
Original by Machine Heart
Author: Siyuan
Recently, Machine Heart interviewed Huang Kang, the senior technical director of Kika, who told us about the deep learning model used in the development of Kika’s input method AI engine (project code name: Alps) and the various challenges encountered in lightweight deployment on mobile devices. This article introduces the theoretical support and practical challenges of the Kika Alps project, starting from input methods and language models, and focuses on lightweight deployment methods.
Deep learning models perform excellently on many tasks due to their strong representational capabilities, but they are also difficult to deploy on mobile devices because of their model size and computational load. This is a problem that many research and development teams are currently considering how to solve.
Generally, after we build deep learning models using frameworks such as TensorFlow, MXNet, and Caffe2, they often perform very well in server training and inference. However, when we deploy the model to mobile devices, even if we only execute the inference process, we will encounter various problems due to hardware conditions and system environments. Moreover, current solutions focused on mobile devices, such as TensorFlow Mobile and TensorFlow Lite, are not perfect to some extent (e.g., TF Mobile’s memory management and the lack of operators in TF Lite), and may require more corrections and improvements in practice.
Kika, focused on input methods, successfully applied a deep learning model based on recurrent neural networks to the Android input method engine, greatly enhancing the input experience while overcoming engineering challenges: not only making context-based word predictions more accurate but also significantly improving the word correction function.
In constructing such an input method engine, Kika needed to consider whether to use LSTM or GRU to achieve an efficient language model while exploring how to make the entire solution lighter and how to deploy it quickly. This article first introduces the input method and the language model used by Kika, and then showcases the engineering challenges encountered in lightweight deployment on Android mobile devices. Finally, this article introduces the sparse word representation method and K-means parameter quantization method used by Kika to compress models, which are crucial for lightweight deployment of deep learning models.
Input Method and Language Model
The most important part of an input method is the input method engine, around which many algorithms and projects at Kika are developed. Generally, the input of the input method engine consists of two parts: the phrases that have been typed and the vocabulary currently being input. The former can be seen as context, while the latter, which is unfinished, can be called the key code. The output of the input method engine is the predicted word given all contexts and the current input key code, which also includes two parts: the completion of the current input vocabulary and error correction. Achieving such functionality is the core module of the input method. Kika initially used Google’s semi-open-source LatinIME to implement this functionality, but this n-gram-based method could not achieve a top-notch user experience. Therefore, after research and development, a solution based on recurrent neural networks (RNN) was developed.
The method of predicting the next word given context and the current key code in the input method engine can actually be seen as language modeling. Generally, language models aim to define the probability distribution of “tokens” in natural language, which can be words, characters, or even bytes. According to Kika, the method used by LatinIME to build the language model is n-gram, which defines a conditional probability distribution, that is, the conditional probability of the nth word given the previous n-1 words. Since it is assumed that the probability of the current word depends only on the previous n-1 words, n-gram can use the product of this conditional probability to define the probability distribution of longer sequences:
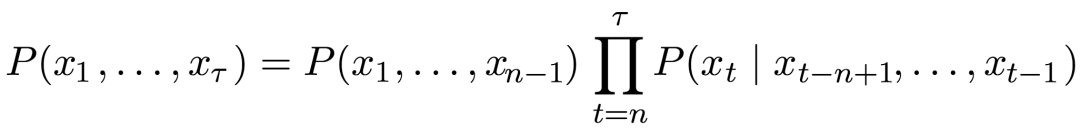
Although n-gram has always been a core module of statistical language models, it still has many limitations. For input methods, a small n (bigram and trigram) is insufficient to capture the entire contextual information for prediction, while increasing n leads to an exponential increase in computational load. Moreover, Kika also hopes that the engine can achieve other intelligent features, such as automatic error correction or sorting based on context. Therefore, Kika chose a more powerful recurrent neural network to construct the language model.
To build a powerful language model, Kika chose long short-term memory (LSTM) units as the basis of the network. LSTM, as a variant of standard recurrent neural networks, performs very well in language modeling. It introduces a clever idea of self-recurrence to update “memories.” If the self-recurrence is controlled by gating, the accumulated historical memory or time scale can change dynamically. Intuitively, LSTM selects the contextual information or memory to retain through gating and uses it to predict the current input word. Each time a word is input, the input gate controls the useful information from the current input for the final prediction, while the forget gate controls the useful information from the previously input words for the final prediction. Finally, the output gate directly controls the effective information from the previous two parts.
Kika indicated that initially, LSTM was only used to implement a standard language model, and it did not take the ongoing key code as model input. This early scheme used the LSTM language model to predict the current word based on context, while the key code part still used traditional solutions based on n-gram and dictionaries. Later, Kika adopted a new strategy to combine the two parts, allowing the model to accept both contextual input and key code input. The architecture of this generalized solution is shown in the following figure, which is different from both typical word-level language models and character-level language models, and can be said to combine the two architectures.
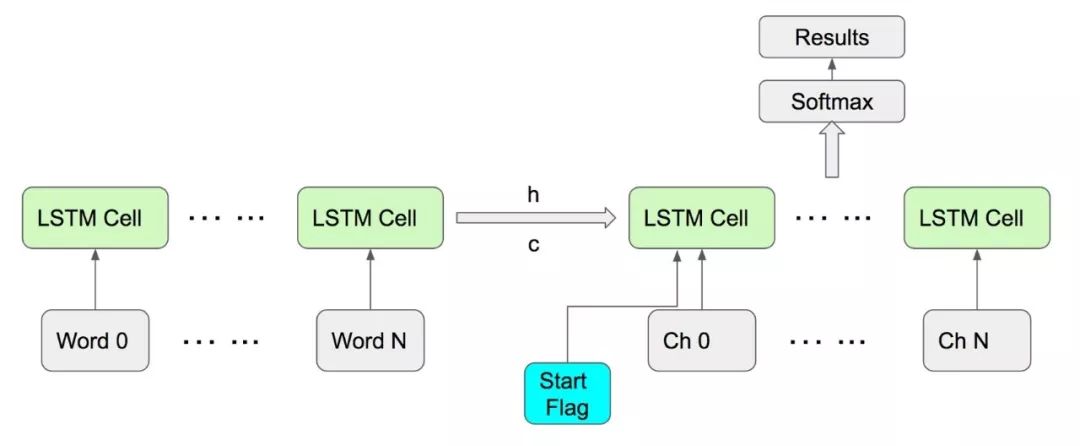
As shown in the figure above, LSTM first models the previously input words and outputs the corresponding hidden state and memory as the prior input for the subsequent character-level language model. Then, starting from the Start Flag, character-level modeling is performed on the key code to ultimately derive predictions.
According to Kika’s explanation, this scheme unifies the two types of inputs. The basic idea considers that the LSTM language model not only predicts the output at the current time step based on the hidden state but also passes this hidden state backward. Kika indicated that if the network is well-trained, this hidden state can contain sufficient semantic information, so we can use it as the initial state for the subsequent character-level LSTM network. This essentially gives the recurrent neural network an initial quantity, which then accepts the key code input to make final word predictions and corrections.
There is actually a very interesting question here: why did Kika choose LSTM instead of GRU. As we know, if we want to deploy deep learning models on mobile devices, we need to strictly control the size of the model and computational load. The sparse word representation and parameter quantization methods used by Kika can effectively control the model size, which will be elaborated later. However, the structure of LSTM is more complex than GRU, requiring more gating, so LSTM has more parameters than GRU. Why did Kika not choose GRU to control the number of parameters?
Kika provided a detailed explanation on this point to Machine Heart. Huang Kang said: “With the same number of layers and units, GRU has fewer parameters and matrix operations than LSTM, so it has certain advantages in model size and training speed. To rigorously compare the effects, we conducted two sets of experiments. The first group was to set the hyperparameters of LSTM and GRU to be consistent, and the result was that GRU’s performance was significantly inferior to that of LSTM. Moreover, since the main contribution to the overall model size comes from the two large word embedding matrices, the size advantage of the model is not obvious.”
However, under the same hyperparameters, the actual number of parameters in GRU is significantly less than that in LSTM. Therefore, Kika conducted a second group of experiments, relaxing the constraints on network architecture while ensuring a roughly consistent number of parameters. The conclusion was that the model sizes of LSTM and GRU were basically the same, and the performance was also roughly the same. In fact, in Kika’s application scenario, LSTM performed slightly better, but only slightly. Additionally, since GRU was relatively new at the time, Kika preferred to choose the more stable LSTM, thus focusing on model structure adjustments and parameter tuning. Recently, Kika has also been conducting some research on network architecture and basic units, as there have been many new structures that are easy to train and efficient since GRU. In Kika’s current development process, there are also some more complex NLP/NLU applications, so they are considering adopting some network results that are friendlier in terms of training time. Regarding how to choose the network structure, Huang Kang stated: “We have a consensus internally that when considering new structures, we will use complex tasks like machine translation to verify whether the network is truly effective before considering its engineering application.”
Overall, Kika spent a significant amount of time on parameter tuning, enabling them to achieve excellent performance with an integrated LSTM-based input method engine. Of course, simply constructing the model is far from enough; deploying such deep learning models on mobile devices presents numerous challenges, such as selecting deep learning frameworks and model compression methods, etc.
Engineering Challenges of Lightweight Deployment
At Kika, lightweight deployment includes the following four aspects: model compression, fast response time, low memory usage, and small shared object (.so) library size, etc. In addition to optimizing model design, methods for compressing model size mainly include sparse word representation and quantization, which we will discuss later.
Response time and memory were the focus of Kika’s work last year, which required a lot of patching for TensorFlow Mobile and Lite. Finally, there’s the dynamic link library file (.so), which defines all the required operations. Since the core code of the entire input method is completed in C++, it exists in Android devices in the form of a library (.so file), and its size directly affects the installation package size (due to Android’s loading mechanism for .so files, it also affects memory overhead).
To address response time and memory, Kika initially made some patches and improvements based on TensorFlow Mobile. Huang Kang said: “TensorFlow Mobile has a very good advantage, which is that it uses a very mature and stable matrix computation library at the bottom layer. Therefore, our main focus was on the parts above the underlying matrix computation library of TensorFlow Mobile. It adopted a lot of encapsulation and calls between matrix computation libraries but did not consider many practical issues encountered in industrialization, especially in memory protection.”
The memory management and protection design of TF Mobile is not perfect, with two main issues: 1. The memory protection mechanism is inadequate, leading to illegal memory operations in actual memory shortages (especially for some low-end models). 2. There are obvious issues with memory size control mechanisms; for example, the model itself may only be 20MB during computation, but the runtime peak memory usage may reach 40 to 70MB. According to Kika’s data, about 1% of scenarios based on TF Mobile (such as invoking the input method in games) fail to load deep learning models due to memory size limitations and can only fall back to non-deep solutions.
In November 2017, Google officially released TensorFlow Lite, which is a very important framework for deep learning models on mobile devices. After TF Lite was open-sourced, Kika immediately conducted tests, focusing on the memory management module. Huang Kang stated: “TF Lite has indeed made significant improvements in memory management, and the scenarios where deep learning models cannot be loaded have decreased by hundreds of times. However, its biggest problem is the incompleteness of operators; it basically only defines the most basic operations. Therefore, to reduce overhead by more than 20MB in memory, Kika wrote a large number of operators by ourselves. However, this still carries certain risks because if we modify the model structure, we still need to write new operations manually.”
The last engineering challenge is the size of the dynamic link library, which also involves the implementation of parameter quantization methods, which we will discuss in the parameter quantization section. In fact, TF Mobile has another drawback: it packs many redundant operations and calculations into the .so file, which leads to an oversized dynamic link library. To minimize the size of the .so file, Kika developed a completely new tool to automatically determine which operations and definitions the model actually needs.
Sparse Word Representation
An important issue in deploying deep learning models in input method clients is model size; we need to limit the number of parameters and computational load to a range acceptable by most mobile devices. Kika found that the main contradiction in model size lies in the word embedding matrix. Therefore, if we can compress the size of the word embedding matrix, we can effectively control the model size. Kika adopted the sparse word representation method to compress the size of the word embedding matrix, significantly reducing the parameters and computational load of the LSTM language model.
In fact, for language models, and even for natural language processing, word embeddings are a very important component. We can represent tens of thousands of words in the vocabulary using 300 to 500-dimensional vectors. This method does not use extremely high-dimensional vectors to represent a word like one-hot encoding; instead, word embeddings reduce the representation of words from |V| dimensions to a few hundred dimensions, where |V| represents the vocabulary size. However, when we use word embeddings as input for the language model, we find that although the dimension of each word is only n, we need |V| vectors, and |V| is usually several orders of magnitude larger than n. Therefore, sparse word representation attempts to use a small number of word vectors (less than |V|) to represent |V| words.
The intuitive concept of this method is that our vocabulary can be divided into common words and uncommon words, and a single uncommon word can be defined by multiple common words. Based on this idea, we can use a set of common words’ embedding vectors as a basis and represent all words’ embedding vectors through combinations. Therefore, we can use a small number of embedding vectors to represent a large number of words. Since each word’s representation uses only a small number of common words, this representation method is very sparse, which is the intuitive concept of sparse word representation.
If we split the vocabulary V into two subsets B and C, the first subset B is the basis vector set, which contains a fixed number of common words. C contains all the uncommon words, so now we need to use the embedding vectors of B to encode the words in C in a linear combination. This process can be learned by minimizing the distance between the word representation learned from the basis vector set and the complete representation. Generally speaking, the entire process can be represented as:
1. Train a word embedding matrix using all vocabulary.
2. Select the |B| most common embedding vectors based on word frequency and form an over-complete basis matrix.
3. Predictions for uncommon words can be represented as a sparse combination of all embedding vectors in B, that is,
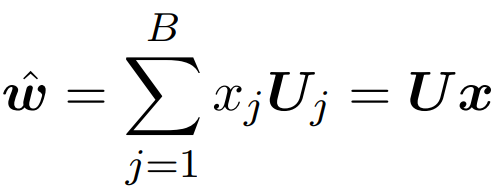
where w hat is the predicted embedding vector for the uncommon word, U is the embedding vectors for common words, and x is the sparse matrix.
4. Minimize the distance between the predicted word vector and the actual word vector to learn the sparse representation, that is,
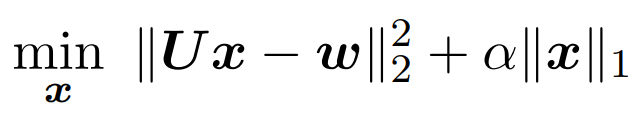
where the first term represents the L2 distance between the predicted word vector through sparse representation x and the complete word vector (w). The latter term is L1 regularization, which pushes the elements of the matrix x towards 0, achieving sparse representation.
In Kika’s paper *Sparse Word Representation for RNN Language Models on Cellphones*, they used the following pseudocode to demonstrate the learning algorithm for sparse representation:

This algorithm’s significant feature is that it implements a binary search to determine α, as we cannot directly control the sparsity of the sparse matrix x, so we control the variation of α based on the number of non-zero elements in the sparse matrix. The entire sparse word representation algorithm requires an over-complete basis matrix U (common words), a complete word embedding matrix w, the sparsity parameter s, and a tolerance level tol as the termination condition.
Among these, s is a very important parameter that controls how many over-complete basis vectors a word needs for representation. Kika stated: “s is a trade-off; if the parameter is too large, the compression ratio will be small, and the model will not meet expectations. If the parameter is too small, the reconstructed word representation will not effectively represent all words.” Because fine-tuning is needed to determine s and other hyperparameters, Kika indicated that the overall model tuning time is 4 to 5 times the training time, so the training process for the entire sparse word representation is quite lengthy.
As shown in the algorithm above, we first determine the search range for α, then take the middle value of α and minimize the loss function to obtain the sparse representation x*, and count the number of non-zero elements in each column vector of x*, which represents how many common words are needed to represent a word. If k is greater than s, there are too many non-zero elements, requiring an increase in α to enhance the effect of L1 regularization. This binary search continues until the distance between the upper and lower bounds of α is less than the parameter tol, and generally, several iterations can quickly converge to an appropriate α to control the sparsity of x*. After learning x*, we extract the indices and weights for each column sparse vector, where the indices represent which basis vectors or common words are used, and the weights represent their importance in defining a word.
Since the previous binary search restricts k to be no larger than s, it is possible that k is less than s, so we need to use zeros to pad these vectors. After the above steps, we ultimately produce equal-length vectors indices and weights containing s elements. Storing these two vectors instead of directly storing the sparse matrix x* can save a lot of space, which is very important for reducing the installation package size.
The word embedding recovery algorithm given in the paper is presented in a serial dense computation manner, which allows readers to clearly understand the reconstruction process:

Given U, indices, and weights, the embedding reconstruction of a word can be directly obtained by taking the corresponding basis vectors using the indices and calculating the weighted sum with the corresponding weights. This linear combination is very simple and efficient, and it is also a very intuitive representation method in linear algebra. Any matrix of rank n can be represented by n linearly independent vectors or bases, and the complete word embedding matrix can be represented by the linear combination of over-complete bases. The final return of Algorithm 1.2 is the complete word embedding vector reconstructed by combining multiple common word embeddings.
The above is the sparse word representation method adopted by Kika, which can effectively reduce model parameters and computational load. However, we can further use parameter quantization to compress the model’s storage size.
Quantization
Generally speaking, the installation package size of an application is crucial for user experience, especially for mobile devices. Therefore, we can use parameter quantization methods to reduce the installation package size. Kika also attempted to use the compression methods packaged in TensorFlow, but still encountered some difficult problems, so they ultimately used the k-means method to reconstruct parameter quantization and resolve the issue of package size increase.
Kika initially tried to use the official tf.quantize for parameter quantization and tf.dequantize to restore parameters. This method is very fast; basically, a model of several dozen megabytes can be compressed in minutes. However, Kika found that this method has a significant problem: when we want to read the quantized model, TensorFlow introduces a large number of operators, which inevitably increases the size of the dynamic link library (.so) and thus increases the size of the installation package. Since the dynamic link library contains all the operations needed by the model, such as addition, subtraction, convolution, and normalization defined by TF, calling TensorFlow’s quantization method will also add the relevant operations to the dynamic link library.
According to Kika’s experiments, using TensorFlow’s official quantization method increases the size of the dynamic link library by about 1 to 2MB, which corresponds to the same increase in the installation package size. For this reason, Kika ultimately chose to implement parameter quantization based on k-means. In simple terms, this method first clusters similar vectors together using k-means and then stores the cluster centers, while the original parameter matrix only needs to store the indices of the cluster centers. Kika stated that this method does not increase the size of the dynamic link library or installation package.
Quantization involves summarizing certain features from the weights, which are stored in a codebook and represented by specific values for a certain class of weights. The original weight matrix only needs to store the indices to indicate which class of features they belong to, which can significantly reduce storage costs.
The scalar quantization algorithm used by Kika is based on the idea that for each m×n dimensional weight matrix W, it is first transformed into a vector w containing m×n elements. Then, the elements of this weight vector are clustered into k clusters, which can be quickly completed using the classic k-means clustering algorithm:
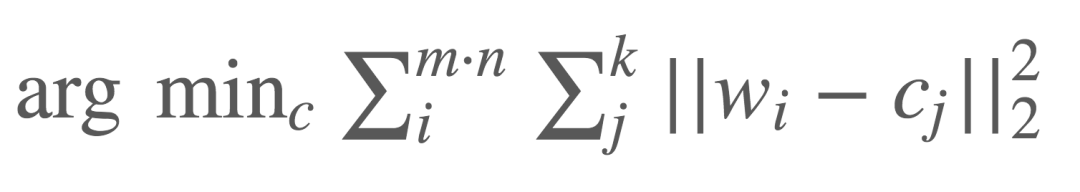
Now, we only need to store k cluster centers c_j, while the original weight matrix only needs to record the indices of their respective cluster centers. In Han Song’s ICLR 2016 best paper, he used a diagram to vividly illustrate the concept and process of quantization.
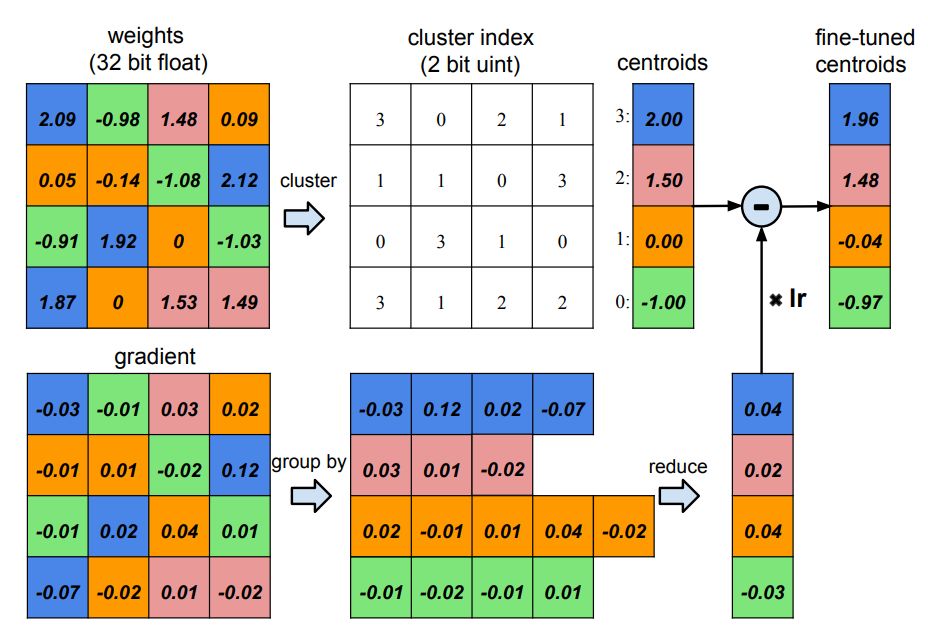
As shown above, all parameters of the weight matrix can be clustered into 4 categories, with different colors representing different categories. The upper part of the weight matrix can take the cluster centers and be stored in the centroids vector, while the original weight matrix only needs to store the corresponding indices in a small space. The lower part shows the process of Han Song and other researchers correcting the current centroids vector using the gradient of backpropagation.
Sparse word representation and parameter quantization are the main methods Kika uses to control parameter size. Huang Kang stated: “In fact, the size of the model can be divided into two stages. First, if the original model is 40MB, sparse word representation can reduce the model to about 20MB, which is the actual size in memory. Further adopting parameter quantization can compress the size to about 4MB, addressing the issue of APK installation package size, which is also very important. After all, for applications like input methods, the APK size is crucial. Regardless of whether parameter quantization is used, the memory required for computation is the size after sparse word vector representation.”
The last two parts are essentially Kika’s solutions to model size, which make the application of deep learning models in practice possible. Of course, embedding deep learning models into input methods and mobile devices will face many challenges; merely controlling model size is not enough. Therefore, Kika has also made efforts in memory size, response time, and dynamic link libraries, among other aspects.
The overall model performance and engineering practices are Kika’s exploration of the input method engine over the past two years. There are still many optimization and improvement directions in the future, such as using new recurrent units or new reinforcement learning to adjust the input method based on user habits. These new features and directions will endow the input method engine with more characteristics and adaptively provide the best experience for different users. 
This article is original by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (full-time journalist/intern): [email protected]
Submissions or inquiries for reports: [email protected]
Advertising & Business Cooperation: [email protected]