

Recommended by New Intelligence
Recommended by New Intelligence
Source: Zhuanzhi (ID: Quan_Zhuanzhi)
Editor: Sanshi
[New Intelligence Guide] In the field of NLP, various advanced tools have emerged recently. However, practice is the key, and how to apply them to your own models is crucial. This article introduces this issue.
Recently in NLP, various pre-trained language models like ELMO, GPT, BERT, Transformer-XL, and GPT-2 have emerged, continuously refreshing the state-of-the-art in various NLP tasks, which is truly exciting. However, when I opened their papers, each one had the words: “Weaklings Retreat” written on it. How exactly can I use these top-notch tools in my model? The answer lies in the pytorch-pretrained-BERT open-sourced by the geniuses at Hugging Face.
GitHub link:
https://github.com/huggingface/pytorch-pretrained-BERT
Recently, various pre-trained language models have swept through various NLP tasks. Here we introduce three of the hottest pre-trained models:
-
BERT, by the Google AI team, published on October 11, 2018. Its paper is: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
-
Transformer-XL, by Google AI and Carnegie Mellon University, published on January 9, 2019. Its paper is: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
-
GPT-2, by the OpenAI team, published on February 14, 2019. Its paper is: Language Models are Unsupervised Multitask Learners.
Basically, each paper, when published, refreshed almost all NLP tasks’ state-of-the-art at that time, sparking a wave of excitement. Of course, the current hot topic is GPT-2, which was just published a few days ago.
However, when I opened their papers, I found each one had the words: “Weaklings Retreat” written on it. How can I use these top-notch tools in my model? The geniuses at Hugging Face have kept up with the frontier, implementing and open-sourcing all pre-trained language models. Even more impressively, they have done a lot of packaging, allowing everyone to stand on the shoulders of these giants.
The library open-sourced by Hugging Face is called pytorch-pretrained-bert, and you can find the link at the beginning of this article. In the following sections, we will introduce its installation and usage.
You can install it directly using Pip install:
pip install pytorch-pretrained-bert
Inside pytorch-pretrained-bert are BERT, GPT, Transformer-XL, and GPT-2.
To obtain the BERT representation of a sentence, we can:


After obtaining the representation, we can connect it to our own model, such as NER.
We can also obtain the GPT representation:
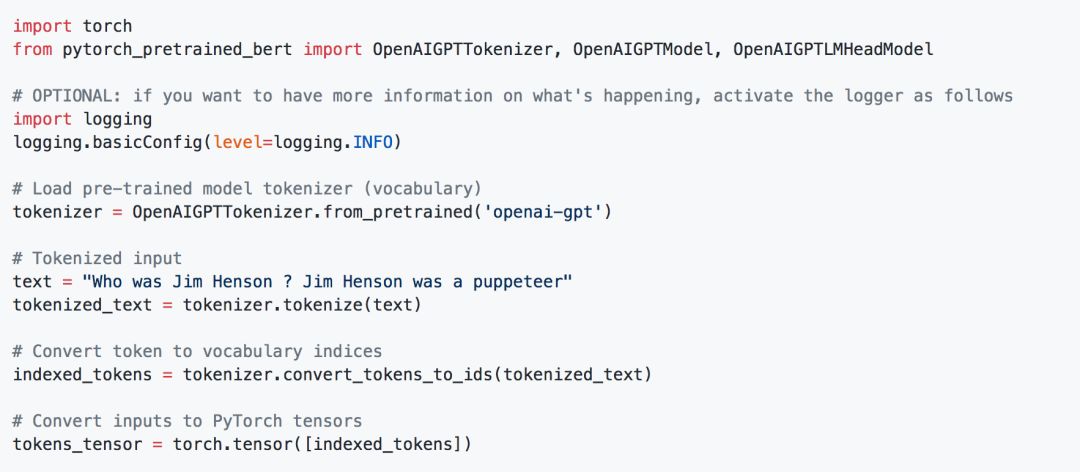

Transformer-XL representation:
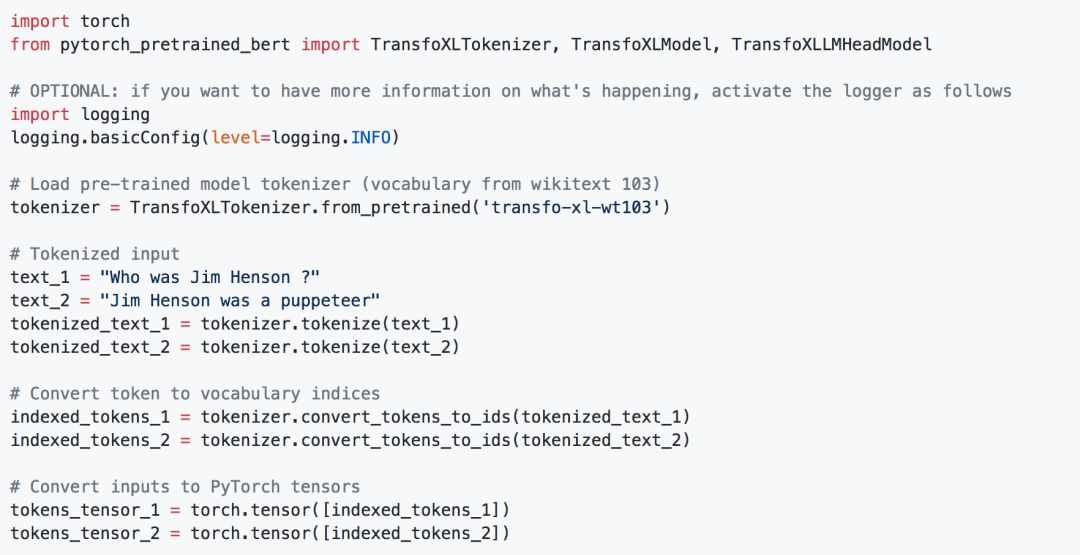

And the very popular GPT-2 representation:
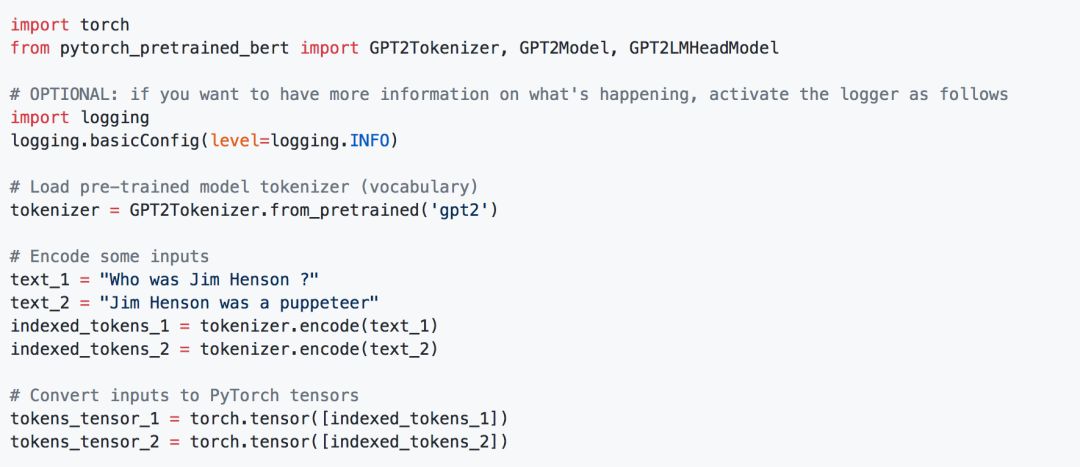

With these representations, we can connect our own models, such as:
-
Text Classification
-
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_classifier.py
-
Reading Comprehension
-
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_squad.py
-
Language Modeling
-
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_lm_finetuning.py
-
And more
This article is reprinted with permission from Zhuanzhi. Click to read the original text.
More Reading
-
After reading this article, will you still shout for “quickly creating a Chinese chip”?
-
Tencent gives a valuation of $2.7 billion, is Reddit becoming a Chinese company?
-
Three Spring Festivals in four years, large humanoid service robots made in China!
[Join the Community]
The New Intelligence AI technology + industry community is recruiting. We welcome students interested in AI technology + industry implementation to add the WeChat account of the assistant:aiera2015_2 to join the group; after passing the review, we will invite you to join the group. After joining the community, please be sure to modify your group remark (Name – Company – Position; the professional group review is strict, please understand).