
Author: Jay Chou from Manchester

Introduction:
Since OpenAI launched the Chat GPT series, it has marked an important milestone in natural language processing technology—the explosion of large models LLM (Large Language Model). Although OpenAI provides functionality for document uploads and fine-tuning, the cost remains too high for impoverished users.
Thus, the open-source community has seen a variety of large models flourish, among which the most popular and extensively fine-tuned models are the LLAMA (Large Language Model Meta AI) series launched by Meta. As a representative of decoder-only structures, not only the base LLAMA series models but also the fine-tuned models including Alpaca, Vicuna, Koala, and Luotuo demonstrate domain adaptability and good performance.
This article will focus on the improvements of the LLAMA series, hoping that readers can quickly understand the enhancements made in this series through this article.©️【Deep Blue AI】Original


① Filtering out low-quality data ② Data deduplication ③ Data diversity
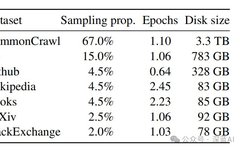
 ▲Figure 1|Distribution Table of LLaMa1 Pre-training Data ©️【Deep Blue AI】
▲Figure 1|Distribution Table of LLaMa1 Pre-training Data ©️【Deep Blue AI】■Improvement 2: Pre-normalization
The authors of RMS Norm believe that this pattern simplifies the computation of Layer Norm and can reduce computation time by approximately 7% to 64%. The relevant formula is as follows:
■Improvement 3: SwiGLU Activation Function

■Summary 1
The LLAMA1 series is the first series launched by LLAMA, which has influenced the entire open-source community since its release. It has introduced four models of different parameter sizes: 7B, 13B, 33B, and 65B, proving that LLaMA-13B outperforms GPT-3 (175B) in most tasks. The performance of LLaMA-65B can rival the best language models, such as Chinchilla-70B and PaLM-540B. The highlights of its performance fully demonstrate the importance of high-quality data rather than simply stacking network depth and parameter quantity.
Prior to LLaMA1, major companies primarily focused on increasing network depth and layers, but LLaMA instilled the core idea that optimal performance under a given computational budget is not achieved by the largest model but by smaller models trained on more data. The emphasis is on training a series of language models to achieve optimal performance under various inference budgets by using more tokens for training, rather than the usual quantity. The goal of LLaMA is to provide a series of possibly best-performing LLMs by training on ultra-large-scale data. This also lays the groundwork for the subsequent release of LLaMa2.

Paper Address: https://arxiv.org/abs/2307.09288
Project Address: https://github.com/meta-llama/llama
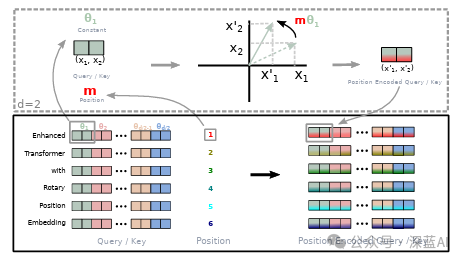
LLaMa2 has only released three models of different weights: 7B, 13B, and 70B versions. However, Meta AI continued to apply the experiences gained from LLaMa1 to LLaMa2. The network structure of LLaMa2, as shown in Figure 4, is also a decoder-only based transformer structure, consisting of 32 blocks, indicating that its overall structure is quite similar to LLaMa1, such as:
● On the basis of LLaMa1, the pre-training data was increased by 40%, mainly cleaning up some privacy data and enhancing knowledge to improve data quality;
● RMSNorm continues to be used in each block input layer;
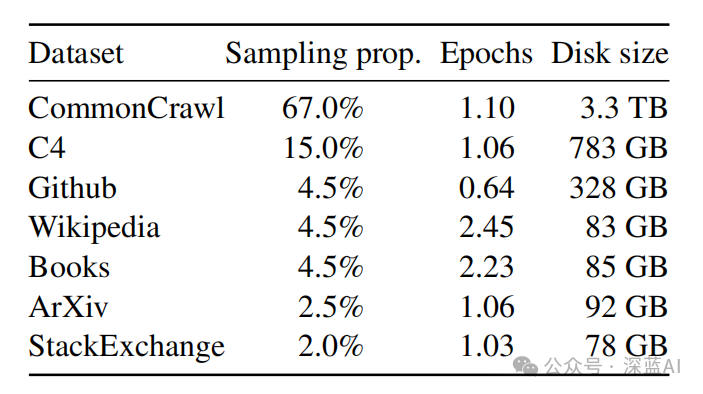
● RoPE position encoding continues to be used.
 ▲Figure 4|LLaMa2 Network Structure ©️【Deep Blue AI】
▲Figure 4|LLaMa2 Network Structure ©️【Deep Blue AI】In addition to continuing some improvements from LLaMa1, LLaMa2 also made some enhancements. Since the improvements of LLaMa have been emphasized above, the repetitive parts will not be reiterated here. The following will focus on the improvements specific to LLaMa2.
■Improvement 1: Grouped-query Attention
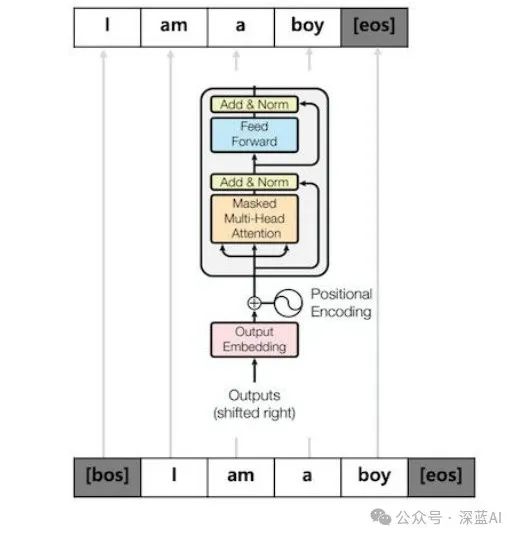
Before introducing GQA, it is necessary to lay out the basic concepts of the output method of autoregressive models and KV cache. As shown in Figure 5, it shows the output method of a typical decoder-only autoregressive model. An autoregressive model uses its output results as input for further output (though it sounds convoluted, that is precisely the meaning).
In simple terms, when we use LLaMa or GPT autoregressive models, we know that it outputs one character at a time rather than generating all answers at once. This reveals its output mechanism. As shown in the following diagram, when I input “one two three four five” into the model, it will generate an extra character the first time, and then the output of that extra character will be used as input to get the second output, and so on… until the model receives the special symbol
In [1]: {prompt:"one two three four five,"}
Out [1]: one two three four five, up
In [2]: one two three four five, up
Out [2]: one two three four five, up the mountain
In [3]: one two three four five, up the mountain
Out [3]: one two three four five, up the mountain to beat
In [4]: one two three four five, up the mountain to beat
Out [4]: one two three four five, up the mountain to beat the old
In [5]: one two three four five, up the mountain to beat the old
Out [5]: one two three four five, up the mountain to beat the old tiger
In [6]: one two three four five, up the mountain to beat the old tiger
Out [6]: one two three four five, up the mountain to beat the old tiger<eos>
Repeating the above process, it is not difficult to see that although the answer only generated five characters, it went through six iterations. For instance, the earliest prompt was repeated six times in the same matrix computation, so there is no need to perform Attention calculations on previous tokens again, which can save a lot of computational power.
The KV cache method is designed to address the above issue: by caching the K and V computed each time, when a new sequence comes in, it only needs to read the previous KV values from the KV cache without recalculating the previous KV.
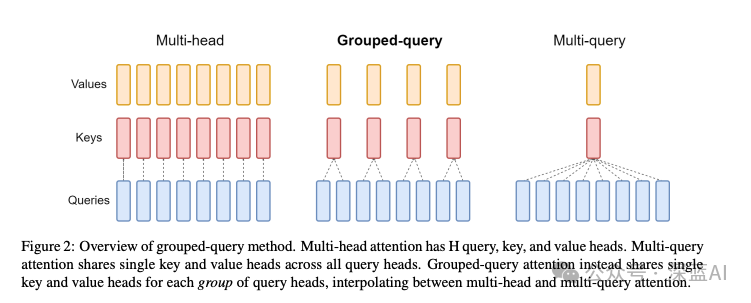 ▲Figure 6|Mechanism of MHA, GQA, and MQA ©️【Deep Blue AI】
▲Figure 6|Mechanism of MHA, GQA, and MQA ©️【Deep Blue AI】While the KV cache method is theoretically sound, in practice, the significant data caching and communication capabilities of hardware impose high pressure. Therefore, the GQA (grouped-query attention) algorithm optimizes from the software side. As shown in Figure 6, the following compares three self-attention mechanisms, where GQA is the mechanism of LLaMa2, while MQA is the computation mechanism of LLaMa1. So why transition from the original MHA to MQA and then to GQA?
In the original MHA (Multi-Head Attention), the Q, K, and V parts have the same number of heads and correspond one-to-one. Each time Attention is performed, head1’s QKV can perform its calculations independently, and the outputs are simply summed. MQA (Multi-query Attention), on the other hand, retains the original number of heads for Q, but has only one K and V, meaning all Q heads share a set of K and V heads, hence the term Multi-Query. Experiments have shown that this generally improves computational performance by 30%-40%, though performance accuracy may decline. GQA achieves a trade-off in performance and computation by grouping a certain number of heads to share a set of KV, thus not significantly reducing precision like MQA while improving speed compared to NHA.
■Improvement 2: SiLu Activation Function
Compared to the SwiGLU function, a simpler SiLU function is used here (the author believes that this comparison indicates minimal performance differences between SwiGLU and SiLU; if there are any doubts, please feel free to point this out), with the relevant formula as follows:
The LLaMa series is the strongest model open-sourced by Meta, especially LLaMa2, which dominated all open-source models at the time of its release with a 70B model, ranking first among open-source models. The two generations of LLaMa2 models share similarities while also featuring numerous improvements worth further research:
●The importance of high-quality datasets (broad and precise)
●RoPE provides a solution for relative position encoding
●GQA replaces NHA and MQA to achieve a trade-off between performance and speed
●NMSNorm and SiLu activation function improvements
The LLaMA series models have made significant progress in the field of NLP due to their high quality, scalability, and flexibility. Through continuous technological innovation and optimization, the LLaMA models have demonstrated outstanding performance across various tasks, marking an important milestone in large language model research and application. As model parameter scales continue to expand and training techniques advance, the LLaMA series models will continue to play a vital role in the field of natural language processing.

Diffusion models’ innovative applications in point cloud data
2024-03-29
TimesFM’s basic model dazzles, leading time series forecasting into a new era
2024-03-24

【Deep Blue AI】 is long-term recruiting authors, welcoming anyone who wants to transform their research and technical experiences into writing to share with more readers! If you wish to join, please click the tweet below for details👇

The author team of Deep Blue Academy is strongly recruiting! We look forward to your joining.

【Deep Blue AI】‘s original content is created with the authors’ personal efforts. We hope everyone respects the original rules and cherishes the authors’ hard work. For reprints, please contact the background for authorization and be sure to indicate that it comes from【Deep Blue AI】WeChat public account; otherwise, legal action will be taken for infringement.
*Click to view, save, and recommend this article*