▲Click on the top Leifeng Network to follow


Since 2012, the field of Natural Language Processing (NLP) has entered the era of neural networks for 7 years. Where is the future development heading? Let’s see how Dr. Zhou Ming, the chairman of ACL 2019 and vice president of Microsoft Research Asia, interprets it~
Written by | camel
Leifeng Network notes: From July 12 to July 14, 2019, the 4th Global Artificial Intelligence and Robotics Summit (CCF-GAIR 2019) was officially held in Shenzhen. The summit was hosted by the China Computer Federation (CCF), co-organized by Leifeng Network and The Chinese University of Hong Kong (Shenzhen), and co-sponsored by the Shenzhen Institute of Artificial Intelligence and Robotics. It received strong guidance from the Shenzhen Municipal Government and aims to create a top-level exchange and exhibition platform for academia, industry, and investment in the domestic artificial intelligence and robotics sectors.
At the CCF-GAIR 2019 conference, Dr. Zhou Ming interpreted the future development path of NLP from the perspectives of what NLP is, the current technical system, and future development. Let’s take a look.

Good afternoon everyone! I am very honored to be at the CCF-GRIR conference today. This forum this afternoon is very meaningful as it discusses the 40th anniversary of artificial intelligence in China.
I started my research in machine translation at Harbin Institute of Technology in 1985, and it has been over 30 years now. I have experienced three stages: rules, statistics, and neural networks. Looking back, I feel a lot of emotions; at that time, we had nothing, but everyone had the enthusiasm to push Chinese natural language, machine translation, and artificial intelligence to the forefront of the world.
Chinese artificial intelligence began in 1979, and in the blink of an eye, it has been 40 years. Looking back, how far have we progressed in natural language processing? Where is our future path? This is what I want to introduce to you today.
In the past 40 years, natural language has basically gone through the stages from rules to statistics to the current neural networks. Compared to the past, we can say that this is the golden age of natural language processing, with breakthrough progress in many fields. However, we cautiously observe that neural network-based natural language processing is overly dependent on computing resources and data, and there are still many shortcomings in modeling, reasoning, and interpretation. Therefore, we want to ask, can this model be sustained? How will NLP develop in the next 3 to 5 years?
To answer this question, I want to outline the technologies in neural network-based natural language processing, identify the key technical points, and highlight the shortcomings, and how we will develop in the future. My view is that the future development of NLP requires long-term collaborative development in various aspects, including computing, data, technology, talent, cooperation, and application.
What is Natural Language Processing? Natural Language Processing is the use of computers to process human language, enabling computers to possess human-like listening, speaking, reading, and writing abilities. It is one of the most critical cores of future artificial intelligence technology. Bill Gates once said, “Natural language processing is the jewel in the crown of artificial intelligence. If we can advance natural language processing, we can recreate a Microsoft.”
Difficulty: Considering NLP as the jewel in the crown of artificial intelligence, the difficulty is evident. Let’s look at the following example:

Words are exactly the same, but their meanings are completely opposite. Humans have common sense and background knowledge when understanding, so they can comprehend; however, computers lack common sense and background knowledge and only process based on the literal meaning, so they understand everything the same. This is the difficulty of natural language processing.

History: Natural language processing emerged with the advent of computers, initially creating rule-based systems, followed by statistical systems, and now neural network systems. China’s natural language processing is not late at all; as early as the founding of the country, there were people working on Russian-Chinese machine translation systems, followed by English-Chinese machine translation systems. I personally have had the fortune to witness the development of machine translation. During my graduate studies at Harbin Institute of Technology (under Professor Li Sheng, 1985), I was engaged in Chinese-English machine translation research, and the CEMT system I developed was the first officially certified Chinese-English machine translation system in China (1989). Later, I led the development of the Chinese-Japanese machine translation product J-Beijing at KDDI in Japan (1998). After joining Microsoft in 1999, I engaged in instance-based and statistical machine translation research, and in recent years, we have been working on neural machine translation research.
It can be said that China’s natural language processing has developed in sync with the world. Currently, I can responsibly say that China’s natural language processing is generally ranked second in the world, second only to the United States. Why has there been such good development? It is thanks to China’s 40 years of reform and opening up, the cooperation of major companies and many schools, and it is particularly worth noting that the cooperation between Microsoft Research and related schools has had a far-reaching impact. It is also due to the deep cultivation of various societies, including the CCF, in the field of NLP over the past few decades, hosting academic conferences (NLPCC has recently entered the CCF-international conference list) and various summer schools and workshops, promoting collaboration among schools, enterprises, and various organizations, and advancing research in a collaborative and platform-based manner.
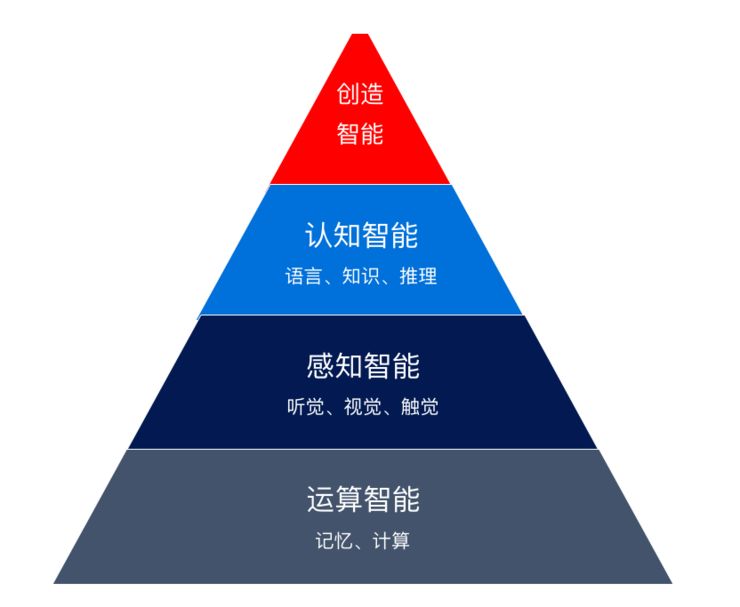
Positioning: Artificial intelligence is to use computers to achieve uniquely human intelligence. It enables computers to listen, speak, understand language, think, solve problems, and create. Specifically, it includes: computational intelligence, perceptual intelligence, cognitive intelligence, and creative intelligence. Computational intelligence refers to memory and computational capabilities, which computers have far surpassed humans. Perceptual intelligence refers to the ability of computers to perceive the environment, including hearing, vision, touch, etc., equivalent to human ears, eyes, and hands. Cognitive intelligence includes language understanding, knowledge, and reasoning. Creative intelligence embodies the intellectual process of utilizing experience to imagine, design, experiment, verify, and realize things that have not been seen or occurred. Currently, with the significant progress in perceptual intelligence, people’s focus has gradually shifted to cognitive intelligence. Among them, language intelligence, or natural language understanding, is considered the jewel in the crown. Once there is a breakthrough, it will significantly promote cognitive intelligence, enhance artificial intelligence technology, and facilitate its implementation in many important scenarios.
In the past few years, due to the increasing amount of data, various test sets have emerged; algorithms have become increasingly complex and advanced, including neural network architectures, pre-training models, etc.; and computational power has greatly improved. Under the influence of these three factors, natural language processing has developed rapidly.

Microsoft has made breakthrough progress in four typical NLP tasks. The first is chatbots, which can chat freely in Chinese, Japanese, and English for over 23 rounds, currently the best in the world. Our reading comprehension technology, machine translation technology, and grammar checking system are currently at the world-leading level under the current test sets, and have surpassed human annotation levels in the respective test sets.
Natural language has many applications, such as input methods, dictionaries, translations that we use every day, as well as sign language translation in collaboration with the Chinese Academy of Sciences, Bing’s voice assistant, Xiaoice, and natural language text generation, couplets, poetry, riddles, music, etc.
I would like to outline the technical system of neural network-based natural language processing.
First is word encoding. The purpose of word encoding is to represent the semantics of words using multi-dimensional vectors. How is this done? There are two famous methods: one is CBOW (Continuous Bag-of-Words), which predicts the current word using surrounding words; the other is Skip-gram, which predicts surrounding words using the current word. Through large-scale training, we can obtain a stable multi-dimensional vector for each word as its semantic representation.
With the semantic representation of words, we can further generate the semantic representation of sentences, also known as sentence encoding. This is generally done using RNN (Recurrent Neural Network) or CNN (Convolutional Neural Network). RNN models the sentence from left to right, with each word corresponding to a hidden state that represents the semantic information from the beginning of the sentence to the current word, and the final state represents the information of the entire sentence. CNN theoretically combines word embedding + position embedding + convolution with a vector representation corresponding to the sentence’s semantics.
Based on this representation, we can implement encoding and decoding mechanisms. For example, we can use the red dot on the graph, which represents the semantic information of the entire sentence, for decoding, transforming one language into another. Any transformation from one sequence to another can be executed through encoding and decoding mechanisms.
Subsequently, attention models were introduced. They comprehensively consider the weighted average of each hidden state corresponding to the encoded input at the current state to reflect the current dynamic input. After the introduction of this technology, neural network machine translation has developed rapidly.
Later, the Transformer was introduced. The Transformer incorporates self-encoding, allowing each word to establish similarity with surrounding words and introduces multi-head attention, which can incorporate multiple feature expressions, enriching the encoding effect or the information encoded.
Now everyone is pursuing pre-training models. There are several methods; the first is ELMo, which encodes the sentence from left to right and can also encode it from right to left. Each layer’s corresponding nodes combine to form the current word’s semantic representation in context. When used, this semantic representation is combined with the word’s embedding for subsequent tasks, resulting in improved performance.
Last October, BERT gained significant attention. It predicts the information of the outermost word using information from both the left and right sides, and it can also determine whether the next sentence is the true next sentence or a fabricated one, encoding each word in the sentence using two methods. The resulting training outcomes represent the semantic representation of each word in context. Based on this semantic representation, we can determine the relationship between two sentences, such as whether it is a subordinate relationship, classify a sentence (for example, in Q&A, determine whether the boundary of the response corresponds to the question), and label each word in the input, resulting in a part-of-speech tagging.
Pre-training models have attracted much attention. Initially, static word representations were developed, meaning that regardless of context, the representation remains the same. For example, the word “bank” has multiple meanings, and its representation is also the same. However, ELMo reflects its unique representation based on context. Following these methods, a series of new methods have been developed, such as GPT-2, and recently XLNET, UNILM, MASS, MT-DNN, and XLM, all based on this concept of expansion, each excelling at solving corresponding tasks. Among them, Microsoft Research’s UNILM can simultaneously train models similar to BERT and GPT, while Microsoft’s MASS achieves better results in machine translation using encoder-decoder training. MT-DNN emphasizes multi-task learning pre-training models, and XLM learns multilingual BERT models, demonstrating significant application effects in cross-language transfer learning. Many companies have made improvements to pre-training models, which I will not list one by one here.
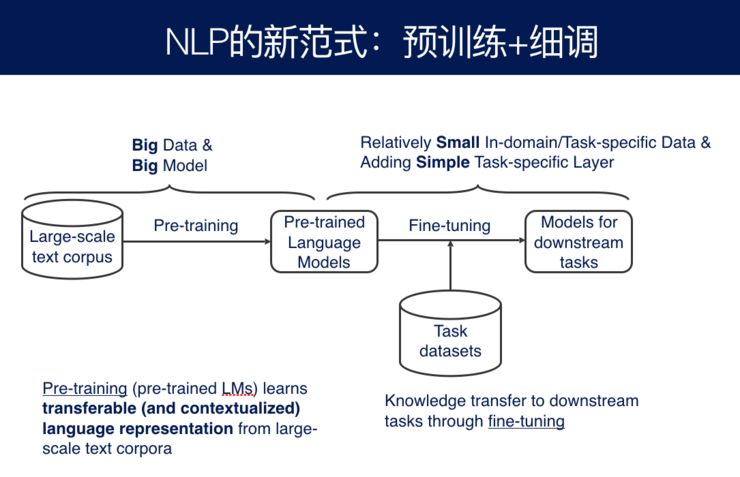
Now that pre-training models are prevalent, people are pondering whether natural language processing should adopt a new modality. In the past, we have always said to enrich the current input with knowledge-based methods, but we have never done particularly well in the past. However, this new pre-training model has given us a new inspiration:
We can pre-train a model on a large-scale corpus, which represents both the structural information of the language and possibly the information of the domain or even common sense, although we may not understand it. Coupled with our future predetermined tasks, which have only a small training sample, utilizing the pre-trained model obtained from large training samples on small training samples results in significantly improved performance.
Currently, NLP’s performance on many tasks has surpassed that of humans. It sounds like a bright future ahead; we just need to prepare the data, buy a lot of machines, and train without worrying too much. Thus, many people are competing for rankings, creating numerous models, data, and machines for new tasks, just to graduate.
However, I do not think so; rather, I have a strong sense of crisis.
Next, I will analyze the existing problems and how we should proceed.
The first issue is the endless arms race for computing resources. Now everyone is using large-scale machines for training; with the same algorithms, as long as the training speed is fast, you can iterate quickly, and your level will be higher than others. Simultaneously, this is particularly resource-intensive, and many models may take several days or cost tens of thousands of dollars to train. Sometimes it works, but sometimes it does not. For example:
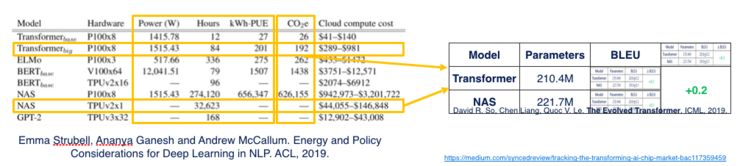
In this example, it used ten times the brute force but only achieved a 0.2% efficiency improvement. The extensive use of resources has led to environmental pollution. Recently, a popular paper online discusses this computational model. If we rely too much on computational power, it will have a significant impact on the environment.
The second issue is the over-reliance on data. First, you need to annotate data, which is very costly. Secondly, there are implicit biases in data; through data analysis, you may obtain discriminatory results. Additionally, data may have biases; when people annotate data, they tend to be lazy and seek the simplest methods for annotation, resulting in uniform annotated data. Models trained on such data can only solve the annotated data, and when applied to real tasks, they perform poorly due to differing distributions from the annotated data. For instance, in our Q&A system, we assume that all questions and answers are ranked first, but many simple questions cannot be solved on the search engine. Furthermore, there are issues regarding data privacy protection, etc.
Now, let’s take a step back and examine how neural networks perform on some typical tasks and what issues exist.
I have selected three typical problems. The first is Rich Resource Tasks, which have sufficient resources, such as Chinese-English machine translation, where there is a wealth of resources online. The second is Low Resource Tasks, which have few or no resources, such as Chinese to Hebrew translation, which has almost no resources. The third is Multi-turn Tasks, which refer to multi-round interactions, like customer service interactions. These three types of problems essentially represent the fundamental issues in natural language processing; if these three problems are well solved, natural language processing will be fundamentally resolved. Let’s see where these three problems currently stand.
For Rich Resource Tasks, we conducted an error analysis of Chinese-English neural machine translation. This is a result based on a large corpus training,
I have selected three typical problems. The first is Rich Resource Tasks, which have sufficient resources, such as Chinese-English machine translation, where there is a wealth of resources online. The second is Low Resource Tasks, which have few or no resources, such as Chinese to Hebrew translation, which has almost no resources. The third is Multi-turn Tasks, which refer to multi-round interactions, like customer service interactions. These three types of problems essentially represent the fundamental issues in natural language processing; if these three problems are well solved, natural language processing will be fundamentally resolved. Let’s see where these three problems currently stand.
For Rich Resource Tasks, we conducted an error analysis of Chinese-English neural machine translation. This is a result based on a large corpus training,
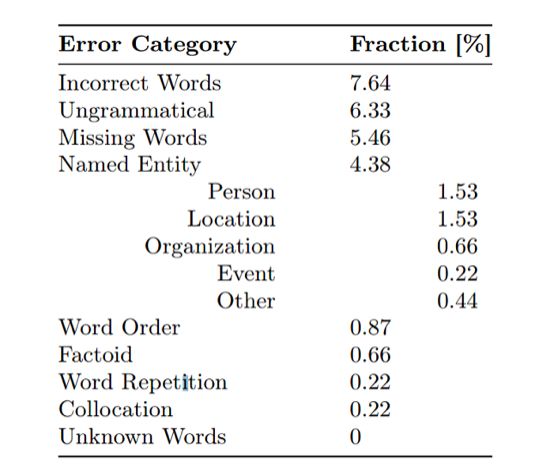
We can see that despite being based on a large corpus, there are still many errors in the translation, including incorrect translations, missing words, and grammatical issues.

For example, this “土方” is not “earth” but refers to “Turkey.” Because neural networks are currently non-interpretable, they are black boxes; you do not know where they went wrong; it could be a data issue or a model issue.

Idioms are also troublesome; even if you have learned many idioms, their translations need to change in new sentences, requiring dynamic calculations.
Thus, even in algorithms with sufficient resources, there remain numerous issues to research, such as word omissions, how to integrate dictionaries, how to make contextual judgments, and domain adaptation, etc. No one can claim that these issues can be resolved through Rich-Resource; there are contextual issues, data bias issues, multi-task learning, and human knowledge.
The second is Low Resource Tasks, where there is little corpus, making it difficult to learn, hence requiring assistance. There are three commonly used methods.
-
The first is transfer modeling, transferring learned content from other corpora. The most common transfer training is the pre-training model mentioned earlier, which is applied to the target task.
-
The second is cross-lingual learning, learning from other languages. For instance, English has a lot of corpora, and I can apply English training models to French and German, which is a popular method.
-
The third is using seeds for iterative learning; for example, if I have a small dictionary, a few rules, and some bilingual data, can I use it as a trigger for a cold start and iteratively improve afterwards?
Although we have conducted much research, we do not have a good solution for Low-Resource tasks. First, how to model Low-Resource tasks and how to perform unsupervised or semi-supervised learning from data analysis is still unanswered. How to perform Transfer Learning and Unsupervised learning is also a current challenge. Additionally, how to activate prior rule dictionaries for cold starts, and whether humans can participate in helping a weak initial system gradually become stronger are all hot topics that have yet to be solved well.
The third is Multi-turn Tasks (multi-round questions). Taking multi-turn dialogue as an example, we look at the following example:

We can see that for simple questions for children, the computer does not know how to respond. The reason is that current natural language processing has not yet effectively solved common sense and reasoning issues.
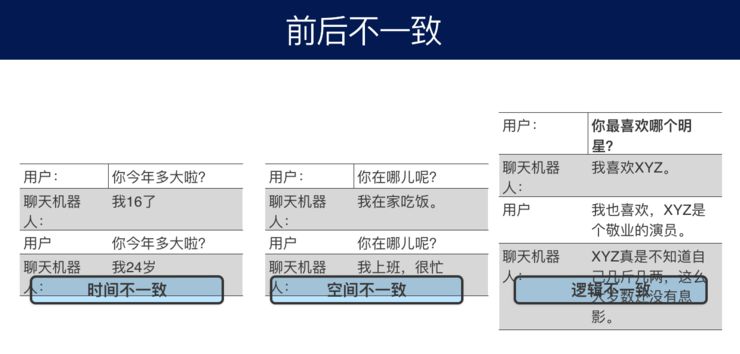
Moreover, there are issues of inconsistency and self-contradiction. For example, when a user asks, “How old are you today?” the chatbot might say, “I am 16.” A few days later, if the user asks again, “How old are you today?” it might say, “I am 24 years old,” thus being inconsistent. There are also spatial inconsistencies and logical inconsistencies. This requires that when humans converse with machines, there should be a memory system to store the features of what has been said, which can be extracted later to represent various aspects of the robot’s information.
Reasoning involves many tasks. First, it is essential to understand the context, remembering what has been said, what questions have been answered, and what actions have been taken. Second, various types of knowledge should be utilized. Only then can the reasoning part be executed, which involves semantic analysis, context reference resolution, and ellipsis resolution. Finally, there is also the issue of interpretability; if your reasoning is not interpretable, no one will believe it, leading to the system’s inability to advance further.
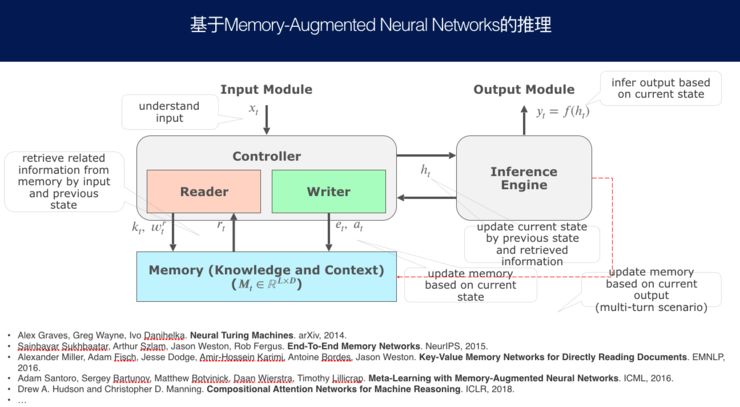
When we aim to perform reasoning, generally, we design such models. They possess memory to remember what has been said or what knowledge exists; they have a reading device and a writing device. When a question arises, after analysis, they retrieve the state and knowledge from memory, adjust the dialogue state, and update certain stored information in memory. After obtaining the answer, they also need to update their memory and storage.
What kind of natural language processing systems do we need in the future? I believe we need to create interpretable, knowledgeable, ethical, and self-learning NLP systems. This is a high goal, and we are currently far from achieving it.
How can we achieve such goals? We must start from specific tasks, identifying the existing problems. As I mentioned earlier, what issues exist in Rich-Resource? Context modeling, data correction, multi-task learning, and understanding human knowledge. What issues need to be resolved in Low-Resource? I have listed some problems. What issues need to be addressed in multi-turn? These include knowledge common sense, context modeling, reasoning mechanisms, interpretability, etc.
If we make progress, our cognitive intelligence will further enhance, including language understanding levels, reasoning levels, question-answering abilities, analytical abilities, problem-solving capabilities, writing abilities, and conversational abilities. Coupled with advancements in perceptual intelligence, such as sound, image, and text recognition and generation capabilities, as well as multi-modal text and image interactions—generating images from text and generating descriptive text from images—we can advance numerous human applications, including search engines, intelligent customer service, education, finance, e-commerce, and more. We can also apply AI technology to our industries to assist in achieving digital transformation.
Achieving this is not easy and requires comprehensive efforts from all aspects. Therefore, the future path of NLP needs collaboration from different companies, schools, governments, enterprises, and investors, etc.
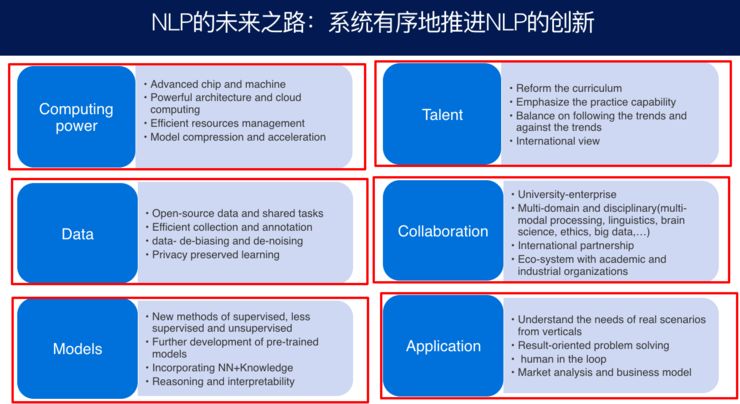
Here, I summarize six crucial perspectives.
The first is the capability of computers. As mentioned earlier, this includes chips, memory, cloud computing, and management, along with model compression and acceleration issues.
The second is data. Data is extremely important; the entire society must contribute its data, learning from each other and working together. There is also the critical aspect of learning under privacy protection.
The third is models. As previously discussed, there are supervised learning, unsupervised learning, semi-supervised learning, pre-training models, and how neural networks can integrate human knowledge and common sense, incorporating reasoning and interpretability into our learning systems.
The fourth is talent cultivation; we must rely on people to realize the overall process. How to cultivate talent? It is essential to emphasize practical experience, ensuring they have a strong practical awareness rather than just pushing formulas, and to have a logical understanding.
The fifth is collaboration: cooperation between schools and enterprises, interdisciplinary collaboration, national collaboration, and cooperation among the business sector, investment sector, and government to form an ecosystem where everyone benefits and progresses steadily.
The sixth is emphasizing applications; obtaining real data and user feedback through applications will improve our systems. Applications also enhance students’ practical skills and help us understand how humans and machines can complement and cooperate in a real system, achieving a bidirectional integration of artificial intelligence and human intelligence.
Thank you all!

Recommended Reading
▎Cutting Edge! Comprehensive Report on Robotics Research | CCF-GAIR 2019
▎ The Integration of “5G+AI+IoT” Redefines the 2019 Battlefield | CCF-GAIR 2019
▎Dr. Zhang Zhengyou from Tencent AI Lab & Robotics X: The Three Lives of Computer Vision | CCF-GAIR 2019
▎ Zheng Yu from JD City: AI and Big Data Will “Reshape Cities” | CCF-GAIR 2019
After this summit, we will launch the complete video and major thematic white papers of the CCF GAIR 2019 summit on 「AI Investment Research Alliance」, including cutting-edge robotics, intelligent transportation, smart city, AI chips, AI finance, AI healthcare, smart education, and more. Members of the “AI Investment Research Alliance” can watch the annual summit videos and research reports for free. Scan the code to enter the member page for more details.Enjoy a special discount of 399 yuan during the summit, which can be claimed directly on the page, or send a private message to Assistant Xiao Mu (WeChat: moocmm) for inquiries.(Last day, 50 spots available, hurry up.)