[GiantPandaCV Introduction] Unlike other articles, DCANet improves the ability of other Attention modules by enhancing them, allowing for better information flow between attention modules and improving attention learning capabilities. Currently, the article has not been accepted.
This article was first published on GiantPandaCV and may not be reproduced without permission.

1. Abstract
The self-attention mechanism has shown significant effects in many visual tasks, but these attention mechanisms often only consider the current features without fusing them with features from other layers (although there are a few works that perform fusion attention, such as BiSeNet and AFF).
The proposed DCANet (Deep Connected Attention Network) aims to enhance the capabilities of the attention module. The main approach is to connect adjacent Attention Blocks to allow information to flow between attention modules.
2. Concept
Attention Mechanism: The attention mechanism can achieve better feature representation by exploring the dependencies between features. Self-attention mechanisms have been widely used in various tasks in NLP and CV fields. The attention mechanism can be divided into three parts: channel attention mechanism, spatial attention mechanism, and self-attention; it is also said that self-attention can be viewed as a mix of channel and spatial attention.
Residual Links: Since ResNet and later DenseNet, residual links have become a standard design in current networks, allowing networks to become deeper and alleviating network degradation. The design of DCANet also references this idea.
Connected Attention: The connection method between attention modules has also been studied to some extent. For example, RA-CNN is a network architecture specifically designed for fine-grained image recognition, where the network can continuously generate discriminative regions, thus achieving recognition from coarse to fine. In GANet, high-level attention features are sent to lower-level features to guide attention learning.
3. Core
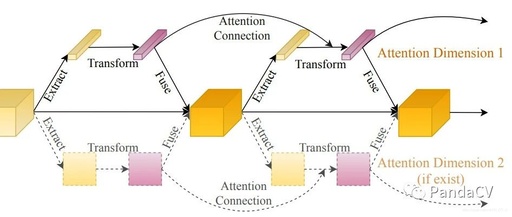
The following figure summarizes the design ideas regarding attention, dividing them into three stages:
-
Extraction: Feature extraction stage -
Transformation: The stage where information is processed or fused -
Fusion: The stage where the obtained information is fused into the main branch
The figure below shows SEblock, GEblock, GCblock, and SKblock, which can all be categorized into the above three stages.

Extraction
This stage involves feature extraction from the feature map, defined as:
Through the feature extractor g (wg is the parameter for this feature extraction operation, and G is the output result):
Transformation
This stage processes the aggregated information obtained from the previous stage and transforms it into a nonlinear attention space. The transformation t is defined as (wt is the parameter, T is the output result of this stage):
Fusion
This stage integrates the feature map acquired from the previous stage, which can be expressed as:
where it represents the final output of this layer, and represents the method of feature fusion, such as dot-product, summation, etc.
Attention Connection
This is the core of this article; features need to be obtained not only from the current layer but also from the previous layer, requiring fusion of information from two layers. Two specific fusion methods are proposed:
-
Direct Connection: Connected through addition.
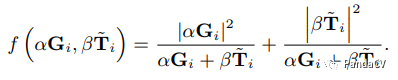
-
Weighted Connection: Connected through weighted methods.
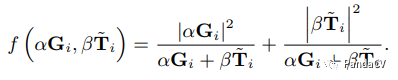
Why this fusion method is used, the author is not quite sure; discussions are welcome.
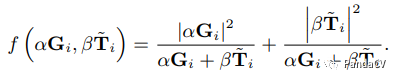
As seen, the upper path consists of two channel attention modules, with an Attention Connection between them allowing the following modules to utilize the information from the previous module. The lower path consists of two spatial attention modules, with the same principle; the spatial attention module can be present or absent.
4. Experiments
Classification results on ImageNet, compared primarily with the aforementioned modules, show about a one-point improvement:
Ablation experiment results on ImageNet12:
Visualization of results:
The first row shows the results of ResNet50, the second row CBAM-ResNet50, and the third row DCA-CBAM-ResNet50.
Comparison of results on the object detection dataset MSCOCO.
5. Evaluation
The author learned on Zhihu that this article was submitted to ECCV and rejected due to insufficient innovation and lack of significant improvement. While the improvement is temporarily set aside, the innovation points are indeed limited. Although many experiments were conducted and the analysis is good, the core idea is simply adding the features of the two modules. This method can indeed enhance performance, but it is insufficient for publication in top conferences. Consider innovations similar to ASFF, Effective Fusion Factor in FPN for Tiny Object Detection, etc.
Article link: https://arxiv.org/pdf/2007.05099.pdf
Code implementation: https://github.com/13952522076/DCANet
-END-
The author maintains a library related to attention mechanisms and other pluggable modules; PRs or Issues are welcome on GitHub.
https://github.com/pprp/awesome-attention-mechanism-in-cv
If you have questions or want to join the discussion group, you can add the author on WeChat; please specify your intention.
