
Language Life Research
Guest of This Issue

Yuan Yulin
Professor at the University of Macau, with main research interests in theoretical linguistics and Chinese linguistics.
Thinking About Language Design Principles and Operational Mechanisms Under Human Habitat Constraints
Yuan Yulin
(University of Macau, Department of Chinese Language and Literature, Macau 999078; Peking University, Department of Chinese/Center for Chinese Linguistics Research/Key Laboratory of Computational Linguistics, Ministry of Education, Beijing 100871)
Abstract The article reviews the 13 design features of human language proposed by Hockett, focusing on the discreteness of linguistic symbols and the duality of patterning. From the perspective of natural language processing, discreteness creates a semantic gap between the form and meaning of linguistic symbols, necessitating the vectorization of natural language words into continuous numerical values for computation, the results of which can be linguistically interpreted. Due to the similarity in duality of patterning between language systems and biological systems, some models from natural language processing can be applied in the field of biomolecular research. According to Tomasello’s theory on the origins of human communication and the cooperative psychological platform, any illusion that language itself has a complex and self-sufficient deep structure is unrealistic. Linguists should consider language under the constraints of human habitat (i.e., the realities of human evolution and survival) to gain a more practical understanding of the design principles and operational mechanisms of language, thereby opening up a more humanistic approach to linguistic research.
Keywords Human habitat; design features of language; discreteness; duality of patterning; cooperative psychological platform
1. Introduction: Language Research Under the Constraints of Human Habitat
The first hurdle faced by language research is the proposal of questions and the choice of methods, which often depend on the researcher’s understanding of fundamental issues regarding the structure and function of language, its origins, and evolution. To examine the rationality of our humanistic approach to grammatical research, this article first introduces and comments on the 13 design features of human language proposed by Hockett (1960), then discusses three understandings of the discreteness of linguistic symbols and their respective emphases, and introduces how to use “word embedding” models in the field of natural language processing to vectorize discrete linguistic symbols into continuous numerical values, as well as the applications and effects of such word vectors in related computational tasks. Next, it discusses the similarities in duality of patterning between language systems and biological systems, especially the application and effects of natural language processing algorithms and models in the field of biomolecular research due to this duality. Finally, it introduces and comments on Tomasello’s (2010) theory regarding the social origins of human communication and the cooperative psychological platform upon which language is based, advocating that linguists should consider language within the realities of human evolution and survival (referred to as “habitat”) to think about the design principles and operational mechanisms of language, thus gaining a more practical understanding of the structural methods and functional utility of language, and opening up a more humanistic approach to linguistic research. In other words, language research is constrained by human habitat; language theory can only dance with the shackles of real linguistic habitat, discarding any unrealistic attempts to construct a palace for language (Yuan Yulin 2019).
2. Design Features of the Human Language System
Hockett (1960: 90-92) first proposed that human language has 13 design features, including: ①
(1) Vocal-Auditory Channel②. This distinguishes it from sign language gestures, bee dances, and courtship rituals of fish; its advantage is that it frees hands and feet for other activities while humans converse.
(2) Broadcast Transmission and Directional Reception. A language signal can be heard by any auditory system within a certain range, and the sound source can be localized using both ears.
(3) Rapid Fading. This means that language signals do not linger for the convenience of the listener, unlike animal tracks and scents that remain for a while. Thus, humans invented writing, a very recent cultural evolution.
Clearly, points (2) and (3) are determined by the physical properties of sound and are inevitable results of (1).
(4) Interchangeability. Speakers can produce any language message they understand. However, the courtship gestures of male and female fish are different, and neither can use the other’s appropriate gestures. Additionally, during communication between human mothers and infants, neither party is suited to emit the other’s unique signals or respond typically.
(5) Total Feedback. When humans speak, they pay attention to everything related to what they are saying; however, male fish do not observe their own coloration, even though it primarily stimulates female fish. Feedback is crucial as it enables the internalization of communicative behavior, which constitutes a significant part of thought.
Clearly, points (4) and (5) are clarified through comparison with other communication systems.
(6) Specialization. This refers to the fact that bodily efforts and the production of speech sound waves serve merely as signals. A dog pants and sticks out its tongue to cool down and maintain an appropriate body temperature, but this is merely a physiological action. While panting and sticking out its tongue, it may occasionally produce sounds to let other dogs (or humans) know where it is and how it feels; however, this method of information transmission is not specialized.
(7) Semanticity. This refers to the fact that in language, a message triggers specific results because the components of the message (like words) have a relatively fixed connection to recurring features or situations in our surrounding world. For example, the English word “salt” refers to salt, not sugar or pepper. Based on this, the dog’s panting behavior does not possess semanticity; it is not a signal indicating that the dog is hot, but merely a part of the dog being hot (a manifestation). Conversely, the calls of gibbons possess semanticity. Gibbons have a call indicating danger, which is no less broad and vague than shouting “fire!”
(8) Arbitrariness. In a semantic communication system, the meaningful components of messages can be arbitrary or non-arbitrary; however, in language, this connection is arbitrary. For example, the English word “salt” does not mean salt, and “dog” does not mean dog; “whale” is small in form but indicates a large object, while “microorganism” is larger in form but indicates a small object. In contrast, a picture looks like the thing it depicts. If a bee wants to report that it has found a nectar source nearby, it dances quickly; if far away, it dances slowly. The design feature of “arbitrariness” has its disadvantages, but it also has great advantages: it imposes no restrictions on the content to be communicated.
(9) Discreteness. Although human vocal organs can produce many different sounds, any language uses only a small subset of those sounds; moreover, the differences between these different sounds are functionally absolute (unrestricted). For instance, the English words “pin” and “bin” differ only in voicing for the ear. If a speaker mispronounces “pin” and moves towards the pronunciation of “bin,” producing noise while saying “pin” (or “bin”), the listener can likely still understand what word the speaker meant based on context. This fundamental discreteness feature of language, which constitutes the basic units of signals, differs from the use of sound effects indicated by vocalization, which exists on a practically continuous scale. For example, when expressing anger, people raise their voices, while when expressing trust, they lower their voices.
(10) Displacement. Clearly, humans are almost unique in this respect: they can talk about things that are far removed in space or time (or both) from the current moment and place of conversation. This characteristic of displacement is undoubtedly lacking in the signaling behavior of our close relatives, although it does appear in the dance signaling behavior of bees.
(11) Productivity. This refers to the ability of language to produce utterances that have never been spoken or heard before and can be understood by others who use that language. If a gibbon emits any call, it is merely one of a limited set of familiar calls. The gibbon’s call system is closed. However, language is open or productive; people can create new utterances by assembling familiar segments from old utterances according to familiar arrangement models.
(12) Traditional Transmission. Humans are genetically endowed with the capacity to acquire language, and there may be a strong intrinsic drive to do so; however, many specific conventions of any language are transmitted from generation to generation through teaching and learning. The role and extent of this “traditional transmission” in the calling systems of gibbons or other mammals remain uncertain; although in some cases, the consistency of vocalizations among animals of the same species (regardless of their location in the world) can largely be attributed to their genes.
(13) Duality of Patterning.③ The meaningful components in any language, the so-called “words” in everyday language or “morphemes” as termed by linguists, are vast in number. However, they are represented by a relatively small set of distinctive phonemes arranged in a limited number of ways, and these phonemes themselves are not meaningful. This duality can be illustrated with the English words “tack,” “cat,” and “act”: although they differ in overall meaning, they are all composed of three identical basic phonemes that do not convey meaning, arranged differently. In fact, this duality is what is commonly referred to as “duality of segmentation.”
Hockett (1960: 92) pointed out that not all of these 13 design features are unrelated; some are interdependent. In particular, a system cannot be arbitrary or non-arbitrary unless it is semantic (i.e., only a semantic communication system can discuss whether the relationship between form and meaning is arbitrary or non-arbitrary—Yuan’s note); similarly, a system cannot possess duality of patterning unless it is semantic (i.e., only a semantic communication system can discuss whether the form represents meaning in a duality—Yuan’s note). Moreover, this enumeration does not attempt to encompass all the discovered features of communication behaviors across different species but only includes those that are evidently important for language.
According to Hockett (1960: 93), reptiles, amphibians, vertebrates, and chordates below land mammals do not use vocal-auditory communication and lack the 13 design features mentioned above. Land mammals like elephants, which exhibit social behaviors and play, possess features (1) to (5), namely, vocal-auditory channel, rapid fading, total feedback, interchangeability, and broadcast transmission and directional reception. Primates such as monkeys, which are omnivorous, have movable facial muscles, possess binocular vision and dexterous hands, and exhibit hand-eye coordination, possess features (1) to (5) and also (6) to (8), namely, specialization, semanticity, and arbitrariness. Although ancient apes could walk bipedally, they were not upright and occasionally used tools; their communication systems possessed features (1) to (8), and also two additional features, namely, (9) discreteness and (12) traditional transmission. In contrast, humans, who can manufacture and carry tools, possess a throat and soft palate, have a sense of humor, vocal qualities, and music, and their communication systems possess features (1) to (9) and (12), and also three additional features, namely, (10) displacement, (11) productivity, and (13) duality of patterning.
Hockett (1960: 92) pointed out that nine of these features have already appeared in the vocal-auditory communication of primitive ancient apes; and these nine features can be verified in the communication systems of modern gibbons and humans. For instance, gibbons have about a dozen different calls, each suitable response targeting a repeatedly occurring, biologically significant situational type: discovering food, detecting predators, sexual interest, needing maternal care, etc. Thus, exploring the origins of human language involves determining how this communication system developed the four additional features (displacement, productivity, fully developed traditional transmission, and eventually developed duality of patterning). This addresses the author’s note beneath the article title: humans are the only animals capable of using abstract symbols for communication. However, this ability shares many features with other animals’ communication systems and is indeed derived from these comparatively primitive systems.
① The translation of these design feature names refers to Wang Shiyuan (2017: 9), but is not entirely the same. Our explanations, examples, and clarifications of these features include our own insights. If quoting, please verify the original text.
② Vocal-auditory channel can be translated as “vocal-auditory channel” or “vocal-auditory communication channel”.
③ Wang Shiyuan (2017: 9) translates it as “duality of hierarchy,” but it can also be translated as “dual structure” or “the duality of structure.”
3. Discreteness Feature of Linguistic Symbols and Vector Representation
From the literature, there are three different understandings of the discreteness of linguistic symbols. The first understanding is the one mentioned above, Hockett (1960) stated that the units constituting signals (i.e., phonemes) have absolute distinctive functions (unrestricted). For example, in languages like English, voicing of consonants has a contrasting function (able to distinguish the phonetic form of words, thus distinguishing their meanings), but whether aspirated or unaspirated consonants does not have a contrasting function; while in Mandarin Chinese, voicing of consonants does not have a contrasting function, but whether aspirated or unaspirated consonants does have a contrasting function. In other words, we can only classify a phoneme heard in speech into a limited set of phonemes that have distinctive value in that language; different phonemes lack continuity, being either one or the other. Thus, when you hear a blurred pronunciation of a word that is between “pin” and “bin,” you must determine whether it is “pin” or “bin.” Clearly, Hockett’s (1960) notion of the discreteness design feature of language primarily focuses on the non-continuity in terms of the sound form and categories of language. Specifically, it indicates that the distinctions between the basic signal units (phonemes or phonetic units) in language are absolute and categorical, not continuous. For instance, modern experimental phonetics has proven that the differences between different vowels primarily manifest in the second formant; and for actual phonemes within a certain range of the second formant, native listeners will either hear [o], or [u], or something else; and will not hear a certain ambiguous vowel that lies between [o] and [u], and so on. Extending this, for a segment of speech, native listeners will hear either word A (like “pin”), or word B (like “bin”), or something else, and will not hear some ambiguous thing that lies between word A and word B.
The second understanding refers to the fact that continuous speech can be segmented into analysis units of different sizes. For example, Harris (1954: 158) pointed out that the primary distribution fact is that any speech flow can be divided (cut) into parts, allowing us to find certain occurrence patterns of a part relative to other parts within a specific speech flow. These parts are discrete components that have a certain distribution in a specific speech flow (a set of relative positions); and each segment of speech is a specific combination of components. His so-called “language components” include phonemes, morphemes, words, phrases, and even sentences. Similarly, the Chinese linguistics community generally defines the discreteness feature of the language symbol system from the perspective that language structure can be segmented into different-sized language units layer by layer. For instance, Feng Zhiwei (2007: 41) described discreteness as follows: continuous speech flow is composed of many discrete units, including discrete units in aggregation classes on the combination axis such as “paragraph-sentence-phrase-word-morpheme-syllable-phoneme”.
The third understanding refers to an undefined usage in the literature of natural language processing, meaning that the form clues of linguistic symbols are disconnected, i.e., morphemes, words, and other language units have a semantic relationship that is usually not represented in form. For example, even with synonyms like “mobile phone” and “cell phone,” unless you already know they refer to the same thing, you cannot understand their semantic relationship from the forms of these two words alone. As a result, morphemes and words become isolated (independent, lacking continuity) units. This reflects the symbolic characteristics of language symbols. Clearly, this discreteness feature of linguistic symbols can be inferred from the arbitrariness of language symbols. The former emphasizes the arbitrariness of the combination of sound and meaning of individual symbols (arbitrariness, also translated as “arbitrariness”), while the latter emphasizes the opacity of semantic relationships between symbols in formal representation. This explains why Saussure’s “Course in General Linguistics” does not specifically discuss the discreteness feature of linguistic symbols. Because the arbitrariness of the sound-meaning combination of linguistic symbols dictates the opacity of the semantic relationships between linguistic symbols in formal representation. From the perspective of data science, natural language, such as text, is a form of symbolic data, ④ which only has psychological reality in the minds of people within a certain linguistic community. Because, as Saussure (1981: 4) pointed out, the sound-meaning combination of linguistic symbols is logically arbitrary; there is no necessary reason for what kind of meaning is expressed by what kind of sound. Thus, two linguistic symbols (e.g., morphemes or words) may have a relationship in meaning (e.g., synonymy, antonymy, hyponymy, entailment, etc.), but this is not necessarily reflected in form. This is the so-called discreteness feature of natural language symbols in the literature of natural language processing, and its discontinuity in numerical representation. ⑤
In fact, as a characterization of the mathematical properties of data, discreteness is relative to continuity. For example, in a class of 120 students taking an exam, if scored on a 100-point scale, students’ scores can be plotted to form a curve, ⑥ which represents a continuous score as a numerical continuous attribute. If changed to a 5-point scale, or a grading system like “excellent, good, pass, fail,” it becomes an ordered discrete attribute. Based on this, the three understandings of the discreteness of linguistic symbols are all reasonable and reveal a facet of the non-continuity of linguistic symbols, just with different emphases.
From the perspective of natural language processing, the result of the discreteness feature of linguistic symbols is that there exists a significant gap between the form and meaning of linguistic symbols. This is known as the phenomenon of semantic gap, ⑦ meaning that there is a significant distance between the information extracted from the form of symbols (sound or text) and the meaning represented by the symbols. This semantic gap poses significant challenges for the textual representation and computational processing of natural language. For the convenience of machine processing, it is usually necessary to convert the symbolic data of natural language text into numerical data. Since the basic unit of text is words, the issue of representing words for numerical computation has become a hot topic in the field of natural language processing in recent years; and it has formed a “word embedding” technique that represents text in real-valued vector form. This technique is based on Harris’s (1954) idea that “words with similar meanings have similar distributions (i.e., appear in similar contexts)” and uses neural networks to learn and discover the probabilities of two or more words occurring together from text corpora, thereby clustering semantically similar words together in vector space and assigning them their respective independent but similar vectors. In 2013, a Google team released the word2vec toolkit for extracting word vectors, with the goal of understanding the probabilities of two or more words occurring together, thereby clustering words with similar meanings together in vector space. Word2vec is essentially a shallow neural network with only two layers, which primarily includes two language models: Continuous Bag of Words (CBOW) model and Skip-Gram model. The former predicts the current word based on context, using surrounding words as input to produce words as output; the latter takes words as input, understands their meanings, and assigns them to contexts to predict surrounding words. For instance, the former is like playing a fill-in-the-blank game, while the latter is like playing a word association game. However, both share the commonality of predicting words based on the local context of nearby words. Like other deep learning models, word2vec can learn from past data and previously occurring words; and based on past events and contexts, accurately guess the meaning of a word, just as we understand language. For example, when we hear or see the words “boy” and “man” as well as “girl” and “woman,” if we can understand their meanings, we can establish connections between them. Similarly, word2vec can form such connections and generate vectors for these words. These words are tightly clustered in the same cluster to ensure that machines understand that these words mean similar things. Once given a corpus, word2vec will produce a vocabulary; each word has its own vector. This is known as neural word embedding. Simply put, this neural word embedding is a representation of a word written in numbers. ⑧
Since these word vectors are continuous numerical values, they can undergo addition and subtraction operations. Moreover, the results of these operations can be linguistically interpreted, thus possessing linguistic significance. For instance, the distance between the word vectors for “Man” and “Woman” is roughly the same as that between “King” and “Queen,” and the direction is also the same. As a result, using the vector for the word “king” (denoted as: Wking) minus the vector for “man” (denoted as: Wman), plus the vector for “woman” (denoted as: Wwoman), the closest resultant word is “queen.” In other words, in the word vector space, relationships such as Wking – Wman + Wwoman ≈ Wqueen, Wking – Wman ≈ Wqueen – Wwoman hold true. Similar relationships also apply to the base and superlative forms of adjectives, such as: Wbiggest – Wbig + Wsmall ≈ Wsmallest, Wbiggest – Wbig ≈ Wsmallest – Wsmall, etc.⑨If in the equation Wbiggest – Wbig ≈ Wsmallest – Wsmall, the values on both sides of the equation roughly represent concepts or meanings like “English superlative adjectives,” then in the equation WParis – WFrance ≈ WRome – WItaly, the values on both sides of the equation roughly represent concepts or meanings like “capital.” This outcome is something linguists did not anticipate.
④ For the distinction between signal data and symbolic data, refer to Zhao Jun et al. (2018: 58).
⑤ It is difficult to represent morphemes, words, and other linguistic symbols with continuous numerical values; even using ID numbers (labels) from a word list or even one-hot vectors cannot reflect the semantic connections between related words.
⑥ This curve is generally high in the middle and low at both ends, reflecting the normal distribution of scores: there are few people in the high and low score segments, while many are in the middle segment.
⑦ For semantic gaps, refer to Zhao Jun et al. (2018: 58).
⑧ The above references Bokka et al. (2019) §1. 5, Chinese translation pages 13-16. Of course, our understanding and elaboration have been added in between.
⑨ Refer to Goldberg (2017), Chinese translation page 122; see Mikolov et al. (2013) for details.
4. The Similar Duality of Patterning and Coding Models Between Language and Biology
Regarding the dual-layer characteristics of language structure, Yuan Yulin (1998) summarized based on previous research and related literature. Now, a brief summary is as follows.
Language is a hierarchical system that produces an infinite number of forms to represent the infinite meanings required for human communication through the graded combination of phoneme layers belonging to pure forms and the graded combination of symbol layers belonging to sound-meaning combinations. This is the principle of dual segmentation in human language information coding. Duality refers to the fact that language consists of two major layers: phonemes and symbols; segmentation means that smaller units can form larger units on both the phoneme and symbol layers. It can be represented as follows:
Phoneme → Syllable → Syllable Cluster & Morpheme → Word → Phrase → Sentence
The dual segmentation coding principle makes language an extremely economical and efficient information system, representing infinite meanings through the multi-level combination of about 50 basic phonetic elements.
Yuan Yulin (1998) also reviewed and envisioned the similarities between biological genetic information coding and human language information coding in dual segmentation.
Biological organisms are also a hierarchical system, which can be represented as:
Cell → Tissue → Organ → System
More interesting than hierarchy is that if we consider the traits of biological organisms as information or meaning, and the biochemical basis that enables the expression of these traits as a signal or symbol, we can find that the coding of biological information (i.e., the expression or realization relationship between biological traits and their biochemical basis) clearly follows the principle of dual segmentation. For example, the 100,000 biological traits of the human body are determined by 100,000 proteins. Interestingly, these 100,000 proteins that determine human traits are formed by only 20 amino acids arranged in different sequences. Several to hundreds of amino acids connect in a certain order to form long and short polypeptide chains. These polypeptide chains can also twist and fold, forming the higher structure of proteins.
In general, amino acids are organic compounds containing both amino and carboxyl groups in a molecule and are the basic units of proteins. Amine is a compound of nitrogen and hydrogen, with a chemical formula of NH3; an amino group is a univalent radical formed by the loss of one hydrogen atom from the amine molecule (−NH2). The carboxyl group is a univalent radical composed of a carbonyl and hydroxyl group (−COOH); the carbonyl group consists of a divalent radical made of carbon and oxygen (=C=O), while the hydroxyl group consists of a univalent radical made of hydrogen and oxygen (−OH). In other words, thousands of proteins are formed through the graded combination of hydrogen, oxygen, carbon, and nitrogen at different levels, providing sufficient biochemical materials to realize or express thousands of biological traits. This method of biological information coding can be illustrated as follows:

If we draw an analogy between biochemical substances and language forms, then here, atoms correspond to phonemes or phonetic units, and molecules correspond to syllables; they are all formed using a limited set of basic forms through graded combinations to create infinitely complex forms for the realization or expression of infinite information.
Currently, biologists have discovered that the nucleotides that make up the large DNA molecules consist of sugars, phosphates, and bases, which have fundamentally the same components; among them, the sugar molecule is deoxyribose, and the bases include four types: adenine (A), cytosine (C), guanine (G), and thymine (T). Therefore, the differences in different nucleotide chains (i.e., DNA) lie in the different arrangements of the bases. It is this order of bases in the DNA molecule that determines the sequence of amino acids that make up protein molecules. In other words, genetic information is encoded by four bases in a specific order. This order of bases on DNA that encodes the arrangement of amino acids in proteins is known as the genetic code.
In the diverse biological world, why can so much information be contained and represented by only these four bases, creating so many organisms? One important point is the adoption of the structural principle of dual segmentation: it does not use a single base to directly represent an amino acid, but rather uses a triplet of three bases to represent an amino acid; ⑩ it does not use a single amino acid molecule to realize a biological trait, but rather uses multiple amino acids to form a protein molecule to realize a biological trait. With this doubling structure principle, combined with the fact that a DNA molecule can have billions of base pairs, the issue of biological diversity becomes understandable.
Since biomolecules exhibit the following parallelism in functional structure with natural language:

It naturally leads one to wonder: can the effective algorithms that process natural language be applied to the field of biomolecules? After all, there are 31.6 base pairs in DNA, and the start and stop of triplets can sometimes be hard to determine. In other words, there is ambiguity throughout the DNA chain. For example: ……GAACATGATTCATAGAGTACGG…… This TGA appears to be a stop codon, while the overlapping GAT appears to be aspartic acid. Therefore, all possible arrangements must be counted. Among them, the subsequences of length K in the counted DNA (or RNA) are referred to as K-mers. The frequency information of these subsequences can be applied to various tasks related to genes, such as genome mismatch detection, pathogenic gene detection, repeat sequence detection, recombination point detection, protein production rate control, gene mutation or polymorphism identification, human mitochondrial haplogroup classification, species classification, species richness estimation, etc. Although K = 3 is a biologically significant value since every three nucleotides encode one amino acid, it can also lead to the loss of specific information. For instance, ……ATGTGTGTGTGTGTGTGTG…… is merely repeating. Moreover, one codon corresponds to at most one amino acid, which is merely the “letter” of a protein. To understand the function of a gene sequence, it is clear that K needs to take a larger value. In other words, different K values have different roles.
Asgari & Mofrad (2015) were the first to apply the ideas of Word2Vec to the field of protein classification, proposing the concepts of Protein Vector (ProtVec) and Gene Vector (GeneVec). This approach is based on the hypothesis that “structure determines function” in proteins: proteins are formed by the arrangement of amino acids, which then acquire specific spatial structures through intermolecular and intramolecular forces, thereby exerting their functions. Specifically, the amino acid sequence forms the primary structure of the protein, while hydrogen bonds lead to folding, forming the secondary structure of the protein; multiple secondary structures arranged in space form the tertiary structure of the protein (a single peptide chain), and interactions between multiple peptide chains form the quaternary structure of the protein molecule. Thus, when the arrangement of amino acids is similar, the spatial structure of the protein will also be similar, and ultimately the functions will be similar. If this theory holds, protein classification can refer to the methods used in natural language processing to compare text similarity to find models. Asgari & Mofrad (2015) thus converted segments of amino acids into vectors, i.e., ProtVec. To validate the meaningfulness of ProtVec, they used the sum of amino acid vectors to represent proteins and employed a binary classification model, the Support Vector Machine (SVM), to classify proteins of similar lengths. The results achieved an average accuracy of over 93% among 7020 protein families. This shows that ProtVec can effectively distinguish different types of proteins. Particularly for “disordered proteins” where the arrangement of amino acids remains unchanged but lacks stable three-dimensional structures, ProtVec performs well in classification. This may be because ProtVec focuses on the information contained in the first and second structures of proteins. The Gene Vector (GeneVec) has a similar usage hypothesis to ProtVec, and currently, they are primarily used for: protein classification, protein structure visualization, protein spatial structure prediction, protein reaction mechanism analysis, protein function prediction, motif extraction, functional gene detection, etc.
It is worth mentioning that natural language processing models are continually evolving, and their processing effects are improving. In 2018, a Google team developed the pre-trained language model BERT (Bidirectional Encoder Representation from Transformers) based on the Transformer architecture, achieving the best results at that time on various natural language processing tasks. The application of BERT in various natural language processing tasks has become increasingly widespread, leading some to proclaim the slogan “Everything Can Be BERT.” Consequently, some have attempted to introduce the BERT model into the biomolecular field for molecular function prediction. However, so far, it has not shown outstanding performance in terms of effectiveness and rationality.
In summary, based on the certain similarities in information coding between natural language and biomolecules, some ideas and models from natural language processing can be applied to biomolecular research. However, many neural network models are designed for the structural characteristics of natural language data, and their applicability in research fields such as biomolecules still requires further study. Of course, we look forward to the day when someone discovers (or invents) a universal model that can be applied to both human language and biological coding.
⑪
⑩ Therefore, this triplet is known as a “codon.”
⑪ The above introduction regarding the application of concepts such as “word vectors” in natural language processing to biomolecules is based on Bai Qiaoling (2020).
5. The Origins of Human Language Communication and the Psychological Platform It Relies On
At least on the surface, using vocal language for communication is a significant difference between humans and animals. Therefore, conversely, observing and studying language can enable humans to better understand their nature. Pinker (2007) pointed out:
Language is closely intertwined with human life. We not only use language to convey information and persuade others, but we also use it to threaten and entice others; of course, language can also be used to swear and curse. Language reflects our understanding of reality; moreover, it is the vivid impression we leave in the minds of others, a bond that closely connects people. I hope you can also believe this fact: language is a window to humanity. (Preface, page II)
Carefully observing our language—people’s conversations, jokes, curses, legal disputes, and names given to infants—can provide us with a deeper insight into the question of “who we really are.” (Preface, page I)
Then, how did this natural language, this means of human communication, arise? Or rather, what kind of mental or psychological basis is it built upon? In this regard, Tomasello (2010) proposed the following insightful hypotheses regarding the evolution of language:
The initial mode of human communication was gesturing (i.e., natural hand gestures—pointing), which is a primitive form of communication unique to humans. This new communication mode, facilitated by social cognition and social motivation, formed a psychological platform. The various conventional communication modes (a total of 6000) are based on this platform. Pointing is the crucial transitional point in the evolutionary history of human communication, reflecting the unique forms of social cognition and social motivation that are essential for the later development of conventional language. (Chinese translation, page 2. The quoted text contains minor modifications from the original translation; if quoting, please verify the original text.)
Why could this seemingly simple act of pointing become the origin and hallmark of human communication, and serve as the psychological platform upon which conventional spoken language is built? Tomasello (2010) insightfully uncovers a secret that people often overlook, namely, that human pointing has a prosocial function:
From an evolutionary perspective, the seemingly trivial act of pointing has an extraordinary aspect: its prosocial motivation. When I point to that bicycle next to the library that seems to belong to your ex-boyfriend, I am alerting you: he might be inside, do you want to go in? This is because I believe this might be something you want to know. In the animal kingdom, such effective communication is quite rare; even our close relatives, the primates, do not behave this way… Therefore, when a young chimpanzee whimpers while searching for its mother, nearby other chimpanzees will also know. However, even if they know where its mother is, they will not specifically extend their forelimbs to point or gesture. (Chinese translation, page 4)
The motivation for human communication is fundamentally cooperative; we not only inform others of helpful matters, but one of the main methods we use when we have requests is to let others know what I desire and expect them to assist proactively. Therefore, if I want a glass of water, I can explicitly state that I want water (telling you what I want), and I also know that in most cases, your inclination to assist (which we both know) will effectively transform my act of informing into a fully developed request.
The essence of human communication is a cooperative endeavor, conducted in the most natural and smooth manner based on (1) a shared conceptual foundation and (2) a shared cooperative communication motivation. (Chinese translation, page 4)
In fact, it is this deeply rooted cooperative spirit and its tacit understanding between the communicators that cultivate a kind of intersubjectivity: our feelings, experiences, cognitions, and understandings of things in specific situations are not solely our own but are shared by our social groups. This forms the basis for our mutual communication and understanding. It is in this shared space of mutual resonance that we achieve interpersonal interaction and linguistic communication.⑫
Tomasello (2010) also attempts to reveal the mental and psychological conditions for human communication:
The common conceptual foundation includes shared attention, shared experiences, and the same cultural knowledge. This is an essential condition for human communication. (Chinese translation, pages 3-4)
Human cooperative behavior is predicated on shared intentionality; this activity must involve multiple subjects: everyone has common goals, common intentions, shared knowledge, and shared beliefs—and all are conducted in a context of cooperative motivation. (Chinese translation, page 5)
Regarding how human communication evolved from natural gestures to conventional language, Tomasello (2010) sketches the following grand outline:
Pointing is based on the natural tendency of humans to follow others’ gazes to look at objects, while pantomiming is based on humans’ spontaneous interpretation of others’ actions. This natural response made gestures the transitional point from the communication of apes to arbitrary language communication.
In the context of mutual assistance, participants share intentions and attention, and through natural gestures coordinate communication, the arbitrary language conventions will subsequently emerge. Conventional language (first in sign language form, then in spoken form) thus attaches to known gestures, replacing natural pointing with shared (and known to all) social learning experiences. This process is undoubtedly facilitated by the unique cultural learning and imitation skills of humans, allowing them to learn from others and their own states of mind in a uniquely advantageous manner. Similarly, through the evolutionary process, humans began to create and transmit complex language structures composed of different linguistic conventions, encoding complex information into different categories (types) for use in frequently occurring communication contexts.
This perspective on human communication and language can be said to overturn Chomsky’s assertions, as the most fundamental aspects of human communication arise in response to general cooperation and social interaction, while the pure linguistic aspects, including grammar, are culturally constructed and passed down through individual language communities over generations. (Chinese translation, pages 7-8)
The fundamental social intentions/motivations of human communication: sharing, informing, requesting. (Chinese translation, page 91)
Tomasello (2010) also proposed the following diagram based on cooperative language communication (Chinese translation, page 72):
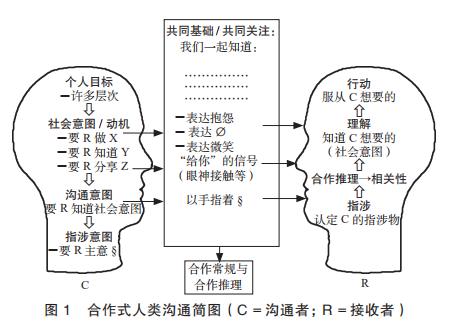
This is the reality of human language communication ecology; any illusion that language itself has a complex and self-sufficient deep structure is unrealistic. It should be noted that currently, we know very little about the working mechanisms of the human brain. We only know that there are significant differences in the number of neurons among different species. Reports indicate that the roundworm has 302 neurons, the fruit fly has 100,000 neurons, the mouse has 75 million neurons, the cat has 1 billion neurons, the chimpanzee has 670 million neurons, while humans have 86 billion neurons, with approximately 150 trillion connections between brain neurons. However, humans are perplexed about the workings of their own brains. Neuroscientists have yet to explain in detail how the electrical activity interactions between brain neurons translate into our thoughts, emotions, memories, and reasoning activities. In other words, the human neural system that supports language generation and understanding is very materialistic and mechanical; although the number of neurons is enormous, the modes of interaction between neurons only have two simple states: connection and disconnection. This is a rigid constraint of brain science on linguistic theory.
⑫ For further details, see Fultner (2012: 216).
6. Conclusion: Studying Language from the Perspective of Human Social Interaction and Cultural Practice
We believe that language has evolved over the last 200,000 years through the transformation of gestures, sounds, and other communication means; although vocal language has improved the efficiency of human communication, as much as two-thirds of semantics still relies on non-verbal signals such as body movements, eye expressions, and psychological tacit understanding during face-to-face conversations.⑬ Therefore, language is an imperfect “encoding-decoding” type of information system, inevitably relying on associative cooperative mechanisms such as “indicating-reasoning.” While we agree with Chomsky’s view that children are not born as blank slates but possess various innate cognitive structures and language abilities, we believe that in language use, the shared experiential conceptual structures of the communicators serve as the foundational cognitive resources for the functioning of cognitive structures and language abilities, playing a significant role in the composition of sentences and the interpretation of their meanings; moreover, there is extensive interaction and communication among various cognitive modules, and language faculties are not an independent cognitive system.
Inspired by the above thoughts, we conducted several case studies based on social interaction and cultural practices to interpret relevant phenomena in Chinese, English, Japanese, and Korean. Here are three cases.
Case 1: A syntactic and semantic study of proximity adverbs and related sentence patterns based on the principle of proximity psychology and optimism. See Yuan Yulin (2013) and Yuan Yulin, Zheng Renzheng (2015).
Case 2: A semantic interpretation study of “white” adverbs and related sentences based on the principle of labor compensation balance. See Yuan Yulin (2014a) and Park Min-eun, Yuan Yulin (2015).
Case 3: A cross-linguistic comparative study of the understanding of “doubt” verbs based on the psychology of suspicious benevolence. See Yuan Yulin (2014b) and Park Min-jun, Yuan Yulin (2016).
Through these case studies of semantic interpretation, we find that people’s understanding of the semantics of specific words and constructions is a process of interaction among syntax, vocabulary, semantics, pragmatics, and other knowledge planes; during which, social psychological principles such as “anti-normativity” and “suspicious benevolence” are also invoked. Clearly, this semantic interpretation is based on social interactive culture and practical experience.
⑬ The source was lost; this clarification and apology is hereby noted.
(References omitted; please refer to the original text if needed)
Compilation: Lu Linlin
Reviewers: Wang Biao, Yu Guilin
Today’s Editor: Mou Someone
