Selected from arXiv
Authors:Jos van der Westhuizen, Joan Lasenby
Compiled by Machine Heart
Contributors: Pedro, Lu
This paper studies what happens when LSTM only has a forget gate and proposes JANET, with experiments showing that this model outperforms standard LSTM.
1. Introduction
Excellent engineers ensure their designs are practical. We now know that the best way to solve sequence analysis problems is through Long Short-Term Memory (LSTM) recurrent neural networks. Next, we need to design an implementation that meets the constraints of resource-limited real-world applications. Given the success of gated recurrent units (GRUs) with two gates (Cho et al., 2014), the first approach to designing a more hardware-efficient LSTM may be to eliminate the redundant gate. Since we are seeking a model more efficient than GRU, a single-gate LSTM model is worth our investigation. To illustrate why this single gate should be the forget gate, let’s start with the origins of LSTM.
In the era when training recurrent neural networks (RNNs) was very challenging, Hochreiter and Schmidhuber (1997) believed that using a single weight (edge) in RNNs to control whether to accept the input or output of memory cells led to conflicting updates (gradients). Essentially, at each step, both long and short-range errors act on the same weights, and if a sigmoid activation function is used, the gradient vanishes faster than the weights increase. They then proposed the Long Short-Term Memory (LSTM) unit recurrent neural network, which has multiplicative input and output gates. These gates can alleviate the conflicting update problem by ‘protecting’ the units from irrelevant information (inputs or outputs from other units).
The first version of LSTM had only two gates: Gers et al. (2000) first discovered that without a mechanism for memory cells to forget information, they could grow indefinitely, eventually causing the network to collapse. To solve this problem, they added another multiplicative gate, the forget gate, to this LSTM architecture, completing the version of LSTM that we see today.
Given the significance of the latest findings about the forget gate, let’s imagine LSTM using only a forget gate; are the input and output gates necessary? This study will explore the advantages of using only the forget gate. Across five tasks, the model using only the forget gate provided better solutions than the model using all three LSTM gates.
3 JUST ANOTHER NETWORK
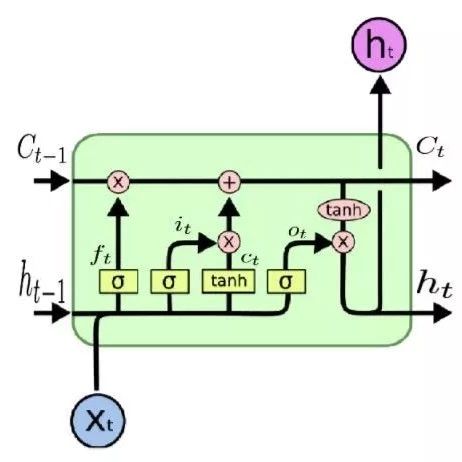
We propose a simple variant of LSTM that has only a forget gate. It is Just Another NETwork, hence we named it JANET. We start with the standard LSTM (Lipton et al., 2015), where the symbols have standard meanings, defined as follows
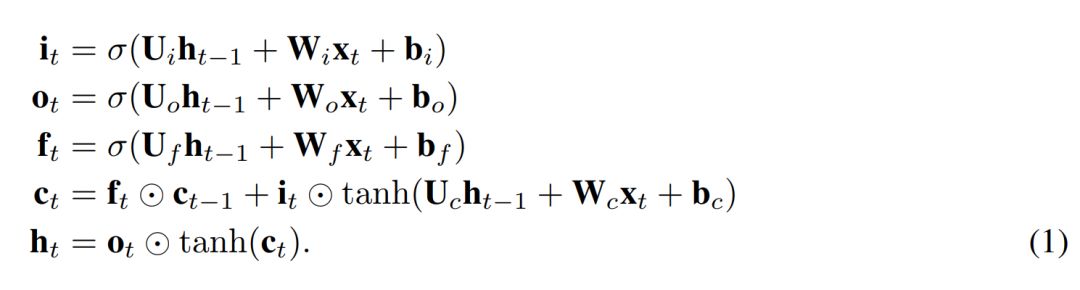
To convert the above content into the JANET architecture, we removed the input and output gates. It seems wise to associate the accumulation and deletion of information, so we combined input and forget modulation, similar to what Greff et al. (2015) did, which is akin to the leaky unit implementation (Jaeger, 2002, §8.1). Furthermore, the tanh activation function of h_t causes gradients to shrink during backpropagation, potentially exacerbating the vanishing gradient problem. The weight U∗ can accommodate values outside the range of [-1,1], allowing us to remove this unnecessary and potentially problematic tanh nonlinearity. The resulting JANET outcomes are as follows:
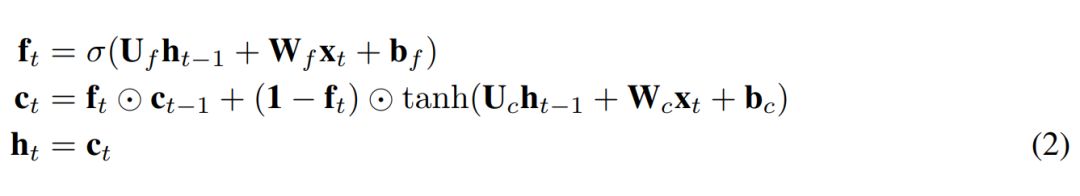
4 Experiments and Results
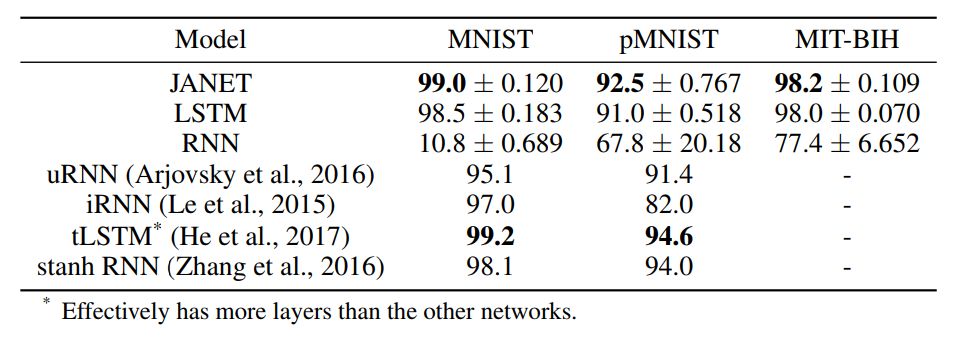
Table 1: Accuracy [%] of different recurrent neural network architectures. The figure shows the mean and standard deviation from 10 independent runs. The best accuracy results from our experiments and the best results from the cited papers are highlighted in bold.
Surprisingly, the results indicate that JANET has a higher accuracy than standard LSTM. Additionally, JANET is one of the best-performing models across all analyzed datasets. Thus, by simplifying LSTM, we not only save computational costs but also improve accuracy on the test set!
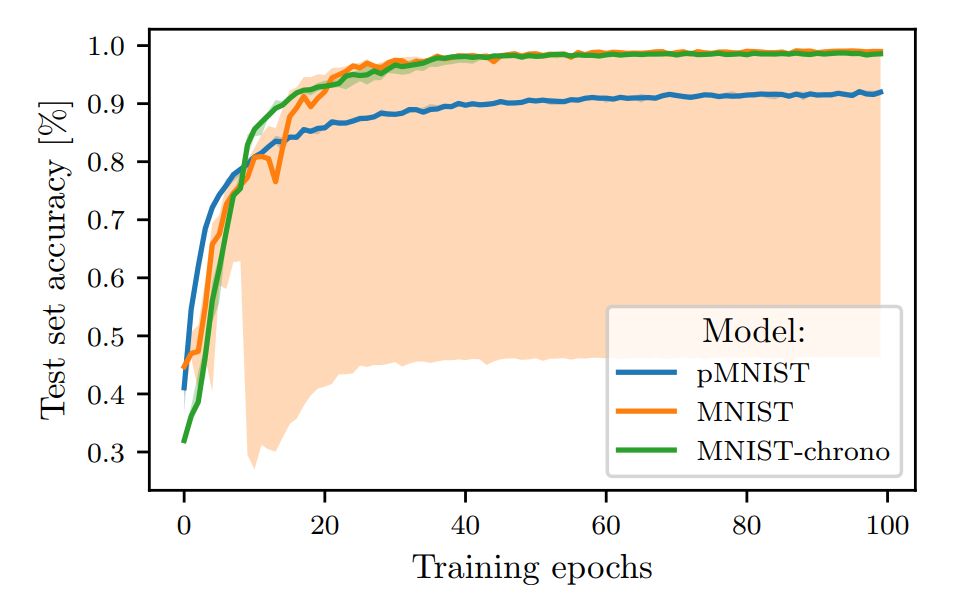
Figure 1: Testing accuracy of LSTM trained on MNIST and pMNIST.
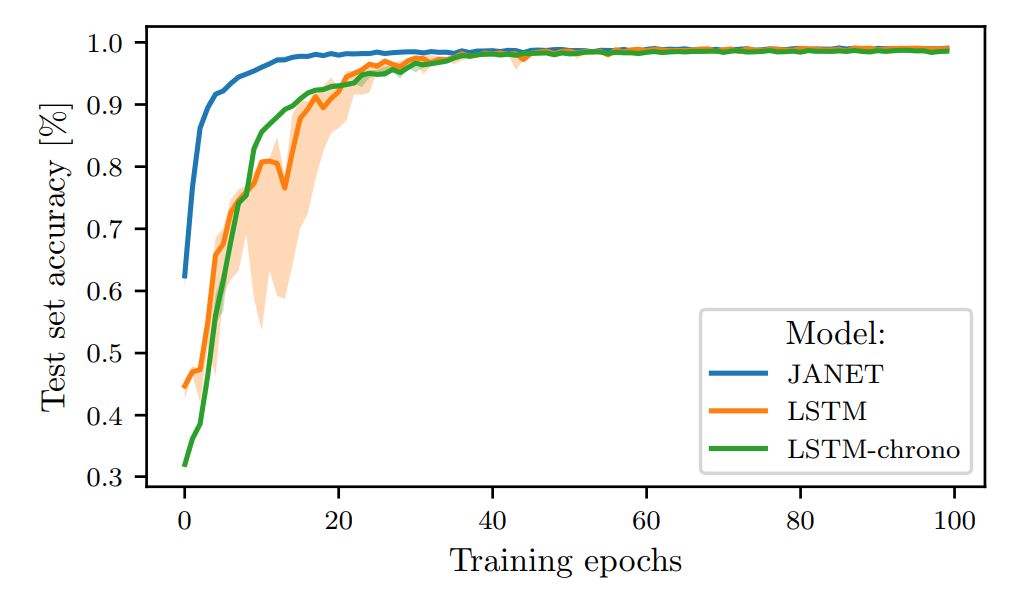
Figure 2: Comparison of test set accuracy for JANET and LSTM during training on MNIST.
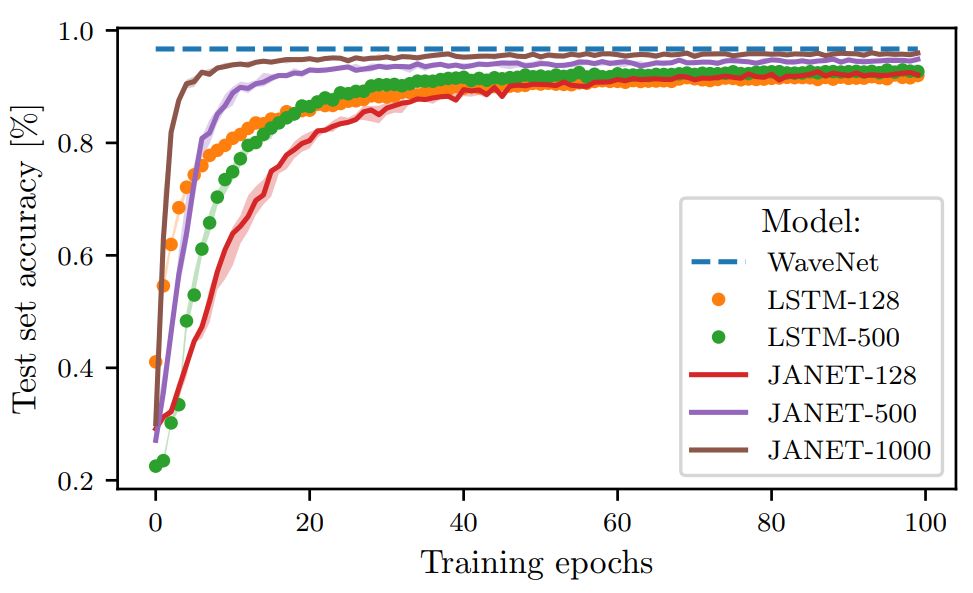
Figure 3: Accuracy (%) of JANET and LSTM on the pMNIST dataset with different layer sizes.
Paper: THE UNREASONABLE EFFECTIVENESS OF THE FORGET GATE

Paper link: https://arxiv.org/abs/1804.04849
Abstract: Given the success of gated recurrent units (GRUs), a natural question arises: are all gates in Long Short-Term Memory (LSTM) networks necessary? Previous research has shown that the forget gate is one of the most important gates in LSTM. Here we find that an LSTM version with only a forget gate and a chrono-initialized bias not only saves computational costs but also outperforms standard LSTM on multiple benchmark datasets, competing with some of the best models currently available. Our proposed network, JANET, achieved accuracies of 99% and 92.5% on the MNIST and pMNIST datasets, respectively, surpassing the standard LSTM’s accuracies of 98.5% and 91%.
This article is compiled by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submissions or inquiries: [email protected]
Advertising & Business Cooperation: [email protected]