
Selected from arXiv
Authors: Yang You, Jing Li, et al.
Editor: Machine Heart Editorial Team
Last year, Google released the large-scale pre-trained language model BERT based on the bidirectional Transformer and made it open-source. The model has a large number of parameters—300 million—and requires a long training time. Recently, researchers from Google Brain proposed a new optimizer called LAMB, which effectively reduces the pre-training time of BERT to just 76 minutes!
Although BERT performs remarkably, it requires a significant amount of computation. The original authors mentioned in their paper that they could only predict 15% of the words at a time, which causes the model to converge very slowly. If we want to retain this Mask mechanism, we need to find another method to accelerate the process.
At that time, the authors of BERT also stated on Reddit that the computational load for pre-training is very high. Jacob said: “OpenAI’s Transformer has 12 layers and 768 hidden units. They used 8 P100s to train on a dataset of 800 million words for 40 epochs, which took about a month. BERT-Large, however, has 24 layers and 2014 hidden units, and it needs to be trained on a dataset of 3.3 billion words for 40 epochs. Therefore, using 8 P100s, it might take a year? 16 Cloud TPUs are already a very large computing power.”
In the new paper from Google Brain, researchers proposed the new optimizer LAMB, which, by using a batch size of 65536/32768, requires only 8599 iterations and 76 minutes to complete the BERT pre-training. Overall, compared to the baseline BERT-Large using 16 TPU chips, LAMB trained BERT-Large on one TPU v3 Pod (1024 TPU chips), thus reducing the time from 3 days to 76 minutes.
However, in the original BERT paper, training BERT-Large used 64 TPU chips (16 Cloud TPUs), which took four days to complete.
Paper: Reducing BERT Pre-Training Time from 3 Days to 76 Minutes

Paper link: https://arxiv.org/abs/1904.00962
Abstract: Large batch training is key to accelerating the training of deep neural networks in large distributed systems. However, large batch training is challenging because it can create a generalization gap, and direct optimization can often lead to a drop in accuracy on the test set. BERT is currently the optimal deep learning model, built on a deep bidirectional transformer for language understanding. When we expand the batch size (e.g., batch sizes over 8192), previous large batch training techniques do not perform well on BERT. BERT pre-training requires a significant amount of time (3 days when using 16 TPUv3s).
To address this issue, researchers from Google Brain proposed a new optimizer called LAMB, which can scale the batch size up to 65536 without sacrificing accuracy. LAMB is a general optimizer suitable for both small and large batches, and requires no adjustment of other hyperparameters besides the learning rate. The baseline BERT-Large model’s pre-training requires 1 million iterations, while LAMB, using a batch size of 65536/32768, only requires 8599 iterations. The researchers pushed the batch size to the memory limits of the TPUv3 pod, completing BERT training in 76 minutes.
Specifically, the LAMB optimizer supports adaptive element-wise updating and accurate layer-wise correction. LAMB can scale the batch size for BERT pre-training to 64K without causing accuracy loss. BERT pre-training consists of two phases: 1) The first 9/10 of the training epochs use a sequence length of 128, 2) The last 1/10 of the training epochs use a sequence length of 512.
The baseline BERT-Large model’s pre-training requires 1 million iterations, but the researchers completed the pre-training in just 8599 iterations, reducing the training time from 3 days to 76 minutes. The training batch size used in this study approached the memory limits of the TPUv3 pod. The LAMB optimizer can scale the batch size to 128k or even larger. Due to hardware limitations, the batch size used at a sequence length of 512 was 32768, and at a sequence length of 128, it was 65536. The BERT models referred to in this paper all denote BERT-Large. For fairness, all experiments in the study ran the same number of epochs (i.e., a fixed number of floating-point operations). The experimental results are shown in the table below.
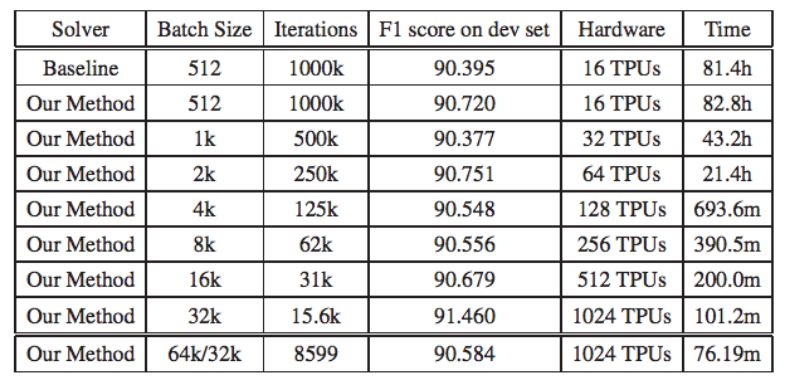
Table 1: The study used the F1 score from SQuAD-v1 as the accuracy metric.
In the table above, the baseline F1 scores are from the corresponding scores of the BERT-Large pre-trained model in the open-source GitHub. The hardware used for the experiments was TPUv3, and the experimental settings were the same as the baseline BERT-Large: the first 9/10 of the training epochs used a sequence length of 128, and the last 1/10 of the training epochs used a sequence length of 512. All experiments ran the same number of epochs.
LAMB (Layer-wise Adaptive Moments optimizer for Batch training)
The training of the BERT baseline model used Adam with weight decay (a variant of the Adam optimizer) as the optimizer. Another adaptive optimizer successfully used for large batch convolutional neural network training is LARS. These optimizers inspired the researchers to propose the new optimizer LAMB for large batch BERT training. For details on the LAMB optimizer, see Algorithm 1.

Experiments
Conventional Training
TPUs are powerful floating-point computing hardware. The researchers used TPUv3 in all experiments. Each TPUv3 pod has 1024 chips and can provide over 100 petaflops of mixed-precision computation. The experimental results are shown in Table 1. The baseline model’s pre-training process used the Wikipedia and BooksCorpus datasets. The researchers used the same datasets as the open-source BERT model for pre-training, which includes the Wikipedia dataset with 2.5 billion words and the BooksCorpus dataset with 800 million words.
The authors of BERT first performed 900k iterations with a sequence length of 128, followed by 100k iterations with a sequence length of 512. The total training time on 16 TPUv3s was about 3 days. The researchers used the F1 score from SQuAD-v1 as the accuracy metric. A higher F1 score indicates better accuracy. The researchers downloaded the pre-trained model provided in the BERT open-source project. Using the script provided by the BERT authors, the baseline model achieved an F1 score of 90.395.
In this study, the researchers used the dataset and baseline model provided by the BERT authors, changing only the optimizer. After using the new optimizer LAMB, the researchers performed 15625 iterations with a batch size of 32768, achieving an F1 score of 91.460 (with 14063 iterations for a sequence length of 128 and 1562 iterations for a sequence length of 512). The researchers reduced the BERT training time from 3 days to about 100 minutes.
The study achieved a weak scaling efficiency of 76.7%. The researchers used synchronous data parallelism for distributed training on the TPU Pod, so gradient transfer incurs communication overhead. These gradients are the same size as the trained model. The weak scaling efficiency can reach over 90% when training ResNet-50 on the ImageNet dataset because ResNet-50 has far fewer parameters than BERT (25 million vs 300 million). The LAMB optimizer does not require users to adjust hyperparameters, as users only need to input the learning rate.
Mixed-Batch Training
As mentioned earlier, BERT pre-training is divided into two parts: 1) The first 9/10 of the epochs use a sequence length of 128; 2) The last 1/10 of the epochs use a sequence length of 512 for training. For the second phase, due to memory constraints, the maximum batch size on the TPUv3 Pod is 32768, so the batch size used in the second phase is 32768. For the first phase, limited by memory, the maximum batch size on the TPUv3 Pod is 131072. However, when the researchers increased the batch size from 65536 to 131072, they did not observe significant acceleration, so they set the batch size for phase 1 to 65536.
Previously, other researchers also discussed mixed-batch training, but they increased the batch size during training; in contrast, this study decreased the batch size so they could fully utilize hardware resources from start to finish. Increasing the batch size can help warm up the initial training and stabilize the optimization process, but decreasing the batch size may disrupt the optimization process and lead to non-convergence in training.
In the researchers’ experiments, they found that some techniques could stabilize the optimization process in the second phase. Since these two phases switch to different optimization problems, it is necessary to re-warm-up the optimization process. The researchers did not perform learning rate decay in the second phase but instead increased the learning rate from zero (re-warm-up). Similar to the first phase, the researchers executed learning rate decay after the re-warm-up. As a result, they were able to complete BERT training in 8599 iterations in just 76 minutes, achieving a weak scaling efficiency of 101.8%.

This article is compiled by Machine Heart. For reprints, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time Reporter / Intern): [email protected]
Submissions or seeking coverage: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]