Madio.net
Mathematics China
/// Editor: Mathematics China Qianxia
Since thoroughly understanding the Self_Attention mechanism, the author’s understanding of the Transformer model has risen directly from the underground to the atmosphere, and the meridians have been opened. Before going to sleep every night, that gentle phrase “Attention is all you need” often echoes in my ears, and I can’t help but applaud. Driven by adrenaline, I stayed up all night and finally implemented the Transformer model.
1. Model Overview
Before explaining the code, let’s first release this classic model architecture diagram. In the following content, I will explain the implementation ideas of each module and my insights during the coding process. Readers without a coding background need not panic; I only just started recently, and the Pytorch code I wrote is straightforward, with variable names kept as consistent with the paper as possible, making it very friendly for beginners.
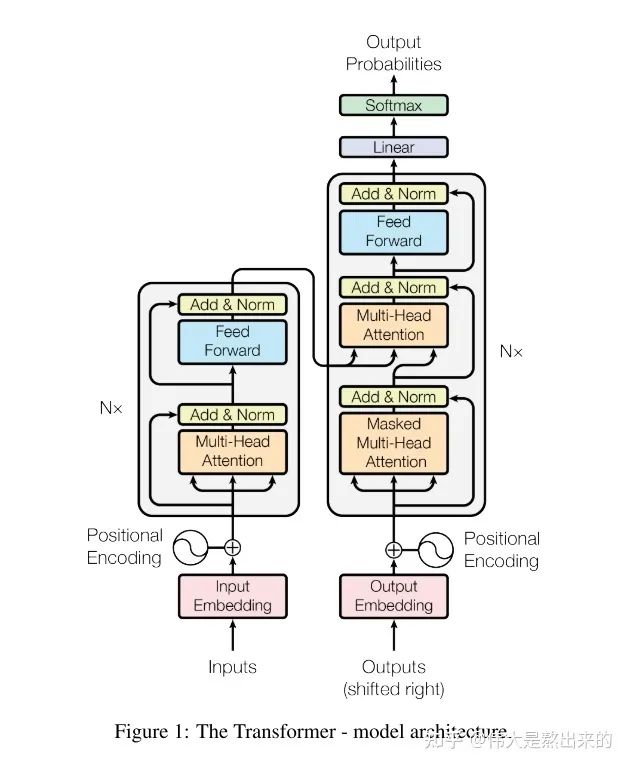
Looking at the model structure diagram, what modules does the Transformer model contain? I have divided it into the following parts:
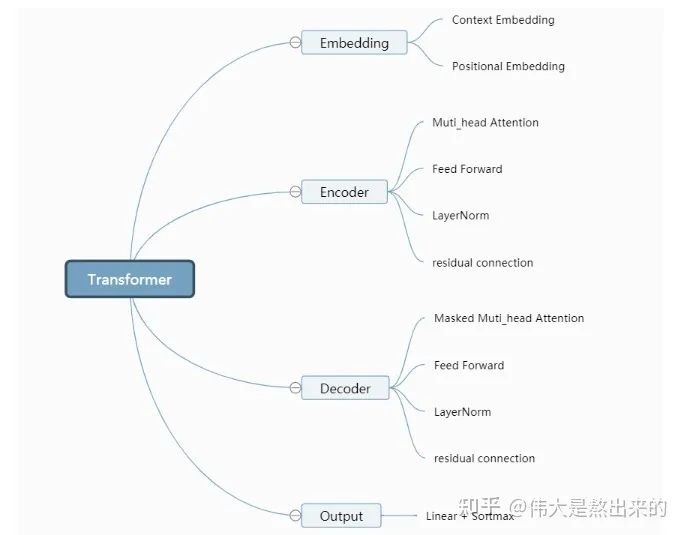
Next, we will explain each part one by one and finally piece together the model reproduction.
2. Config
Below are the library files and some hyperparameter information used in this Demo. The reason for implementing a separate Config class is to facilitate future reuse. Just copy the model part, and the used hyperparameters can be saved in the Config class of the new project. I won’t elaborate further here.
import torch
import torch.nn as nn
import numpy as np
import math
class Config(object):
def __init__(self):
self.vocab_size = 6
self.d_model = 20
self.n_heads = 2
assert self.d_model % self.n_heads == 0
dim_k = d_model % n_heads
dim_v = d_model % n_heads
self.padding_size = 30
self.UNK = 5
self.PAD = 4
self.N = 6
self.p = 0.1
config = Config()3. Embedding
The Embedding part accepts the raw text input (batch_size*seq_len, e.g., [[1,3,10,5],[3,4,5],[5,3,1,1]]), adds a normal Embedding layer and a Positional Embedding layer, and outputs the final result.
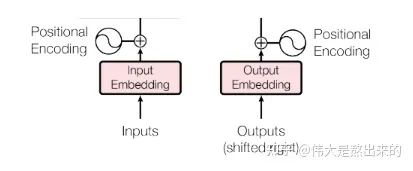
In this layer, the input is a list: [batch_size * seq_len], and the output is a tensor: [batch_size * seq_len * d_model]
Regarding the normal Embedding layer, I want to mention two points:
-
Using torch.nn.Embeddingto implement the embedding operation. One point to note is the Mask mechanism mentioned in the paper, including padding_mask and sequence_mask (for details, please refer to the theoretical explanation provided at the beginning of the article). Before the text input, we need to pad to a uniform length, and the implementation of padding_mask can utilize thepadding_idxparameter intorch.nn.Embedding. -
During padding, shorter sequences are padded to longer ones.
class Embedding(nn.Module):
def __init__(self,vocab_size):
super(Embedding, self).__init__()
# A normal embedding layer, we can implement the padding_mask in the paper by setting padding_idx=config.PAD
self.embedding = nn.Embedding(vocab_size,config.d_model,padding_idx=config.PAD)
def forward(self,x):
# Padding according to the length of each sentence, shorter ones are padded to longer ones
for i in range(len(x)):
if len(x[i]) < config.padding_size:
x[i].extend([config.UNK] * (config.padding_size - len(x[i]))) # Note that UNK is the token index used in your vocabulary to represent oov, simplified here, directly assumed to be 6
else:
x[i] = x[i][:config.padding_size]
x = self.embedding(torch.tensor(x)) # batch_size * seq_len * d_model
return xRegarding Positional Embedding, we need to refer to the formulas given in the paper. As a side note, in the author’s experiments, a comparison was made between Positional Embedding and using a single Embedding to train the model for position perception, and the model performance was similar.
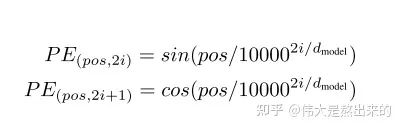
class Positional_Encoding(nn.Module):
def __init__(self,d_model):
super(Positional_Encoding,self).__init__()
self.d_model = d_model
def forward(self,seq_len,embedding_dim):
positional_encoding = np.zeros((seq_len,embedding_dim))
for pos in range(positional_encoding.shape[0]):
for i in range(positional_encoding.shape[1]):
positional_encoding[pos][i] = math.sin(pos/(10000**(2*i/self.d_model))) if i % 2 == 0 else math.cos(pos/(10000**(2*i/self.d_model)))
return torch.from_numpy(positional_encoding)4. Encoder
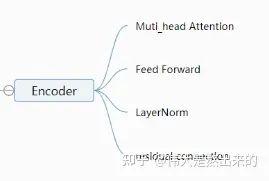
Muti_head_Attention
This part is the core content of the model, and I won’t elaborate on the theoretical part; readers can refer to the first link at the beginning of the article, which contains the basic code implementation.
The Muti_head_Attention in the Encoder does not require a Mask, so it is the same as the implementation in our previous article.
To avoid information leakage in the model, the Muti_head_Attention in the Decoder requires a Mask. In this section, we will focus on the implementation of the Mask mechanism in Muti_head_Attention.
If readers have read our previous article, they will notice a small difference in the code below, mainly reflected in the parameters of the forward function.
-
The parameter of the forwardfunction changes from x to x,y: please observe the model architecture; the Decoder needs to accept the input from the Encoder asVin the formula, which is y in our parameters. In a normal self-attention mechanism, we simply sety=x. -
requires_mask: whether to use the Mask mechanism, set to True in the Decoder
class Mutihead_Attention(nn.Module):
def __init__(self,d_model,dim_k,dim_v,n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model,dim_k)
self.k = nn.Linear(d_model,dim_k)
self.v = nn.Linear(d_model,dim_v)
self.o = nn.Linear(dim_v,d_model)
self.norm_fact = 1 / math.sqrt(d_model)
def generate_mask(self,dim):
# This is the sequence mask to prevent the decoder from peeking at future time steps.
# The padding mask is completed before the data is input to the model.
matirx = np.ones((dim,dim))
mask = torch.Tensor(np.tril(matirx))
return mask==1
def forward(self,x,y,requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# Self-attention on x
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
# print("Attention V shape : {}".format(V.shape))
attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
if requires_mask:
mask = self.generate_mask(x.shape[1])
attention_score.masked_fill(mask,value=float("-inf")) # Note the small trick here, we only need to MASK the result before Softmax
output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
# print("Attention output shape : {}".format(output.shape))
output = self.o(output)
return outputFeed Forward
 img
img
This part is very simple to implement, just connect two Linear layers with ReLU to add non-linear information to the model and improve its fitting ability.
class Feed_Forward(nn.Module):
def __init__(self,input_dim,hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.L1 = nn.Linear(input_dim,hidden_dim)
self.L2 = nn.Linear(hidden_dim,input_dim)
def forward(self,x):
output = nn.ReLU()(self.L1(x))
output = self.L2(output)
return outputAdd & LayerNorm
This section implements the residual connection and LayerNorm proposed in the paper.
The paper provides formulas for this part:

The dropout in the code is also explained in the paper, applying dropout to the tensor input to layer_norm has a significant impact on the model’s performance.
The parameter sub_layer in the code can be either Feed Forward or Muti_head_Attention.
class Add_Norm(nn.Module):
def __init__(self):
self.dropout = nn.Dropout(config.p)
super(Add_Norm, self).__init__()
def forward(self,x,sub_layer,**kwargs):
sub_output = sub_layer(x,**kwargs)
# print("{} output : {}".format(sub_layer,sub_output.size()))
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.size()[1:])
out = layer_norm(x)
return outOK, we have explained all the modules in the Encoder, and next we will piece them together as the Encoder.
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x): # batch_size * seq_len and x is not a tensor, it is a normal list
x += self.positional_encoding(x.shape[1],config.d_model)
# print("After positional_encoding: {}".format(x.size()))
output = self.add_norm(x,self.muti_atten,y=x)
output = self.add_norm(output,self.feed_forward)
return output5. Decoder
In the explanation of the Encoder part, we have already implemented most of the Decoder modules. The Muti_head_Attention in the Decoder introduces the Mask mechanism, and the way the Decoder and Encoder modules are pieced together is different. Readers need to pay attention to these two points during coding.
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x,encoder_output): # batch_size * seq_len and x is not a tensor, it is a normal list
# print(x.size())
x += self.positional_encoding(x.shape[1],config.d_model)
# print(x.size())
# First sub_layer
output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
# Second sub_layer
output = self.add_norm(output,self.muti_atten,y=encoder_output,requires_mask=True)
# Third sub_layer
output = self.add_norm(output,self.feed_forward)
return output6. Transformer
At this point, all content has been laid out, and we can start assembling the Transformer model. The paper mentions that the Transformer stacks 6 of the Encoder and Decoder we implemented above. Here, I use nn.Sequential to achieve the stacking operation.
The implementation of the Output module’s Linear and Softmax is also included in the code below.
class Transformer_layer(nn.Module):
def __init__(self):
super(Transformer_layer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self,x):
x_input,x_output = x
encoder_output = self.encoder(x_input)
decoder_output = self.decoder(x_output,encoder_output)
return (encoder_output,decoder_output)
class Transformer(nn.Module):
def __init__(self,N,vocab_size,output_dim):
super(Transformer, self).__init__()
self.embedding_input = Embedding(vocab_size=vocab_size)
self.embedding_output = Embedding(vocab_size=vocab_size)
self.output_dim = output_dim
self.linear = nn.Linear(config.d_model,output_dim)
self.softmax = nn.Softmax(dim=-1)
self.model = nn.Sequential(*[Transformer_layer() for _ in range(N)])
def forward(self,x):
x_input , x_output = x
x_input = self.embedding_input(x_input)
x_output = self.embedding_output(x_output)
_ , output = self.model((x_input,x_output))
output = self.linear(output)
output = self.softmax(output)
return outputSource: Artificial Intelligence Technology
Click below
Follow us
— THE END —