MLNLP community is a well-known machine learning and natural language processing community at home and abroad, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning at home and abroad, especially for beginners.Reprinted from | DataWhaleEditor | Jishi PlatformAuthors | Zhang Fan, Chen Andong
Introduction
In the field of AI, the development of large models is pushing the boundaries of technology at an unprecedented speed.On April 19, 2023, Beijing time, Meta officially announced Llama-3 on its website. As the third generation model following Llama-1, Llama-2, and Code-Llama, Llama-3 has achieved comprehensive leading performance in multiple benchmark tests, surpassing the industry’s most advanced models.Looking at the Llama series models, from version 1 to 3, they showcase the evolution of large-scale pre-trained language models and their significant potential in practical applications. These models not only continuously break records technically but also have a profound impact on both the commercial and academic fields. Therefore, a systematic comparison of the different versions of the Llama model can reveal specific details of technological advancements and help us understand how these advanced models solve complex real-world problems.This text will detail the evolutionary history of the Llama open-source family, including:
The Evolution of Llama (Section 1)
Model Architecture (Section 2)
Training Data (Section 3)
Training Methods (Section 4)
Performance Comparison (Section 5)
Community Ecology (Section 6)
Conclusion (Section 7)
1. The Evolution of Llama
This section will provide a brief introduction to each version of the Llama model, including their release dates and main features.
1.1 Llama-1 Series
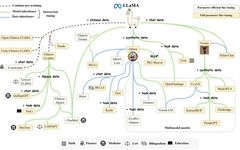
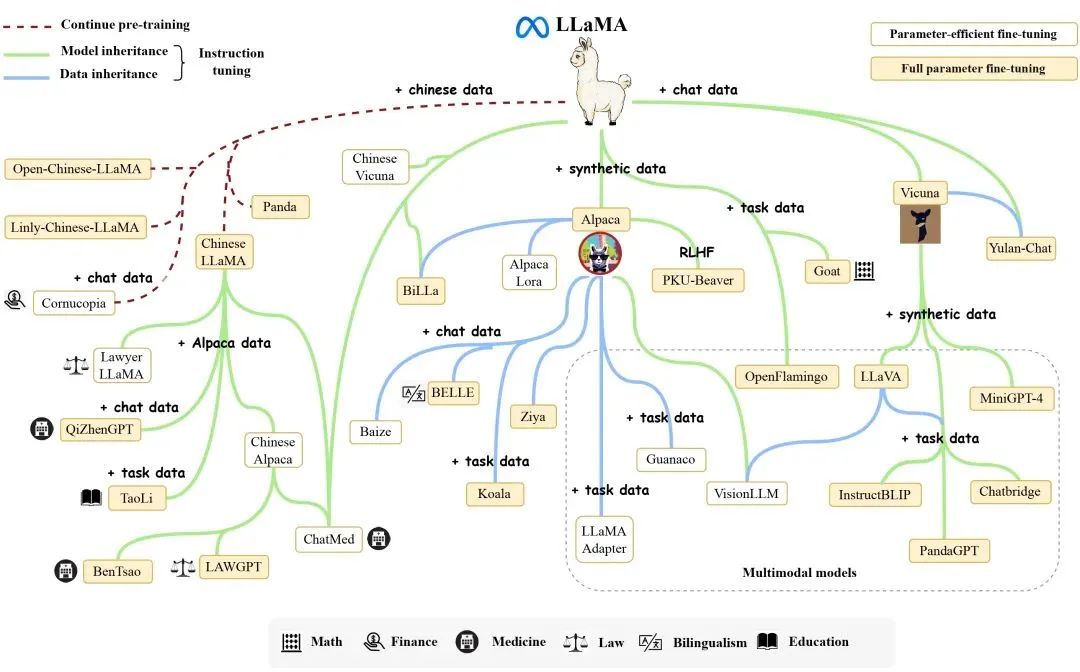
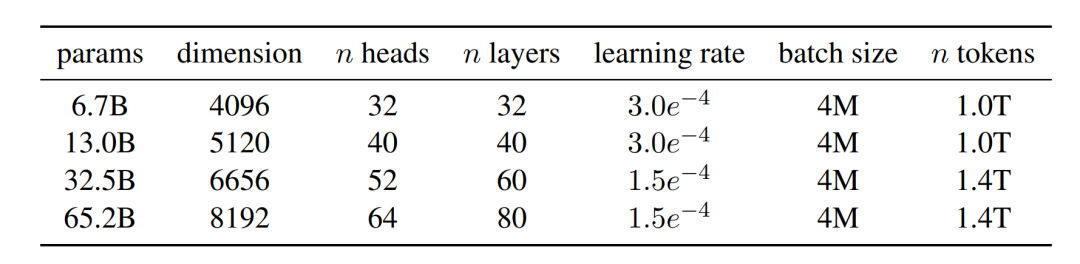
Llama-1 [1] is a large language model released by Meta in February 2023, and it was one of the most outstanding open-source models at that time, with parameter versions of 7B, 13B, 30B, and 65B. Each version of Llama-1 was pre-trained on a corpus of over 1T tokens, with the largest 65B parameter model trained on 2,048 A100 80G GPUs for nearly 21 days, surpassing the 175B parameter GPT-3 in most benchmark tests.Due to its open-source nature and excellent performance, Llama quickly became one of the most popular large models in the open-source community, leading to the rise of an ecosystem centered around Llama. We will provide a detailed introduction to this ecosystem in Section 6. Meanwhile, many researchers used it as a base model for further pre-training or fine-tuning, resulting in numerous variant models (see the figure below), greatly advancing research in the field of large models.The only downside is that due to open-source licensing issues, Llama-1 cannot be used commercially for free.
1.2 Llama-2 Series
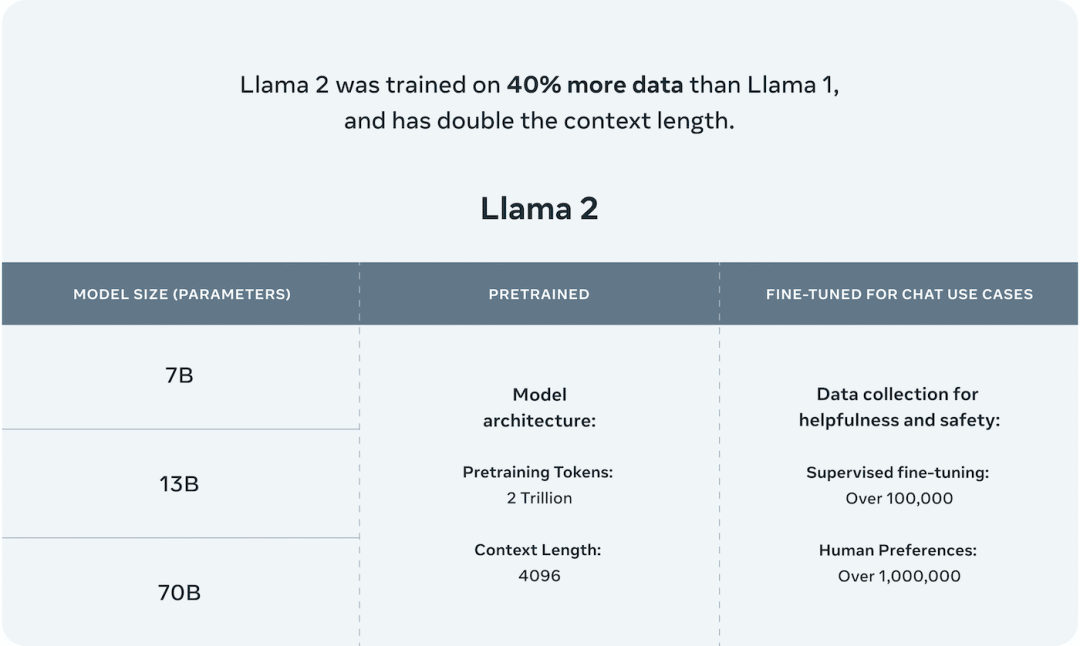
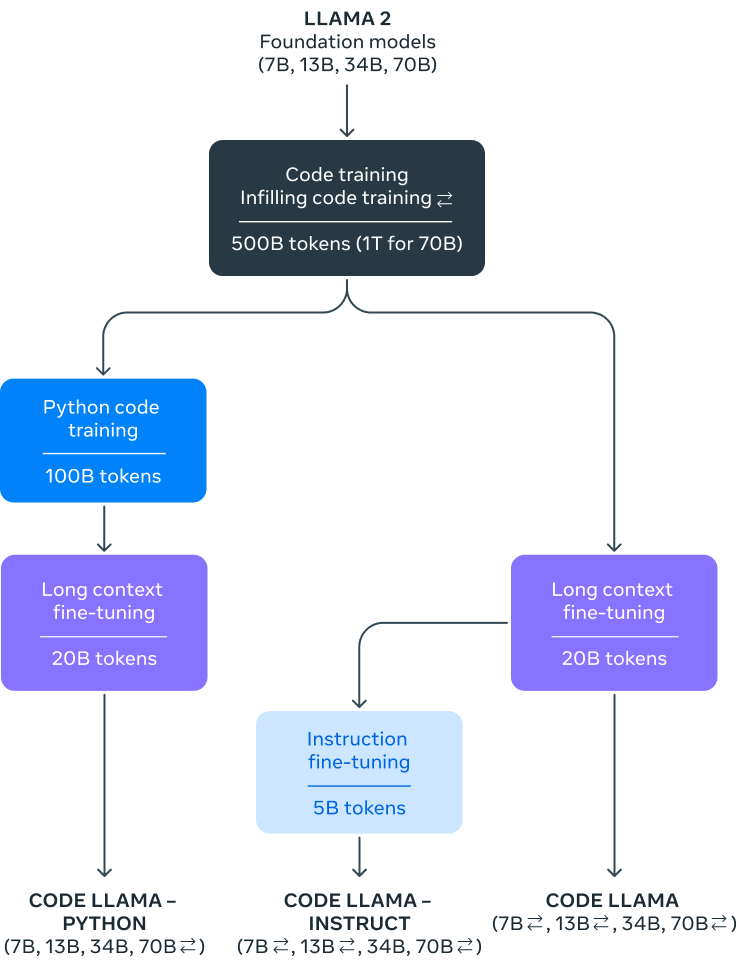
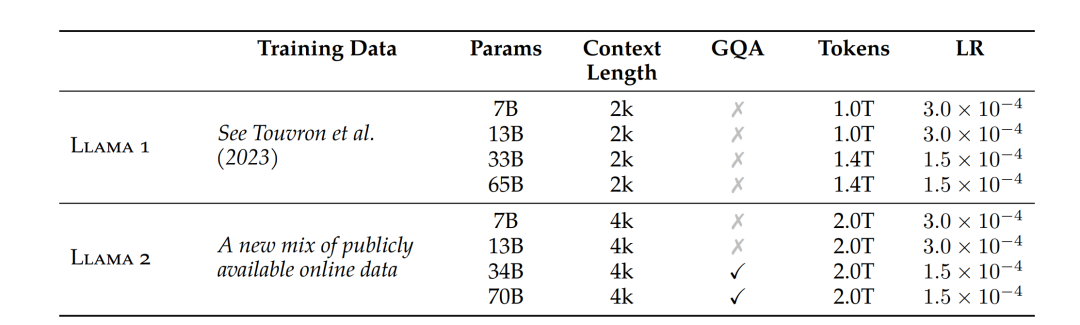
After a gap of 5 months, Meta released the commercially usable version Llama-2 [2] in July 2023, with parameter versions of 7B, 13B, 34B, and 70B. Except for the 34B model, all others have been open-sourced.Compared to Llama-1, Llama-2 expanded the pre-training corpus to 2T tokens, doubled the context length from 2,048 to 4,096, and introduced technologies such as grouped-query attention (GQA).With the more powerful base model Llama-2, Meta iteratively optimized the model using further supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) techniques, releasing a fine-tuned series model for dialogue applications called Llama-2 Chat.Through the “pre-training – supervised fine-tuning – reinforcement learning based on human feedback” training process, Llama-2 Chat not only achieved better model performance in numerous benchmark tests but also became safer in applications.Subsequently, thanks to the excellent performance of Llama-2, Meta released Code-Llama focused on code generation in August 2023, with parameter versions of 7B, 13B, 34B, and 70B.
1.3 Llama-3
In April 2024, Meta officially released the open-source large model Llama-3, including parameter versions of 8B and 70B. In addition, Meta revealed that a 400B version of Llama-3 is still in training.Compared to Llama-2, Llama-3 supports 8K long texts and uses a more efficient tokenizer with a vocabulary size of 128K. In terms of pre-training data, Llama-3 utilized over 15T tokens, which is more than seven times that of Llama 2.Llama-3 achieved a significant leap in performance and attained the best performance among large models of the same scale.Additionally, capabilities such as inference, code generation, and instruction following have been greatly improved, making Llama 3 more controllable.
2. Model Architecture
This section will describe Llama’s model architecture in detail, including the size of the neural network, the number of layers, and the attention mechanism.Currently, mainstream large language models adopt the Transformer [3] architecture, which is a neural network model based on multi-layer self-attention.The original Transformer consists of an encoder and a decoder, both of which can be used independently.For example, the encoder-based BERT [4] model and the decoder-based GPT [5] model.The Llama model, similar to GPT, also adopts a decoder-based architecture. Based on the original Transformer decoder, Llama made the following modifications:
To enhance training stability, a pre-layer RMSNorm [6] was adopted as the layer normalization method.
To improve model performance, SwiGLU [7] was used as the activation function.
To better model long sequence data, RoPE [8] was adopted as the positional encoding.
To balance efficiency and performance, some models adopted the grouped-query attention mechanism (Grouped-Query Attention, GQA) [9].
Specifically, the input token sequence is first transformed into a sequence of word vectors through the word embedding matrix. Then, the sequence of word vectors is passed through L decoder layers sequentially as the hidden layer state, and finally, RMSNorm is used for normalization. The normalized hidden layer state will be used as the final output.In each decoder layer, the input hidden layer state is first normalized through RMSNorm and then sent to the attention module. The output of the attention module will perform a residual connection with the hidden layer state before normalization. After that, the new hidden layer state is normalized again through RMSNorm and sent to the feedforward network layer. Similarly, the output of the feedforward network layer also undergoes a residual connection to serve as the output of the decoder layer.Each version of Llama has different variants due to its hidden layer size and number of layers. Next, we will look at the different variants of each version.
2.1 Llama-1 Series
The Llama-1 model architecture can be found in the MODEL_CARD:https://github.com/meta-llama/llama/blob/main/MODEL_CARD.mdTo better encode data, Llama-1 uses the BPE [10] algorithm for tokenization, specifically implemented by sentencepiece. It is noteworthy that Llama-1 decomposes all numbers into individual digits and reverts unknown UTF-8 characters to bytes for decomposition. The vocabulary size is 32k.
2.2 Llama-2 Series
The Llama-2 model architecture can be found in the MODEL_CARD (same as above)Llama-2 uses the same model architecture and tokenizer as Llama-1. Unlike Llama-1, Llama-2 extends the context length to 4k, and the 34B and 70B parameter versions use GQA.
2.3 Llama-3 Series
The Llama-3 model architecture can be found in the MODEL_CARD:https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.mdCompared to Llama 2, Llama-3 replaced the tokenizer from sentencepiece to tiktoken, consistent with GPT4. Additionally, the vocabulary size has expanded from 32k to 128k. Moreover, to improve model efficiency, both the 8B and 70B versions of Llama-3 adopted GQA, while the context length has also been extended to 8k.
3. Training Data
This section will briefly introduce the training data for each version, including data sources, scale, and processing methods.
3.1 Llama-1 Series
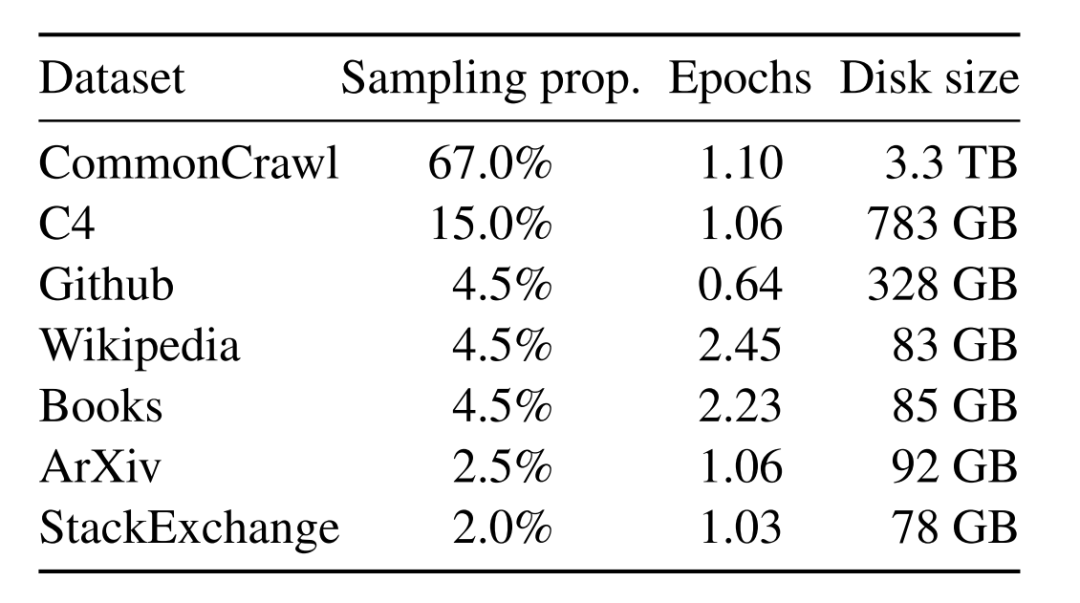
Llama-1 used a vast amount of unlabeled data for self-supervised learning, which was mixed from multiple publicly available sources. The amount and sampling ratio of data from each source are shown in the table below.
English CommonCrawl: Llama-1 preprocessed five CommonCrawl datasets from 2017 to 2020. This process included deduplication at the line level, using the fastText linear classifier for language identification to remove non-English pages, and filtering low-quality content using n-gram language models. Additionally, Llama-1 trained a linear model to classify pages used as references in Wikipedia and randomly sampled pages, discarding those not classified as references.
C4: In exploratory experiments, Llama-1 observed that using a diverse preprocessed CommonCrawl dataset could enhance performance. Therefore, Llama-1’s data included publicly available C4 datasets. The preprocessing of C4 also involved deduplication and language identification steps: the main difference from CCNet lies in quality filtering, which primarily relies on heuristic rules such as the presence of punctuation or the number of words and sentences on a webpage.
Github: Llama-1 used publicly available GitHub datasets on Google BigQuery. Llama-1 only retained projects distributed under Apache, BSD, and MIT licenses. In addition, Llama-1 employed heuristic rules based on line length or the ratio of alphanumeric characters to filter out low-quality files and removed boilerplate content such as headers using regular expressions. Finally, Llama-1 deduplicated the resulting dataset at the file level, matching exactly the same content.
Wikipedia: Llama-1 added Wikipedia data from June to August 2022, covering 20 languages using Latin or Cyrillic scripts. Llama-1 processed the data to remove hyperlinks, comments, and other formatted boilerplate content.
Gutenberg and Books3: Llama-1 included two book corpora in the training dataset: the Gutenberg project (which contains public domain books) and the Books3 portion of ThePile, a publicly available dataset used for training large language models. Llama-1 deduplicated at the book level, removing books with over 90% content overlap.
ArXiv: Llama-1 processed ArXiv’s LaTeX files to incorporate scientific data into Llama-1’s dataset. Llama-1 removed all content before the first section and the reference section. Llama-1 also removed comments in .tex files and inlined user-defined definitions and macros to enhance consistency across papers.
Stack Exchange: Llama-1 included data dumps from Stack Exchange, a high-quality question-and-answer site covering a range of fields from computer science to chemistry. Llama-1 retained data from the 28 largest sites, removed HTML tags from the text, and sorted answers based on scores (from highest to lowest).
After the above processing, Llama-1’s entire training dataset contains approximately 1.4T tokens. For most of Llama-1’s training data, each token was used only once during training, but Wikipedia and book data underwent about two epochs of training.
3.2 Llama-2
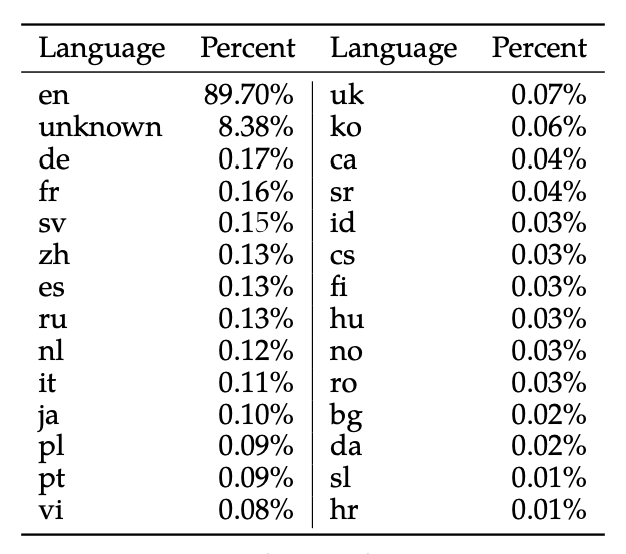
Llama-2 pre-trained on 2T tokens of data from publicly available sources (specific open-source data not detailed). Llama-2-Chat also underwent additional fine-tuning on 27,540 prompt-response pairs created for this project, outperforming larger but lower-quality third-party datasets. To achieve AI alignment, a combination of 1,418,091 Meta examples and seven smaller datasets was used for human feedback reinforcement learning (RLHF). In Meta examples, the average dialogue depth is 3.9, while the Anthropic Helpful and Anthropic Harmless sets average 3.0, and five other sets, including OpenAI Summarize and StackExchange, average 1.0. The fine-tuning data includes publicly available instruction datasets and over one million new human-annotated examples.During pre-training, Llama-2 took comprehensive considerations for data safety. By analyzing the pre-training data, Llama-2 could increase transparency and identify potential root issues, such as bias. Llama-2 took a series of measures, including adhering to Meta’s privacy and legal review processes, excluding data from websites known to contain large amounts of personal information. Furthermore, Llama-2 did not apply additional filtering to the dataset to make the model more widely available for various tasks while avoiding the unintended demographic erasure that excessive cleaning might cause. For language representativeness and toxicity analysis, Llama-2 used corresponding tools and datasets to understand the characteristics of the pre-training data, providing guidance for the model’s safety adjustments. This process ensured that our model received ample consideration regarding safety and prompted us to make significant safety adjustments before deploying the model.Llama-2’s pre-training primarily focused on English data, although experimental observations indicated that the model had some proficiency in other languages. However, due to the limited amount of pre-training data in non-English languages, its proficiency remains constrained (as shown in the figure below). Therefore, the model’s performance in non-English languages is still weak and should be used with caution (indicating poor multilingual capability: possibly due to a smaller vocabulary size).The pre-training data is up to September 2022, but some adjustment data is newer, up to July 2023.The technical report released with Llama2 states:
We will continue to refine the model to improve its applicability in other language contexts and will release updated versions in the future to address this issue.
Currently, Llama-3 not only expanded the vocabulary size but also increased the multilingual training corpus. Thus fulfilling the commitment made in Llama2’s technical report, and achieving a significant performance improvement in the currently published multilingual tasks.
3.3 Llama-3 Series
To better train Llama-3, researchers meticulously designed the pre-training corpus, focusing not only on quantity but also on quality. The training data for Llama-3 significantly increased from Llama-2’s 2T tokens to 15T tokens, an increase of about 8 times. Among them, the code data expanded four times, significantly enhancing the model’s performance in coding capabilities and logical reasoning.Llama-3 provides three sizes of model versions: a small model with 8B parameters, slightly outperforming Mistral 7B and Gemma 7B; a medium model with 70B parameters, whose performance lies between ChatGPT 3.5 and GPT 4; and a large model with 400B parameters, which is still in training, aiming to become a multimodal, multilingual version of the model, expected to perform comparably to GPT 4 or GPT 4V.It is noteworthy that Llama-3 does not adopt the Mixture of Experts (MOE) structure, which is mainly used to reduce training and inference costs but typically cannot match the performance of dense models of the same scale. As the model scale increases, how to reduce inference costs will become a matter of concern.Additionally, Llama-3’s training data includes a large number of code tokens and over 5% non-English tokens from more than 30 languages. This not only makes the model more efficient in processing English content but also significantly enhances its multilingual processing capability, indicating Llama-3’s adaptability and application potential in global multilingual environments.To ensure data quality, Meta developed a series of data filtering pipelines, including heuristic filters, NSFW filters, semantic duplicate data removal techniques, and text classifiers for predicting data quality. The effectiveness of these tools benefits from the performance of previous versions of Llama, particularly in identifying high-quality data.Moreover, Meta evaluated the best strategies for mixing data from different sources in the final pre-training dataset through extensive experimentation, ensuring that Llama-3 could demonstrate excellent performance across various scenarios, such as everyday tasks, STEM fields, programming, and historical knowledge.
4. Training Methods
This section will briefly introduce the training methods for each version, including pre-training, supervised fine-tuning, and reinforcement learning based on human feedback.
4.1 Llama-1 Series
The Llama-1 model is a basic self-supervised learning model that has not undergone any form of specific task fine-tuning. Self-supervised learning is a machine learning technique in which the model learns to predict certain parts of its input data by analyzing a large amount of unlabeled data. This method allows the model to automatically learn the intrinsic structure and complexity of the data without human-annotated data. Llama-1’s technical report details the specific training configuration of the machine learning model using the AdamW optimizer. AdamW is an improvement over the Adam optimizer, which can handle weight decay more effectively, thereby improving training stability. The selection of β1 and β2 parameters affects the convergence behavior and stability of the training process. The cosine learning rate scheduling described for Llama-1 is an effective technique used to adjust the learning rate during training, which can lead to better convergence in some cases by gradually reducing the learning rate. Implementing a weight decay of 0.1 and gradient clipping of 1.0 is a standard practice to prevent overfitting and ensure numerical stability. Using warm-up steps is a strategic approach aimed at stabilizing training dynamics in the early stages of the training process. Adjusting the learning rate and batch size according to the model size is a practical method for optimizing resource allocation and efficiency, which can potentially enhance model performance.Llama-1 also demonstrates a series of optimizations tailored for training large-scale language models. By using the efficient implementation of causal multi-head attention in the xformers library [12] (achieved by not storing attention weights and not computing the key/query scores that are masked due to the causal nature of the language modeling task), memory usage and computation time are reduced, reflecting a focus on efficiency when handling large data sets. Additionally, manually implementing the backpropagation function instead of relying on an automatic differentiation system and utilizing checkpointing techniques to save computationally expensive activations are effective strategies to improve training speed and reduce resource consumption. Enhancing training efficiency through model and sequence parallelism and optimizing communication between GPUs further improves the training process. These optimizations are particularly suited for training large models, such as those with 65 billion parameters, significantly reducing training time and improving overall computational efficiency. Overall, these optimization techniques reflect a deep consideration of resource management and efficiency optimization in high-performance computing, which is crucial for advancing large-scale language models.
4.2 Llama-2 Series
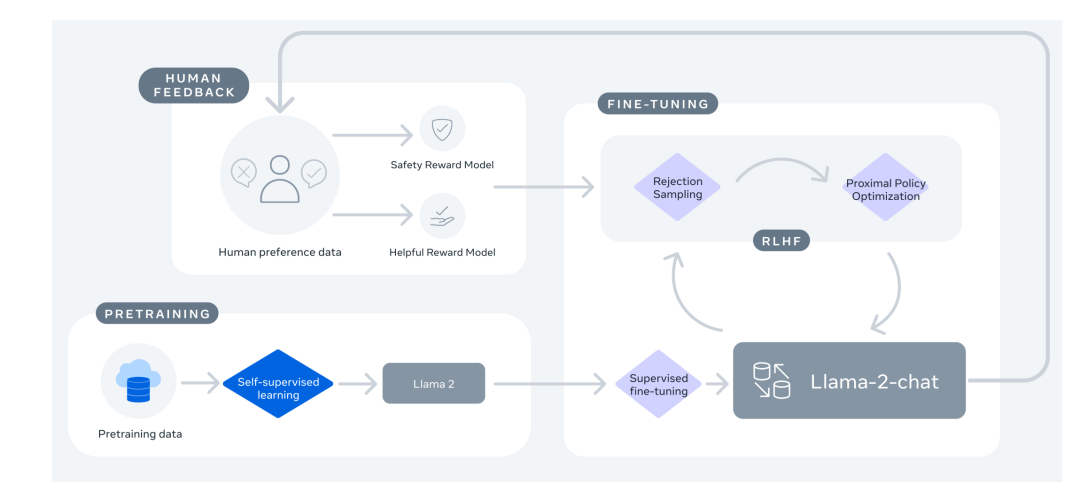
The Llama-2 model further develops on the basis of Llama-1, while the Llama-2-Chat model is a fine-tuned version based on Llama-2. Both models maintain a fixed context length of 4k, which differs from the potentially increased context length during fine-tuning in OpenAI’s GPT-4.In the fine-tuning of Llama-2 and Llama-2-Chat, an autoregressive loss function was employed, a common approach in generative models where the model considers all previous tokens when predicting the next token. During the training process, the loss of tokens from user input prompts is set to zero, meaning the model is trained to ignore these specific tokens, allowing it to focus more on generating responses.The training process of Llama-2-Chat is illustrated in the figure below. The entire process begins with pre-training Llama-2 using publicly available data. Following this, a supervised fine-tuning created the initial version of Llama-2-Chat. Subsequently, reinforcement learning with human feedback (RLHF) methods were used to iteratively improve the model, specifically including rejection sampling and proximal policy optimization (PPO). In the RLHF phase, human preference data was also iteratively updated in parallel to keep the reward model current.
4.3 Llama-3 Series
Similar to Llama-2, the Llama-3 series also includes two models—pre-trained model Llama-3 and fine-tuned model Llama-3-Instruct.During the pre-training phase, to effectively utilize the pre-training data, Llama-3 invested considerable effort in expanding pre-training. Specifically, a series of scaling laws were formulated for downstream benchmark tests, allowing for performance predictions on key tasks before training and leading to the selection of the best data combinations.In this process, Llama-3 made some new observations regarding scaling laws. For example, according to the scaling law proposed by the DeepMind team, the optimal training data amount for the 8B model is about 200B tokens, but experiments found that even after training with two orders of magnitude more data, the model’s performance continued to improve. After training on up to 15T tokens, both the 8B and 70B parameter models continued to show log-linear performance improvements.To train the largest Llama-3 model, Meta combined three parallel strategies: data parallelism, model parallelism, and pipeline parallelism. When training simultaneously on 16K GPUs, the most efficient strategy achieved over 400 TFLOPS of computational utilization per GPU. Finally, the model was trained on two customized 24K GPU clusters.To maximize GPU uptime, Meta developed an advanced new training stack that can automatically detect, handle, and maintain errors. Additionally, hardware reliability and silent data corruption detection mechanisms were significantly improved, and a new scalable storage system was developed to reduce checkpoint and rollback overhead. These improvements ensured that the total effective training time exceeded 95%. Collectively, these advancements made Llama-3’s training efficiency approximately three times that of Llama-2.In the fine-tuning phase, Meta made significant innovations in the model’s fine-tuning methods, combining supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO). This comprehensive approach optimized the model’s performance in executing complex reasoning and coding tasks. Particularly, through preference ranking training, Llama-3 can more accurately select the most appropriate answer when addressing complex logical reasoning problems, which is crucial for enhancing AI usability and reliability in practical applications.
5. Performance Comparison
This section will compare the performance differences of different versions across numerous benchmark tests.
5.1 Llama-2 vs Llama-1
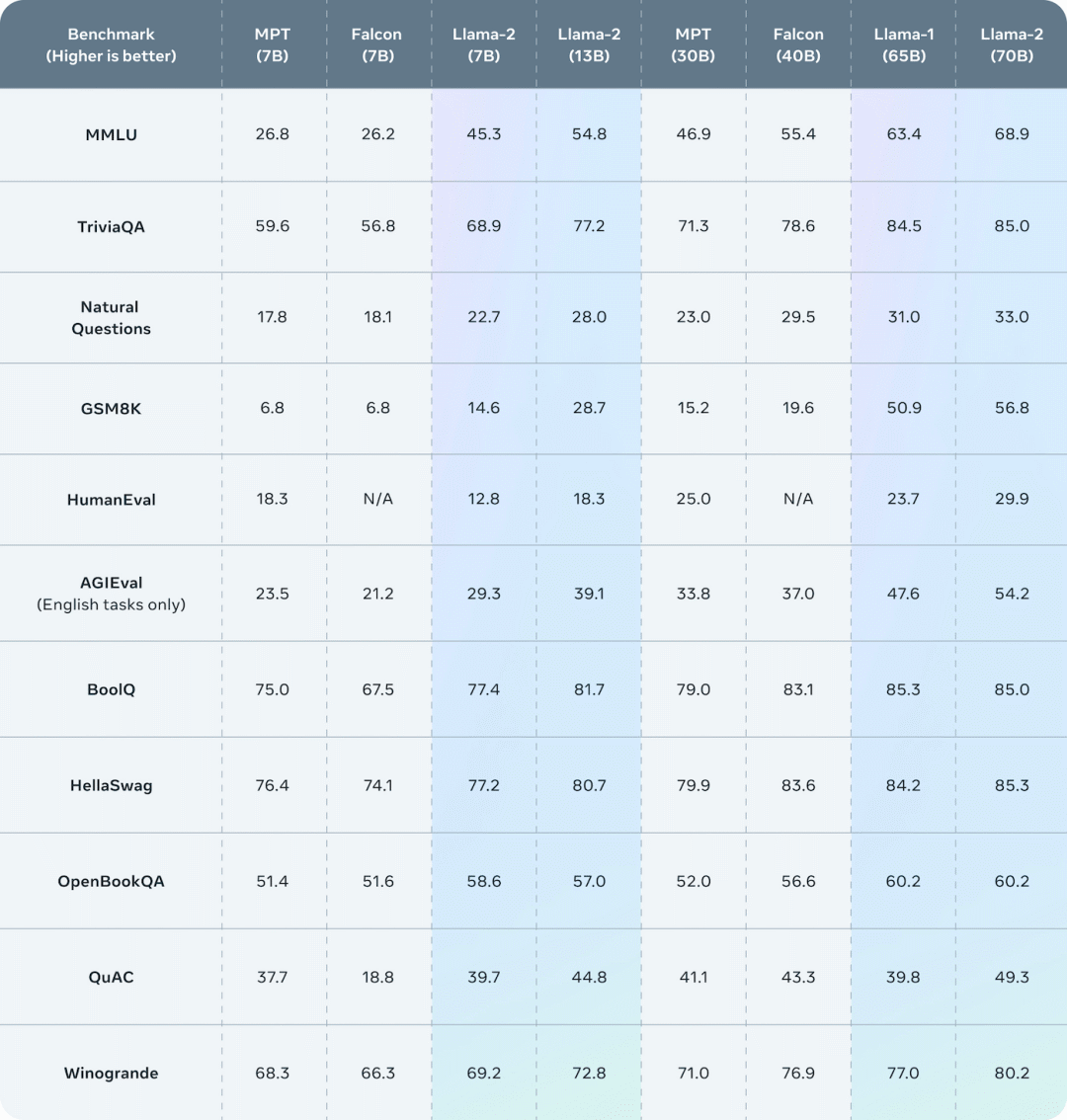
Official data from Meta shows that Llama-2 outperforms Llama-1 and other open-source language models across numerous benchmark tests.
5.2 Llama-3 vs Llama-2
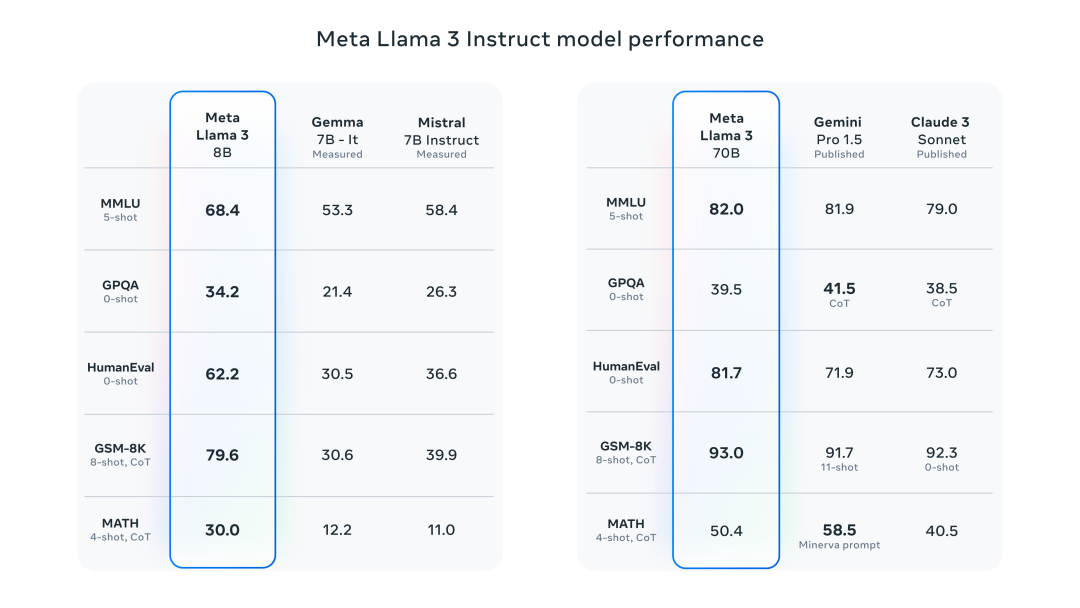
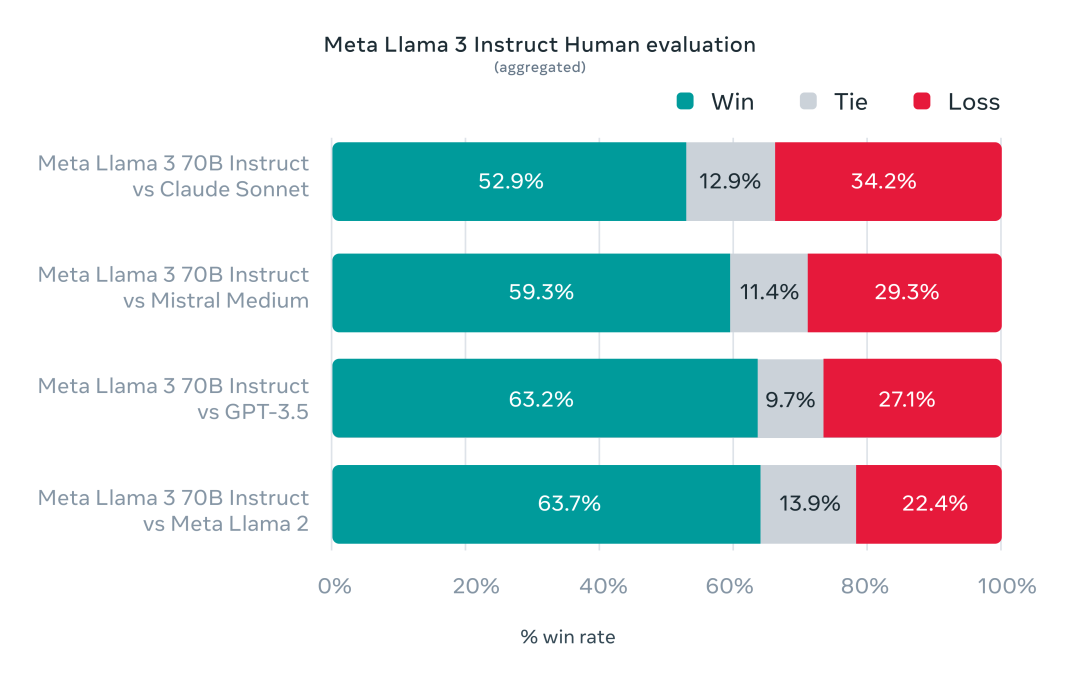
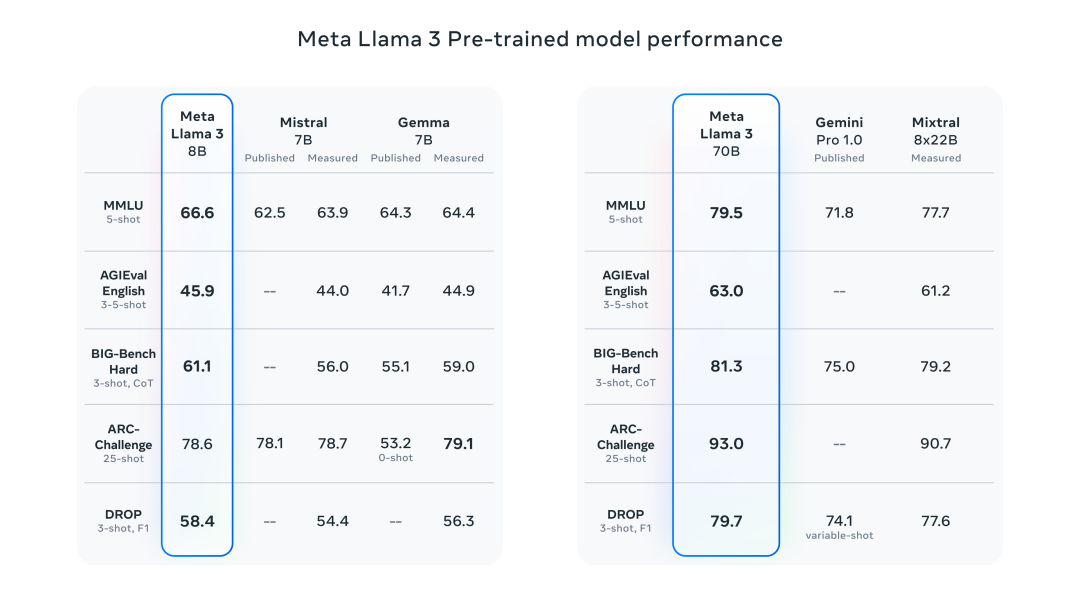
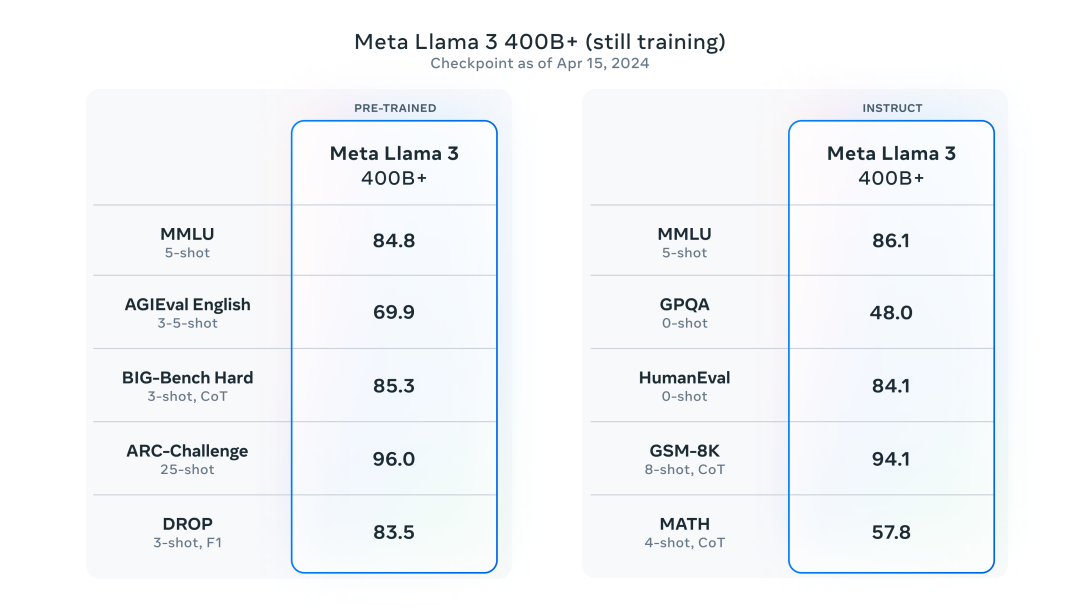
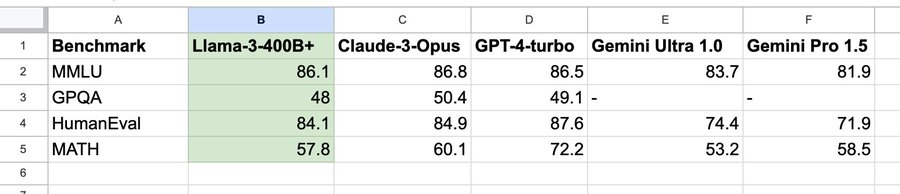
Official data from Meta shows that both the 8B and 70B versions of Llama-3 achieved good results across their respective parameter scales. The 8B model outperformed both Gemma 7B and Mistral 7B Instruct in numerous benchmark tests, while the 70B model surpassed the closed-source model Claude 3 Sonnet, achieving comparable performance to Google’s Gemini Pro 1.5.Additionally, during the development of Llama-3, Meta also developed a high-quality human evaluation set containing 1,800 prompts. The evaluation results show that Llama 3 not only significantly surpasses Llama 2 but also outperforms well-known models such as Claude 3 Sonnet, Mistral Medium, and GPT-3.5.The outstanding performance of Llama-3 can be attributed to its superior pre-trained model performance. In numerous benchmark tests, the 8B model surpassed Mistral 7B and Gemma 7B, while the 70B model outperformed Gemini Pro 1.0 and Mixtral 8x22B.Moreover, Meta stated that the largest Llama-3, which has over 400B parameters, is still in training and has achieved excellent results in multiple benchmark tests. Once training is completed, Meta will publish a detailed research paper.It is noteworthy that, according to NVIDIA scientist Jim Fan’s compilation, Llama3 400B is approaching Claude-3-Opus and GPT-4-turbo, which would mean that the open-source community is about to welcome a model at GPT-4 level.
6. Community Impact
This section will briefly introduce the impact of the Llama model on the open-source community.
6.1 The Power of Open Source Models
Since the release of the Llama model by Meta, it has had a profound impact on the global AI community. As an open-source large language model (LLM), Llama not only provides a strong technical foundation but also promotes the widespread adoption and innovation of AI technology globally.The open-source strategy of the Llama model is considered the “Android” of the LLM era, meaning it offers a modular and customizable platform that allows researchers and developers to adjust and optimize the model according to their needs. This openness has greatly lowered the entry barriers, enabling everyone from small startups to large enterprises to leverage this technology. On April 19, the release of Llama 3 saw a one-day download volume exceeding 1.14k, with both 8B models trending at number one.
6.2 Impact on Global AI R&D
After OpenAI shifted to a more closed commercial model, the release of Llama provided a reliable alternative for teams and individuals conducting AI project R&D globally. This open-source model ensures that users do not have to rely entirely on a single commercial API, thus increasing operational security and freedom for enterprises, especially regarding data security and cost control.
6.3 Technological Advancements and Community Innovation
Technically, the Llama model has demonstrated performance comparable to GPT, proving the open-source community’s ability to drive cutting-edge technology. Additionally, the community has developed applicable solutions in various vertical fields through continuous optimization and adjustment of the model, similar to community-driven large models such as Stable Diffusion and Midjourney.
6.4 Ecosystem and Diversity
The application of Llama has expanded to various platforms and devices, including mobile and edge devices. This diversification of applications not only promotes the popularization of technology but also accelerates innovation in new applications. For instance, the active participation of cloud platforms like AWS and Google Cloud demonstrates the wide applicability and powerful capabilities of the Llama model.
6.5 Future Prospects of the Llama Community
With the continuous development and optimization of the Llama model, Meta emphasizes its ongoing focus on multimodal AI, security, and accountability, as well as community support. These directions not only align with current trends in AI development but also provide a clear roadmap for the future of the Llama community.
7. Conclusion
In summary, the release of the Llama model not only demonstrates the importance of open-source models in the global AI field but also provides new perspectives and momentum for the future development of AI. Through continuous technological advancements and community-driven innovation, Llama is expected to continue driving the widespread application and development of AI technology globally.References[1] Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.[2] Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.[4] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.[5] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.[6] Zhang B, Sennrich R. Root mean square layer normalization[J]. Advances in Neural Information Processing Systems, 2019, 32.[7] Shazeer N. Glu variants improve transformer[J]. arXiv preprint arXiv:2002.05202, 2020.[8] Su J, Ahmed M, Lu Y, et al. Roformer: Enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063.[9] Ainslie J, Lee-Thorp J, de Jong M, et al. Gqa: Training generalized multi-query transformer models from multi-head checkpoints[J]. arXiv preprint arXiv:2305.13245, 2023.[10] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units[J]. arXiv preprint arXiv:1508.07909, 2015.[11] Hoffmann J, Borgeaud S, Mensch A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.[12] https://github.com/facebookresearch/xformersTechnical Exchange Group Invitation
△ Long press to add assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply to join Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community is a grassroots academic community jointly built by domestic and foreign scholars in machine learning and natural language processing. It has now developed into a well-known machine learning and natural language processing community at home and abroad, aiming to promote progress between the academic and industrial sectors of machine learning and natural language processing and the vast number of enthusiasts.The community can provide an open communication platform for the further education, employment, and research of related practitioners. Everyone is welcome to follow and join us.