Click on 'Xiao Bai Learns Vision' above, select 'Star' or 'Top'1. Model Iteration Methods
In practical applications of machine learning models, the model is usually iterated based on newly added data. Common model iteration methods include the following:
-
1. Retrain a model using the full dataset by directly merging historical training data with the new data. The model learns from the entire dataset offline, resulting in a completely new model. Pros and Cons: This is the most common method for model iteration in practice, and it usually yields the best model performance. However, this approach is time-consuming and resource-intensive, making it less suitable for real-time applications, especially in big data scenarios.
-
2. Model ensemble methods, where the predictions of the old model are used as a new feature to train a new model on the new data. Pros and Cons: Training time is shorter, but it increases decision complexity. The amount of new data must be large enough to ensure effective ensemble performance.
-
3. Incremental (online) learning methods, such as using
partial_fitfrom sklearn for direct incremental learning, allow for updates to the existing model using newly added data. Incremental learning is highly efficient for model iteration (especially suitable for neural network training, as discussed in arxiv.org/abs/1711.03705). In practice, online learning and offline full dataset learning are often used in combination, such as training a complex model offline with the full dataset and fine-tuning it online with new samples. Pros and Cons: Memory-friendly, fast model iteration, and high efficiency.
2. Incremental Learning
Several mainstream machine learning frameworks have implemented incremental learning functionality. For example, sklearn can directly call partial_fit for incremental learning, and neural network incremental learning is also very convenient. Below is an example of implementing incremental learning using the tensorflow.keras framework:
# tensorflow.keras incremental learning
model_path = 'init.model' # Load the original model
loaded_model = tf.keras.models.load_model(model_path) # Continue training the original model with new data
history = loaded_model.fit(
train_data_gen,
epochs=epochs)This article mainly introduces the incremental (online) learning of tree models, taking the tree models lightgbm and xgboost for incremental learning of financial default classification as examples to verify the actual effects. The example uses the dataset from the previous article: A Comprehensive Overview of Financial Risk Control Modeling Process (Python).
Before we start, we first divide the data into training and testing sets, with the test set used only for evaluation. Next, the training data is further divided into two parts: old training data and new training data. This is to verify the effect of learning the new dataset using the incremental learning method.
# Split the dataset: training set and test set
train_x, test_x, train_y, test_y = train_test_split(train_bank[num_feas + cate_feas], train_bank.isDefault, test_size=0.3, random_state=0)
# Further split the training set into old and new training sets, with the new training set using incremental learning
trainold_x, trainnew_x, trainold_y, trainnew_y = train_test_split(train_x, train_y, test_size=0.5, random_state=0)
lgb_train = lgb.Dataset(trainold_x, trainold_y)
lgb_newtrain = lgb.Dataset(trainnew_x, trainnew_y)
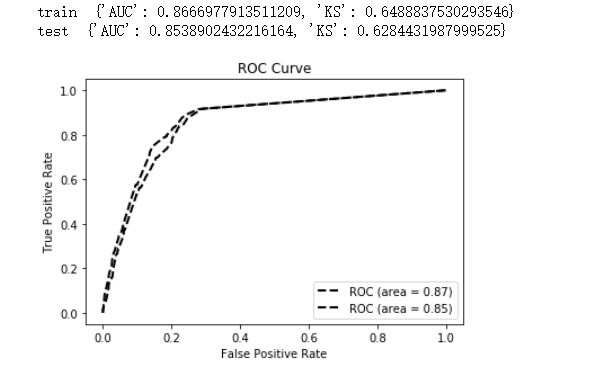
lgb_eval = lgb.Dataset(test_x, test_y, reference=lgb_train)Train the original lightgbm model, and the evaluation results are quite good: train {‘AUC’: 0.8696629477540933, ‘KS’: 0.6470059543871476} test {‘AUC’: 0.8458304576799567, ‘KS’: 0.6284431987999525}
# Parameters
params = {
'task': 'train',
'boosting_type': 'gbdt', # Set boosting type
'objective': 'binary', # Objective function
'metric': {'l2', 'auc'}, # Evaluation function
'num_leaves': 12, # Number of leaf nodes
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9, # Feature selection ratio for tree construction
'bagging_fraction': 0.8, # Sample selection ratio for tree construction
'verbose': 1
}
# Model training
gbm = lgb.train(params, lgb_train, num_boost_round=1)
print('train ', model_metrics(gbm, trainold_x, trainold_y))
print('test ', model_metrics(gbm, test_x, test_y))
# Visualization of tree model decisions
# First install https://graphviz.org/download/
import os
os.environ['PATH'] += os.pathsep + 'D:/Program Files/Graphviz/bin/'
for k in range(1):
ax = lgb.plot_tree(gbm, tree_index=k, figsize=(30,20), show_info=['split_gain', 'internal_value', 'internal_count', 'internal_weight', 'leaf_count', 'leaf_weight', 'data_percentage'])
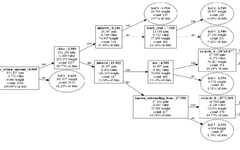
plt.show()The structure of the original tree model is printed as follows:
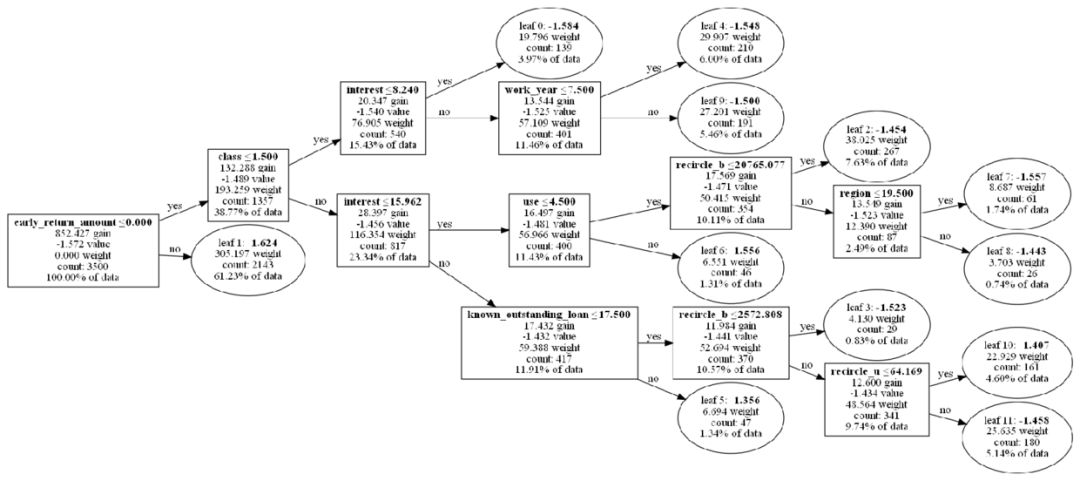
Next is the focus of this article, the incremental learning of the new lightgbm tree model. We continue to update the model to gbm2 based on the original gbm model.
In fact, the update method for lightgbm incremental learning is based on the unchanged tree structure of the original model, continuing to add new trees. For example, the following code shows that we will train 2 new trees:
num_boost_round = 2 # Continue training 2 trees
gbm2 = lgb.train(params,
lgb_newtrain, # New data
num_boost_round=num_boost_round,
init_model=gbm, # Continue training based on the original model gbm
verbose_eval=False,
keep_training_booster=True) # Support incremental training of the modelFrom the structure of the tree model after incremental learning, we can see that the original tree model gbm structure remains unchanged, with 2 new trees added at the end. Verifying the performance of the updated model after incremental learning, the AUC of the test set has improved by about 1% (Note: This example does not consider the differences in effects under parameter tuning, but the result seems quite good).
This raises a question: Is the incremental learning of tree models only a ‘patching’ update method? Can’t we update the weights of the leaf nodes of the old model?
In fact, both incremental learning methods are possible for tree models, but I have not found a supported method for lightgbm. Interested students can learn more. Below is the implementation of two incremental learning methods in XGBoost:
### XGBoost Incremental Learning https://xgboost.readthedocs.io/en/latest/parameter.html
import xgboost as xgb
import pprint
xgb_params_01 = {} # Incremental learning method one
xgb_params_02 = {'process_type': 'default', # default, update
'refresh_leaf': True} # Current iteration tree structure remains unchanged and adds new trees
# Incremental learning method two
xgb_params_02 = {'process_type': 'update', # default, update
'updater': 'refresh', # Can also choose to prune the current model
'refresh_leaf': True} # Only update the weights of the leaf nodes of the model,
dtrain_2class = xgb.DMatrix(train_x[num_feas], label=train_y, enable_categorical=True)
gbdt = xgb.train(xgb_params_01, dtrain_2class, num_boost_round=1) # Old model
pprint.pprint(gbdt.get_dump())
gbdt = xgb.train(xgb_params_02, dtrain_2class, num_boost_round=2, xgb_model=gbdt) # Update model
pprint.pprint(gbdt.get_dump())Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply 'Extension Module Chinese Tutorial' in the backend of 'Xiao Bai Learns Vision' public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Practical Python Vision Projects
Reply 'Python Vision Practical Projects' in the backend of 'Xiao Bai Learns Vision' public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply 'OpenCV Practical Projects 20 Lectures' in the backend of 'Xiao Bai Learns Vision' public account to download 20 practical projects based on OpenCV for advanced learning of OpenCV.
Discussion Group
You are welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will be gradually subdivided in the future). Please scan the WeChat number below to join the group, and note: 'Nickname + School/Company + Research Direction', for example: 'Zhang San + Shanghai Jiao Tong University + Vision SLAM'. Please follow the format, or you will not be approved. After successful addition, you will be invited to related WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise you will be removed. Thank you for your understanding.