
Author|Hong Dou Jun
Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/429061708
This article is for academic sharing only. If there is any infringement, please contact the backend for deletion.
Residuals
BatchNorm normalizes each feature within a batch-size sample, while LayerNorm normalizes all features of each sample.
To illustrate, suppose there is a two-dimensional matrix. The rows represent batch-size and the columns represent sample features. Then, BN normalizes vertically, while LN normalizes horizontally.
Their starting point is to stabilize the parameters of the layer to avoid gradient vanishing or explosion, facilitating subsequent learning. However, they also have different focuses.
Generally speaking, if your features depend on statistical parameters across different samples, BN is more effective because it eliminates the size relationship between different features while retaining the size relationship between different samples (in the CV field).
In the NLP field, LN is more suitable because it eliminates the size relationship between different samples while retaining the size relationship between different features within a sample. For NLP or sequence tasks, the different features of a sample actually represent the temporal variation of character values, and the relationships among features within a sample are very tight.
It allows the use of larger learning rates, accelerating training. It has a certain anti-overfitting effect, making the training process smoother.
It is somewhat similar to multiple convolutional kernels in CNN. Through the mapping of three linear layers, the Q, K, and V in different heads are different, and the weights of these three linear layers are initialized and then learned. Different weights can capture different correlations in the sequence.
It is an autoregressive model.
Autoregressive means using the characters predicted by itself to predict the following information. During the prediction phase (in machine translation tasks), the Transformer first predicts the first character, and then predicts the subsequent characters based on the first predicted character, making it a typical autoregressive model. The Mask task in BERT is a typical autoencoding model, which predicts the current information based on the context characters.
When the values are particularly small, it actually doesn’t matter whether to divide or not. Whether in the encoder or decoder, the Q, K matrices are essentially the same matrix. The multiplication of Q and K is essentially equal to Q multiplied by the transpose of Q, which can lead to results that are too large or too small. If the result is small, it’s manageable; if large, it will amplify during the subsequent softmax, causing gradient vanishing, which is detrimental to gradient backpropagation.
To prevent the weights of the embedding layer from being too small, multiplying by √d_model ensures that they are comparable to the positional encoding values, thus preserving the original vector space.
Transformers are parallel during training and sequential during validation. This question examines the same knowledge point as whether Transformers are autoregressive models.
For specific details, refer to this article.
Hong Dou Jun: How Do the Encoder and Decoder Work During Training and Evaluation in Transformers? 11 Likes · 12 Comments
n is the sequence length, and d is the embedding length. The largest computational cost in Transformers comes from the multi-head self-attention layer, where the main computation is the multiplication of Q and K followed by V, i.e., two matrix multiplications. The multiplication of Q and K is a matrix of [n d] multiplied by [d n], resulting in complexity.
There are three multi-head self-attention layers in the Transformer, one in the encoder and two in the decoder.
The role of the multi-head self-attention layer in the encoder is to integrate the original text sequence information, where each character in the transformed text sequence is related to the information of the entire text sequence (this is also the most innovative idea in Transformers; however, according to recent review studies, while Transformers perform very well, the multi-head self-attention layer does not contribute overwhelmingly). The schematic diagram is as follows:
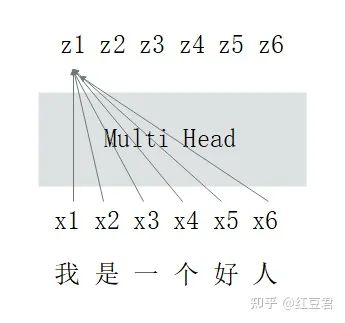
The first multi-head self-attention layer in the decoder is special; the original paper names it Masked Multi-Head Attention. It serves the purpose of integrating input text (for translation tasks, the encoder’s input is the text before translation, and the decoder’s input is the text after translation). Another task is masking to prevent information leakage. To elaborate, during information integration, the first character should not see the subsequent characters, the second character can only see the first and second characters’ information, and so on.
The second multi-head self-attention layer in the decoder functions identically to the first multi-head self-attention layer in the encoder. However, it is important to emphasize that the inputs are known; the multi-head self-attention layer integrates information by calculating the Q, K, and V matrices. Here, Q is the information integrated by the decoder, while the K and V matrices are the information integrated by the encoder, which are identical matrices. The multiplication of the Q and KV matrices allows for sufficient interaction and integration between the text before and after translation. The resulting vector matrix is then used for subsequent downstream tasks.
It has two functions.
-
To pad sequences of unequal lengths.
-
Masking to prevent information leakage.
Refer to question eleven.
The first function of the mask mechanism is used in all three multi-head self-attention layers, while the second function is only used in the first multi-head self-attention layer of the decoder.
Invitation to Technical Communication Group

Scan the QR code to add the assistant on WeChat.