

MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and researchers from companies.
The vision of the community is to promote the exchange between the academic and industrial circles of natural language processing and machine learning, as well as enthusiasts, especially for the progress of beginners.
This article is reprinted from | Jishi Platform
Author | Technology Beast
1
『Summary』
1
『Summary』
Transformer is a classic NLP model proposed by Google’s team in 2017, and the popular Bert is also based on Transformer. The Transformer model uses the Self-Attention mechanism, not adopting the sequential structure of RNN, allowing the model to be trained in parallel and to have global information.
Although Vision Transformers have made significant progress in various visual tasks, exploration of their architectural design and training process optimization is still quite limited. This article provides three suggestions for training Vision Transformers.
2
『3 Things You Should Know About Vision Transformers』
2
『3 Things You Should Know About Vision Transformers』

Paper Title: Three things everyone should know about Vision Transformers
Paper Link:
https://arxiv.org/pdf/2203.09795.pdf
Paper Interpretation:
Although Vision Transformers have made significant progress in various visual tasks, exploration of their architectural design and training process optimization is still quite limited. This article provides three suggestions for training Vision Transformers.
Suggestion 1: Achieve Lower Latency with Parallel Vision Transformers
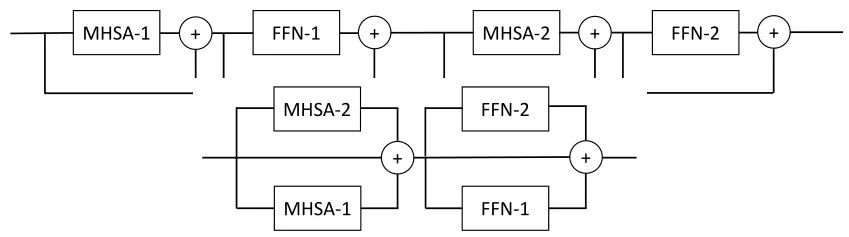
A shallower network architecture is easier to achieve lower latency and easier to optimize. Let MHSA represent the Multi-Head Self-Attention block and FFN represent the Residual Feed-Forward Network. As shown in Figure 1, the authors reorganized the model architecture in pairs, resulting in a wider and shallower architecture, with each parallel block having the same amount of parameters and computation. This design allows for more parallel processing, achieving lower latency and easier optimization.
Suggestion 2: Fine-Tune Only Attention for Good Transfer Performance
The standard method of transfer learning generally involves pre-training the model first, then transferring it to the target task. This situation applies when the dataset size of the target task is limited, or when the resolution of the target task differs from that of the pre-training task. Generally, the training resolution should be lower than the resolution used during inference. This not only saves resources but also reduces the ratio difference between training and testing images caused by Data Augmentation. The authors demonstrate in this article that in most ViT transfer learning scenarios, it is sufficient to only fine-tune the MHSA layer and freeze the parameters of the FFN layer, which can save computation and reduce memory peak during training without affecting accuracy.
Suggestion 3: Improve the ViT Patch Pre-Processing Layer for Better Adaptation to MIM-Based Self-Supervised Learning
The first layer of the Transformer generally has a small receptive field. Processing input images with a Convolutional Stem is beneficial for training stability. However, using convolution to preprocess images is incompatible with MIM-based self-supervised learning methods (such as BeiT[1], MAE[2], etc.). To adapt to MIM self-supervised learning methods, the authors propose a patch pre-processing method in this article.
Experiment Process
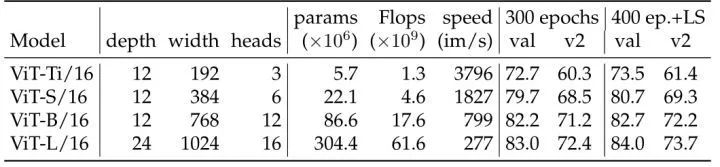
First, the authors ran some baseline experimental results, as shown in Figure 2. The resolution is 224×224, and LS represents Layer Scale. The learning rates are set to: ViT-Ti and ViT-S at 4e-3, and ViT-B and ViT-L at 3e-3.
Experiment Exploration 1: Achieve Lower Latency with Parallel Vision Transformers
In the ViT model, complexity metrics are affected by width and depth. Ignoring the initial image patching operation and the final classification head, as their impact on complexity is negligible, we have:
-
The number of parameters in the ViT model is proportional to the depth of the network and quadratically related to the width.
-
The computational load of the ViT model is proportional to the depth of the network and quadratically related to the width.
-
The memory peak during ViT inference does not change with the depth but is quadratically related to the width.
-
A wider architecture theoretically has better latency because it is more parallelized, but the actual acceleration depends on implementation and hardware.
The first experiment the authors conducted was to change the serial structure shown in Equation 1 to the parallel structure shown in Equation 2:
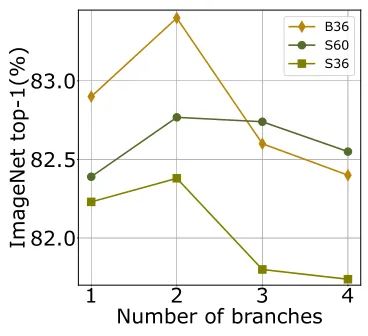
The following Figure 1 shows the impact of the number of branches on ViT performance. For both the Small model and the Base model, using two parallel branches achieves the best performance. The performance between ViT-S60’s S20×3 and S30×2 is comparable.
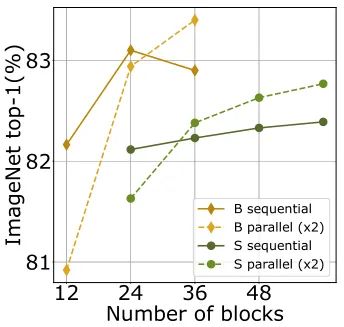
The following Figure 2 compares the performance of different model sizes using sequential and parallel structures. For both the Small model and the Base model, using two parallel branches achieves the best performance. The performance between ViT-S60’s S20×3 and S30×2 is comparable. The observations from the experiments are consistent with previous findings: the parallel version of the ViT model is helpful for deeper and higher-capacity models that are harder to optimize, and the proposed parallelization scheme makes the training of deep ViTs easier.
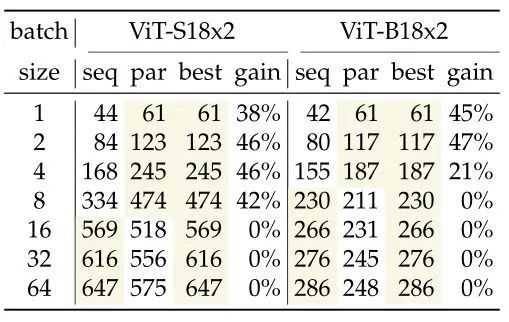
The following Figure 3 compares the processing speed of different model sizes using sequential and parallel structures. On V100 GPUs, the authors observed a significant speedup in single-sample processing, but when the batch size becomes larger, there is no increase in processing speed.
Experiment Exploration 2: Fine-Tune Only Attention for Good Transfer Performance
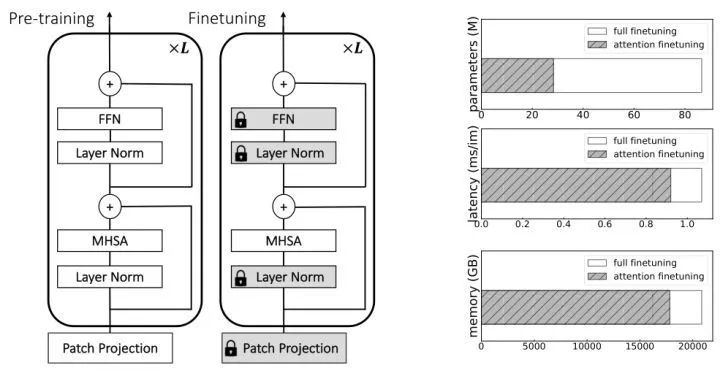
In this section, the authors focus on fine-tuning the ViT model to make it adapt to higher image resolutions or address different downstream classification tasks. Specifically, consider a method where only the weights of the MHSA layer are fine-tuned, as shown in Figure 4. The authors analyze the impact of this approach in terms of predictive accuracy, peak memory usage, and parameter count.
As shown in Figure 4, the authors fine-tuned the ViT-S, ViT-B, and ViT-L models pre-trained at 224×224 resolution at 384×384 resolution. It can be seen that whether on ImageNet-val or ImageNet-V2, the results of fine-tuning only the MHSA layer weights are very close to those of fine-tuning all weights. However, when only fine-tuning the FFN layer, the results differ significantly.

The advantage of fine-tuning the MHSA parameters at high resolution compared to fine-tuning all parameters is: significant savings in parameters, latency, and peak memory usage, as shown in Figure 5. Fine-tuning the MHSA can save 10% of memory on GPUs, which is particularly useful in situations where high-resolution fine-tuning requires more memory. Additionally, the training speed is also improved by 10% because fewer gradients are computed. Finally, the weights of the MHSA are approximately one-third of the total weights. Therefore, if multiple models are to be fine-tuned for different input resolutions, we can save 66% of storage space for each additional model.
Experiment Exploration 3: Improve ViT’s Patch Pre-Processing Layer for Better Adaptation to MIM-Based Self-Supervised Learning
The traditional ViT model performs the pre-processing (patching) operation on input images through a convolutional head, usually referred to as the Convolutional Stem. Although these pre-processing designs can improve accuracy or stability, there are still some issues. For example, how can the Patch pre-processing layer better adapt to MIM-based self-supervised learning, such as the BEiT paradigm?
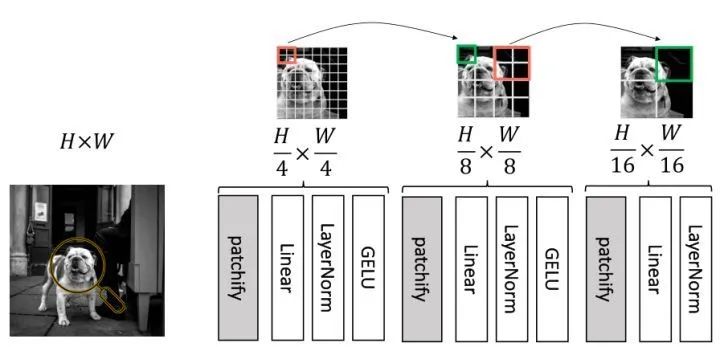
In this section, the authors designed a hierarchical MLP (hMLP) stem, i.e., a layered MLP pre-processing paradigm, as shown in Figure 6. The image is first divided into 4×4 sized patches, then merged twice in 2×2 regions, ultimately transforming the 224×224 sized image into a 14×14 feature. It can be seen that each 16×16 sized image patch is processed independently.
The specific implementation of hMLP is shown in Figure 7. The linear operations are specifically implemented using convolutions, with the parameters of the three convolutions being:

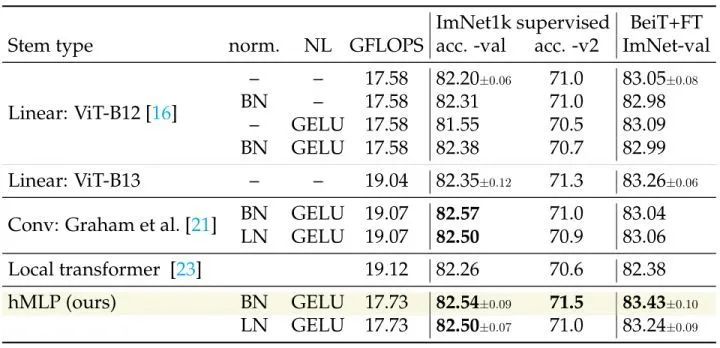
One benefit of hMLP is that this way of processing images allows for no correlation between the patches of the image. In other words, there is information exchange between different patches, which is not entirely equivalent to the original ViT. Moreover, the design of hMLP does not significantly increase computational demands. For example, the FLOPs required for ViT-B is only 17.73 GFLOPs. Compared to using a typical linear projection, it only increases computational load by less than 1%.
The authors compared several stems in supervised learning tasks and BEiT’s self-supervised learning tasks in Figure 8. hMLP also achieved better accuracy-computation balance.
3
『Conclusion』
3
『Conclusion』
This article introduces three different themes of ViT. First, a simple and effective parallelization method that can save inference latency. Second, when performing transfer learning tasks, fine-tuning only the parameters of the MHSA can achieve good performance while saving training memory usage. Finally, a patching method: hMLP, which can adapt well to MIM-based self-supervised learning methods, ensuring that information between different patches does not interact.
References
-
BEiT: BERT pre-training of image transformers -
Masked autoencoders are scalable vision learners

Scan the QR code to add assistant WeChat
About Us
