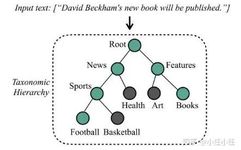

Hierarchical Attention-based
Framework Introduction
Hierarchical Text Classification (HTC) refers to a given hierarchical label system (typically a tree structure or directed acyclic graph structure) that predicts the label path of the text (the parent node labels contain the child node labels along the path). Generally, there is at least one label at each level, making it a path-based multi-label classification task.
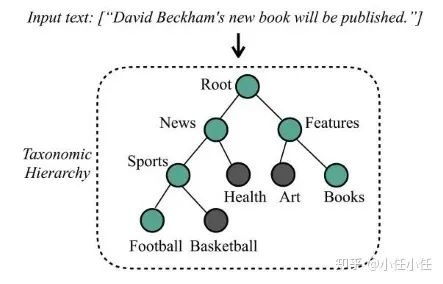
▲Tree-like Hierarchical Label System
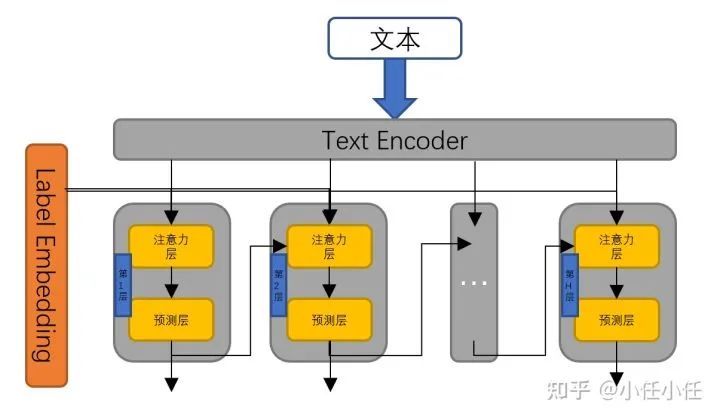
In addition to the main framework description above, there are some optional components:
● Units can either share parameters or not.
● The results from the Units are local results for each layer, and there can also be a global result, which is combined for the final output.
● Generally, the order of Units is top-down, but a bottom-up sequence of Units can also be added for a bidirectional approach.
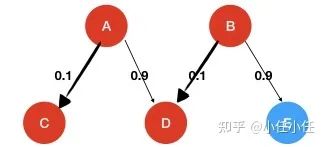
▲ Assuming the upper-level labels A and B have been predicted, and the lower-level labels C and D have been predicted, the correct paths are A->C and B->D, then the issue of path decoding arises
Paper:Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach
Paper link:
http://base.ustc.edu.cn/pdf/Wei-Huang-CIKM2019.pdf
Open-source code:
https://github.com/RandolphVI/Hierarchical-Multi-Label-Text-Classification
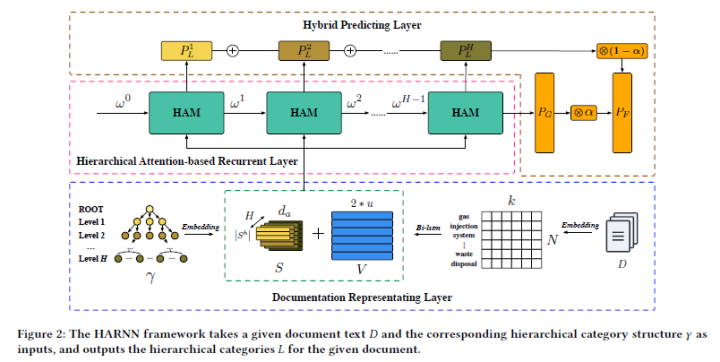
▲ Overall Structure of the Model
●Token Representation Vectors: Given a text sequence of length N
■ The text passes through word2vec to obtain the embedding vector for each token
■ Then it goes through BILSTM, concatenating the forward and backward vectors to obtain the representation vector V for each token, where u is the size of the BILSTM’s hidden state
■ For the entire text, average pooling is used to obtain the overall representation
●Hierarchical Label Representation Vectors
■ Randomly generate an embedding for each label in the multi-layer label system
■ Then assemble them into hierarchical category representation vectors S based on the multi-layer label system, where H is the number of layers in the multi-layer label system, is a matrix of the embedding of all labels at the i-th level, is the number of labels at the i-th level, and is the dimension of the embeddings.
Here, they consider using recurrent neural networks to model the relationships between levels. Below is an introduction to the Unit proposed in their RNN structure: Hierarchical Attention-based Memory (HAM)
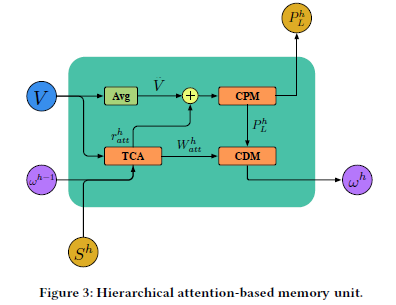
▲HAM Unit
-
Text-Category Attention (TCA): Obtains the relationship between the text and the current level -
Class Prediction Module (CPM): Based on the results of TCA, CPM generates the representation for the current level and predicts the current category -
Class Dependency Module (CDM): Generates the information from the current layer to the next layer
The input to the HAM unit is:
-
Text representation sequence 
-
Current layer’s label representation 
-
Information passed down from the previous layer
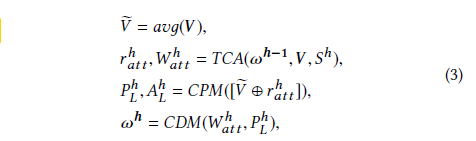
In the above formula:
> Input is:
● : Information passed from the previous layer, which is the attention of each token from the previous layer
● : Token representation
● : Current layer’s label representation
> Output is:
● : The attention score for the text-label at the h-th layer
● : The text-label representation at the h-th layer, which is the text representation influenced by the h-th layer label
CPM: is for prediction
CDM: is to model the dependencies between different layers
> Input is:
● : The attention score for the text-label at the h-th layer (output of TAC)
● : Sigmoid value for each label at the h-th layer (output of CPM)
> Output is:
● : Attention values for all tokens at the h-th layer
Next, we will detail the three components:
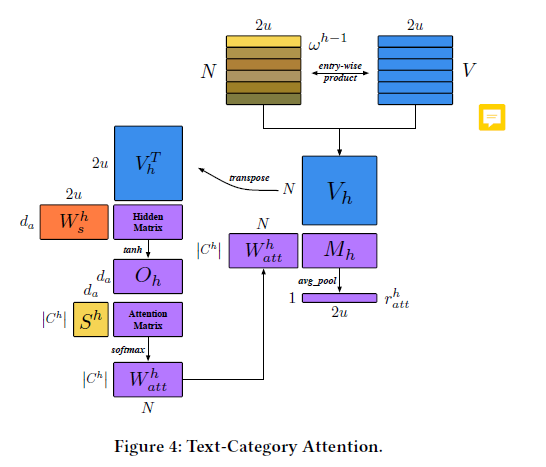
▲TCA Structure
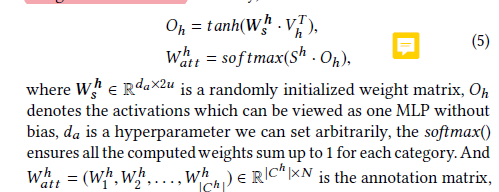
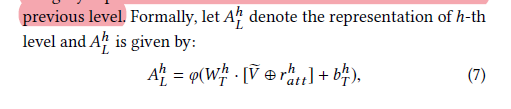

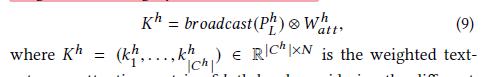
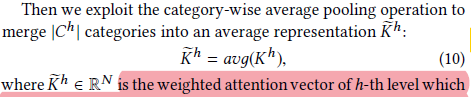
● Finally, broadcast this to obtain the information passed to the next layer , to be multiplied with the text representation in TCA.

Although the prediction results for each layer have been obtained in the above RNN structure, they believe this is a local result. Therefore, they put all the results together and predict again to generate a global result:
● All representations from each layer are combined, and then average pooling is performed across layers:
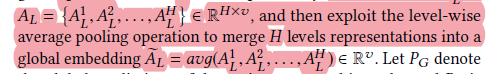
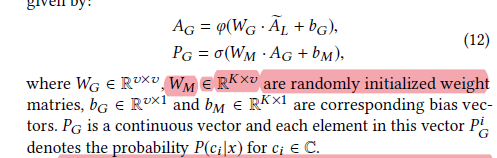
● Finally, the local and global results are merged: the parameter alpha=0.5. They conducted experiments varying alpha and found that when alpha=0.5, it performed significantly better than using just Global or Local results.

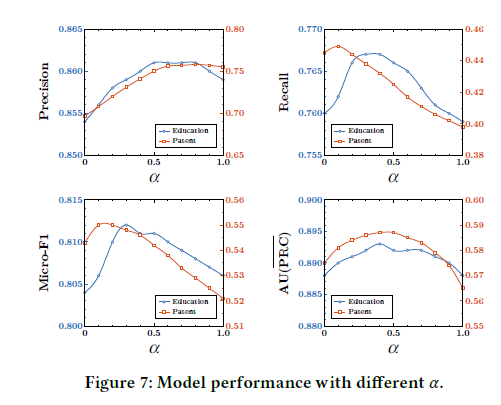
▲ Experiment on Alpha
● Finally, the local and global losses are calculated using BCE, along with L2 regularization, as the final loss.
The results are quite good, significantly better than the previous HMCN.
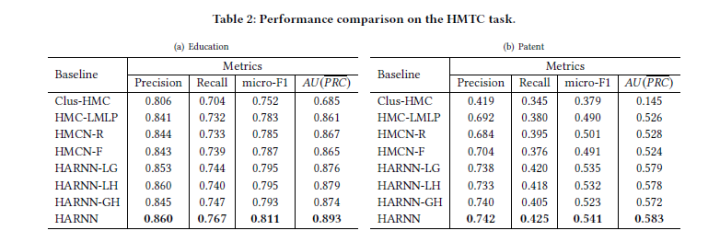
▲ 1) HARNN-LG does not consider the dependencies between different layers; 2) HARNN-LH does not consider the information from the entire multi-layer structure; 3) HARNN-GH does not consider Local information
Paper:Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification
Paper link:
https://aclanthology.org/2021.acl-long.388/
Open-source code:
https://github.com/wxpkanon/CLEDforHTC

▲ Model Structure
-
Text Encoder: Obtains token representations -
Concept-based Classifier Module: Responsible for encoding and classification at each layer, which is also the main module of the paper -
Concept Share Module: Mainly generates label representations based on the concept and label hierarchy -
Label Embedding Attention Layer: Primarily generates text representations concerning this layer’s labels -
Classifier: Just for classification
After obtaining text embeddings, CNN is used to extract n-gram features, and then BiGRU is used to extract contextual features, resulting in the representation for each token .
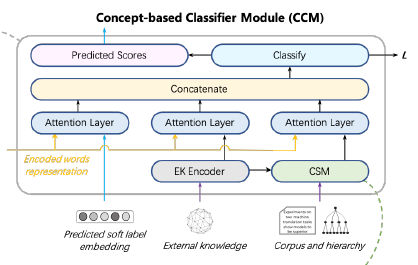
The input to this module is the token representation S of a text sequence of length |d| and the label embeddings for the i-th layer of length . The specific steps are as follows:
● Calculate the cosine similarity matrix G between the text representation and the label embeddings, where G has dimensions
● Use a convolution kernel F to extract features of length k around the p-th word. Theoretically, the dimensions are
● Next, apply max pooling to obtain the maximum correlation of the p-th word to the i-th layer label (since even if two labels are related to the p-th word, only the maximum one is needed).

●External Knowledge is obtained through the EK Encoder, and attention is applied between it and the text representation. Here, External Knowledge refers to the textual descriptions of the labels, and the EK Encoder averages the word embeddings of the label descriptions.
●Predicted soft label embedding is the sum of the EK Embedding of the labels predicted from the previous layer.
●Concept Share Module: is the concept-based label embedding for this layer, which is obtained through attention with the text representation. Below, we will introduce how the concept representations are derived.
This section mainly introduces how the concept representations are derived. In CSM, concept embeddings are first obtained using a Concepts Encoder, and then concept-based label embeddings are derived via Dynamic Routing.
We know that a concept is represented by n keywords, and the method for obtaining the concept has been introduced above.
※2.2.1 Concepts Encoder
※2.2.2 Concepts Sharing via Dynamic Routing
They modified the dynamic Routing mechanism from CapsNet to allow routing only between a category (layer l) and its subcategories (layer l+1).
The general idea is that a particular subclass may only be related to a portion of the parent class’s concept words. Therefore, each concept word from the parent class is allowed to perform attention with the subclass, attempting to generate the subclass’s concept-based label embedding using only the relevant concept words from the parent class.

▲Dynamic Routing Steps
The classifier’s input comes from the outputs of the three Attention Layers, which are:
● : The text representation obtained from the previous layer after attention,
● : The label embedding obtained by averaging the word embeddings of the external knowledge (class definitions), which is then used for attention with the text to obtain the text representation.
● : The text representation obtained through attention with the concept-based label embedding;
All three inputs are concatenated, passed through linear mapping, and then softmax is applied to obtain the final output:
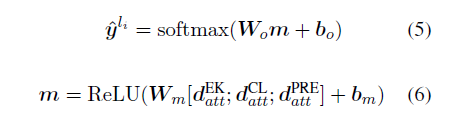
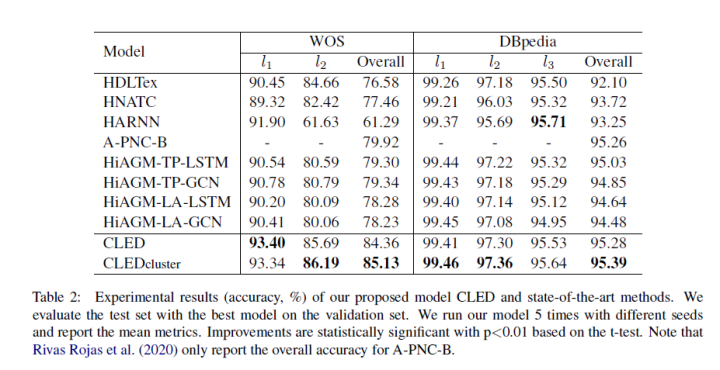
▲ Much better than HARNN and also significantly better than HIAGM
It can be seen that CLED performs much better than previous models, achieving SOTA on these two datasets at the time. During discussions with peers, several points were noted:
● On WOS, other papers like HIAGM report Micro-F1 (which is accuracy in multi-class scenarios) at 85%+, while Macro-F1 is around 79. However, comparing the two papers reveals that the data splits are quite different; CLED has less training data but more test data. HIAGM’s results should be from their re-run experiments.
● HARNN performs well on DBpedia, but poorly on WOS. I consider that the data volume may have some impact, as the training data for DBpedia is 278K, while WOS has only 28K. Additionally, HARNN’s label embedding is randomly initialized, which I speculate may have some influence.
-
w/o CL is the removal of concept-based label embedding, -
w/o EK is the removal of the extra attention module -
w/o PRE is the removal of information passed from the previous layer -
w/o reference in CSM is the removal of the initialization using EK for the CSM module -
w/o DR is the removal of dynamic Routing
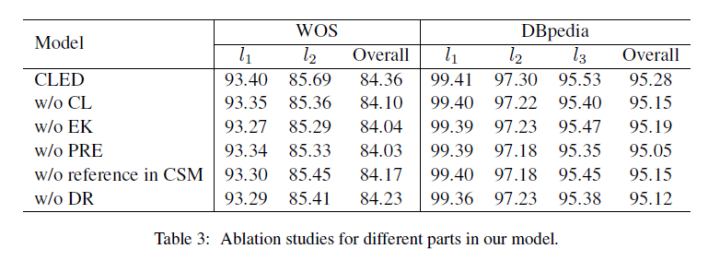
▲ Although removing different modules results in some degree of performance degradation, it can be seen that removing the input from the previous layer has the most significant impact.
Although each component shows a slight decrease in performance when removed, the most significant reduction is seen when the PRE component is removed, indicating that the results passed from the previous layer are quite important. Additionally, the concept-based label embedding proposed in this paper also has a certain impact when removed, but it is not the most significant. This concept seems quite good (essentially compensating for the insufficient refinement of the label hierarchy in the dataset), although it has some effect, it may not be substantial. However, it should not be ruled out that in some datasets, the relationships between upper and lower layers may not be closely tied, and the concept hypothesis may not hold in such cases.
Finally, here are some thoughts:
● Why not add a step to generate the current Label embedding using the current label’s concept? It seems worth trying.
● If Label Embedding could be further encoded through graph networks or TreeLSTM, etc., it would effectively incorporate the label hierarchy structure (referencing HIAGM, HGCRL, etc.), which could potentially enhance the results.
To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2)Please specify the specific direction + relevant technical pointsAbout AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include text summarization, intelligent Q&A, chatbots, machine translation, automatic generation, knowledge graphs, pre-trained models, recommendation systems, computational advertising, recruitment information, and job experience sharing. Welcome to follow! To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction + purpose for joining the group.
Having read this far, please share, like, or give feedback 🙏