

Author: Shining
School: Beijing University of Posts and Telecommunications
Original article link: https://www.cnblogs.com/gczr/p/12874409.html
1. Background Introduction
BERT and RoBERTa have achieved SOTA results in regression tasks for sentence pairs, such as text semantic similarity. However, they require feeding both sentences into the network simultaneously, which leads to significant computational overhead: finding the most similar sentence pairs from 10,000 sentences requires approximately 50 million (C100002=49,995,000) inference computations, taking about 65 hours on a V100 GPU. This structure makes BERT unsuitable for semantic similarity searches and also for unsupervised tasks (e.g., clustering).
This paper modifies the BERT network and proposes the Sentence-BERT (SBERT) network structure, which uses Siamese and triplet network architectures to generate semantically meaningful sentence embedding vectors. Sentences with similar semantics have closer embedding vectors, allowing for similarity calculations (cosine similarity, Manhattan distance, Euclidean distance). This network structure reduces the time to find the most similar sentence pairs from 65 hours to 5 seconds (calculating cosine similarity takes about 0.01s), while maintaining the same level of accuracy. Thus, SBERT can accomplish new specific tasks, such as similarity comparison, clustering, and semantic-based information retrieval.
2. Model Introduction
1) Pooling Strategy
SBERT adds a pooling operation on the output results of BERT/RoBERTa to generate a fixed-size sentence embedding vector. Three pooling strategies were compared in the experiments:
-
Directly using the output vector at the CLS position to represent the entire sentence’s vector representation
-
MEAN strategy, calculating the average of each token’s output vectors to represent the sentence vector
-
MAX strategy, taking the maximum value of all output vectors in each dimension to represent the sentence vector
The experimental comparison of the three strategies is as follows:

It can be seen that among the three strategies, the MEAN strategy performed the best, so the subsequent experiments default to the MEAN strategy.
2) Model Structure
To fine-tune BERT/RoBERTa, the article uses Siamese and triplet networks to update the weight parameters, achieving semantically meaningful sentence vectors. This network structure depends on specific training data; the paper experiments with the following structures and objective functions:
Classification Objective Function:

Here, the embedding vectors u and v and their difference vector are concatenated to form a new vector, multiplied by the weight parameter Wt∈R3n*k, where n represents the dimension of the vector and k is the number of classification labels.
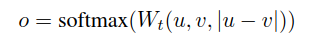
Cross-entropy loss is used during optimization.
Regression Objective Function:
The similarity computation structure for the two sentence embedding vectors u and v is as follows:

MAE (mean squared error) loss is used as the optimization objective function.
Triplet Objective Function:
Given a main sentence a, a positive sentence p, and a negative sentence n, the triplet loss adjusts the network to ensure that the distance between a and p is less than the distance between a and n. Mathematically, we minimize the following loss function:

s represents the sentence embedding vectors a, p, and n; ||·|| represents distance; and the margin parameter ε indicates that the distance between sp and sa should be at least ε closer than sn.
3) Model Training
The training combines the SNLI (Stanford Natural Language Inference) and Multi-Genre NLI datasets. SNLI contains 570,000 manually annotated sentence pairs, labeled as contradiction, entailment, neutral; MultiNLI is an upgraded version of SNLI, with the same format and labels, containing 430,000 sentence pairs, primarily a series of spoken and written texts. The text entailment relationship describes the inference relationship between two texts, where one text serves as a premise and the other as a hypothesis. If the hypothesis H can be inferred from the premise P, it is said that P entails H, denoted as P->H. An example is shown below:

During the experiment, the author fine-tuned SBERT using the 3-way softmax classification objective function for each epoch, with a batch_size of 16, using the Adam optimizer, a learning rate of 2e-5, and the MEAN pooling strategy.
3. Evaluation – Semantic Textual Similarity (STS)
In the evaluation, cosine similarity is used to compare the similarity of two sentence vectors.
1) Unsupervised STS
This evaluation uses task data from STS 2012-2016, STS benchmark data (constructed in 2017), and SICK-Relatedness data. These datasets are labeled sentence pairs indicating the relationship between sentences, ranging from 0 to 5. An example is shown below:

Unsupervised evaluation does not use any training data from these datasets, directly calculating the similarity between sentences using the trained model and measuring the model’s performance using the Spearman rank correlation coefficient. The results are as follows:

The results indicate that directly using BERT’s output yields poor performance, even worse than simply calculating the average of GloVe embedding vectors; however, using the Siamese network fine-tuned on the NLI dataset significantly improves the model’s performance, with SBERT and SRoBERTa showing minimal differences.
2) Supervised STS
The supervised STS dataset uses the STS benchmark (referred to as STSb) dataset, which was constructed in 2017, and is currently a popular supervised STS dataset. It primarily comes from three sources: subtitles, news, and forums, containing 8,628 sentence pairs, with 5,749 in the training set, 1,500 in the validation set, and 1,379 in the test set. BERT inputs sentence pairs into the network simultaneously, followed by a simple regression model as the output, achieving SOTA performance on this dataset.
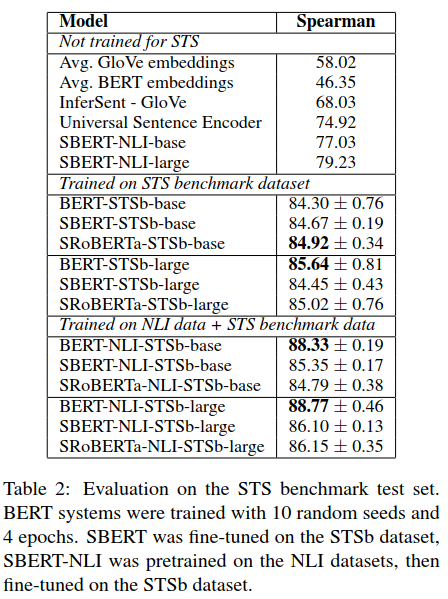
The experimental results are divided into three parts:
-
not trained for STS: indicates that the same model as the unsupervised evaluation was used, yielding identical results;
-
Trained on STS benchmark: indicates that the NLI dataset was not used, and the regression model was fine-tuned directly on the STSb training dataset using the Siamese network structure;
-
Trained on NLI data + STS benchmark: indicates that the Siamese network was first trained on the NLI dataset to learn sentence vector representations, and then the regression model was fine-tuned again on the STSb training set, effectively performing fine-tuning twice using both datasets.
During evaluation, the STSb test set was used. It can be seen that the last training method performed the best, especially with a significant improvement in the pure BERT architecture.
4. Evaluation – SentEval
SentEval is a popular tool used to evaluate the quality of sentence embeddings. Here, sentence embeddings can serve as features for a logistic regression model, constructing a classifier and calculating its accuracy on the test set. The following comparison of SBERT with other sentence embedding methods was conducted using the SentEval tool across several transfer tasks:
-
MR (movie review): Sentiment prediction of movie review excerpts, binary classification
-
CR (product review): Sentiment prediction of customer product reviews, binary classification
-
SUBJ (subjectivity status): Prediction of sentence subjectivity in movie reviews and plot summaries, binary classification
-
MPQA (opinion-polarity): Phrase-level opinion polarity classification from news websites, binary classification
-
SST (Stanford sentiment analysis): Stanford Sentiment Treebank, binary classification
-
TREC (question-type classification): Fine-grained question type classification from TREC, multi-class classification
-
MRPC: Microsoft Research Paraphrase Corpus from parallel news sources, paraphrase detection.

The experimental results show that the sentence vectors generated by SBERT seem to capture sentiment information well, with significant improvements in MR, CR, and SST; BERT performed poorly on the previous STS dataset but showed decent performance on SentEval. This is because the STS dataset measures sentence vector similarity using cosine similarity, which treats each dimension of the vector equally, while SentEval uses a logistic regression classifier for evaluation, where certain dimensions can significantly affect the final classification result.
Thus, the direct output results of BERT, whether from the CLS position or the average embedding, are not suitable for calculating cosine similarity, Manhattan distance, or Euclidean distance. Although BERT performs slightly better on SentEval, SBERT based on the NLI dataset still achieves SOTA results.
5. Ablation Study
To conduct an ablation study on different aspects of SBERT to better understand their relative importance, we constructed classification models on the SNLI and Multi-NLI datasets and regression models on the STSb dataset. In terms of pooling strategies, we compared MEAN, MAX, and CLS strategies; in the classification objective functions, we compared different vector combination methods. The results are as follows:

In terms of pooling strategies, MEAN performed the best; in vector combination modes, it was only used during classification training, and the results showed that the element-wise |u-v| had the most significant impact.
Original article title: “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”
Recommended Reading:
【Long Article Explanation】From Transformer to BERT Model
Sail Translation | Understanding Transformer from Scratch
A Picture is Worth a Thousand Words! A Step-by-Step Guide to Building a Transformer in Python