

Author | Howard Source | Zhihu
1. NLP’s Head Start
The history of NLP development is quite early, as the need for language processing has existed since the invention of computers. Various string algorithms have been intertwined with the history of computer development. The great Chomsky proposed generative grammar, which is the most basic framework for human language processing, along with automata (regular expressions), stochastic context-free parsing trees, string matching algorithms like KMP, and dynamic programming.
NLP tasks, such as text classification, matured very early, with spam classification being effectively handled using Naive Bayes. Twenty years ago, machine translation could be achieved through pure statistics and rules. In contrast, during that time, the MNIST classification in the CV field was still not well established.
In the 1990s, the development of information retrieval introduced a series of text matching algorithms like BM25, and the rise of search engines like Google pushed NLP to new heights, compared to the dim prospects in the CV field.
2. The Challenges of Feature Extraction in CV
The predecessor of CV was a field called image processing, which studied image compression, filtering, and edge detection, often involving a famous image of a beauty called Lenna.

In the early days of computer vision, the field was hindered by the difficulty of feature extraction, whether it was HOG or various handcrafted feature extractions, which did not yield very good results.
Large-scale commercial applications were quite challenging. Meanwhile, in NLP, handcrafted features combined with SVM were already thriving.
3. The Rise of Deep Learning – Automatic Feature Extraction
In recent years, the very popular deep learning models can be simply summarized as:
Deep Learning = Feature Extractor + Classifier
This suddenly solved the problem of difficulty in manual feature extraction in CV, leading to explosive progress in the field. The idea of deep learning is to allow the model to automatically learn feature extraction from data, thereby generating many features that are difficult for humans to extract:
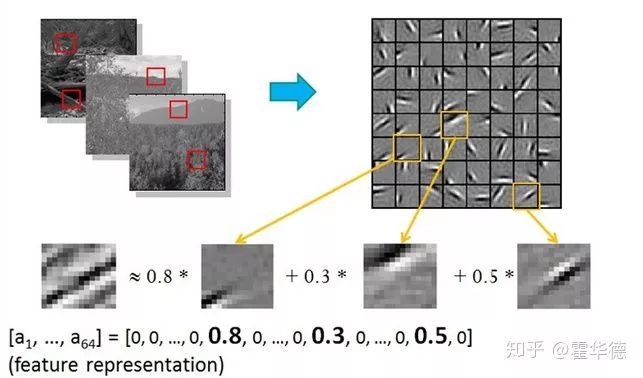
4. The Knowledge Dilemma in NLP
It is not that NLP has not made progress in this wave of deep learning, but the breakthroughs are not as substantial as in CV. For many text classification tasks, using a complex bidirectional LSTM may not yield significantly better results than using well-crafted features with SVM, while SVM is fast, compact, does not require large amounts of data, and does not need a GPU. In many scenarios, deep learning models are not necessarily better than traditional models like SVM or GBDT.
The greater challenge in NLP lies in the knowledge dilemma. Unlike the perceptual intelligence of CV, NLP involves cognitive intelligence, which inevitably involves knowledge issues, and knowledge is the most discrete and difficult to represent.
Recommended Reading:
[Tsinghua Liu Yang] 244-page Academic Paper Writing Methods and Techniques for Machine Translation
Google’s Global Strike! Covering Up Sexual Harassment by the ‘Father of Android’ Sparks Outrage, Employees Propose 5 Demands
LeetCode Problem Solving Guide: Burst Balloons
