Translated by|Yang Ting, Xu Jiayu
Recently, AI image generation has attracted attention, capable of generating exquisite images based on text descriptions, significantly changing the way people create images.Stable Diffusion is a high-performance model that generates higher quality images, runs faster, and consumes fewer resources and memory, marking a milestone in the field of AI image generation.
After being introduced to AI image generation, you may be curious about how these models work.
Below is an overview of how Stable Diffusion works.
Stable Diffusion has diverse applications and is a multifunctional model. First, it can generate images from text (text2img). The image above is an example of generating an image from text input. Additionally, we can use Stable Diffusion to replace or modify images (in this case, we need to input both text and images).
Below is the internal structure of Stable Diffusion. Understanding the internal structure can help us better understand the components of Stable Diffusion, how they interact, and the meaning of various image generation options/parameters.
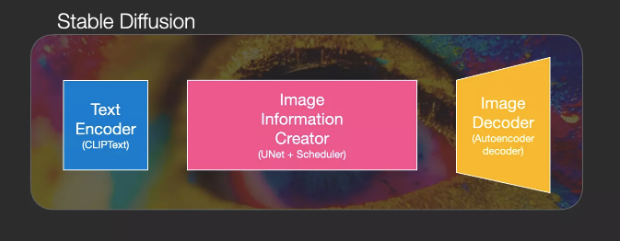
1Components of Stable Diffusion
Stable Diffusion is not a single model but a system composed of multiple parts and models.
Internally, we can first see a text understanding component, which converts text information into a numeric representation to capture the text’s intent.
This section mainly provides a general introduction to ML, and more details will be explained later in the article. This text understanding component (text encoder) can be considered a special Transformer language model (technically, it is a text encoder of a CLIP model). Text input into the Clip text encoder yields a list of features, with a vector feature for each word/token in the text.
Then, the text features are used as input for the image generator, which consists of several parts.
The image generator consists of two steps:
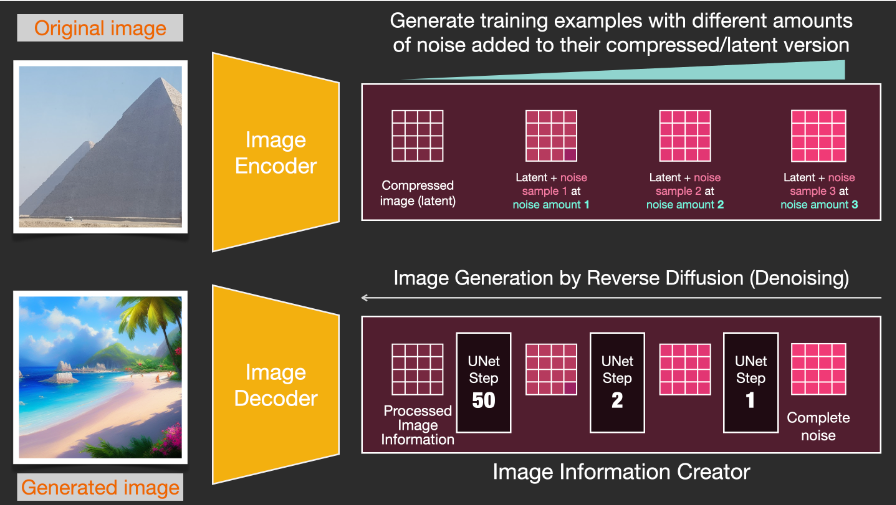
1-Image Information Creator
The image information creator is a key part unique to Stable Diffusion and is the reason for its performance vastly exceeding that of other models.
The image information creator runs multiple steps to generate image information. The step parameter for Stable Diffusion interfaces and libraries is generally set to 50 or 100 by default.
The image information creator operates entirely in the image information space (also known as latent space), allowing Stable Diffusion to run faster than previous diffusion models that operated in pixel space. Technically, the image information creator consists of a UNet neural network and a scheduling algorithm.
The term “diffusion” describes what happens in the image information creator. As the image information creator processes the information step by step, the image decoder can subsequently produce high-quality images.
The image decoder draws images based on the information from the image information creator. It only runs once at the end of the process to generate the final pixel image.
This constitutes the three main components of Stable Diffusion, each with its own neural network:
-
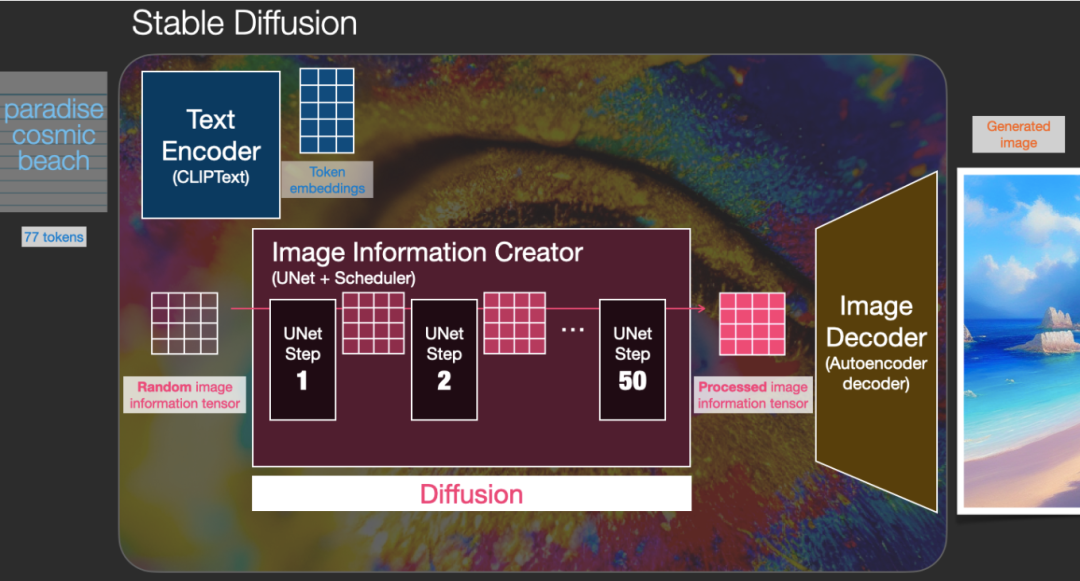
ClipText: Used for text encoding. Input: Text. Output: 77 token embeddings, each with 768 dimensions.
-
UNet + Scheduler: Processes information step by step in latent space. Input: Text embeddings and a noise initialized multidimensional array (structured numerical list, also known as a tensor). Output: Processed information array.
-
Autoencoder Decoder: Uses the processed information array to draw the final image. Input: Processed information array (dimensions: (4,64,64)) Output: Generated image (dimensions: (3,512,512), i.e., (Red/Green/Blue; Width, Height)).
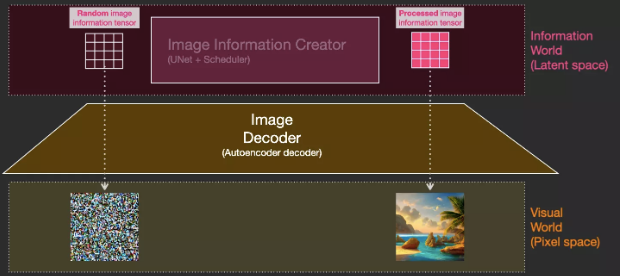
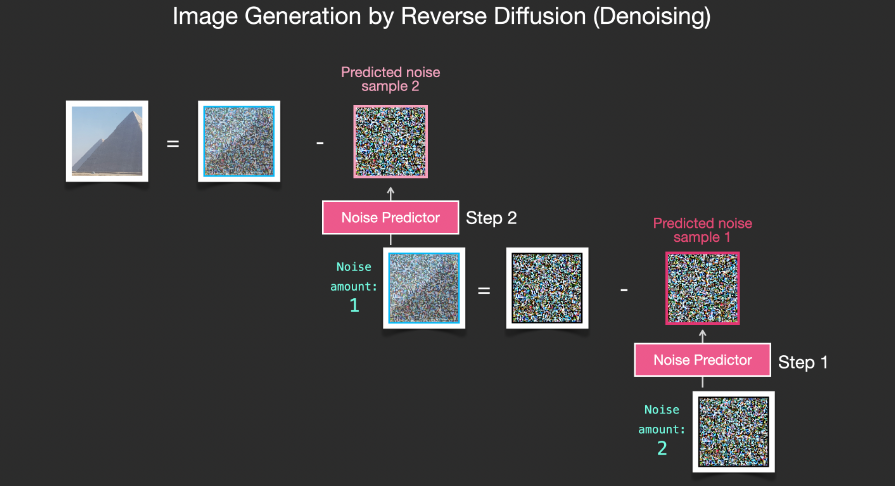
Diffusion is the process that occurs in the pink area of the image information creator component. This part has a token embeddings representing the input text and a randomly initialized image information array, also known as latents. This process generates an information array that the image decoder uses to generate the final image.
Diffusion occurs progressively, with each step adding more relevant information. To better visualize this process, we can examine the random latents array to see if it transforms into visual noise. In this case, visual inspection is done through the image decoder.
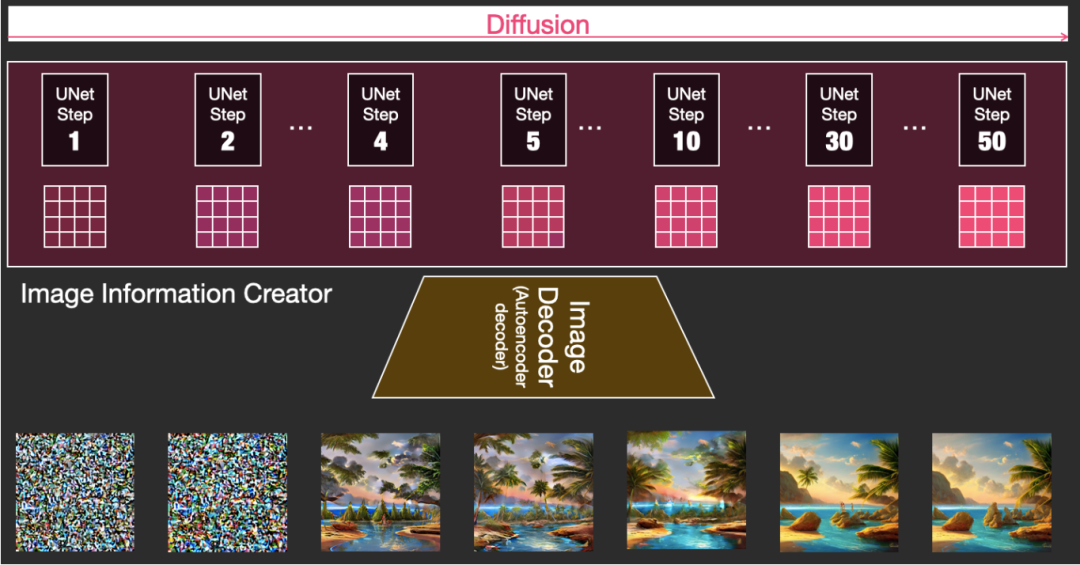
Diffusion is divided into multiple steps, with each step running on the input latents array, producing another latents array that is more similar to the input text and all visual information obtained during model training.
We can visualize a set of such latents arrays to see what information is added at each step. This process is breathtaking.
In this case, something particularly interesting happens between steps 2 and 4, as if the outline emerges from the noise.
The core of diffusion model image generation is a powerful computer vision model. Based on sufficiently large datasets, these models can learn many complex operations. The diffusion model constructs the problem for image generation as follows:
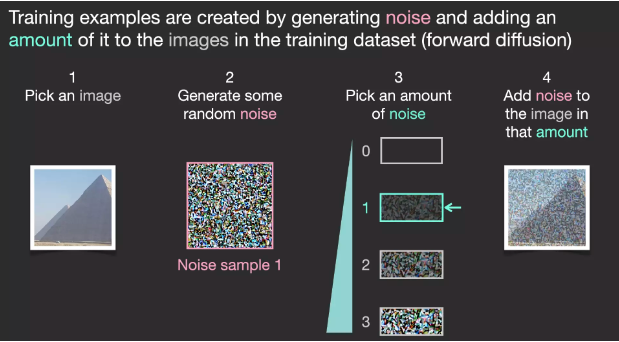
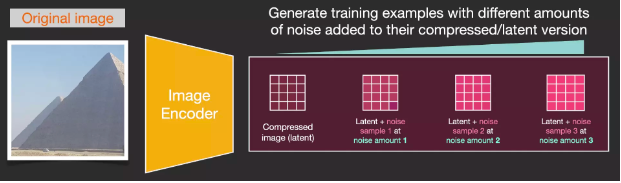
Assuming we have an image, we first generate some noise and then add this noise to the image.
We can view this as a training example. We then use the same formula to create more training examples and train the central component of the image generation model with these examples.
While this example shows some noise values from the image (total 0, no noise) to total noise (total 4, total noise), we can easily control the noise added to the image, allowing us to create dozens of training examples for each image in the dataset.
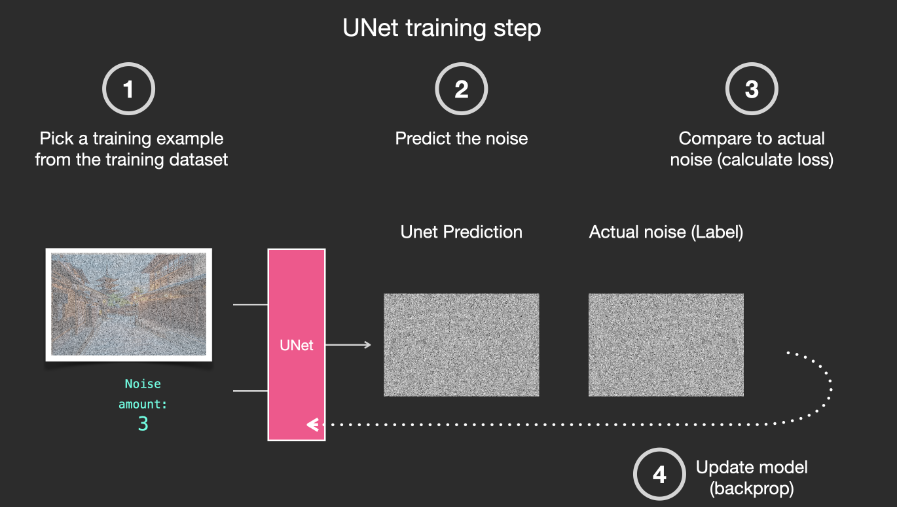
With this dataset, we can train a noise predictor and ultimately obtain a predictor that can create images when run under specific configurations. Those familiar with ML will find the training steps very familiar:
Next, let’s look at how Stable Diffusion generates images.
4Drawing Through Denoising
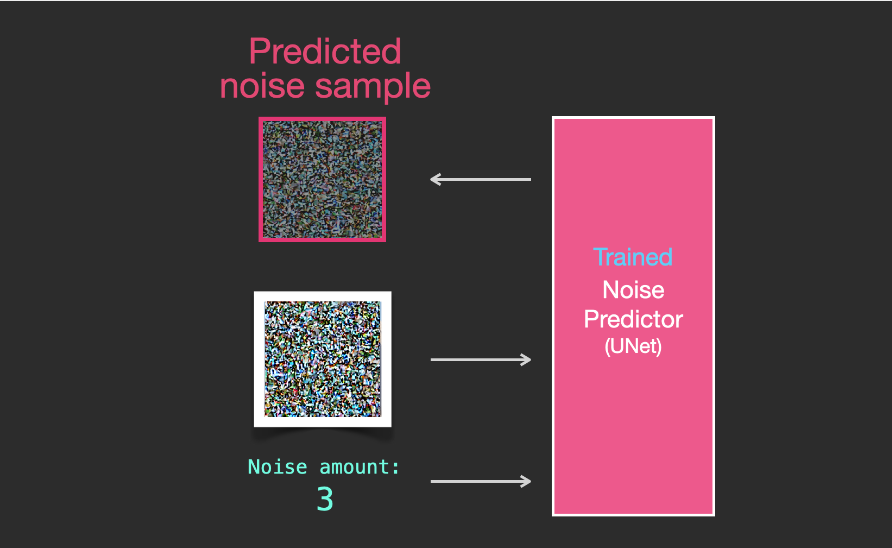
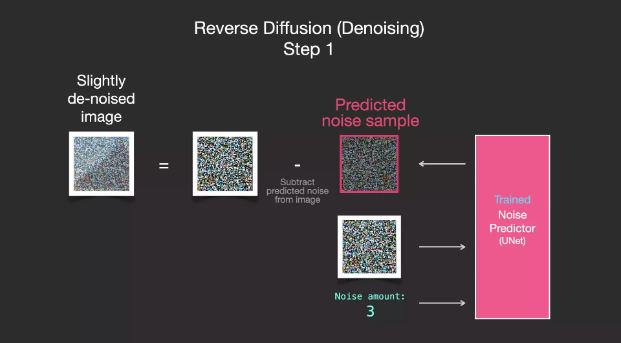
The trained noise predictor can denoise noisy images and predict noise.
Because the sampled noise is predicted, if we remove this sample from the image, the resulting image will be closer to the images trained by the model. (This image is not the exact image itself but the distribution of images, which is the arrangement of pixels in an image, where the sky is usually blue, above the ground, people have two eyes, cats have pointed ears, and are always lazy.)
If the images in the training dataset are aesthetically pleasing, such as those trained by Stable Diffusion, LAION Aesthetics, the generated images will also be more visually appealing. If we train on logo images, we will ultimately obtain a logo generation model.
Here, we summarize the process of how diffusion models handle image generation, mainly as described in the paper Denoising Diffusion Probabilistic Models. I believe you now have a certain understanding of the meaning of diffusion and know the main components of Stable Diffusion, Dall-E 2, and Google Imagen.
It is worth noting that up to this point, the diffusion process we have described has not used any text data, and only running the model can generate exquisite images. However, we cannot control the content of the image; it could be a pyramid or a cat. Next, we will discuss how to incorporate text information into the diffusion process to control the type of images.
5Speed Improvement: Diffusion in Compressed (Latent) Data
To speed up the image generation process, the Stable Diffusion paper does not run on pixel images but on a compressed version of the images. The paper refers to this as Departure to Latent Space.
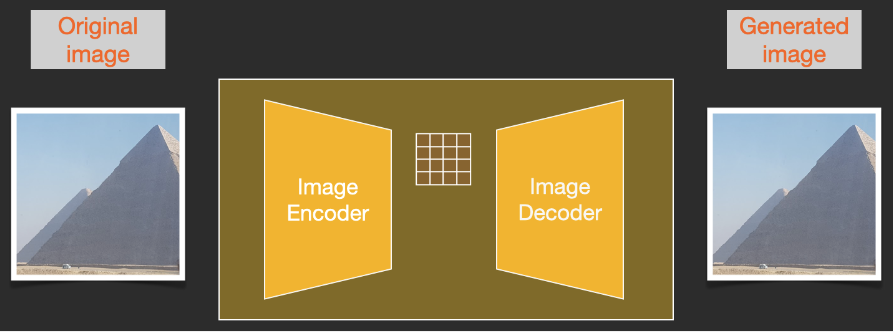
Compression (and subsequent decompression/drawing) is accomplished through an encoder. The autoencoder uses an Image Encoder to compress the image into latent space and then uses an Image Decoder to reconstruct the compressed information.
Forward diffusion is completed in latent space. Noise information is applied to latent space rather than to pixel images. Therefore, training the noise predictor is actually to predict noise on the compressed representation, which is also referred to as latent space.
Forward diffusion is performed using the Image Encoder to generate image data to train the noise predictor. Once training is complete, reverse diffusion can be executed using the Image Decoder to generate images.
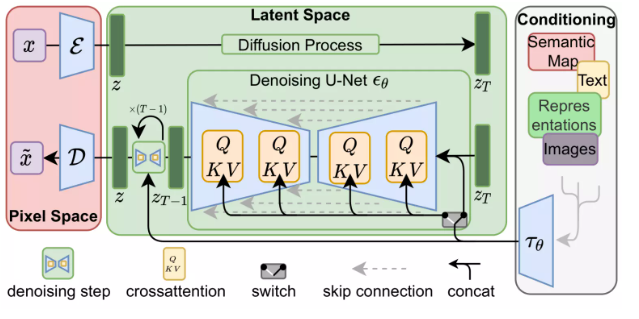
The processes mentioned in the LDM/Stable Diffusion paper are illustrated in Figure 3:
The above image also shows the “conditioning” component, which in this case is the text prompts describing the images generated by the model. Next, we continue to explore the text component.
6Text Encoder: A Transformer Language Model
The Transformer language model serves as the language understanding component, capable of accepting text prompts and generating token embeddings. The Stable Diffusion model uses ClipText (a GPT-based model), while the paper utilizes BERT.
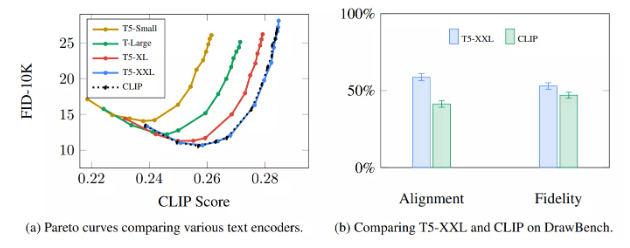
Imagen’s paper indicates that the choice of language model is quite important. Compared to larger image generation components, larger language model components have a greater impact on the quality of generated images.
A larger/better language model has a huge impact on the quality of image generation models. Source: Figure A.5 from the paper Google Imagen by Saharia et al.
Early Stable Diffusion models only used the pre-trained ClipText model released by OpenAI. Future models may shift to the newly released larger CLIP variant, OpenCLIP. (Updated in November 2022, see Stable Diffusion V2 uses OpenClip. Compared to ClipText, which has 6.3 million text model parameters, OpenCLIP has up to 354 million text model parameters.)
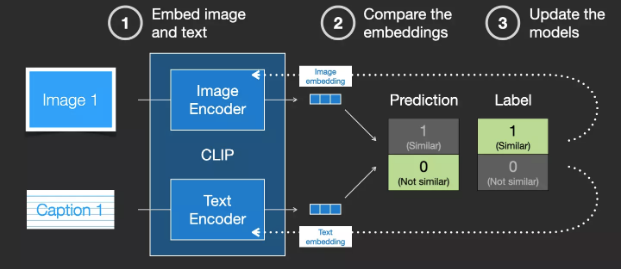
CLIP models are trained on datasets of images and their descriptions. We can envision a dataset containing 400 million images and their corresponding descriptions.
Image and Image Description Dataset
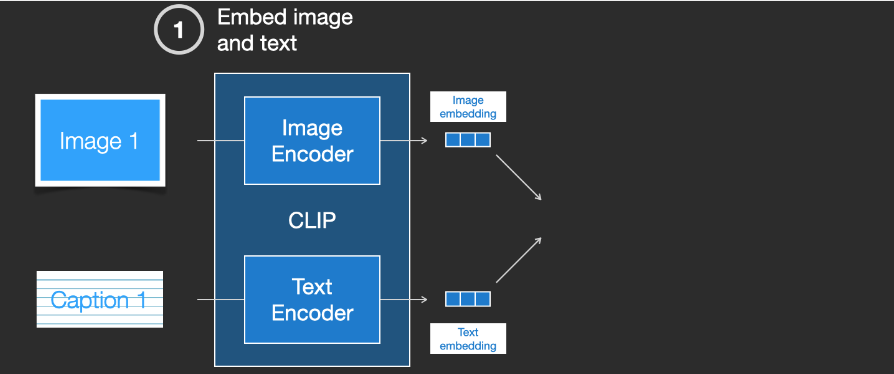
In fact, CLIP is trained on images scraped from the web with “alt” tags. CLIP is a combination of image encoder and text encoder. In simple terms, training CLIP involves encoding both images and their textual descriptions separately.
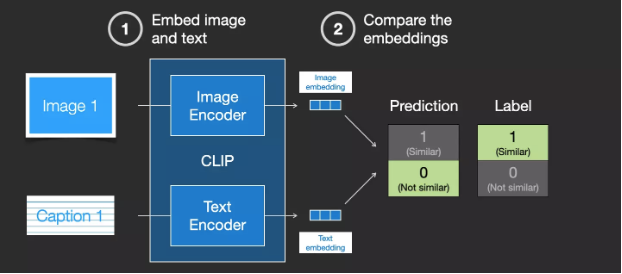
Then, cosine similarity is used to compare the generated embeddings. At the beginning of training, even if the text accurately describes the image, the similarity will be low.
We update these two models so that the next time we embed them, we can obtain similar embeddings.
By repeating this process over the dataset and using a large batch size, we ultimately enable the encoder to generate similar embeddings for images and their textual descriptions. Like word2vec, the training process also requires mismatched images and textual descriptions as negative samples to achieve lower similarity scores.
8Incorporating Text Information into Image Generation
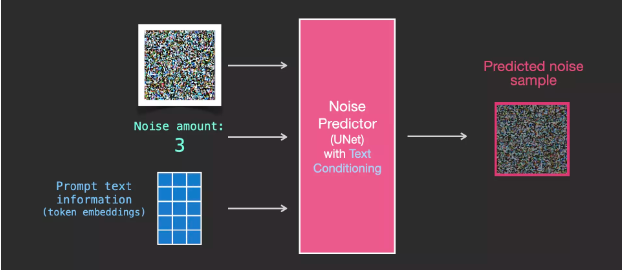
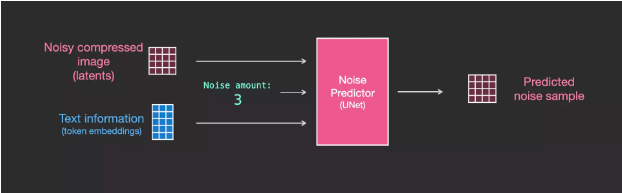
To incorporate text into image generation, we need to adjust the noise predictor to input text.
Now, text is added to the dataset. Since we are operating in latent space, both the input images and predicted noise are in latent space.
To better understand how text tokens are used in UNet, we will further explore the UNet model.
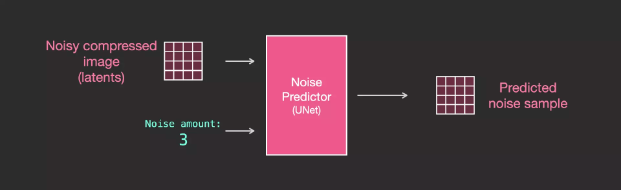
UNet Noise Predictor Layers (Without Text)
First, let’s look at the UNet without text, with the following inputs and outputs:
-
UNet is a series of layers used to transform latents arrays
-
Each layer operates on the output of the previous layer
-
Some of the outputs are fed (via residual connections) into the processing later in the network
-
Through residual connections, the outputs of earlier layers are sent into later layers for processing
-
Time steps are converted into embedding vectors for use in network layers
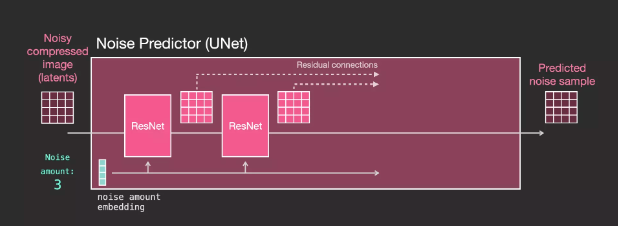
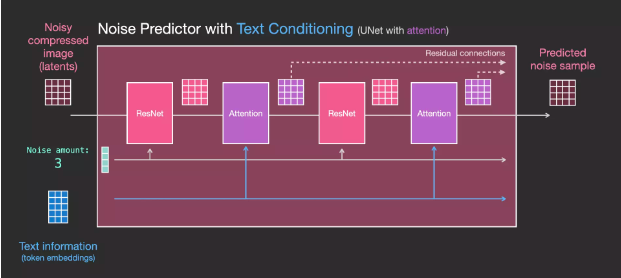
UNet Noise Predictor Layers (With Text)
Now let’s see how to modify the system to increase its focus on text.
To support text input, also known as text conditioning, we need to add an attention layer between the ResNet blocks of the system.
Text information is not processed directly by ResNet but is integrated into the latents through the attention layer. Thus, the next ResNet can utilize the integrated text information during processing.
I hope this article helps you gain a deeper understanding of how Stable Diffusion works. Although many other concepts are involved, once you are familiar with the above sections, these concepts will become much easier to understand. Below are some resources I find very useful.
-
https://www.youtube.com/shorts/qL6mKRyjK-0
-
https://huggingface.co/blog/stable_diffusion
-
https://huggingface.co/blog/annotated-diffusion
-
-
-
-
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
-
(This article is published by OneFlow, compiled and translated based on the CC BY-NC-SA 4.0 license and for reprints, please contact for authorization. Original: Alammar, J (2018). The Illustrated Transformer [Blog post]. https://jalammar.github.io/illustrated-stable-diffusion/)
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。