Paper Title:
SemCity: Semantic Scene Generation with Triplane Diffusion
Authors:
Jumin Lee1, Sebin Lee1, Changho Jo, Woobin Im, Juhyeong Seon, Sung-Eui Yoon
Project Address:
https://sglab.kaist.ac.kr/SemCity/
Compiler: Babata
Reviewer: Los
Introduction:
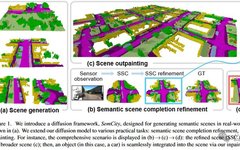
This paper has been accepted by CVPR24 and proposes a 3D diffusion model for generating outdoor real scenes. Utilizing the Triplane Diffusion method, it not only excels in generating outdoor real scenes but also seamlessly extends to tasks such as scene inpainting, scene outpainting, and semantic scene completion refinement.©️【Deep Blue AI】Compiled

Diffusion models are currently mainstream tools for scene generation, achieving great results especially in the image domain. Both academia and industry are actively exploring the application of diffusion models in the generation of 3D data, with some diffusion models also performing well in generating various 3D forms (such as voxels and meshes). Although these 3D diffusion models are mainly aimed at creating single objects, generating scenes composed of multiple objects remains an unexplored area in 3D diffusion.
Scene generation diffusion models aim to create geometrically and semantically coherent environments. Compared to single object generation, generating scenes containing multiple objects requires a deeper understanding of more complex geometric and semantic structures due to its broader spatial scope. Scene generation diffusion models mainly focus on two directions: indoor and outdoor environments. Particularly, outdoor environments present broader landscapes but also greater challenges.
In this paper, the authors propose the SemCity method, a 3D diffusion model for semantic scene generation in real outdoor environments. Specifically, SemCity utilizes Triplane Representation to handle broader outdoor scenes, a method that decomposes 3D data into three orthogonal 2D planes, widely used in 3D object reconstruction and NeRF models. The Triplane Representation method has advantages in addressing the data sparsity issues commonly found in outdoor datasets (due to sensor limitations such as occlusion and range restrictions when capturing outdoor scenes), as it reduces the inclusion of unnecessary blank information by decomposing 3D data into 2D planes.
This efficiency in capturing relevant spatial details makes it an effective tool for representing the numerous objects typically found in outdoor environments.
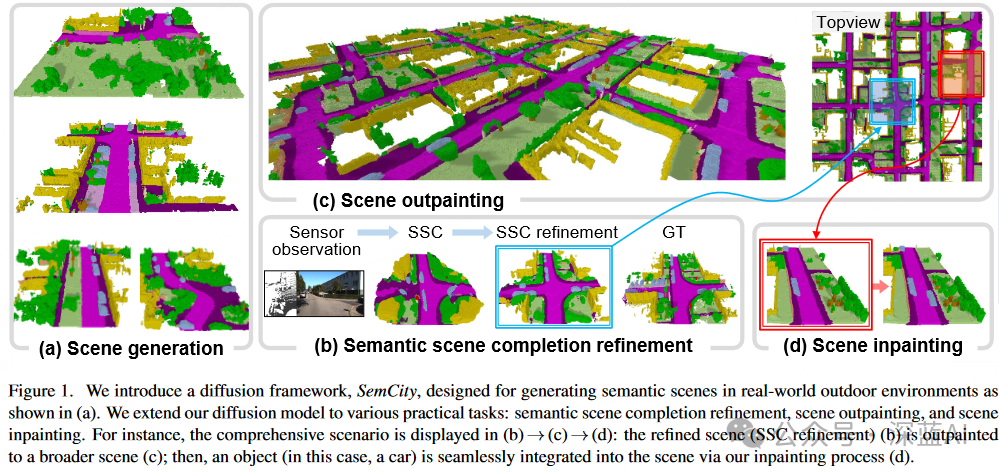
In this paper, the authors learn to compress voxelized scenes into Triplane Representation by reconstructing the semantic labels of the scenes, utilizing a Triplane autoencoder. Furthermore, researchers train a Triplane diffusion model and use it to generate new scenes, as shown in Figure 1(a), by creating new planes based on efficient representation. It can also extend the Triplane diffusion model to several practical tasks (i.e., scene inpainting, scene outpainting, and semantic scene completion refinement), as illustrated in Figure 1(b-d).
 ▲Figure 1|Overview of SemCity Diffusion Model for Outdoor Scene Generation ©️【Deep Blue AI】Compiled
▲Figure 1|Overview of SemCity Diffusion Model for Outdoor Scene Generation ©️【Deep Blue AI】CompiledMain Contributions of This Paper:
● The authors reveal the applicability of Triplane representation in generating semantic scenes for real outdoor environments and extend it to practical downstream tasks such as scene inpainting, scene outpainting, and semantic scene completion refinement.
● They also propose operating on Triplane features during the diffusion process, seamlessly extending this method to downstream tasks (like adding, deleting, or modifying objects in a scene).
● It is clear that this method significantly improves the quality of generated scenes in real outdoor environments.

■2.1 Diffusion Models
Learning data distribution through an iterative denoising process based on score functions. The results generated exhibit a very realistic appearance, high fidelity, and diversity in various 2D image synthesis tasks, such as outpainting, inpainting, and text-to-image generation. Building on these foundations, diffusion models have also been extended to the 3D domain, producing good results in generating various 3D shapes, including voxel grids, point clouds, meshes, and implicit functions. While these models can create single 3D objects, SemCity focuses on generating 3D scenes composed of multiple objects using a classified voxel data structure, which is a relatively unexplored area in the 3D diffusion domain.
■2.2 Diffusion Models for Scene Generation
Compared to single object generation, scene generation involves understanding a larger 3D space, leading to more semantic and geometric complexity. In indoor environments, diffusion models aim to learn the distribution of relationships between objects represented as a scene graph. The scene graph captures object properties (such as location, orientation, and size), capturing complex relationships between objects within a confined space. For outdoor scenes, the difference is that they typically contain large open areas (such as sky and open spaces). Traditional methods rely on discrete diffusion methods on voxel spaces, requiring detailed representations for each air volume, while SemCity abstracts 3D space into three orthogonal 2D planes, effectively capturing the vastness of outdoor environments predominantly consisting of air.
■2.3 3D Inpainting and Outpainting
The main goal of 3D inpainting is to fill in missing parts or modify existing elements while maintaining geometric consistency. Most existing work focuses on single object repair, such as transitioning the number of legs on a 3D chair from three to four. In contrast, 3D outpainting extrapolates a given scene into unseen space. Existing work focuses on scene extrapolation within bounded indoor environments. Similarly, in 3D space, this paper focuses more on scene-level repairs; SemCity can seamlessly add, delete, or modify objects in a scene. Additionally, the scene-level outpainting discussed in this paper is not limited to bounded scenes and can extend from sensor ranges (such as LiDAR) to city-scale outdoor scenes.
■2.4 Semantic Scene Completion
Semantic scene completion (SSC) is crucial for 3D scene understanding, jointly inferring the completion and semantic segmentation of 3D scenes from sensor observations (such as RGB images or point clouds). Furthermore, SSC plays a key role in downstream tasks that support fully autonomous navigation systems (such as path planning and map building). Despite significant progress in this area, a persistent challenge is the semantic and geometric discrepancies between SSC estimated scenes and their real counterparts, as shown in Figure 1(c). These discrepancies can impair the performance of downstream tasks. The Triplane diffusion model proposed in this paper can help bridge this gap by leveraging 3D scene priors. This method improves the reliability and effectiveness of SSC, which is expected to enhance its application in autonomous navigation systems.

This section focuses on the Triplane diffusion model in SemCity and its extensions.
 ▲Figure 2|How SemCity Works ©️【Deep Blue AI】Compiled
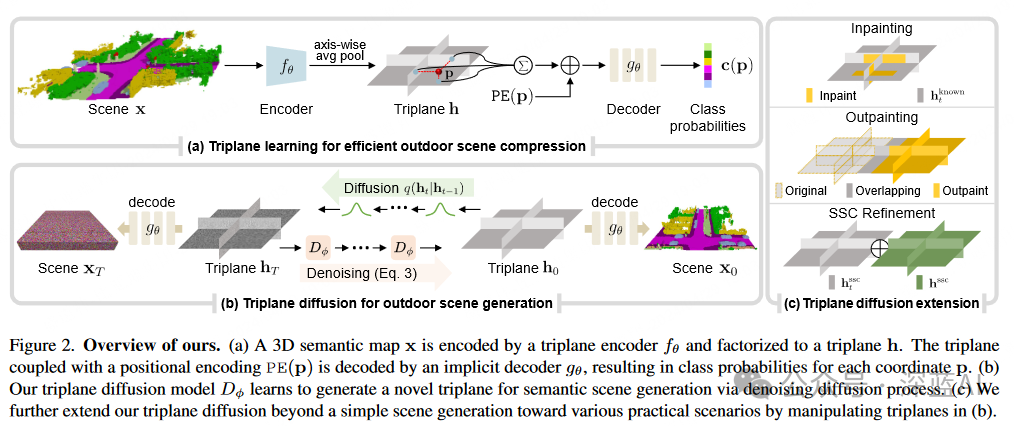
▲Figure 2|How SemCity Works ©️【Deep Blue AI】Compiled■3.1 Representing a Semantic Scene with Triplane
To represent a 3D scene as a Triplane, the autoencoder learns to compress the 3D scene into a Triplane representation as shown in Figure 2(a). The autoencoder consists of two modules:
1) An encoder that produces a Triplane;
2) An implicit multi-layer perceptron (MLP) decoder for reconstructing from the Triplane.
The encoder takes a voxelized scene containing categories, with a spatial grid resolution of. It produces an axis-aligned Triplane representation. The Triplane consists of three planes, each with different dimensional characteristics: and, where represents feature dimensions
■3.2 Triplane Diffusion
where
■3.3 Applications with Triplane Manipulation
As mentioned above, the Triplane diffusion process allows the model to facilitate various practical downstream tasks with minimal modifications.

■4.1 Experimental Details
Training Dataset:The experiments are validated on the SemanticKITTI and CarlaSC datasets. SemanticKITTI provides 3D semantic scene annotations of real outdoor environments with 20 semantic categories. Each scene is represented by a voxel grid of 256×256×32, covering an area of 51.2 meters in front of the vehicle, 51.2 meters on each side, and a height of 6.4 meters. This dataset retains the traces of object movements generated by sensor frame integration, used to establish dense ground truth. In contrast, CarlaSC is a synthetic dataset providing 3D semantic outdoor scenes with 11 semantic categories, without traces of moving objects. This dataset contains voxel grids of 128×128×8, covering an area of 25.6 meters in front and behind the vehicle, 25.6 meters on each side, and a height of 3 meters.
Implementation Details:The experiments are deployed on a single RTX3090 GPU, with a batch size of 4 for the Triplane autoencoder and a batch size of 18 for the Triplane diffusion model. For the Triplane autoencoder, the input scene is encoded into a Triplane with a spatial resolution and feature dimensions of. The loss weight in formula 1 is set to 1.0. The order of the norm in formula 2 is set to 1 for SSC refinement and 2 for other cases. In the diffusion process, default settings are used, with a total of 100 time steps (). For Triplane inpainting and outpainting, the authors adopted the RePaint sampling strategy as a reference, performing 5 resampling and a jump step of 20.
Evaluation Metrics:The performance of semantic scene generation is assessed by examining the diversity and fidelity of 3D semantic scenes in rendered images. Recall is used to evaluate diversity, while accuracy and Inception Score (IS) are used to assess fidelity; Fréchet Inception Distance (FID) and Kernel Inception Distance (KID) metrics are used to reflect the comprehensive impact of diversity and fidelity on scene quality. For the performance of semantic scene completion (SSC) refinement, Intersection over Union (IoU) metrics are used to quantify scene integrity, and mean IoU (mIoU) measures the quality of semantic segmentation.
■4.2 Semantic Scene Generation
As shown in Figure 3, SemCity demonstrates the ability to effectively synthesize detailed scenes even on real datasets. It outperforms SSD in accurately capturing complex building shapes on the CarlaSC dataset. Additionally, this method exhibits exceptional capability in generating overall outlines and details of roads and buildings on the SemanticKITTI dataset. Table 1 provides a detailed comparative evaluation using various metrics. The SemCity model shows significant improvements in both fidelity and diversity of generated scenes. Furthermore, as shown in Figure 4, the generated results are not limited by fixed resolutions, thanks to the implicit neural representation. More results can be found in the supplementary materials provided in the original paper.
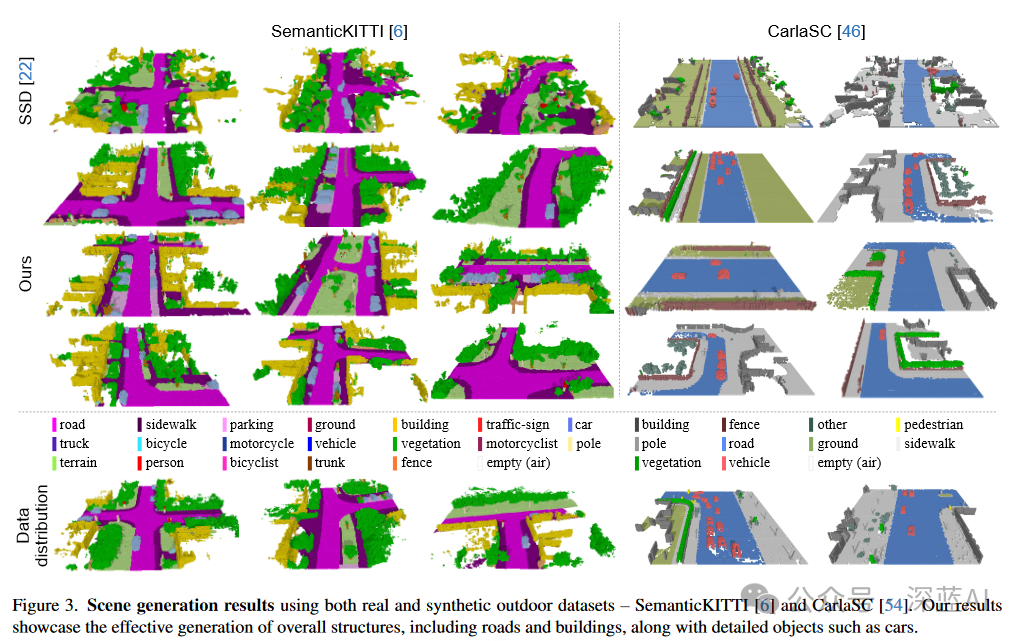 ▲Figure 3|Qualitative Comparison of SemCity on SemanticKITTI and CarlaSC Datasets ©️【Deep Blue AI】Compiled
▲Figure 3|Qualitative Comparison of SemCity on SemanticKITTI and CarlaSC Datasets ©️【Deep Blue AI】Compiled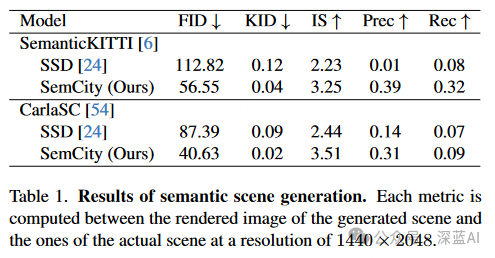 ▲Figure 4|High-Resolution Scene Generation ©️【Deep Blue AI】Compiled
▲Figure 4|High-Resolution Scene Generation ©️【Deep Blue AI】Compiled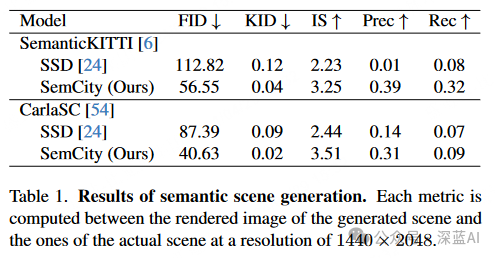
■4.3 Applications of Triplane Diffusion
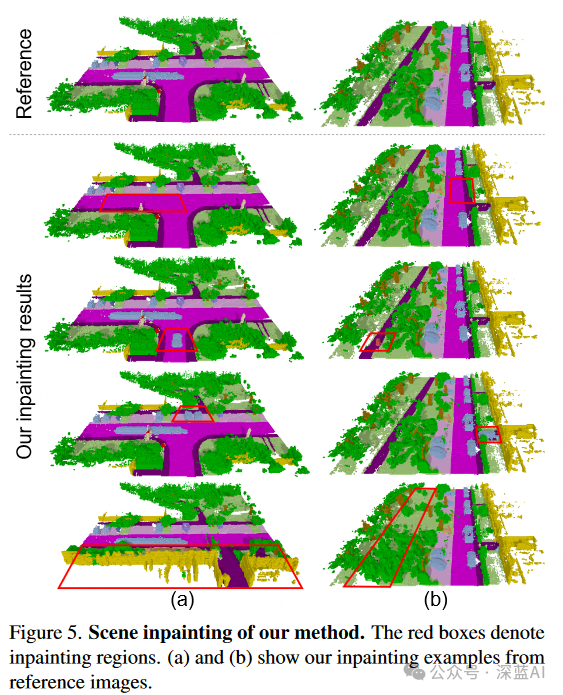
Scene Inpainting: As shown in Figure 5, SemCity demonstrates effectiveness in repairing small and large areas in scenes while maintaining the consistency of the 3D context. Specifically, the second-row examples a and b illustrate the model’s ability to seamlessly remove vehicles, coordinating with adjacent roads. The third-row showcases the ability to insert new entities (a car in a, a person in b) that are contextually consistent with the reference scene. The fourth-row in Figure 5(a) demonstrates the model’s dual capability in modifying and adding vehicles to the scene, while the fifth row highlights the model’s proficiency in altering the scene. Here, the model changes existing scene components, showcasing its ability to alter the overall atmosphere of the scene. These results indicate that the SemCity model excels not only in object-level repairs but also in scene-level repairs.
Scene Outpainting: Figure 6 demonstrates the generated extrapolated city-scale scene, expanding the 256×256×32 scene to a large-scale 1792×3328×32 landscape, showing that SemCity maintains consistency over a large range.
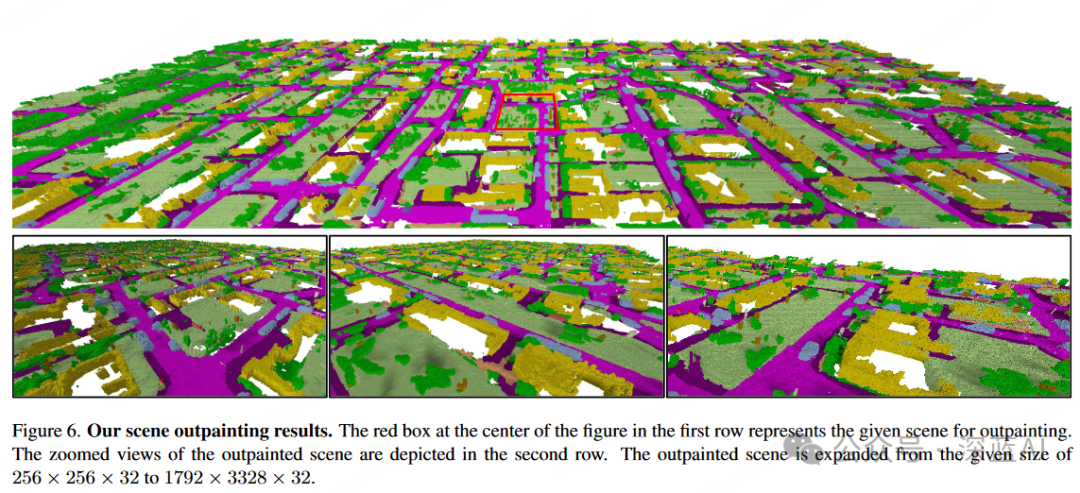 ▲Figure 6|Scene Outpainting Effect ©️【Deep Blue AI】Compiled
▲Figure 6|Scene Outpainting Effect ©️【Deep Blue AI】CompiledSemantic Scene Completion Refinement: In Figure 7, there are noticeable semantic and geometric differences between the scenes predicted by existing semantic scene completion (SSC) methods and their real counterparts. The SemCity model bridges this gap by utilizing 3D scene priors effectively modeled through the authors’ diffusion model. While SSC models exhibit discrepancies with real-world data distributions, the SemCity model shows potential to align these discrepancies more closely with reality. As shown in Table 2, the SSC refinement process of SemCity seems to provide improvements over all state-of-the-art SSC models. These preliminary results indicate that the SemCity model can provide not only more accurate semantic segmentation but also more complete scenes.
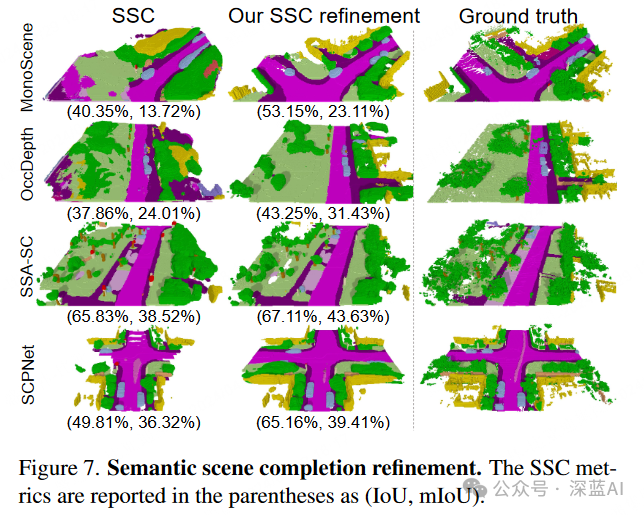 ▲Figure 7|Semantic Scene Completion Effect ©️【Deep Blue AI】Compiled
▲Figure 7|Semantic Scene Completion Effect ©️【Deep Blue AI】Compiled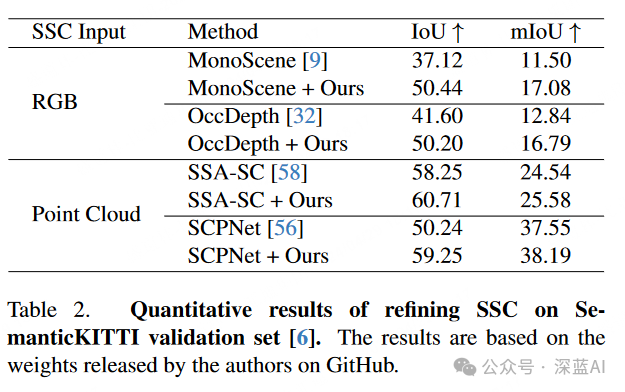 ▲Table 2|Quantitative Results of Refining SSC ©️【Deep Blue AI】Compiled
▲Table 2|Quantitative Results of Refining SSC ©️【Deep Blue AI】CompiledSemantic Scene to RGB Image: As shown in Figure 8, through image-to-image generation experiments. The semantic map is presented from a driving perspective without shadows, serving as input for ControlNet. The generated RGB image is reasonable both geometrically and semantically, but due to the pre-trained ControlNet not being trained on real autonomous driving datasets, it only shows a certain level of synthesis quality.
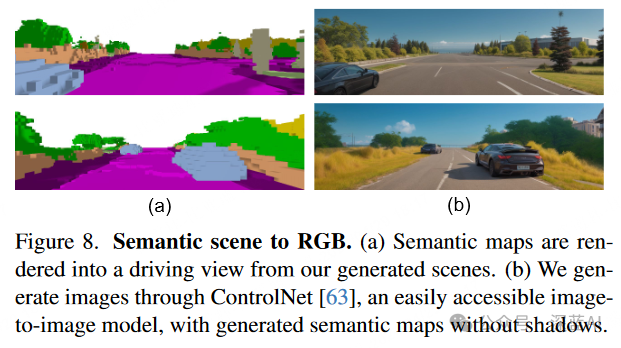 ▲Figure 8|Semantic Scene to RGB Image ©️【Deep Blue AI】Compiled
▲Figure 8|Semantic Scene to RGB Image ©️【Deep Blue AI】Compiled■4.4 Ablation Studies
As shown in Table 3, the authors also conducted ablation studies on the Triplane diffusion model, focusing on two key design elements:
Position Embeddings: — Variants of SemCity that exclude position embeddings () result in a loss of crucial high-frequency features for detailed scene reconstruction. Their absence leads to performance degradation across all metrics.
Triplane Representation: — Additionally, the authors evaluated the effectiveness of Triplane representation in generating real outdoor scenes. Compared to 3D features, Triplane and planes can improve generation quality, while plane performance is lower than that of Triplane. A possible reason is that excessive factorization limits the representational capability of planes compared to Triplane.
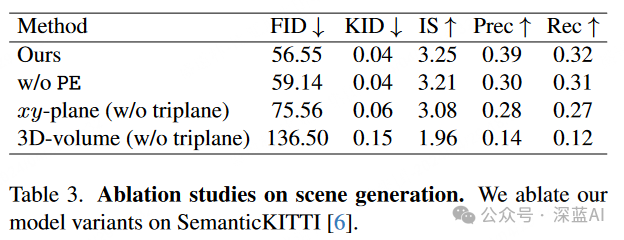 ▲Table 3|Ablation Study Results for Scene Generation ©️【Deep Blue AI】Compiled
▲Table 3|Ablation Study Results for Scene Generation ©️【Deep Blue AI】Compiled■4.5 Limitations
Despite significant progress made by the SemCity model in generating 3D real outdoor scenes, it inherently reflects the characteristics of the training data. This dependency brings some limitations. One obvious challenge is that the model struggles to accurately depict occluded areas from the sensor’s perspective, such as the rear sides of buildings, often resulting in incomplete representations of these areas in the generated scenes. Additionally, since the dataset was captured from a driving perspective, it cannot fully capture the full height of buildings. This results in the vertical structures of buildings and other tall elements in the scene being only partially represented. Another issue is that the model tends to produce traces of moving objects derived from the dataset’s preprocessing of merging consecutive frames.

In this paper, the authors propose the SemCity diffusion framework for generating real outdoor scenes. Its core idea is to generate scenes by decomposing real outdoor scenes into Triplane representations. It leverages the advantages of Triplane representations over traditional voxel methods, producing scenes that are not only visually more appealing but also richer in semantic details, effectively capturing the complexity of various objects in the scene, and due to the introduction of implicit neural representations, this method is also not limited by fixed resolutions. Moreover, by extending the capabilities of the Triplane diffusion model, the SemCity model can be applied not only to scene inpainting, scene outpainting, and semantic scene completion refinement but also better align the predictions of existing semantic scene completion methods with actual data distributions using 3D prior knowledge.

The favorite SOTA algorithm for autonomous driving companies is here! CVPR2024: HPNet – generating accurate and stable future trajectories!
2024-05-05

A Guide to Doubling the Efficiency of Large Language Models: One-Stop Optimization Guide
2024-04-30

【Deep Blue AI】is recruiting authors long-term, welcoming anyone who wants to turn their scientific and technical experiences into writing to share with more readers! If you want to join, please click the tweet below for details 👇

Deep Blue Academy Author Team is strongly recruiting! Looking forward to your joining

【Deep Blue AI】‘s original content is crafted with the personal dedication of the author team. We hope everyone will respect the rules of originality and cherish the authors’ hard work. For reprints, please privately message the backend for authorization and be sure to indicate that it comes from【Deep Blue AI】 WeChat public account, otherwise legal action will be taken for infringement.
*Click to view, save and recommend this article*