Hello everyone, I am Chen Ge! If you are a developer or an AI enthusiast, you might want to quickly extract answers from a large volume of documents without flipping through every page. Today, I will guide you on how to build a localized Retrieval-Augmented Generation (RAG) system to get precise answers directly from documents. By combining DeepSeek R1 and Ollama, you can easily achieve this goal without relying on cloud services, avoiding the hassle of cloud API latency. Complete code can be found at the end.
Understanding DeepSeek R1
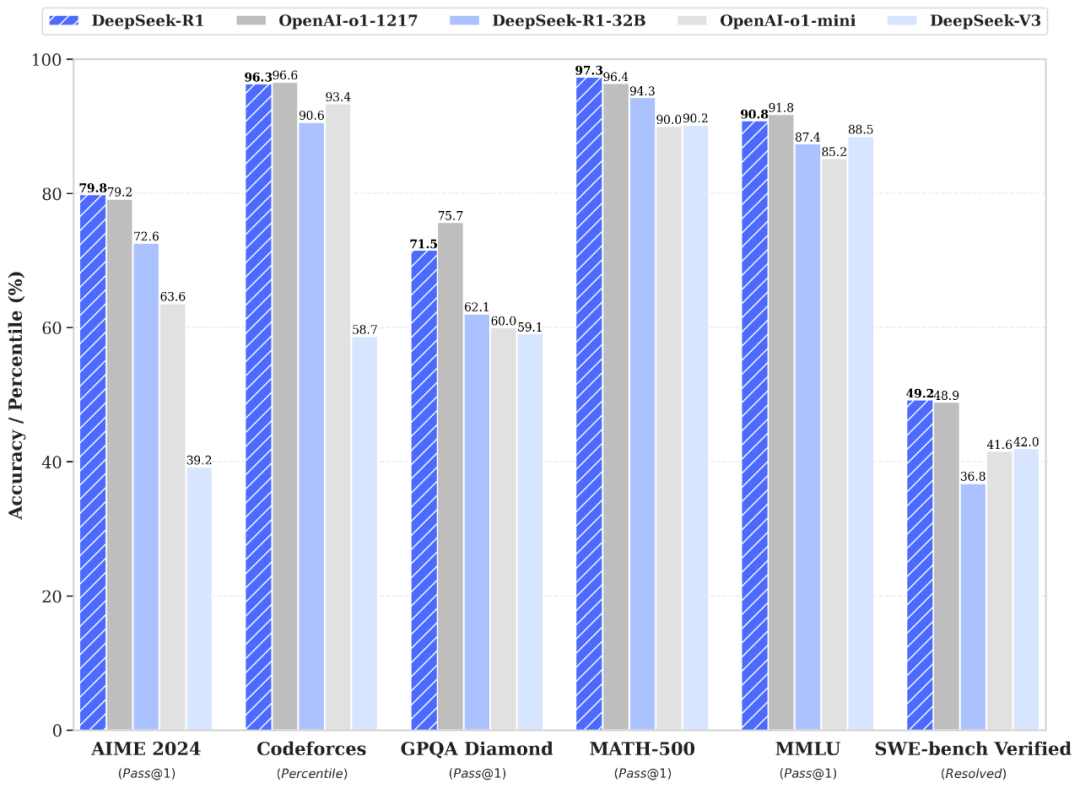
DeepSeek R1, as an open-source inference model, has quickly become the first choice for many developers due to its high cost-performance ratio. Compared to OpenAI’s models, DeepSeek R1 has approximately 95% lower costs but does not compromise on inference performance. Most importantly, it can run directly on your local machine, significantly improving efficiency and data security. With DeepSeek R1, you can extract the most relevant information from PDFs without relying on external APIs for inference.
Core Elements of a Localized RAG System
To build an effective localized RAG system, you first need to prepare the following key components:
1.Ollama: This is a lightweight framework that allows you to run the DeepSeek R1 model locally. It supports various model variants, enabling you to choose the appropriate size and parameters based on your needs.
2.PDF Document Processing: Since the core of the RAG system is document retrieval and generation, you need a tool to efficiently handle PDF files and extract their content. We will utilize PDFPlumberLoader to load PDFs and extract text.
3.Text Splitting and Embedding: To improve retrieval accuracy, we need to split the document content into semantic chunks and generate vector embeddings, utilizing the FAISS vector database for fast searching.
4.Retrieval Q&A Chain: Finally, we will construct a Q&A chain that can understand and answer questions, generating high-quality answers through the DeepSeek R1 model.
Extracting Data from PDF Documents
First, we create a simple user interface using Streamlit that allows users to upload PDF files. Next, we use PDFPlumberLoader to load the document and extract its text content. Here is the relevant code:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# Temporarily save the PDF file
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load PDF content
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
This code implements a simple file upload function that saves the PDF file locally and uses PDFPlumberLoader to load the file content. Next, we can split the document for efficient retrieval.
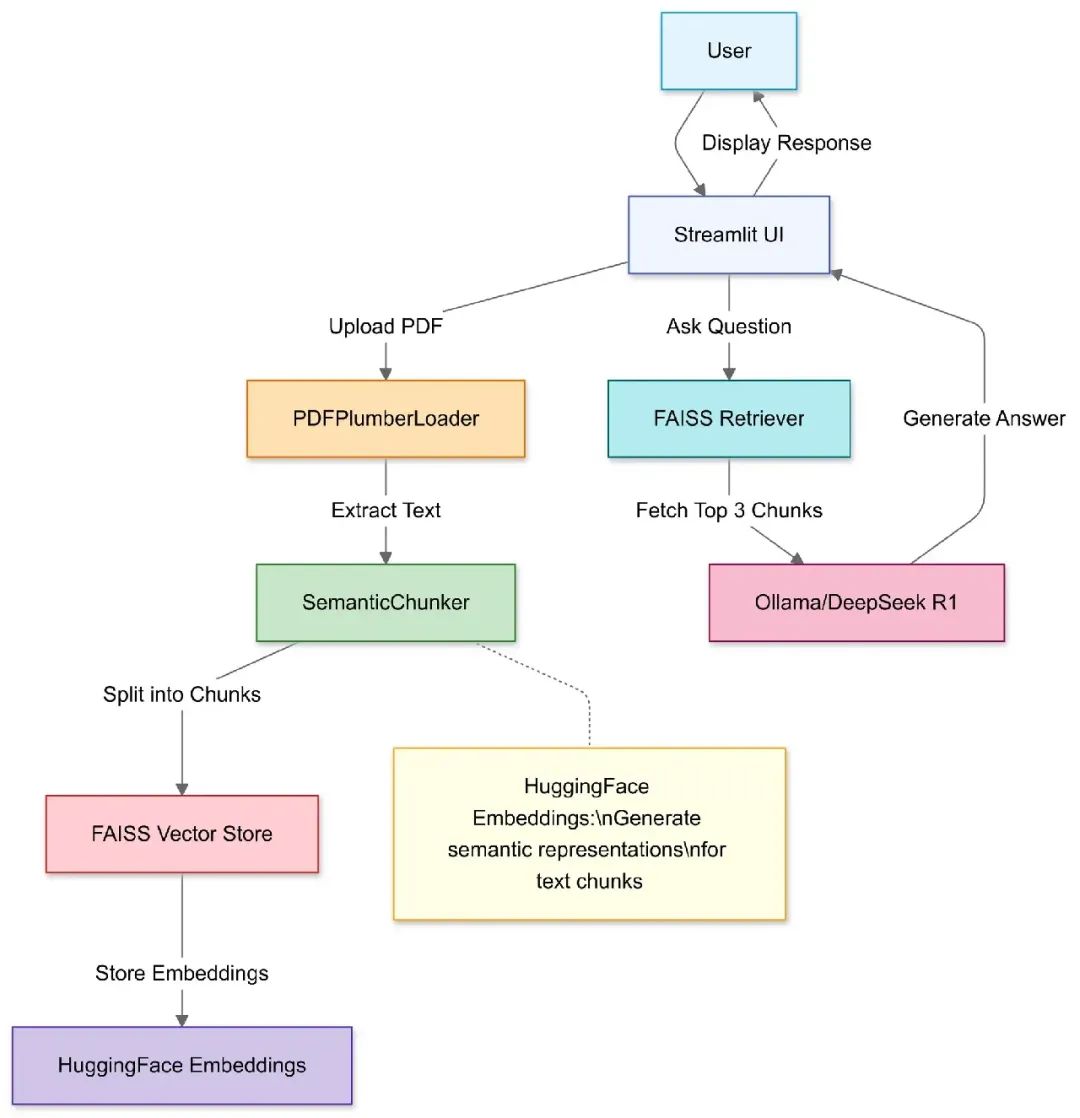
Text Splitting and Vector Embedding
To quickly retrieve relevant content, we will split the document text into smaller semantic chunks. SemanticChunker is the tool we use to split the text, which can divide the text into reasonable segments based on semantics for further processing.
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Next, we will convert these split text segments into vector embeddings and store them in the FAISS vector database for fast retrieval.
from langchain_community.vectorstores import FAISS
embeddings = HuggingFaceEmbeddings()
vectore_store = FAISS.from_documents(documents, embeddings)
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Retrieve the 3 most relevant segments
Building the Q&A Chain
At this step, we will combine the DeepSeek R1 model with the text retrieval system to create a Q&A chain. By constructing appropriate prompt templates, we can ensure that the model’s answers are based on the document content, rather than its own training data.
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
llm = Ollama(model="deepseek-r1:1.5b") # Use DeepSeek R1 1.5B parameter model
# Create prompt template
prompt = """
1. Use only the following context.
2. If unsure, respond with "I don't know".
3. Keep the answer under 4 sentences.
Context: {context}
Question: {question}
Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
In the prompt template, we require the model to rely solely on the context in the document to answer questions, effectively avoiding incorrect or inaccurate answers.
Integrating the RAG Process
Now, we will integrate all the previous steps into a complete RAG process. The user’s input question will be passed to the retriever, and the retrieved relevant document segments will be passed to the DeepSeek R1 model to generate answers. Here is the process code:
from langchain.chains import LLMChain
from langchain_community.chains import RetrievalQA
from langchain_community.chains import StuffDocumentsChain
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
document_prompt = PromptTemplate(template="Context:\nContent:{page_content}\nSource:{source}", input_variables=["page_content", "source"])
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt),
retriever=retriever)
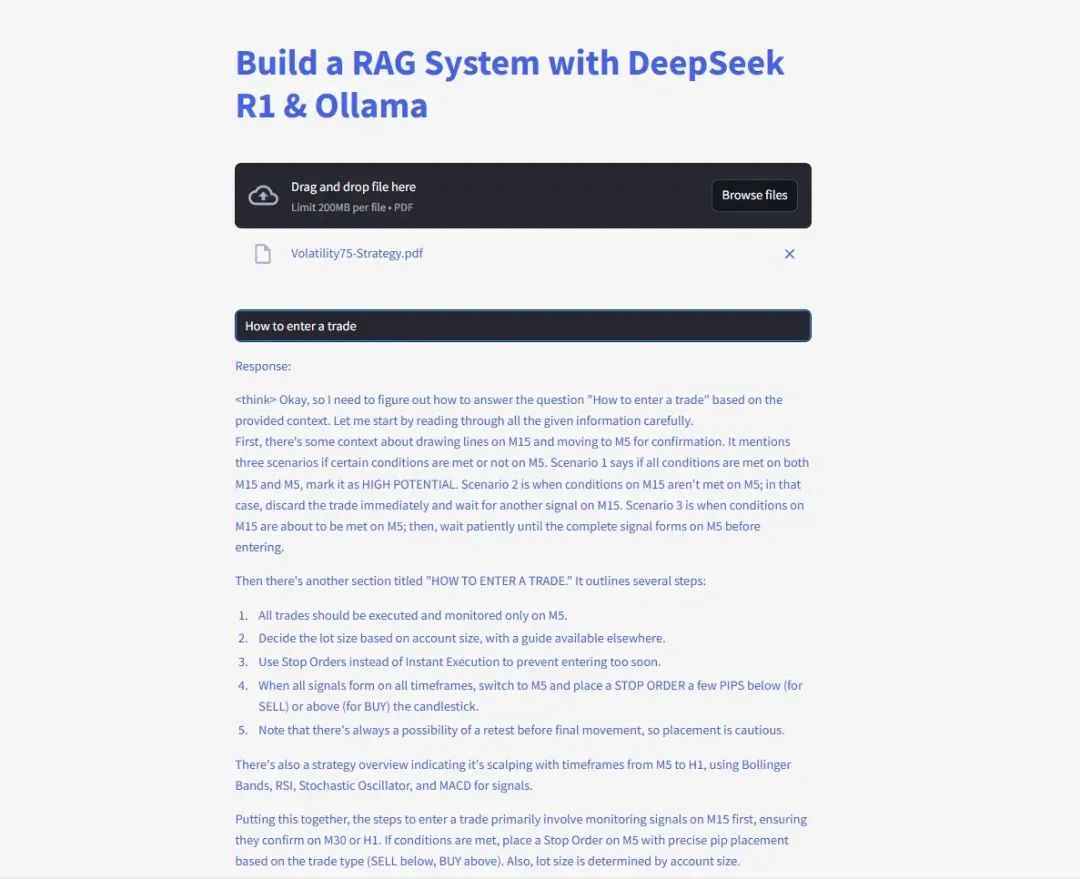
Launching the Web Interface
Finally, we use Streamlit to create a simple web interface that allows users to directly ask questions about the document and receive instant answers. Here is the code to implement this functionality:
user_input = st.text_input("Ask your PDF:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)
With this code, users can input questions on the web interface, and the system will generate accurate answers based on the document’s content and display them in real-time.
Future Prospects: DeepSeek’s RAG System
DeepSeek R1 is just the beginning; future RAG systems will introduce more innovative features. For instance, DeepSeek’s self-validation capabilities and multi-hop reasoning abilities will enable the model to perform logical reasoning and improvements independently, even debating with users to refine its reasoning process. This means that future RAG systems will not only provide answers but also self-validate the correctness of those answers, enhancing their credibility and intelligence.
Long press the QR code belowto get the complete source code of this article:

Click to read the original text and join the AI Technology Monetization Training Camp

