
Click on the above “AI Meets Machine Learning“, and select “Star” public account
Original content delivered first-hand
 In the previous article, we discussed the concept of attention. This article builds on that, providing a deeper understanding of the ideas surrounding attention and the latest self-attention mechanism.
In the previous article, we discussed the concept of attention. This article builds on that, providing a deeper understanding of the ideas surrounding attention and the latest self-attention mechanism.
1. The Essence of Attention Mechanism
To better understand the essence of the Attention mechanism, we can abstract it from the Encoder-Decoder framework discussed previously.
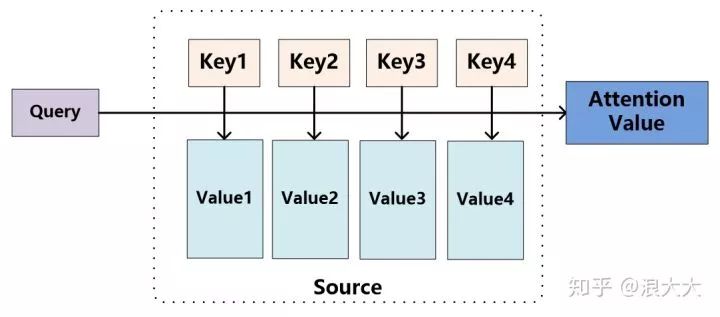
We can view the Attention mechanism as follows (refer to Figure 9): Imagine the elements in the Source as pairs of
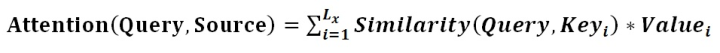
Here, Lx=||Source|| represents the length of the Source, and the meaning of the formula is as described above. In the example of machine translation provided earlier, during the calculation of Attention, the Key and Value from the Source merge into one, pointing to the same entity, which is the semantic encoding corresponding to each word in the input sentence. Therefore, it may be difficult to see this structure that reflects the essence of the idea.
Of course, conceptually, we can still understand Attention as selectively filtering out a small amount of important information from a large amount of data and focusing on this important information while ignoring most of the unimportant data. This thought process still holds. The focusing process is reflected in the calculation of the weight coefficients; the larger the weight, the more focused it is on the corresponding Value, meaning the weight represents the importance of the information, while the Value corresponds to that information.
As for the specific calculation process of the Attention mechanism, if we abstract most of the current methods, we can summarize it into two processes: the first process is to calculate the weight coefficients based on Query and Key, and the second process is to perform a weighted sum of the Values based on the weight coefficients. The first process can be further divided into two stages: the first stage calculates the similarity or relevance between Query and Key; the second stage normalizes the raw scores from the first stage. Thus, we can abstract the calculation process of Attention into the three stages shown in Figure 10.
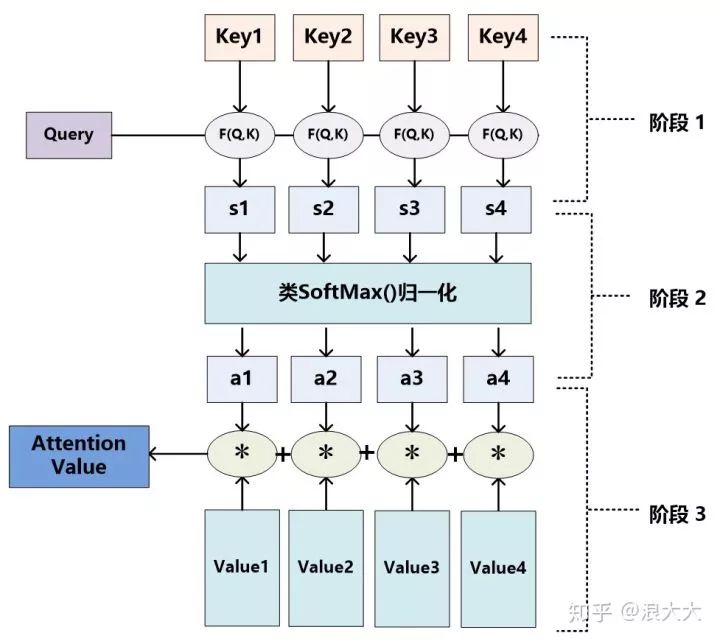
In the first stage, different functions and calculation mechanisms can be introduced to calculate the similarity or relevance between Query and a certain Keyi. The most common methods include: calculating the dot product of the two vectors, calculating the cosine similarity of the two vectors, or introducing additional neural networks to evaluate, as shown below:

The score produced in the first stage may have a different range of values based on the methods used. The second stage introduces a computation similar to SoftMax to transform the scores from the first stage. On one hand, it normalizes the original scores into a probability distribution where the sum of all element weights equals 1; on the other hand, it can also highlight the weights of important elements through the inherent mechanism of SoftMax. The calculation is generally done using the following formula:
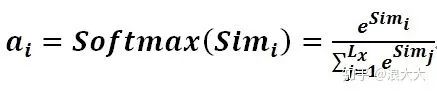
The result of the calculation in the second stage, ai, is the weight coefficient corresponding to Valuei, and then a weighted sum can yield the Attention value:
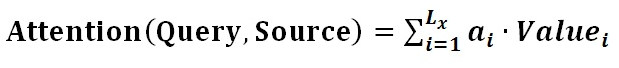
Through the computation of these three stages, we can obtain the Attention value for the Query. Currently, the vast majority of specific attention mechanism calculation methods conform to the three-stage abstract calculation process described above.
2. Self Attention Model
By organizing the essence of Attention as described above, we can more easily understand the Self Attention model introduced in this section. Self Attention is often referred to as intra Attention and has gained widespread use in the past year, such as in Google’s latest machine translation model, which extensively employs the Self Attention model.
In a typical Encoder-Decoder framework for tasks, the input Source and output Target content are different. For instance, in English-Chinese machine translation, the Source is the English sentence, and the Target is the corresponding translated Chinese sentence. The Attention mechanism occurs between the elements of the Target and all elements of the Source. Self Attention, as the name implies, refers not to the Attention mechanism between Target and Source, but rather the Attention mechanism that occurs between the elements within the Source or within the Target. It can also be understood as the attention calculation mechanism in the special case where Target=Source. The specific calculation process is the same, but the objects of calculation have changed, so we will not elaborate on the calculation details here.
Self Attention is very different from traditional Attention mechanisms: traditional Attention is based on the hidden states of the source and target ends to calculate Attention, resulting in a dependency relationship between each word in the source and each word in the target. However, Self Attention operates separately at the source and target ends, relating only to the input of the source or the input of the target, capturing the dependencies between words within the source or the target. Then, the Self Attention obtained from the source is added to the Attention obtained from the target to capture the dependencies between words in the source and target. Therefore, Self Attention performs better than traditional Attention mechanisms, one of the main reasons being that traditional Attention mechanisms overlook the dependencies between words within the source or target sentences. In contrast, Self Attention can not only capture the dependencies between words in the source and target but also effectively capture the dependencies between words within the source or target itself, as shown in Figure 7.


From the two figures (Figure 11 and Figure 12), it is clear that Self Attention can capture certain syntactic features (such as the phrase structure shown in Figure 11) or semantic features (such as the referent of ‘its’ shown in Figure 12) between words in the same sentence.
Clearly, the introduction of Self Attention makes it easier to capture long-distance dependencies between words in a sentence. In contrast, if using RNN or LSTM, the sequence must be computed step by step, and for long-distance dependencies, several time steps of information accumulation are required to connect the two, making it less likely to effectively capture such dependencies the farther apart they are.
However, Self Attention directly relates any two words in the sentence through a single computation step, significantly shortening the distance between long-distance dependencies, which is beneficial for effectively utilizing these features. Additionally, Self Attention directly aids in increasing the parallelism of computations. This is one of the main reasons why Self Attention has gradually been widely adopted.
Source: Zhihu, Lang Dada Link: https://zhuanlan.zhihu.com/p/61816483
Recommended Reading
Content|How to Write Academic Papers
Resource|NLP Books and Course Recommendations (with Download Links)
Content|Comprehensive Understanding of N-Gram Language Models
Resource|Recommended Book: “Machine Learning for OpenCV”
Welcome to follow us, to see popular content!
