significantly without reducing or slightly reducing model accuracy? This is the theme of ALBERT.
3. Several Optimization Strategies Used in ALBERT
3.1 Where are the Parameters Mainly in BERT and Transformer

In the image above, the Attention feed-forward block accounts for about 80% of the total parameters, while the Token embedding projection block accounts for about 20% of the parameters.
3.2 Method 1: Factorized Embedding Parametrization

The image below shows BERT’s One-hot vector input; the first projection has no interaction between words. Only during Attention do words interact. Therefore, the first projection does not require a high-dimensional vector.
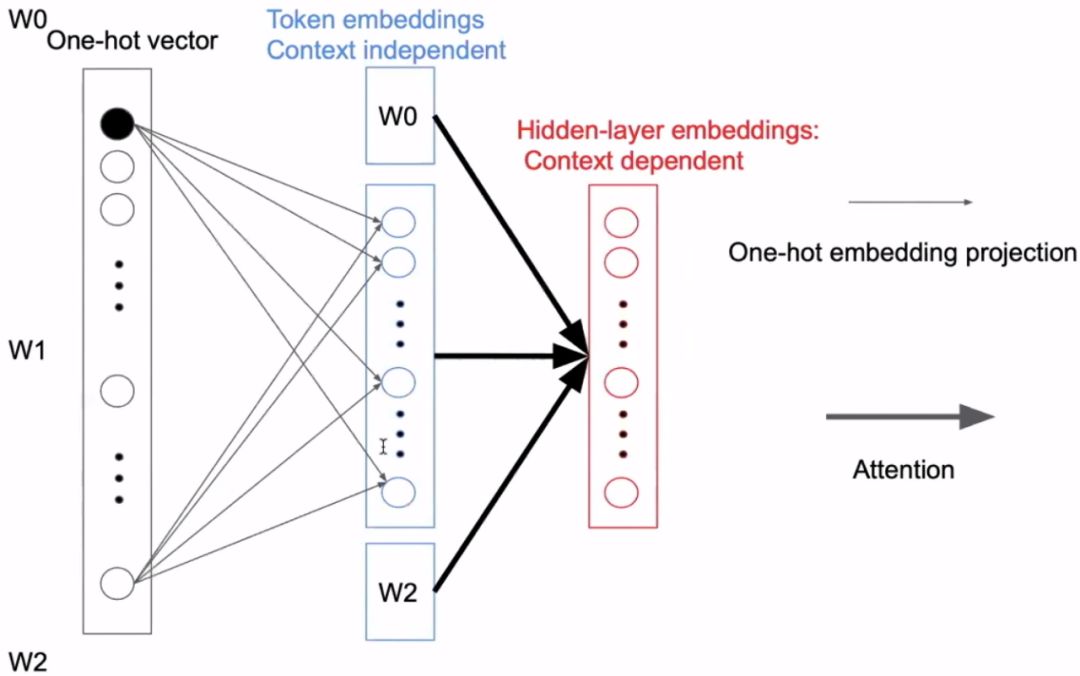
The image below shows ALBERT’s improvement, where the first mapping is placed in a very low dimension, and then mapped to the required dimension. This approach has two benefits:
-
The independent representation of words and the context-dependent representation can be unlocked, allowing for a wider network. -
The parameters from the one-hot vector to the first mapping are numerous; this part of the parameters can be made very small.

Matrix factorization is essentially a low-rank decomposition operation, which reduces parameters by dimensionality reduction on the embedding part. In the original BERT, for example, in the Base version, the dimensions of the embedding layer and the hidden layer are both 768. However, for distributed representations of words, such high dimensions are often unnecessary; for instance, in the Word2Vec era, dimensions of 50 or 300 were often used. A simple idea is to reduce the parameter count by decomposing the embedding part, represented by the formula:
: vocabulary size; : hidden layer dimension; : word vector dimension
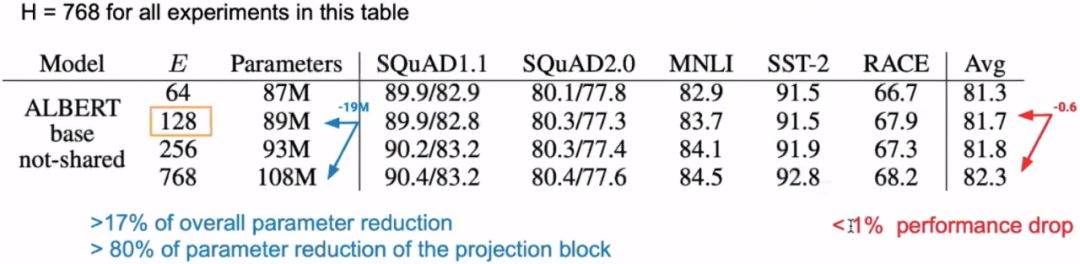
Taking BERT-Base as an example, with a hidden size of 768 and a vocabulary size of 30,000, the parameter count is: 768 * 30,000 = 23,040,000. If we change the dimension of the embedding to 128, then the parameter count for the embedding layer becomes: 128 * 30,000 + 128 * 768 = 3,938,304. The difference between the two is 19,101,696, about 19M. We see that the embedding parameter count decreased from the original 23M to now 4M, which seems like a significant change. However, when viewed globally, the parameter count of BERT-Base is 110M, so reducing by 19M does not produce a revolutionary change. Therefore, it can be said that factorization of the embedding layer is not the primary means of reducing parameter count.
3.3 Method 2: Cross-layer Parameter Sharing
Inspired by the paper “Gong L, He D, Li Z, et al. Efficient training of BERT by progressively stacking[C]//International Conference on Machine Learning. 2019: 2337-2346”, each layer of the Transformer focuses on similar areas, so weight sharing can be implemented across layers.
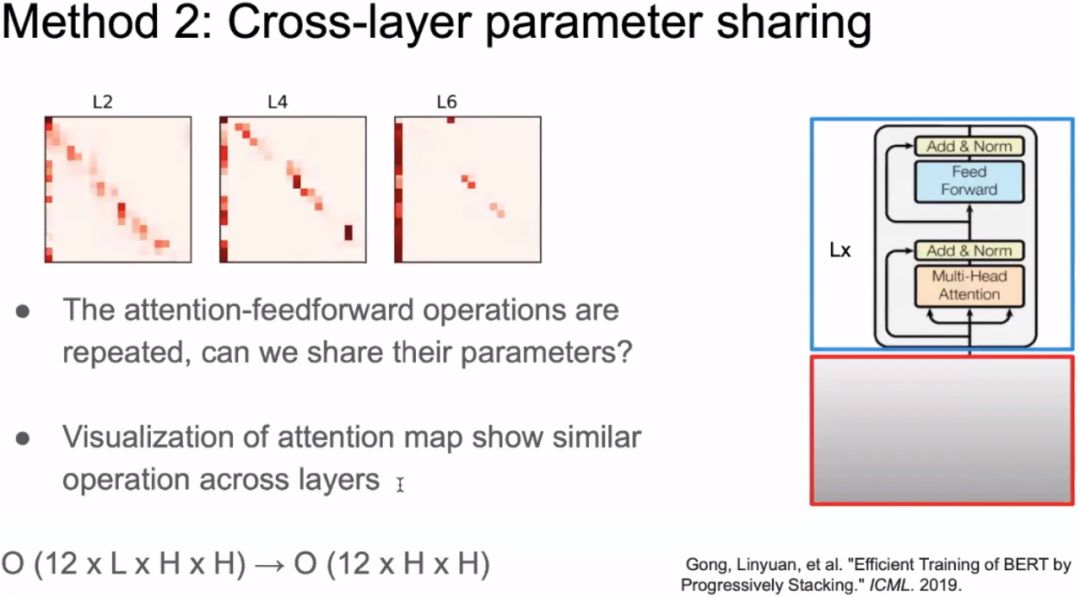
Another method proposed by ALBERT to reduce parameter count is parameter sharing between layers, meaning multiple layers use the same parameters. There are three ways to share parameters: only share the feed-forward network parameters, only share the attention parameters, or share all parameters. ALBERT defaults to sharing all parameters. It can be understood that the weights shared do not mean that the values of the 12-layer transformer encoder are the same; they just occupy the same variable. Therefore, the computational load of the model does not decrease; the number of parameters simply becomes one-twelfth of the original.
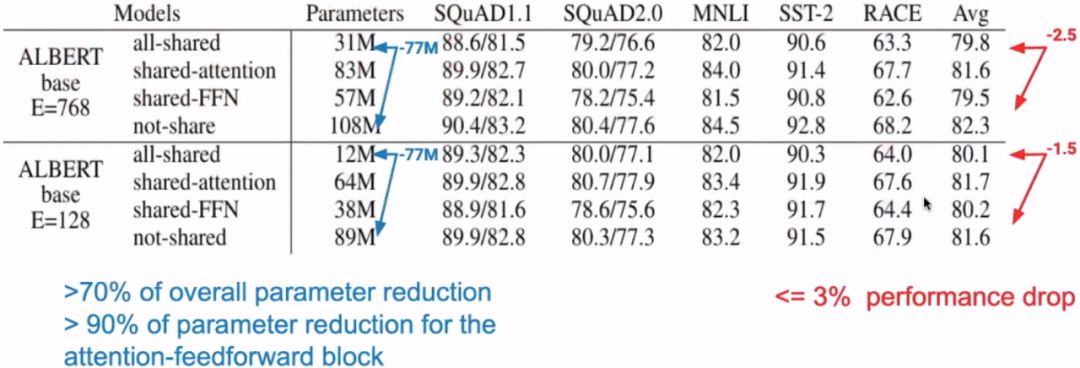
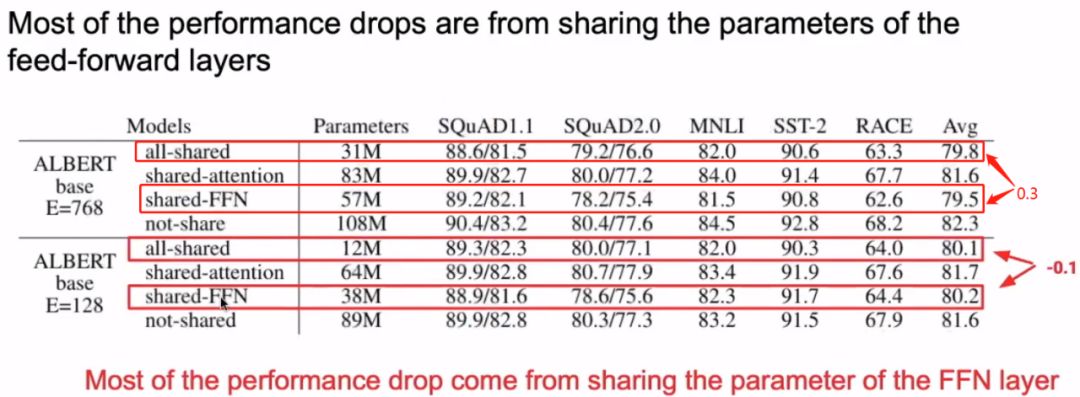
3.4 Widening the Model
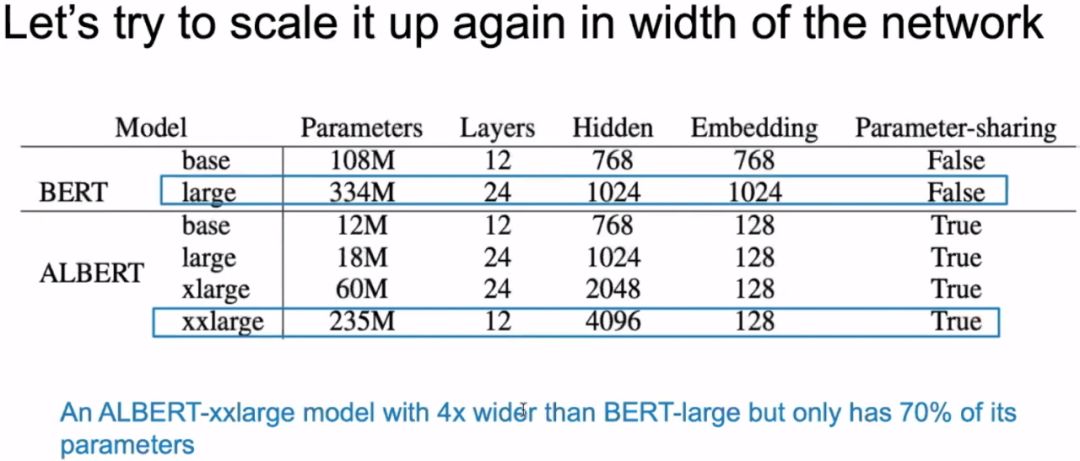
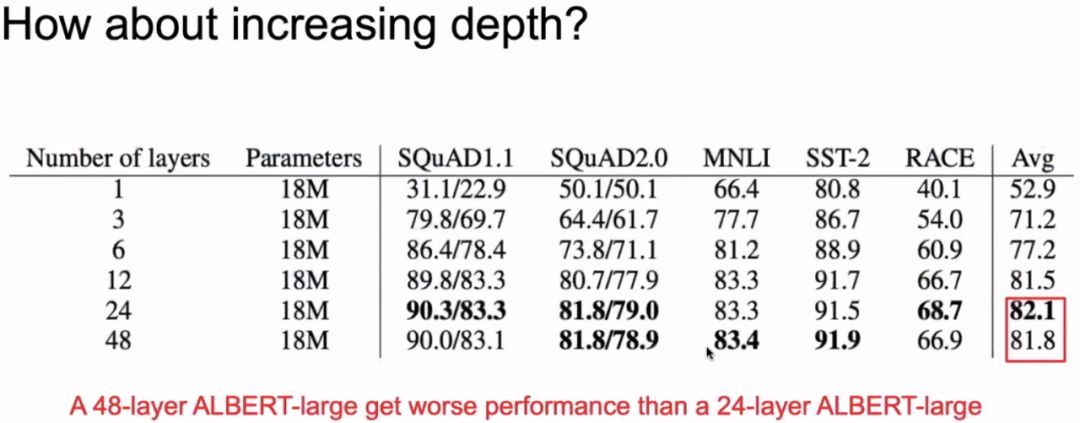
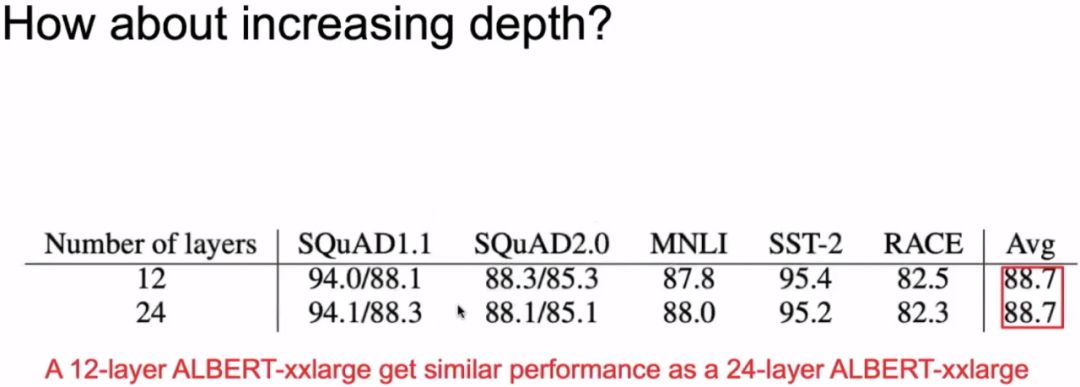
3.5 Deepening the Model
3.6 Pre-training Strategy: SOP Replacing NSP
Innovation: Design better self-supervised learning tasks
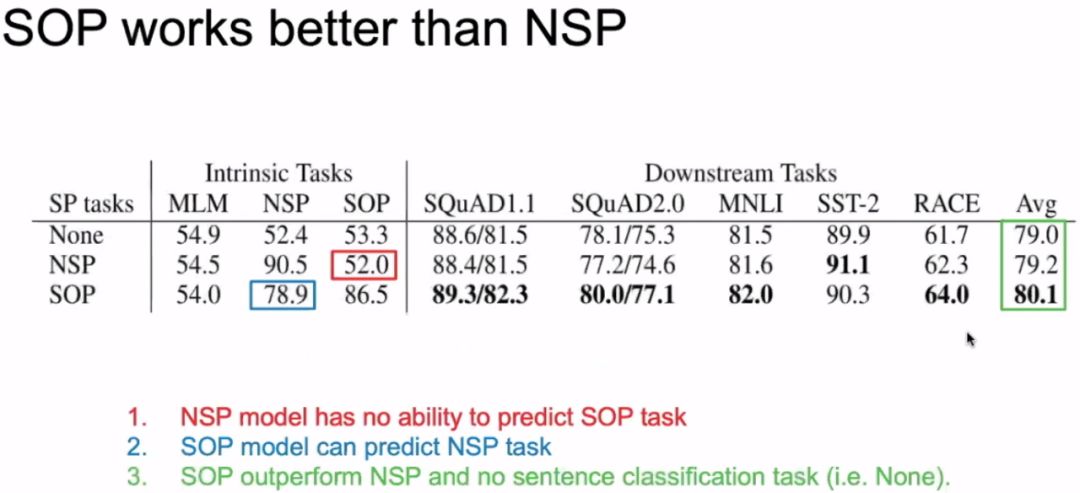
This pre-training strategy is also an innovation, with SOP standing for Sentence Order Prediction, which replaces NSP’s role in BERT. After all, some experiments indicate that NSP not only has no effect but can actually harm the model. SOP’s method is similar to NSP; it also determines whether the second sentence is the next sentence of the first, but for negative examples, SOP does not generate them from unrelated sentences but instead flips the original consecutive two sentences to form a negative example.


3.7 Removing Dropout
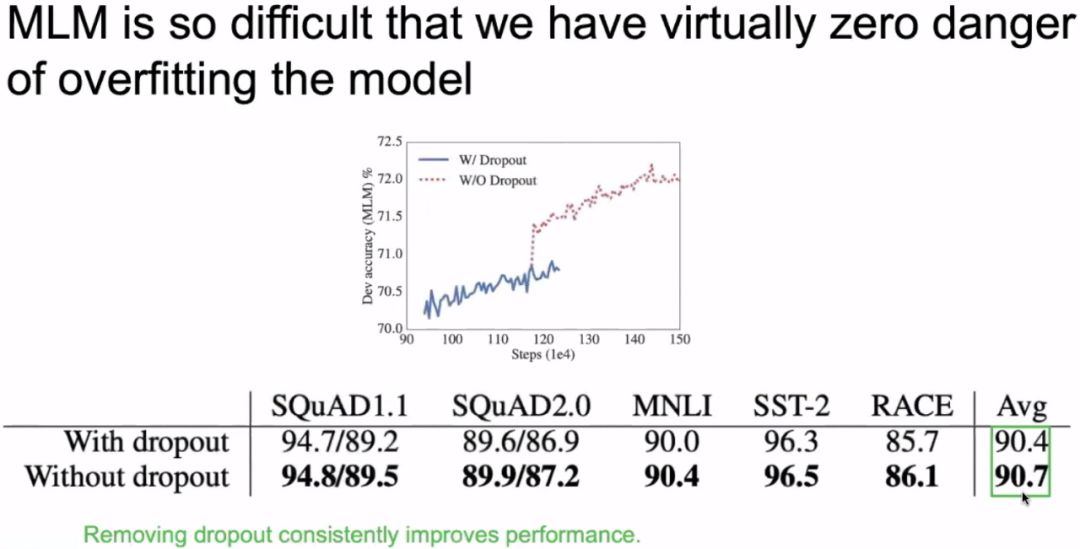
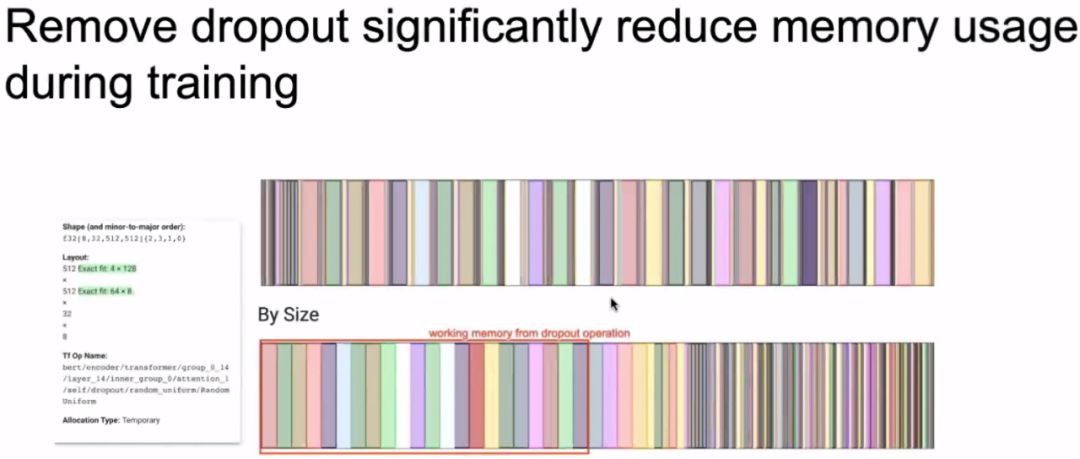
Innovation: Further increase model capacity by removing dropout
Removing dropout in ALBERT leads to very minimal accuracy improvement but significantly reduces memory usage during training.
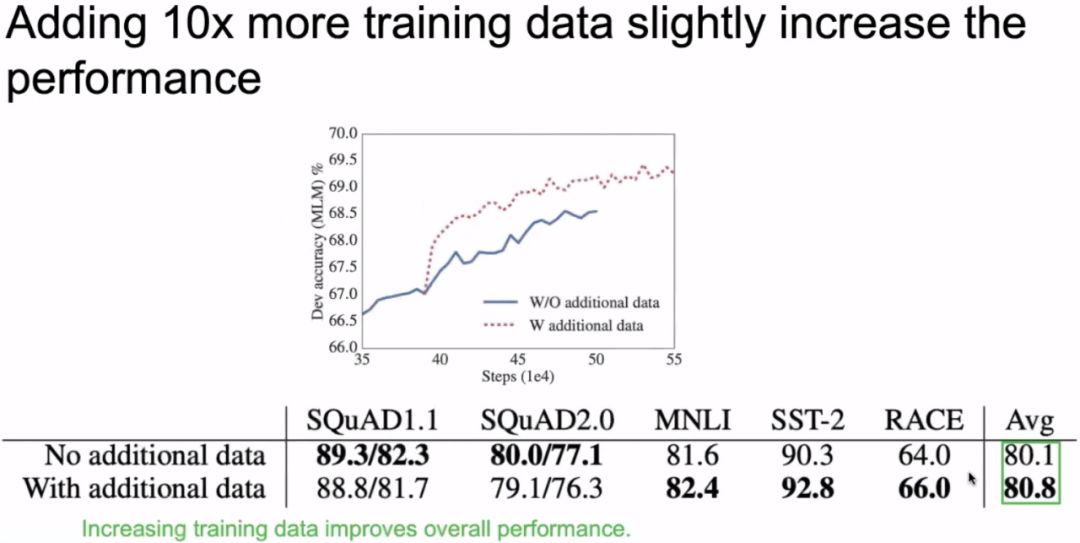
3.8 Increasing Data Volume
4. Summary of ALBERT
ALBERT was proposed to slim down BERT, allowing a larger BERT model to run effectively. The authors reduced parameters through weight sharing and matrix factorization. This lowered spatial complexity, but computational load did not decrease, so during downstream tasks and predictions, the model does not operate faster. Therefore, the authors say that current optimization methods for BERT are also aimed at optimizing time complexity.
The innovations of ALBERT are shown in the image below:

5. Future (Current) Works

6. Prospects for the NLP Field

7. Reference
[1] This article is a study note from Microstrong watching Lan Zhenzhong’s live course on Bilibili titled “From BERT to ALBERT”. Live address: https://live.bilibili.com/11869202 [2] [Natural Language Processing] NLP free live stream (Greedy Academy), https://www.bilibili.com/video/av89296151?p=4 [3] Understanding ALBERT – an article by xixika – Zhihu https://zhuanlan.zhihu.com/p/108105658 [4] ALBERT Principles and Practices, address: https://mp.weixin.qq.com/s/SCY2J2ZN_j2L0NoQQehd2A
Important! Yizhen Natural Language Processing – Academic WeChat group has been established
You can scan the QR code below to join the group for discussions,
Note: Please modify the remarks when adding as [School/Company + Name + Direction]
For example – Harbin Institute of Technology + Zhang San + Dialogue System.
WeChat account owner, please avoid direct sales. Thank you!
Recommended Reading:
[Long Article Explanation] From Transformer to BERT Model
Sai Er Translation | Understanding Transformer from Scratch
Nothing beats a code! A step-by-step guide to building a Transformer with Python