When developing or incubating large models, do not insist on absolute short-term financial metrics, but rather focus on relative improvements in business and technical indicators.
By | Tencent Research Institute Large Model Research Group
The technology of general large models is developing rapidly, but many traditional industries are not advancing as quickly. For enterprises, the application of large models needs to comprehensively consider various factors such as professionalism, data security, continuous iteration, and overall costs. In response to these realities, Tencent Group has proposed the concept of focusing on the development of industry large models. This article systematically summarizes the real situation of the development of industry large models based on extensive practical feedback from the front lines, clarifying key controversies and confusion. Enterprises that genuinely address user needs and are closer to scenarios and data will possess the future of large models.
Industry Large Models Bridge the Gap Between Technology and Demand
1. Large Models Trigger an Intelligent Revolution
On November 30, 2022, OpenAI released the large language model (LLM, Large Language Model) ChatGPT, which saw rapid growth in user numbers, becoming the fastest-growing application in history. The explosive popularity of ChatGPT marked the beginning of the era of AI (Artificial Intelligence) large models and heralded a new stage in AI’s journey towards Artificial General Intelligence (AGI). Currently, there is no clear and unified definition of large models in the industry; in a narrow sense, it refers to large language models based on the Transformer technology framework; in a broad sense, it includes multimodal large models encompassing language, sound, image, video, etc., with technical frameworks that also cover stable diffusion models.
Before the emergence of large models, artificial intelligence typically required the design of specialized algorithm models tailored to specific tasks and scenarios, executing only single tasks within the range of training data. The breakthrough of large models lies in their ability to exhibit human-like general intelligence “emergence” capabilities, allowing them to learn knowledge from multiple domains and handle various tasks, hence they are also referred to as general large models. Large models have many characteristics.
First, large parameter scale. The parameter scale of large models is significantly larger than that of traditional deep learning models, exhibiting scaling law characteristics, meaning that there is a power-law relationship between model performance and model scale, dataset size, and computational resources used for training. Performance improves exponentially with these three factors; simply put, great effort yields remarkable results. However, “large” does not have an absolute standard. Traditional models typically have parameter counts ranging from tens of thousands to hundreds of millions, while large models have at least hundreds of millions and have developed to trillions.
Second, strong generalization ability. Large models can effectively handle various unseen data or new tasks. Based on attention mechanisms and pre-training on large-scale, diverse, unlabeled datasets, large models can learn and master rich general knowledge and methods, thus being applicable in a wide range of scenarios and tasks. Large models do not require or only need a small number of specific task data samples to significantly improve performance on new tasks.
Third, support for multimodality. Large models can efficiently process various types of modality data. Traditional deep learning models mostly handle single data types (text, speech, or image), while large models can achieve cross-modal data understanding, retrieval, and generation through expanded encoding/decoding, cross-attention, and transfer learning. Large Multimodal Models (LMMs) can provide more comprehensive cognitive abilities and rich interactive experiences, broadening the application scope of AI in handling complex tasks, becoming one of the important paths for the industry to explore towards general artificial intelligence.
2. Industry Large Models are the Last Mile of AI+
The scaling law drives the continuous improvement of the performance of general large models, but it also creates the “impossible triangle” problem: it is difficult to achieve professionalism, generalization, and economy simultaneously.
First, professionalism refers to the accuracy and efficiency of large models in handling specific domain issues or tasks. The higher the requirement for professionalism, the more training on specific domain data is needed, which may lead to model overfitting and reduce generalization ability. Additionally, increased data collection and training will also increase costs and reduce economy.
Second, generalization refers to the performance of large models on new samples outside the training dataset. The higher the generalization requirement, the more diverse large-scale training datasets are needed, and the more model parameters are required, which means increased training and usage costs, reduced economy, and possibly reduced professional ability to handle specific issues.
Third, economy refers to the input-output ratio of large model training and application. The higher the requirement for economy, the less computational resources and costs are needed to meet performance needs; however, reducing resource consumption generally requires using smaller models or fewer parameters, which in turn reduces model performance. General large models primarily aim to develop general capabilities, focusing more on generalization, making it difficult to fully meet the specific needs of particular industries in terms of professionalism and economy, leading to situations such as “hallucinations and high costs.”
Industry organizations adopting large models also have two key considerations: competition and security. Transforming data into competitive advantage is the core driver. To effectively enhance competitiveness, organizations will strive to find the best-performing models and utilize unique resources of industry-specific or private data to customize, adjust, and optimize the models. Currently, leading general large models in the market, such as GPT-4, are mostly closed-source, serving the public through web and app services or standard API calls for developers, with limited customization options. Second, ensuring security and controllability is a bottom-line requirement. Large models not only involve the use of private data from organizations but also integrate with their business processes, making it increasingly important to emphasize security and controllability as the use of large models deepens. General large models typically provide services based on public clouds, which raises concerns for organizations regarding the security of private and sensitive data.
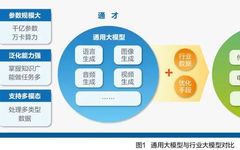
There is a gap between general large models and the specific needs of industries/organizations, and industry large models, with their numerous advantages (see Figure 1), have become a necessary product to bridge this gap, effectively supporting various industries in accelerating the application of large models.
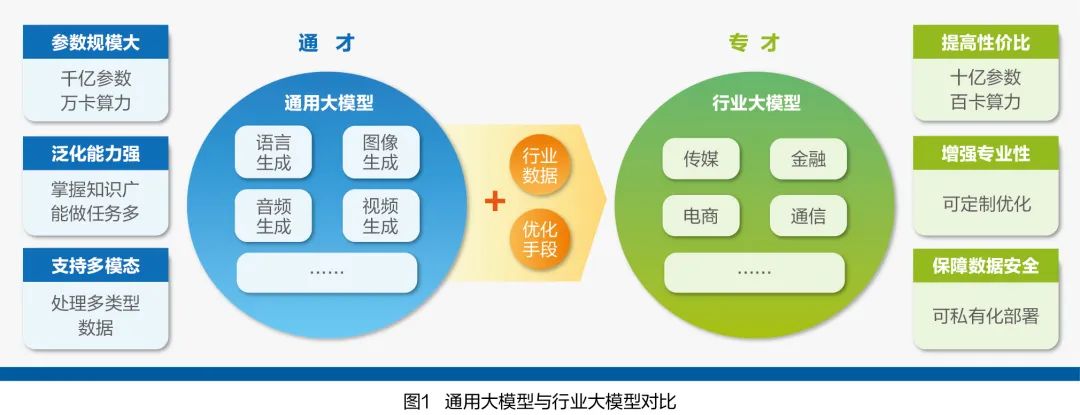
First, high cost-effectiveness. Industry large models can achieve good performance results through relatively low-cost retraining or fine-tuning based on smaller parameter models. Billion to hundred billion parameter industry large models are currently the mainstream choice, significantly saving development costs compared to general large models, which often have parameter counts exceeding hundreds of billions.
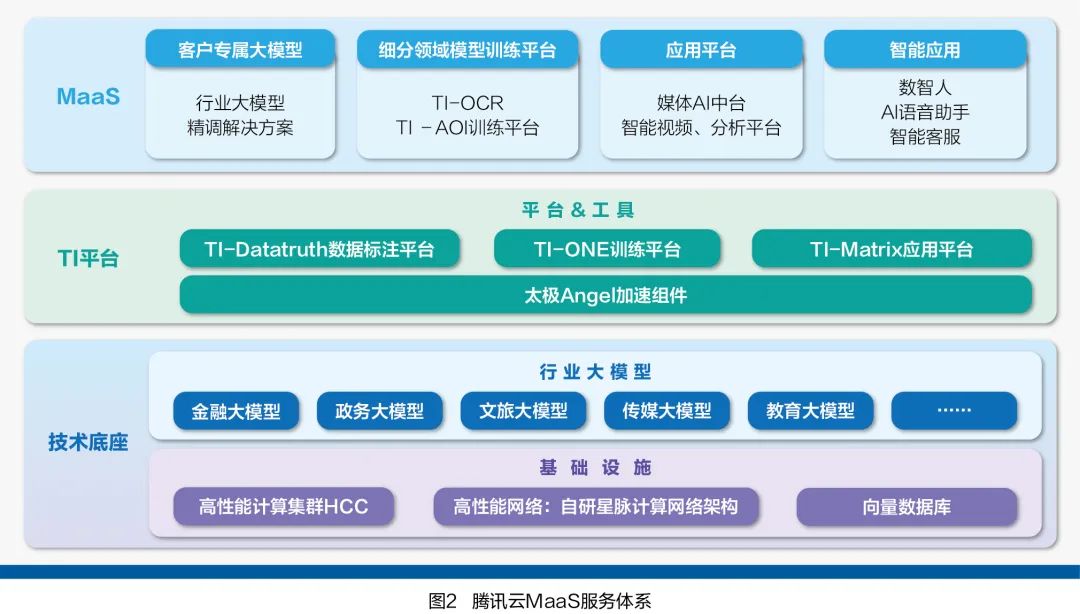
Second, customizable professionalism. Industry large models can be developed based on open-source models, allowing adjustments to model structure and parameters as needed, better adapting to personalized application needs. Through Model as a Service (MaaS, see Figure 2), organizations can quickly select suitable products from various models integrated into the platform, including initial versions of industry large models developed by vendors.
Third, data security and controllability. Industry large models can adopt a privatized deployment approach, allowing organizations to utilize private data more confidently to enhance application effectiveness and reduce data security concerns.
3. Industry Large Models are Built on General Large Models
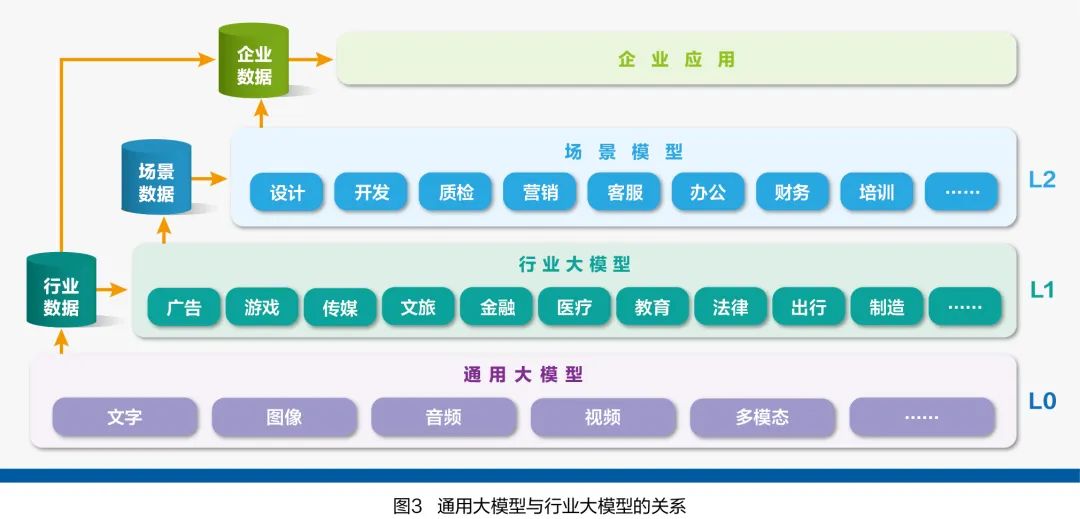
Industry large models are a concept relative to general large models. General large models focus on developing general capabilities, while industry large models emphasize developing professional capabilities. From industry practice, industry large models not only refer to the development of a model specifically for an industry but also include the adjustment and development of industry applications based on general large models. Therefore, broadly speaking, industry large models can be summarized as: utilizing large model technology to train or optimize for specific data and tasks, forming large models and applications with specialized knowledge and capabilities. In addition, internationally, the terms vertical model or vertical AI are more commonly used, while domestically, terms such as vertical model, domain model, and exclusive model are also used.
Industry large models are mostly built on the foundation of general large models. General large models possess rich knowledge and strong generalization abilities, which can provide a broad knowledge base for industry large models and enhance interactive experiences, while significantly saving the extensive data and computational resources required to train models from scratch, greatly improving the efficiency and effectiveness of developing and applying industry large models. By utilizing prompt engineering, retrieval-augmented generation, fine-tuning, continued pre-training/post-training, etc., models can better handle specific data or tasks, thus generating versions of industry large models (model changes) or possessing the functionalities of industry large models (model remains unchanged). Many industry large models available in the market today, such as those in finance, law, education, media, and cultural tourism, are mostly built on mainstream open-source large models like Llama, SD, GLM, Baichuan, etc. (see Figure 3).
The essence of industry large models is solutions, which often require tailored development or adjustments for specific data and tasks, targeting B-end customers. Each customer has unique business, data, and processes, and the specific problems that need to be addressed with large models also have personalized requirements. Therefore, the industry large models provided by vendors are not just products and tools; they also require customized services and support, and even need customer participation in co-construction. It can be understood that the products in industry large models are often “shells” that require customers to “renovate” based on their specific uses to meet their needs.
Progress and Evaluation of Large Model Applications in the Industry
The progress of large model technology implementation varies across different industries. This difference is mainly determined by the maturity of large model technology, the level of industry digitization, input-output ratios, industry requirements for professionalism and accuracy, and security and controllability factors.
1. Phases of Industry Large Model Applications
Referring to Everett Rogers’ “Diffusion of Innovations,” this article constructs a view from the dimensions of technology development and market penetration, combining front-line research data to comprehensively assess and position various industries at the beginning of 2024, allowing for comparisons of different industries’ adoption of large models. The results show that industries are currently mainly concentrated in two stages of large model technology adoption: the exploration incubation phase and the experimental acceleration phase. Some industries have already entered the adoption growth phase, but no industry has reached the maturity phase yet (see Figure 4).
The first phase is the exploration incubation phase, represented by agriculture and energy industries. In these industries, the number of organizations attempting to adopt large models is relatively small, but some leading or innovative organizations are actively exploring. The key to advancing market applications in these organizations lies in proving the feasibility and practicality of the technology and addressing industry-specific challenges, facing high risks and uncertainties while having the opportunity to lead the market.
The second phase is the experimental acceleration phase, represented by education, finance, gaming, and travel industries. These industries generally have a relatively good data foundation, and the number of organizations exploring the application of large models is rapidly increasing, starting to generate economic value in specific application scenarios. Organizations focus on how technology can solve practical problems, such as the winning rate of financial quantitative strategies and cost reduction and efficiency improvement in game design. Successful cases are the barometer of this phase, and practical benefits can attract more participants to join.
The third phase is the adoption growth phase, represented by the advertising and software industries. Mainstream organizations in these industries have generally adopted and are using large models. Due to their high compatibility with the foundational capabilities of large models, capabilities such as copy generation, text-to-image, code generation, and data analysis are widely used in many organizations within the advertising and software industries (including various internet applications). The key to further expanding the market lies in optimizing technology applications, enhancing user experience and efficiency, while also reducing costs.
The fourth phase is the maturity phase, which no industry has yet reached. This phase signifies that the application of large model technology is basically mature, and the vast majority of organizations are using it in major production and operational scenarios, establishing stable commercial partnerships with suppliers. Currently, large model technology is far from maturity, and the maturity of industry applications will require more time. Stability, interpretability, and reliability of plugin calls are all necessary prerequisites for industry applications to enter the maturity phase.
2. Analysis of Industry Large Model Application Scenarios
Research has found that multiple industries have begun exploring the application of large model technology in various production processes, specifically involving research/design, production/manufacturing, marketing/sales, customer service, and management.
Horizontal Comparison of Various Industries, this article further elaborates on specific application scenarios from the perspective of the speed of large model application progress. Digital-native industries are the pioneers in large model applications. Internet, gaming, and other digital-native industries, due to their high level of digitization, rich data accumulation, and strong technology acceptance, have become industries where large model implementation is relatively fast. The application scenarios of large models in these industries are widespread, covering many aspects such as marketing, customer service, and content generation, and have accumulated relatively rich and mature practices. Productive service industries have become demonstration areas for traditional industries integrating large models. Financial, advertising, software, and other productive service industries have strong demands in customer service and data processing due to the non-physical nature of their products and services, making them relatively compatible with the current capabilities of large model technology, thus advancing relatively quickly.
For example, financial institutions utilize large models to enhance the breadth and precision of services, empowering and improving efficiency in marketing, risk control, and investment research. The large model practices in these industries are accelerating towards maturity and exploring deeper into scenarios. Heavy asset industries are in the local exploration phase regarding large model applications. Industries such as energy/power, construction, and manufacturing are relatively slow in advancing large model applications, mainly limited by the complexity of offline production processes and high specialization. The core processes in these industries are in production operations, requiring a deeper integration of industry-specific knowledge based on the capabilities of general large models while avoiding hallucination issues to ensure accuracy and safety, which requires a longer and more gradual process. For instance, the manufacturing industry needs to deeply integrate large models with industrial internet, digital twins, and other infrastructures and professional data to maximize value in core areas such as process optimization, quality control, and equipment maintenance. Overall, two key factors influencing the speed of industry large model applications are: data availability, with higher quality data being easier to obtain and progressing faster; and demand adaptability, with the core business of the industry being more aligned with the creative generation and interaction capabilities of large models, thus progressing faster.
Looking at the Deep Vertical Links of Industries, the current penetration of large model technology presents characteristics similar to the industrial smile curve, where large model application implementation is faster at both ends of the value-added chain (research/design and marketing/service), while the middle (production, assembly, etc.) progresses more slowly. The reason lies in the paradigm shift brought about by large model technology, which particularly adapts to the two ends of the smile curve, knowledge-intensive and service-intensive fields, significantly enhancing human capabilities and even partially replacing them, marking a new chapter in the large-scale industrialization and automation of cognitive labor.
Marketing/Service Links Progress the Fastest, Cross-Industry Generalizability is a Key Reason. In the downstream marketing and service links of the industrial chain, content generation and intelligent dialogue based on organizations’ proprietary knowledge bases can significantly enhance the efficiency and experience of marketing and service activities, becoming the leading fields for various industries to attempt large model applications. Marketing and service activities are mostly directly aimed at C-end users, with strong cross-industry generalizability, fully utilizing the foundational capabilities of general large models and general marketing and service knowledge to quickly develop and debug applications tailored to organizational needs.
Research/Design Links are the Most Integrated, High-Quality Professional Datasets Determine Progress. In the upstream design and research links of the industrial chain, the efficient learning, reasoning, and generation capabilities of large models for massive knowledge can significantly enhance the efficiency of generating creative content such as copy, images, and code, and are also applicable in scientific computing fields involving massive research data processing, such as biology, environment, and materials. The availability of high-quality professional datasets determines the speed of progress in this link across different industries and fields. Fields like copy, images, and code have a wealth of open and open-source datasets based on the internet, thus progressing the fastest; fields with high-quality, large-scale open datasets in research also progress relatively quickly, such as DeepMind’s AlphaFold, which can predict protein 3D structures based solely on amino acids, significantly accelerating protein research, relying on the use of open datasets for pre-training; in industrial research/design areas, applications using large models to assist design generation have emerged in fields such as chips and automobiles, but these fields often involve strong commercial competition, making it difficult to obtain high-quality open datasets, requiring more investment and resulting in relatively slow practical progress.
Production/Manufacturing Links Progress Relatively Slowly, with Human-Aiding Enhancement as the Main Integration Point. The production and manufacturing links in the middle of the industrial chain often involve operations on various entities such as machines, requiring adaptation between people and equipment, processes, and systems, with many links and complex processes, high requirements for safety, accuracy, and stability. Currently, the capabilities of large models primarily manifest in natural language and image processing, and are not directly applicable to the complex numerical calculations, time-series analyses, and real-time decision-making scenarios of production and manufacturing, often requiring targeted collection of professional datasets for specialized model training and development, resulting in relatively slow integration progress. From current industry practices, the application of large models in production and manufacturing focuses on enhancing human capabilities, primarily taking the form of Copilot (robot assistants), assisting humans in industrial simulation, production monitoring, fault diagnosis, etc.
Although the progress and focus of integration between different industries and large models vary, there is a consensus and demand regarding the advantages and development directions of large models, generally encompassing three aspects.
First, content generation and creative design. This mainly utilizes the generative capabilities exhibited by large models, including text generation, image generation, and generative capabilities for code, tables, and other semi-textual content, combined with specific industry and scenario data to support content generation and creative design.
Second, information extraction and professional assistance. This mainly utilizes the summarization and planning capabilities of large models to assist individuals in extracting, analyzing, and processing professional knowledge based on specific industry and scenario data. Many industries are achieving such assistant-like applications through dialogue robots, covering multiple links such as research design, production manufacturing, and marketing services.
Third, task scheduling and intelligent interaction. The demand for large models in the industry more reflects the expectation for their agency capabilities, hoping that large models can connect with other applications, and even with real-world machines and devices, assisting in task scheduling and problem-solving across a broader range. This involves real-time data processing, automated control, environmental perception, and decision support, placing higher demands on the model’s response speed, accuracy, and adaptability, requiring the successful development of large model plugin ecosystems and the integration of large models with small models.
3. Evaluation Standards for Industry Large Models
As large models develop and their application in industries progresses, more and more industry organizations are beginning to care about what constitutes a successful industry large model. This question is also a common challenge faced by the industry today. Overall, large models are still in the early stages of development; on one hand, rapid technological iteration contains immense innovative value, while on the other hand, the scaling law drives exponential growth in investments such as computing power. Many industry organizations are almost unsure where to start, let alone having sufficient application experience to measure success. However, without measurement standards and methods, it is difficult to fully invest in technological innovation and application, easily falling into decision-making dilemmas.
Based on research from multiple parties and combined with international frontier explorations, this article attempts to summarize and construct the current 2-3-1 principle for measuring the success of industry large model applications: avoid two misconceptions, evaluate three types of value, and build one model.
Avoid Two Misconceptions. First, do not equate technical indicators with standards for proving the success of large models. Some organizations focus on technical performance, reflecting the success of large models by presenting growth in metric values. However, these indicators do not directly reflect the value of large models. We should focus on business indicators, such as user numbers, usage volumes, and revenue, and establish a connection between technical indicators and business indicators, using business development to drive technology development and optimization.
Second, do not overly emphasize the short-term output portion of the investment return while neglecting long-term input. It is not problematic for industries to focus on the practicality of large models and emphasize input-output ratios. However, if large models are treated similarly to mature businesses, requiring clear input-output, or even achieving positive profitability in the short term, it is not conducive to the development of large model applications. Large models are still in a rapid iteration stage with many uncertainties; a reasonable approach is to treat large models as research and development or incubation projects, not insisting on absolute achievement of short-term financial indicators, but instead focusing on relative improvements in business and technical indicators.
Evaluate Three Types of Value. First, cost reduction and efficiency improvement. The core lies in the ability of large models to assist in enhancing personnel capabilities and improving automation levels to simplify processes.
Second, business innovation. The core lies in the generative capabilities of large models to expand content supply, and their integration with application scenarios may create new functions or businesses. Third, enhanced experience. With the development towards multimodality and embodied intelligence, large models can provide users with a more natural and rich natural language interaction experience.
Build One Model. Data is the core energy that allows large models to operate and create value. For specific industry organizations, the ability to generate and expand value through large models primarily depends on how well they leverage their unique data. There is often a misconception regarding data, namely that more data is always better.
In fact, compared to quantity, data quality is more crucial for the performance of large models, especially for industry large models that require high professionalism and accuracy. The construction of industry large models needs to incorporate a high-quality data environment from the outset, through systematic data governance design, prioritizing the development of data pipelines, allowing large models to connect with relevant proprietary data sources of organizations, to support continuous acquisition of effective data, forming a data flywheel. A high-quality data environment is not merely about taking any data from the enterprise but needs to focus on application-related data capable of providing contextual understanding, with significant investments in continuously labeling, organizing, and monitoring this data, such as the Q&A content of industry experts. The data architecture itself also needs to encompass both structured and unstructured data sources to support diverse data processing.
Multi-Dimensional Optimization Strategies for Industry Large Models
In the construction and application of industry large models, due to differing demands and objectives, the complexity of technical implementation also varies significantly. Through research and summary, organizations currently adapt large models to industry applications in four main ways, from easy to difficult: prompt engineering, retrieval-augmented generation, fine-tuning, and pre-training. Enterprises typically do not use only one method but will combine them to achieve the best results.
1. Guidance: Prompt Engineering
Prompt engineering refers to the targeted design of prompts to guide large models to produce outputs needed for specific application scenarios. Prompt engineering is relatively simple to start with, requiring no bulk collection or construction of datasets, nor does it require adjustments or training of models. Many enterprises adopt this method to explore applications when first encountering large models. Although the capabilities of general large models are powerful, minimal input can still generate content, but arbitrary input may produce ineffective or erroneous outputs. By systematically designing prompts and standardizing model input and output methods, enterprises can quickly obtain more accurate and practical results.
Prompt engineering has become a fundamental method for continuously optimizing large model applications. By constructing a prompt library and continuously updating it, developers of large model applications in enterprises can reuse these prompts in different scenarios, encapsulating users’ open-ended inputs into prompts to send to the model, enabling the model to output more relevant and accurate content, thus enhancing user experience by avoiding repeated experimentation. The complexity of tasks determines the choice of technical methods for prompt engineering. Simple tasks can use zero-shot or few-shot prompts, providing no or minimal examples to the model, allowing it to quickly output results. Complex tasks often need to be broken down into several steps, providing more examples, using chain-of-thought prompting, etc., enabling the model to reason step-by-step to produce more accurate results. The effectiveness of prompt engineering highly depends on the capabilities of the general large model itself. If the general large model was trained with data related to industry applications, prompt engineering can effectively guide the model to output results more aligned with industry needs; however, if the general large model contains relatively little industry application data, the role of prompt engineering will be limited.
2. Plugin: Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) refers to providing specific domain data inputs to the model through external knowledge bases, without changing the large model itself, enabling more accurate information retrieval and generation in that domain. RAG effectively helps enterprises quickly utilize large models to process private data and has become a mainstream choice for deploying industry large model applications, especially suitable for enterprises with good data resource foundations and scenarios requiring accurate citation of specific domain knowledge, such as customer service Q&A, content inquiry, and recommendation.
The main advantages include: improving the professional accuracy of model applications, allowing the model to generate content based on specific data and reducing hallucinations; meeting the need for protection of the ownership of enterprises’ proprietary data, as the model only retrieves and calls external data without absorbing it and training it into the knowledge contained within the model; and providing a high cost-performance ratio, as the underlying large model itself does not require adjustments, and no massive computational resources are needed for fine-tuning or pre-training, enabling faster development and deployment of applications.
The core capability of RAG effectively combines retrieval and generation methods. The basic idea is to slice private data, vectorize it, and then recall it through vector retrieval, using it as contextual input to the general large model, which then analyzes and answers.
In specific applications, when a user poses a question or request, RAG first retrieves private data to find information related to the question. This information is then integrated into the original question, serving as additional contextual information along with the original question input into the large model. Upon receiving this enhanced prompt, the large model integrates it with its internal knowledge and ultimately generates more accurate content. Vectorization has become a common means to enhance the efficiency of private data retrieval. By converting various data into vectors, it can more efficiently process various types of unstructured data and conduct similarity searches, quickly finding the most similar vectors within large datasets, suitable for the needs of large models to retrieve and call various data.
3. Optimization: Fine-Tuning
Fine-tuning (FT) is often referred to as micro-tuning, which involves further adjusting certain parameters based on a pre-trained large model and a specific dataset, enabling the model to better adapt to business scenarios and accurately and efficiently complete specific tasks. This is currently a commonly used method for constructing industry large models. Fine-tuning is suitable for scenarios where specific fields have higher performance requirements for large models.
In industry applications, when general large models cannot accurately understand or generate professional content, fine-tuning can be used to enhance the model’s ability to comprehend industry-specific terms and correctly apply industry knowledge, ensuring that the model’s output aligns with specific business rules or logic. Fine-tuning internalizes industry knowledge into the parameters of the large model. The fine-tuned large model not only retains general knowledge but also accurately understands and utilizes industry knowledge, better adapting to the diverse scenarios within the industry, providing solutions that are more aligned with practical needs.
Fine-tuning is a compromise choice between customizing and optimizing large models and the cost investment. Fine-tuning often involves adjustments to the weights or structure of the large model and requires multiple iterations to meet performance requirements, thus requiring more time and computational resources compared to methods like prompt engineering and RAG that do not alter the model itself.
However, compared to training a model from scratch, fine-tuning is still a more economical and efficient method, as it typically only requires partial adjustments to the model and relatively fewer training data. High-quality datasets are critical to determine the performance of the model after fine-tuning. The datasets need to be closely related to business scenarios, and the data labeling must be highly precise. High-quality datasets can come from both internal data extraction from enterprises and external data collection, both requiring specialized data labeling processes. These datasets need to be representative, diverse, and accurate, complying with data privacy and other regulatory requirements. Only when enough high-quality data is used for training can fine-tuning truly take effect. The fine-tuning strategy also directly impacts the final performance of the large model.
Fine-tuning can be divided into full fine-tuning and partial fine-tuning. Partial fine-tuning methods are more efficient and are more commonly used in practice than full fine-tuning. Common forms include: supervised fine-tuning (SFT), which adjusts the model on labeled data for specific tasks; low-rank adaptation (LORA), which reduces the number of learning parameters through low-rank matrix updates; and adapter layers technology, which adds small network layers to the model, focusing on training specific layers to adapt to new tasks. The choice of fine-tuning strategy can be comprehensively considered based on specific task requirements, data availability, and computational resource constraints.
4. Native: Pre-Training
When the requirements cannot be met through prompt engineering, retrieval-augmented generation, or fine-tuning, the pre-training method can be chosen to build a large model specifically customized for a particular industry. Pre-training industry large models are suitable for scenarios that differ significantly from existing large models, requiring the collection and labeling of large amounts of industry-specific data, covering text, images, interaction records, and special format data (such as gene sequences). During the training process, the model typically starts training from the ground up or undergoes post-training based on a general model with some capabilities, enabling the large model to better understand specific domain terms, knowledge, and workflows, enhancing its performance and accuracy in industry applications, and ensuring its professionalism and efficiency in that field.
For example, Google’s protein generation model AlphaFold2 is a large model specific to bioinformatics, whose pre-training involved in-depth analysis and learning of a large amount of experimentally determined protein structure data, enabling the model to capture the complex relationship between protein sequences and their spatial structures, thus accurately understanding and predicting the complex three-dimensional structures of proteins.
The pre-training method involves significant costs and is currently less commonly adopted; it not only requires substantial computational resources and a long training process but also necessitates close collaboration and deep involvement of industry experts. Furthermore, pre-training from scratch involves complex data processing and model architecture design work, along with continuous tuning and validation during the training process. Therefore, only a few enterprises and research institutions have the capability to adopt this high-investment, high-risk approach, which also has high potential returns.
In the future, as technology advances and costs decrease, pre-training industry large models may increase. The technical process of pre-training industry large models is similar to that of general large models but pays more attention to industry characteristics. In terms of dataset preparation, industry-specific data will be incorporated from the outset, and in model construction technology and processes, it will involve model architecture design, pre-training task selection, extensive data processing, and large-scale unsupervised or self-supervised learning. For instance, using self-supervised learning (SSL) technology to generate labels from the data itself to learn the intrinsic structure and features of the data without manual labeling, and reinforcement learning from human feedback (RLHF) technology to guide the model learning process through subjective feedback from human experts, producing higher quality outputs.


