
Author: Gao Kaiyuan
School: Shanghai Jiao Tong University
Research Direction: Natural Language Processing
Zhihu Column: BERT on the Shoulders of Giants
Original Article Link:
https://zhuanlan.zhihu.com/p/91052495
Introduction
In the previous blog, I discussed some knowledge representation learning models. Today, let’s explore the current most popular BERT model and how it develops with the addition of external knowledge. This idea has been seen before in interesting and efficient works, such as Baidu’s ERNIE and ERNIE2.0, as well as Tsinghua’s ERNIE. For introductions to these works, please refer to the article on new NLP models standing on the shoulders of BERT (PART I).
√ KG-BERT from NWU
√ K-BERT from PKU
√ KnowBERT from AI2
1. KG-BERT: BERT for Knowledge Graph Completion (2019)
This article introduces work on knowledge base completion, where the pre-trained model BERT can incorporate richer contextual representations into the model, achieving SOTA results in tasks such as triple classification, link prediction, and relation prediction.
The specific approach is very simple and understandable: it modifies the input of the BERT model to be suitable for the format of knowledge base triples.
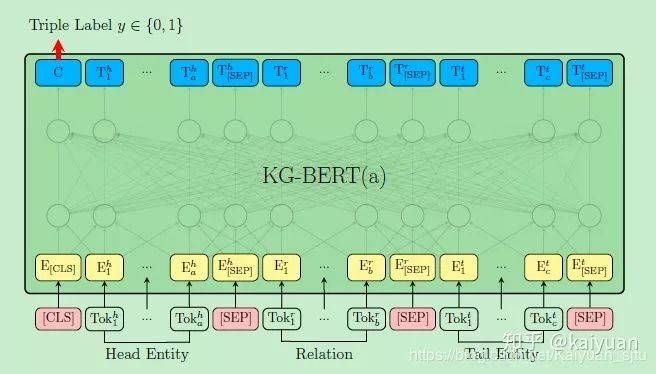
First is KG-BERT(a), where the input is in the form of triples  and the special tokens that come with BERT. For example, for the triple
and the special tokens that come with BERT. For example, for the triple  , the
, the Head Entity input can be represented as Steven Paul Jobs was an American business magnate, entrepreneur and investor or Steve Jobs, while the Tail Entity can be represented as Apple Inc. is an American multinational technology company headquartered in Cupertino, California or Apple Inc. This means that the inputs for the head and tail entities can be either entity description sentences or the entity names themselves.
The model training first constructs positive triple set and negative triple set separately, and then uses BERT’s [CLS] token to perform a sigmoid scoring and finally a cross-entropy loss.

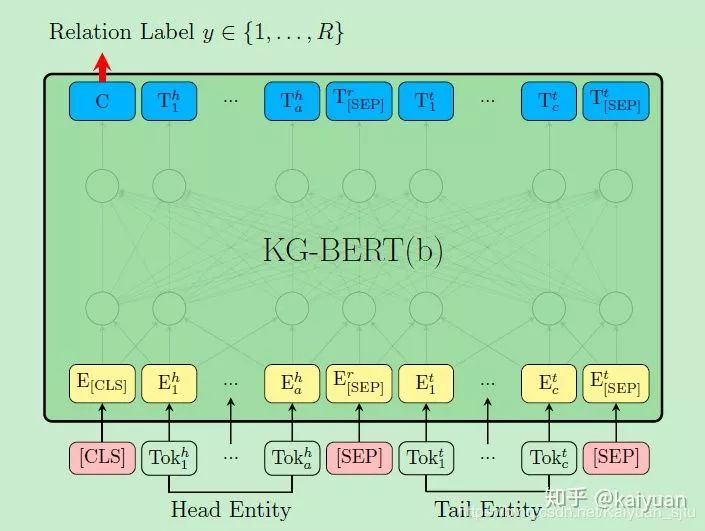
The aforementioned KG-BERT(a) requires input relationships, which are not suitable for relation classification tasks. Therefore, the author proposed another version, KG-BERT(b), as shown in the figure above. Here, the sigmoid binary classification is changed to a softmax multi-class classification of relations.

One thought I have is that since so much triple information has been trained, the model should have learned some information about external knowledge, which can be seen as a form of knowledge fusion. Could this model, after training on triples, be used for other NLU tasks to see how it performs?
yao8839836/kg-bertgithub.com
2. K-BERT: Enabling Language Representation with Knowledge Graph (2019)
The author points out that the BERT model trained on public corpora only acquires general knowledge, much like an ordinary person. When faced with specific domain situations (such as medical, financial, etc.), it often performs poorly due to domain discrepancy between pre-training and fine-tuning. The proposed K-BERT acts like a domain expert by integrating structured information (triples) from knowledge bases into the pre-trained model, allowing for better handling of domain-related tasks. How to integrate external knowledge into the model becomes a key point, which usually involves two challenges:
-
Heterogeneous Embedding Space: The word embeddings of the text and the entity embeddings of the knowledge base are usually obtained through different methods, resulting in inconsistent vector spaces;
-
Knowledge Noise: Excessive knowledge fusion may cause the original sentence to deviate from its correct meaning, leading to diminishing returns.
Okay, after understanding the general idea, let’s analyze the specific implementation approach. The overall framework of the model is shown in the figure below, which mainly includes four sub-modules: knowledge layer, embedding layer, seeing layer, and mask-transformer. For a given input  , the knowledge layer first injects relevant triples from a KG, transforming the original sentence into a knowledge-rich sentence tree. The sentence tree is then simultaneously fed into the embedding layer and seeing layer to generate a token-level embedding representation and a visible matrix; finally, the output for downstream tasks is obtained through the mask-transformer layer.
, the knowledge layer first injects relevant triples from a KG, transforming the original sentence into a knowledge-rich sentence tree. The sentence tree is then simultaneously fed into the embedding layer and seeing layer to generate a token-level embedding representation and a visible matrix; finally, the output for downstream tasks is obtained through the mask-transformer layer.
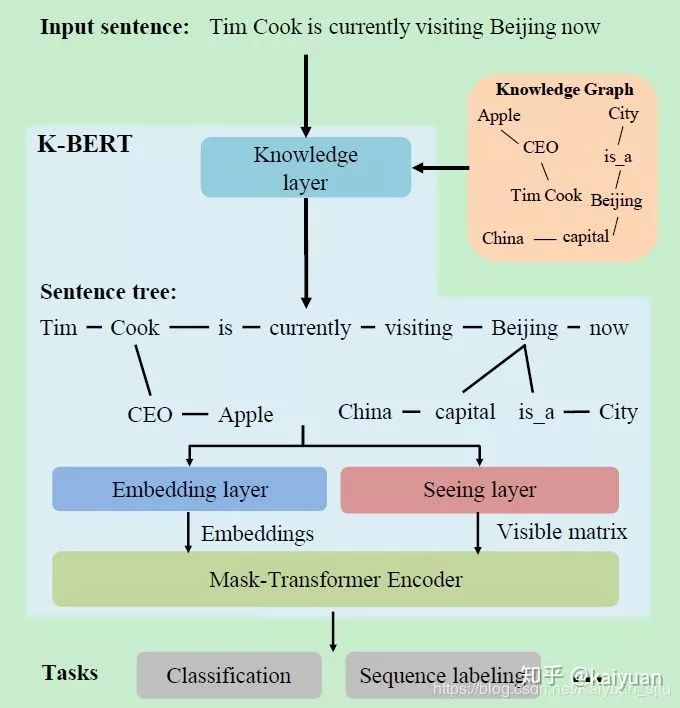
Knowledge Layer
The input of this layer is the original sentence  , and the output is the sentence tree infused with KG information
, and the output is the sentence tree infused with KG information  achieved through two steps:
achieved through two steps:
-
K-Query selects all entities involved in the input sentence and queries their corresponding triples in the KG
 ;
; -
K-Inject injects the queried triples into the sentence
 by inserting the triples from
by inserting the triples from  into their corresponding positions, generating a sentence tree t.
into their corresponding positions, generating a sentence tree t.
Embedding Layer
The input format of K-BERT is the same as that of the original BERT, requiring token embedding, position embedding, and segment embedding. The difference is that K-BERT’s input is a sentence tree, so the problem becomes converting the sentence tree into a serialized sentence while retaining structured information.
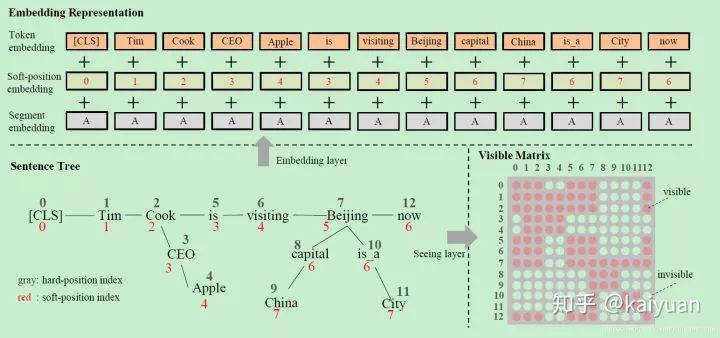
Token embedding
The serialization of the sentence tree involves a simple rearrangement strategy: tokens in branches are inserted after their corresponding nodes, while subsequent tokens are moved backward. For example, for the sentence tree in the figure above, after rearrangement, it becomes Tim Cook CEO Apple is visiting Beijing capital China is a City now. Indeed, it looks illogical, but fortunately, tricks can be applied later to resolve this.
Soft-position embedding
Clearly, the rearranged sentence is meaningless, so position embedding is utilized to restore structural information. Using the above figure as an example, after rearrangement, CEO and Apple are inserted between Cook and is, but is should actually follow Cook. Thus, we simply set the position number of is to 3. The segment embedding part remains the same as BERT.
Seeing Layer
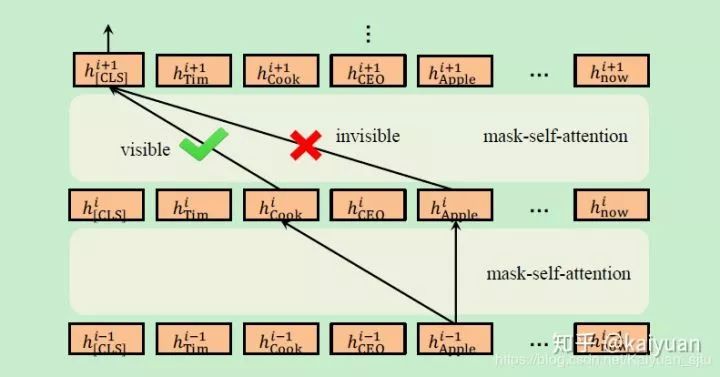
The author believes that the mask matrix of the Seeing layer is key to K-BERT’s effectiveness, mainly addressing the previously mentioned Knowledge Noise issue. In the example, China only modifies Beijing and has no relation to Apple, so tokens like this should not influence each other. Therefore, a visible matrix is defined to determine whether words in the sentence affect each other.

Mask-Transformer
The Transformer Encoder in BERT cannot accept the visible matrix as input, so some modifications are needed. The Mask-Transformer is a stack of masked self-attention layers,

Code Heregithub.com
3. Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations (2019)
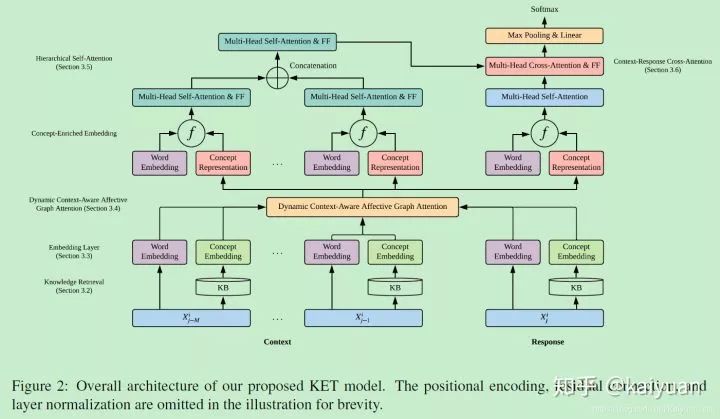
This article applies external common sense knowledge to a specific task, emotion recognition in dialogues, proposing a Knowledge-Enriched Transformer (KET) framework as shown in the figure below. There will be no complex introduction to the background knowledge of Transformer, emotion recognition, etc.; we will mainly focus on how external knowledge is applied.
Task Overview
First, let’s look at the task. Given a dialogue dataset, the data format is  ,
,  represents the
represents the  group dialogue’s
group dialogue’s  sentence representation, and the goal is to maximize
sentence representation, and the goal is to maximize 

Knowledge Retrieval
The model uses the common sense knowledge base ConceptNet and emotion lexicon NEC_VAD as sources of external knowledge. For each non-stopword token in the dialogue, knowledge graph g(t) containing its direct neighbors is retrieved from ConceptNet, and for each g(t), stopwords, out-of-vocabulary words, and concepts with confidence scores below 1 are removed. After these operations, for each token, a list of tuples is obtained:

Embedding Layer
This consists of common word embedding plus position embedding.
Dynamic Context-Aware Affective Graph Attention
This name is quite a mouthful… Dynamic context-aware affective graph attention aims to calculate the contextual representation of each token after incorporating knowledge  where
where  represents concept embedding, and
represents concept embedding, and  represents its corresponding attention weight
represents its corresponding attention weight 
The most important part here is the computation of  . In this model, it is assumed that concepts that are more contextually relevant and have stronger emotional intensity are more important and thus have higher weights. How to measure this? Two factors are proposed: relevance factor and emotion factor
. In this model, it is assumed that concepts that are more contextually relevant and have stronger emotional intensity are more important and thus have higher weights. How to measure this? Two factors are proposed: relevance factor and emotion factor
-
Relevance Factor: Measures the degree of correlation between
 and the conversational context.
and the conversational context.
 is the cosine similarity,
is the cosine similarity,  represents the context representation of the
represents the context representation of the  group dialogue, as there may be multiple sentences in a group dialogue, it is averaged over all sentence vectors
group dialogue, as there may be multiple sentences in a group dialogue, it is averaged over all sentence vectors 
-
Emotion Factor: Measures the emotional intensity of


Considering the above two factors, we can obtain the expression for  .
.
The context representation infused with knowledge can be obtained through a linear transformation 
Hierarchical Self-Attention
A hierarchical self-attention mechanism is proposed to utilize the structural representation of dialogues and learn the vector representation of contextual utterances.
-
In the first step, for the utterance
 , it can be represented as:
, it can be represented as: 


-
In the second step, utilize all dialogues to learn contextual representations


Context-Response Cross-Attention
Finally, predictions are made using the context representation infused with external knowledge.
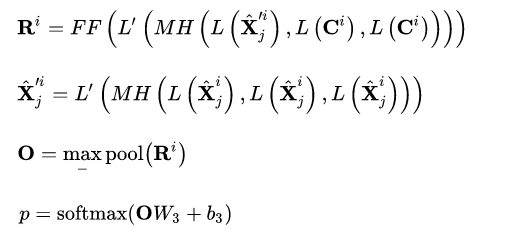
zhongpeixiang/KETgithub.com
————————————————————————————————————————————————————————————————————————————
After reading, do you find that the techniques used by experts to integrate knowledge into models are varied? However, if you look closely, you will see that everyone shares a common key point: **ATTENTION**. Haha, it feels like we’re back to attention is all you need. The next article will also introduce knowledge integration into models, but the focus will be on analysis rather than model introduction~
That’s all~
2019.11.6
This article is authorized by the author for original publication on the AINLP public platform. Click ‘Read the original’ to go directly to the original link. Contributions are welcome, covering AI and NLP.
Recommended Reading
BERT Source Code Analysis PART I
BERT Source Code Analysis PART II
BERT Source Code Analysis PART III
New NLP Models on the Shoulders of BERT (PART I)
New NLP Models on the Shoulders of BERT (PART II)
New NLP Models on the Shoulders of BERT (PART III)
Nvidia League Player: Come on, compete until the end of time
About AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include text summarization, intelligent Q&A, chatbots, machine translation, automatic generation, knowledge graphs, pre-trained models, recommendation systems, computational advertising, recruitment information, and job experience sharing. Welcome to follow! To join the technical exchange group, please add AINLP’s WeChat (id: AINLP2), and note your work/research direction + purpose of joining the group.
