
Interpretation: AI Generates the Future
This article introduces the Multimodal Large Language Model (MLLM), its definition, applications using challenging prompts, and the top models that are reshaping computer vision.

Table of Contents
- What is a Multimodal Large Language Model (MLLM)?
- Applications and Cases of MLLMs in Computer Vision
- Leading Multimodal Large Language Models
- Future Outlook
1. What is a Multimodal Large Language Model (MLLM)?
Simply put, a Multimodal Large Language Model (MLLM) combines the reasoning capabilities of Large Language Models (LLMs) (such as GPT-3 [2] or LLaMA-3 [3]) while possessing the ability to receive, understand, and output information in multiple modalities.
Example: Figure 1 shows a multimodal AI system in the medical field [4]. It receives two inputs:
- A medical image
- A text query, such as: “Is there pleural effusion in this image?” The system outputs a predicted answer regarding the query.


In this article, the term “Multimodal Large Language Model” may be simplified to “multimodal model”.
1.1 The Rise of Multimodality in AI
In recent years, artificial intelligence has undergone significant transformations, with the rise of the Transformer [5] architecture greatly advancing the development of language models [6]. This architecture was proposed by Google in 2017 and has had a profound impact on the field of computer vision.
Early examples include Vision Transformer (ViT) [7], which segments images into multiple patches and processes them as independent visual tokens.
With the rise of Large Language Models (LLMs), a new generative model, the Multimodal Large Language Model (MLLM), has naturally emerged.
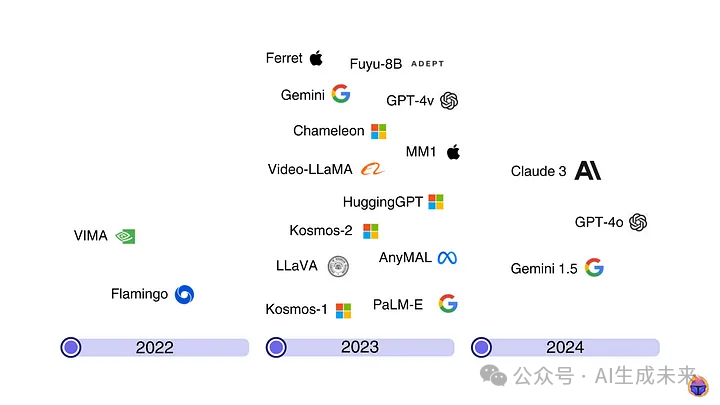
As shown in the previous timeline, by 2023, most tech giants have launched at least one MLLM. By 2024, OpenAI’s GPT-4o became a hot topic upon its release in May.
1.2 MLLMs vs VLMs vs Foundation Models
Some believe that MLLMs are actually Foundation Models. For example, Google classifies multimodal large language models such as Claude 3, PaliGemma, and Gemini 1.5 as foundation models.🤔
On the other hand, Vision-Language Models (VLMs) [8] are a subclass of multimodal models that integrate text and image inputs and generate text outputs.
The main differences between MLLMs and VLMs are:
- MLLMs can handle more modalities, not just text and images (like VLMs).
- VLMs have weaker reasoning capabilities, while MLLMs possess stronger logical reasoning abilities.
1.3 Architecture
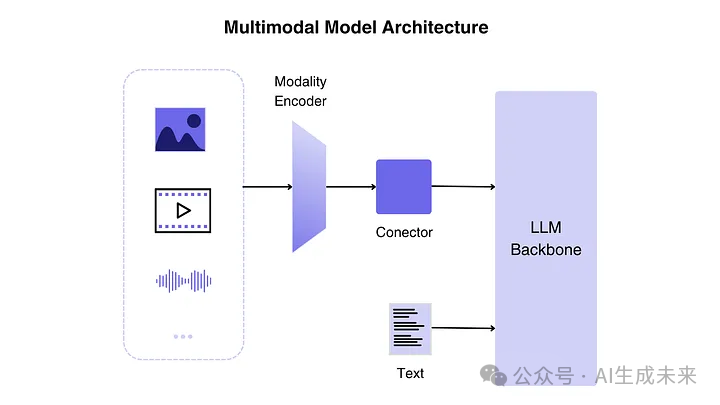
As shown in Figure 3, the architecture of MLLM is mainly divided into three parts:
- Modality Encoder: This component converts raw data such as visual and audio into compact representations. Pre-trained encoders (like CLIP) are commonly used for transfer learning to adapt to different modality inputs.
- LLM Backbone: The language model is responsible for generating text output, serving as the “core brain” of the MLLM. The encoder receives image, audio, or video inputs and generates features, which are processed by a connector (modality interface) before being input into the LLM.
- Modality Interface: This connects the encoder and LLM, ensuring that the LLM can understand information from different modalities and perform reasonable reasoning and output.
2. Applications of Multimodal Models in Computer Vision
To validate the capabilities of these models, we tested three top MLLMs using GPUs and employed challenging queries (no longer simple examples of cats 🐱 and dogs 🐶).
Tested MLLMs:
- GPT-4o (OpenAI)
- LLaVA 7b (Open Source, based on LLaMA)
- Apple Ferret 7b (Open Source by Apple)
2.1 Object Counting in the Presence of Occlusion

Task: Count the number of safety helmets appearing in the image and provide their locations (see Figure 4).
- GPT-4o provided a detailed scene description but gave incorrect coordinates.
- LLaVA only detected 3 safety helmets and failed to correctly identify the occluded helmet.
- Apple Ferret successfully detected 4 safety helmets, including the one on the left that was occluded! ⭐️
2.2 Autonomous Driving: Risk Assessment and Planning

Task: Assess risks from the perspective of an autonomous vehicle and detect vehicles and pedestrians (see Figure 5).
- LLaVA failed to identify the large truck ahead.
- GPT-4o excelled in text analysis but had incorrect target box positions.
- Apple Ferret was the only model that accurately detected most objects and provided correct coordinates ✅.
2.3 Sports Analysis: Object Detection and Scene Understanding

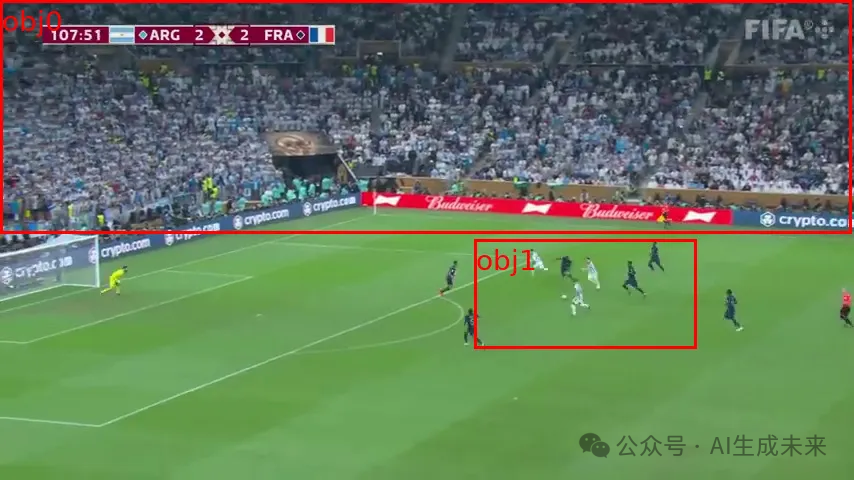
Task: Analyze a soccer match scene, including player counting, ball and goalkeeper position estimation, and predicting the likelihood of scoring (see Figure 7).
Results:
- All models failed to correctly detect all players and distinguish between different teams.
- In contrast, unimodal detection models like YOLOv8 performed better.
This indicates that MLLMs still have limitations in some complex tasks and have not fully replaced specialized computer vision models.
Should the next step be to fine-tune MLLMs? 🤔
3. Leading Multimodal Large Language Models
| Model | Input | Output | Description | Link |
|---|---|---|---|---|
| GPT-4o (2024, OpenAI) | Text, Image, Audio (Test), Video (Test) | Text, Image | Has cross-modal reasoning capabilities using “multimodal thinking chain” technology. | https://chatgpt.com/ |
| Claude 3.5 Sonnet (2024, Anthropic) | Text, Image | Text, Image | Supports a 200K token context window, excels in complex analysis and automation tasks. | https://claude.ai/ |
| LLaVA (2023, University of Wisconsin-Madison) | Text, Image | Text | Open-source model that employs “instruction fine-tuning” technology, with performance comparable to GPT-4 for some tasks. | https://llava-vl.github.io/ |
| Gemini 1.5 (2024, Google) | Text, Image, Audio (Test), Video (Test) | Text, Image | Three variants (Ultra, Pro, Nano) suitable for different application scenarios. | https://gemini.google.com/ |
| Qwen-VL (2024, Alibaba Cloud) | Text, Image | Text, Image | Improved image reasoning capabilities, supports high-resolution image analysis. | https://qwenlm.github.io/blog/qwen-vl/ |
References
[1] A Survey on Multimodal Large Language Models
[2] Language Models are Few-Shot Learners
[3] Introducing Meta Llama-3: The most capable openly available LLM to date
[4] Multimodal medical AI
[5] Attention is all you need
[6] Language Models are Unsupervised Multitask Learners
[7] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
[8] An Introduction to Vision-Language Modeling
[9] GPT-4o
[10] LLaVA: Large Language and Vision Assistant
[11] FERRET: Refer and Ground Anything Anywhere at Any Granularity
This article is for academic sharing only. If there are any infringements, please contact us for deletion.