
Source: Machine Heart
This article is approximately 1000 words long and is recommended for a 6-minute read.
This article introduces a very practical indexing tool in the NLP field called "The NLP Index".
When it comes to searching, academic search is also a science.
Being adept at using search can help you quickly find the academic materials you want, achieving results with half the effort. For example, the tool we often use, Papers With Code, collects many SOTA papers and their corresponding source code. You can directly search for papers by keywords and get relevant papers and code, and you can also search by field; similarly, arXiv collaborates with the literature research tool Connected Papers, allowing each arXiv paper to link directly to its related papers in Connected Papers from the abstract page.
This super practical search tool can conveniently help researchers find academic materials, saving a lot of time and providing optimal search results.
Here we introduce a very practical NLP indexing tool called “The NLP Index”, which is also developed for academic search and is free and open-source.
Project address: https://index.quantumstat.com/
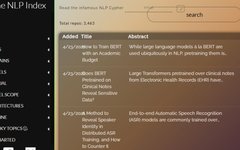
“The NLP Index” has over 3000 code repositories, and users can search through one of the sidebar sections, which includes some of the most important topics in today’s NLP. When you type in relevant content, you can search. Its index includes arXiv research papers in PDF format, links to the literature research tool Connected Papers, and corresponding GitHub code repositories, effectively integrating these three academic tools.
Introduction to “The NLP Index”
On the left sidebar of “The NLP Index”, there are 10 modules, as shown in the image below, including data (data augmentation, datasets, etc.), tasks (relation extraction, speech recognition, etc.), related fields (medical, finance, etc.), models (BERT, BART, etc.), language types (cross-language, multilingual, etc.), model scope (character level, sentence level, etc.), included architectures (encoder, decoder, etc.), PIPELINE, etc.
Taking the third module “MODELS” from the left sidebar as an example. When you click this module, a dropdown interface appears as shown in the image below, which includes commonly used models such as cnn, rnn, bart, bert, gpt-2, etc.
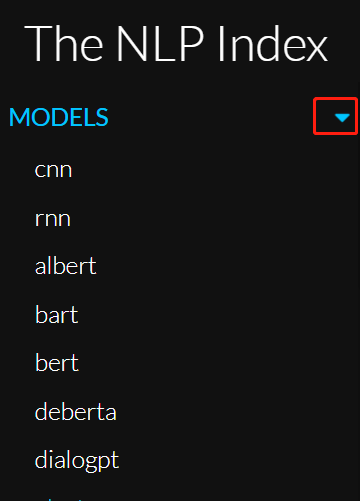
Some content included in the MODELS dropdown
If we randomly click on any model, such as “bert”, the right side will display relevant papers with the keyword “BERT” highlighted in blue, along with the paper’s abstract, authors, PDF link, Graph link, and GitHub link, making it easy for users to find quickly.
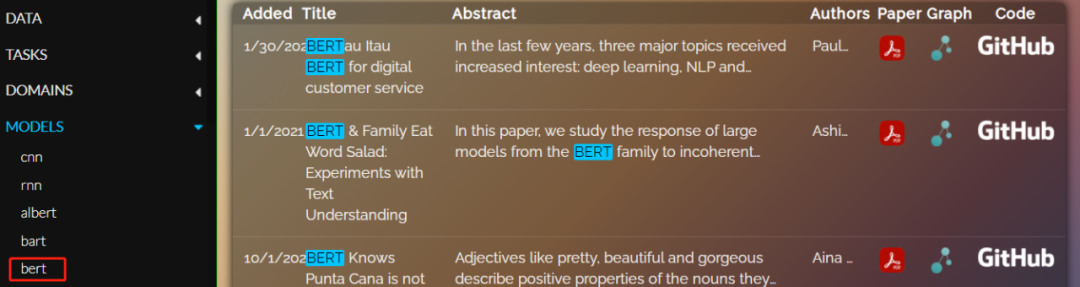
When the mouse hovers over the corresponding module (such as abstract, authors, etc.), the relevant content will be fully displayed for users to understand the overall content of the paper.

In addition, “The NLP Index” is also linked to Connected Papers. Clicking the Graph interface jumps to the generated literature analysis network graph. The results page is divided into three columns: the left column displays the titles of this paper and related references, the right column contains the specific content of the related references, and the middle column shows the literature retrieval analysis map. You can analyze citation information of literature online, easily understand the citations and references of a paper, and analyze the history of a paper, facilitating researchers to conduct research on a specific paper or field.
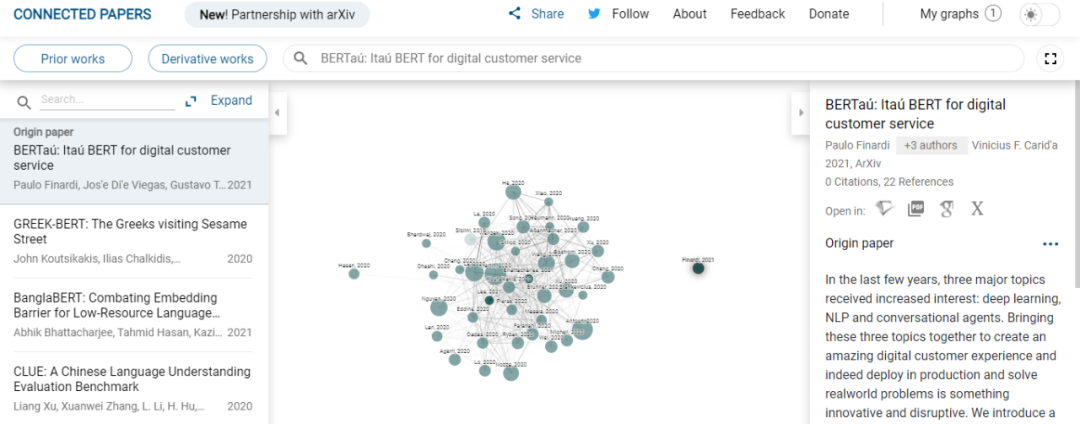
For this free and open indexing tool, some users commented: “This is amazing. Is the data from Papers With Code?”

Another user said: “Thank you very much for providing convenience to others.”

Reference link:
Editor: Huang Jiyan
Proofreader: Wang Yuqing
