
For all source code in this tutorial, please visit Github:
https://github.com/zlsdu/Word-Embedding
1. Word2vec
1. Gensim Library
The gensim library provides implementations of the Word2vec cbow model and skipgram model, which can be called directly.

Full reference code
2. TensorFlow Implementation of Skipgram Model
The skipgram model predicts context words based on a center word; there are many online resources available, including the original paper.
The data used for this model experiment is from the Chinese Wikipedia, available in both original and tokenized versions. The data is large, and you can download it from Github. For detailed implementation, refer to the code, which contains comments at key points. Here, I want to mention the commonly used nce loss function in Word2vec, defined as follows:

Let’s explain the parameter sampled_values. From the TensorFlow source code for nce_loss, we can see that when sampled_values=None, the sampling method is to preferentially sample high-frequency words as negative samples in Word2vec.
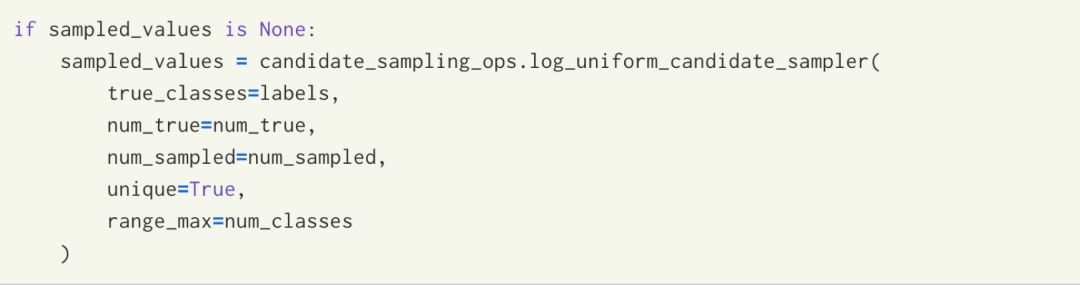
The above image shows the parameter list for nce_loss during actual usage, along with the meanings of each parameter. Next, let’s look at the implementation logic of the nce_loss function in the TensorFlow source code:

For the complete details of the TensorFlow implementation of the skipgram model, refer to the code. The training and testing results can be seen in the following images:


2. Fasttext Chinese Word Vector Training
1. Introduction to Fasttext Word Vector Practice
Facebook has released the official code for Fasttext on GitHub for text classification and word vector training, which can be directly used for Chinese word vector training. The download URL is:
https://github.com/facebookresearch/fastText
After downloading, you first need to compile it using make, and once the compilation is successful, you can directly use the following commands for Chinese word vector training, adjusting the parameters as needed:
$./fasttext skipgram -input data/fil9 -output result/fil9
The above command uses skipgram for word vector learning, and you can also use cbow for word vector learning:
$./fasttext cbow -input data/fil9 -output result/fil9
Adjustable parameters include: word vector dimension, subwords range, epoch, learning rate, thread
$./fasttext skipgram -input data/fil9 -output result/fil9 -minn 2 -maxn 5
-dim100 –epoch 2 –lr 0.5 –thread 4
You can also use the trained word vector model for word vector printing and querying similar word vectors. Naturally, before training, you need to prepare the data, i.e., prepare Chinese tokenized or character-separated text data as input.
For a detailed word vector training process and the meanings of various parameters, please refer to the blog:
https://blog.csdn.net/feilong_csdn/article/details/88655927
3. GloVe Chinese Word Vector Training
GloVe can be used to train Chinese word vectors through the officially released model. The steps are as follows:
1. First, download GloVe from the official site and unzip it:
https://github.com/stanfordnlp/GloVe
2. Prepare the training corpus, ensuring tokenization and stopword removal, and place it in the GloVe root directory.
3. Modify the demo.sh file. There are two modifications required, as shown in the image below:
4. In the GloVe root directory, execute the command to compile: make
5. In the GloVe root directory, execute the command to train word vectors: bash demo.sh
If the training data is large and the training time is long, use the following command to train word vectors:
nohup bash demo.sh > output.txt 2>&1 &
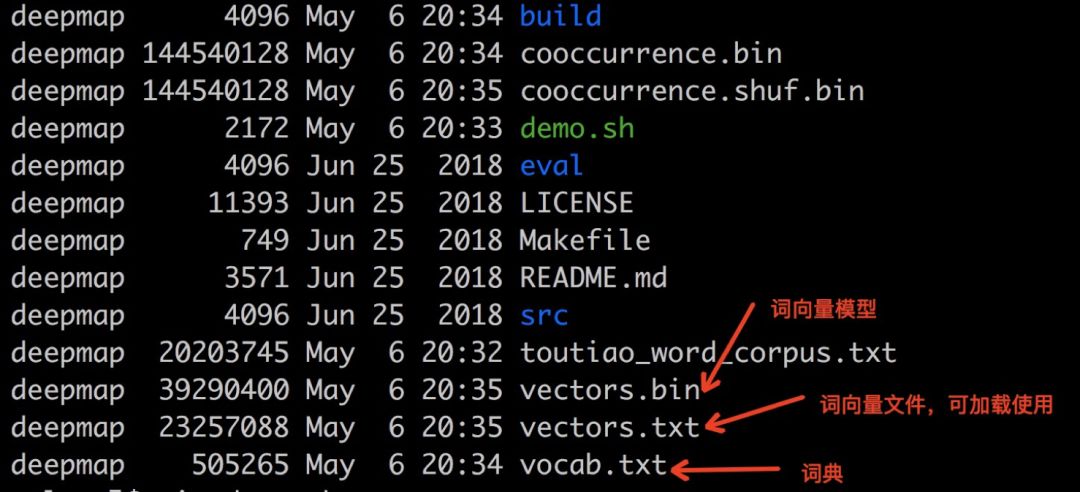
Upon successful training, you will get a vectors.txt file, which can be loaded using the gensim Word2Vec module.
The effect of the word vectors trained by GloVe is as follows:

Using gensim to load the GloVe-trained word vectors, the difference between GloVe and Word2vec in terms of the word vector file is that Word2vec includes the number of vectors and their dimensions.

You can use gensim to load GloVe-trained word vectors, so first convert the GloVe format word vectors to Word2vec format, then load the GloVe-trained word vector model using gensim.models.KeyedVectors.load_word2vec_format().
4. Elmo Word Vector Training
Elmo differs from Word2vec, Fasttext, and GloVe in that it produces dynamic word vectors, meaning that the word vectors obtained from ELMo are not fixed; they vary based on the context of the sentence. Currently, there are two implementation methods for training Elmo word vectors:
1. Training English Word Vectors
Using the tensorflow_hub library, here is a simple example of how to use the tensorflow_hub library to load the Elmo model for word vector training, followed by a complete Elmo example code. The pre-trained Elmo word vectors are used for downstream tasks.
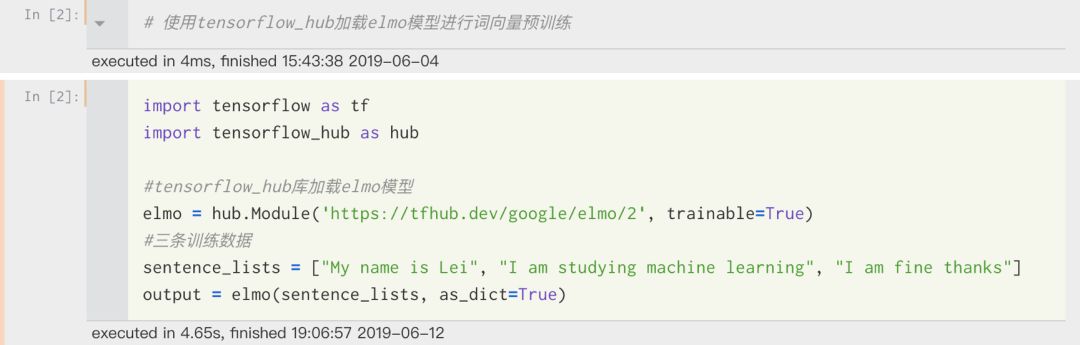
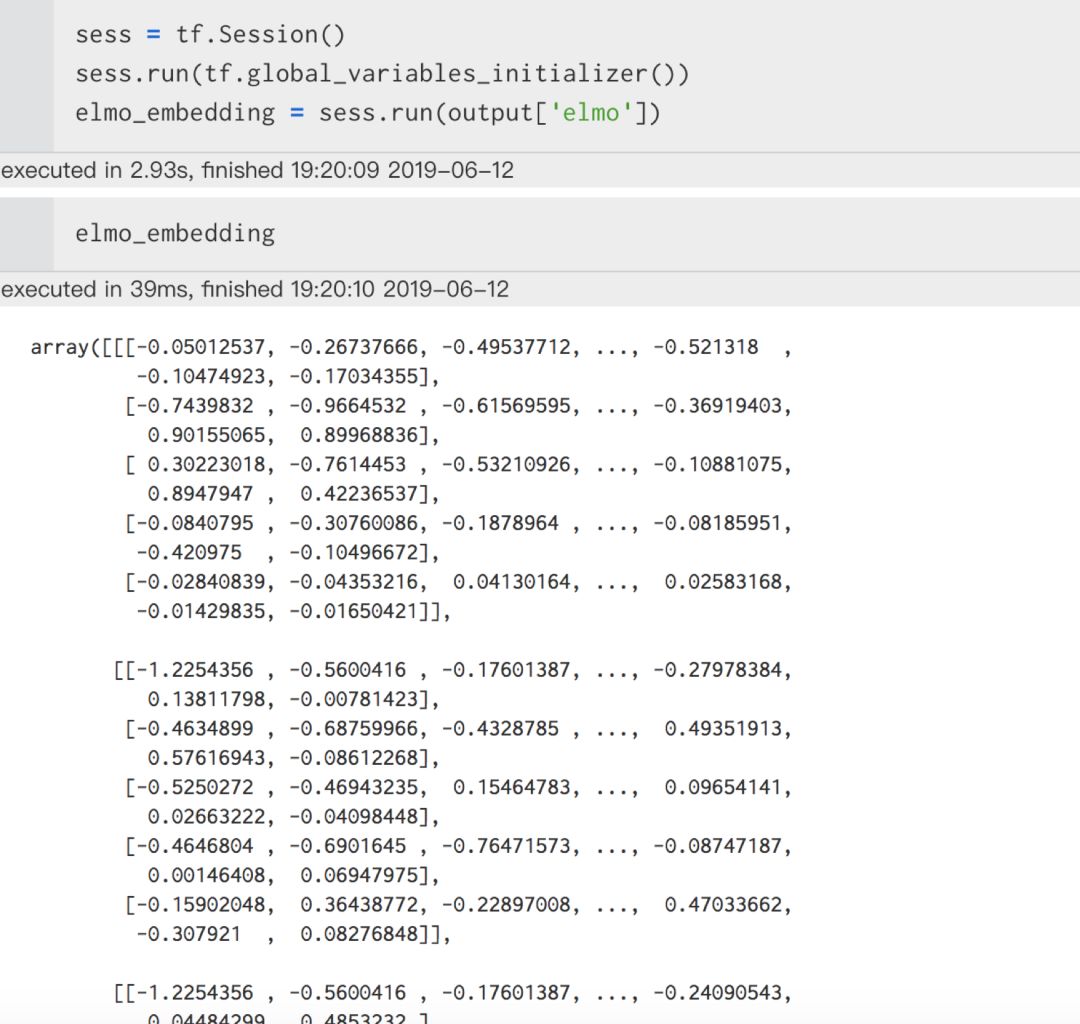
As shown above, by loading the Elmo model through tensorflow_hub, we obtained the output. Let’s print the output to see what it is.
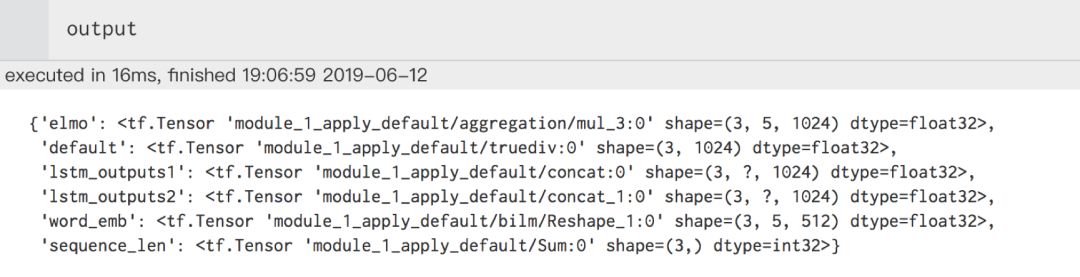
From the above image, we can see that the Elmo model training resulted in a dictionary, where the keys include elmo, default, lstm_output1, lstm_output2, word_emb, and sequence_len. Let’s explain one of the keys:
(1) sequence_len: Length of each sentence in the input
(2) word_emb: The first layer of character-based word embedding from Elmo, with shape [batch_size, max_length, 512]
(3) lstm_output1/2: The hidden state outputs of the first and second layers of LSTM in Elmo, with shape [batch_size, max_length, 1024]
(4) default: The previous outputs are word-level vectors; default provides the sentence-level vector obtained using mean-pooling, which averages all words from the Elmo output.
(5) elmo: The final word vectors obtained by linearly weighting the input layer (word_emb), the first layer LSTM output, and the second layer LSTM output. This linear weight is trainable, with shape [batch_size, max_length, 1024].
Note the Attention, the red Attention: Under normal circumstances, we use output[‘elmo’] to obtain the Elmo word vectors for subsequent tasks.
We can print the dynamic word vectors we just trained for downstream tasks.
For detailed usage of pre-trained ELMo for downstream tasks, please refer to the source code.
2. Train Chinese Word Vector Model Based on Your Own Corpus
Modify the official TensorFlow version to train your own Chinese corpus to obtain an Elmo model suitable for Chinese word vector training. The general steps are as follows:
(1) Prepare your own tokenized Chinese corpus data.
(2) Use the corpus to generate vocabulary data.
(3) Pre-train word2vec word vectors.
(4) Download the BILM-TF code from GitHub: https://github.com/allenai/bilm-tf
(5) Modify the BILM-TF code to train Chinese word vectors; the following will detail how to do this.
This experiment used news classification data.

Note two points:
(1) Pre-trained word2vec word vectors only need to be pre-trained on the corpus as mentioned above.
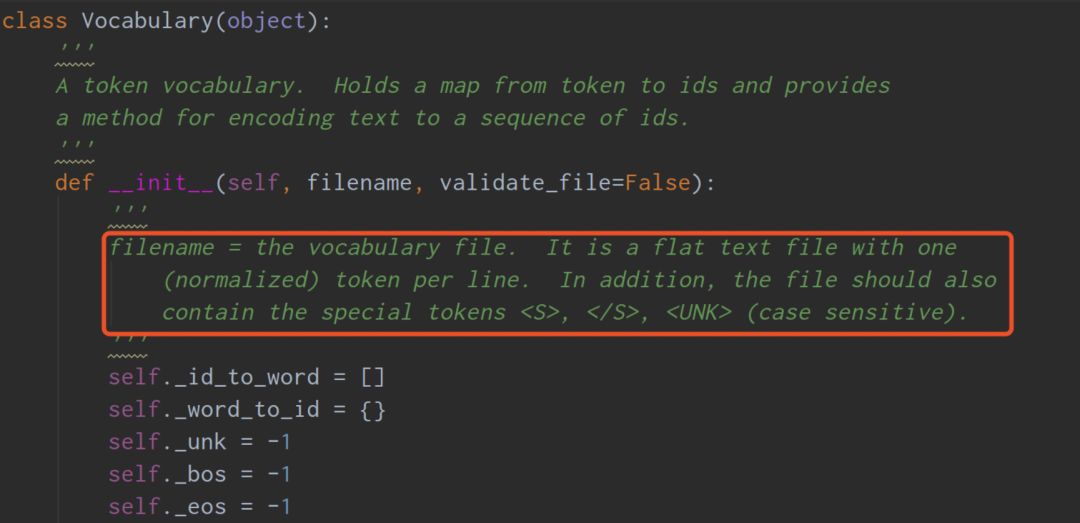
(2) Vocabulary data vocab.data: Use the corpus to generate the vocabulary, but you need to add three lines , ,

This is necessary because the BILM-TF source code requires these first three lines to be read in when loading the vocabulary, as shown in the image below.
After downloading the BILM-TF source code, we will focus on how to modify the code for training on Chinese corpus.
(1) Modify bin/train_elmo.py file
This file is the program entry point, and the modifications are as follows:
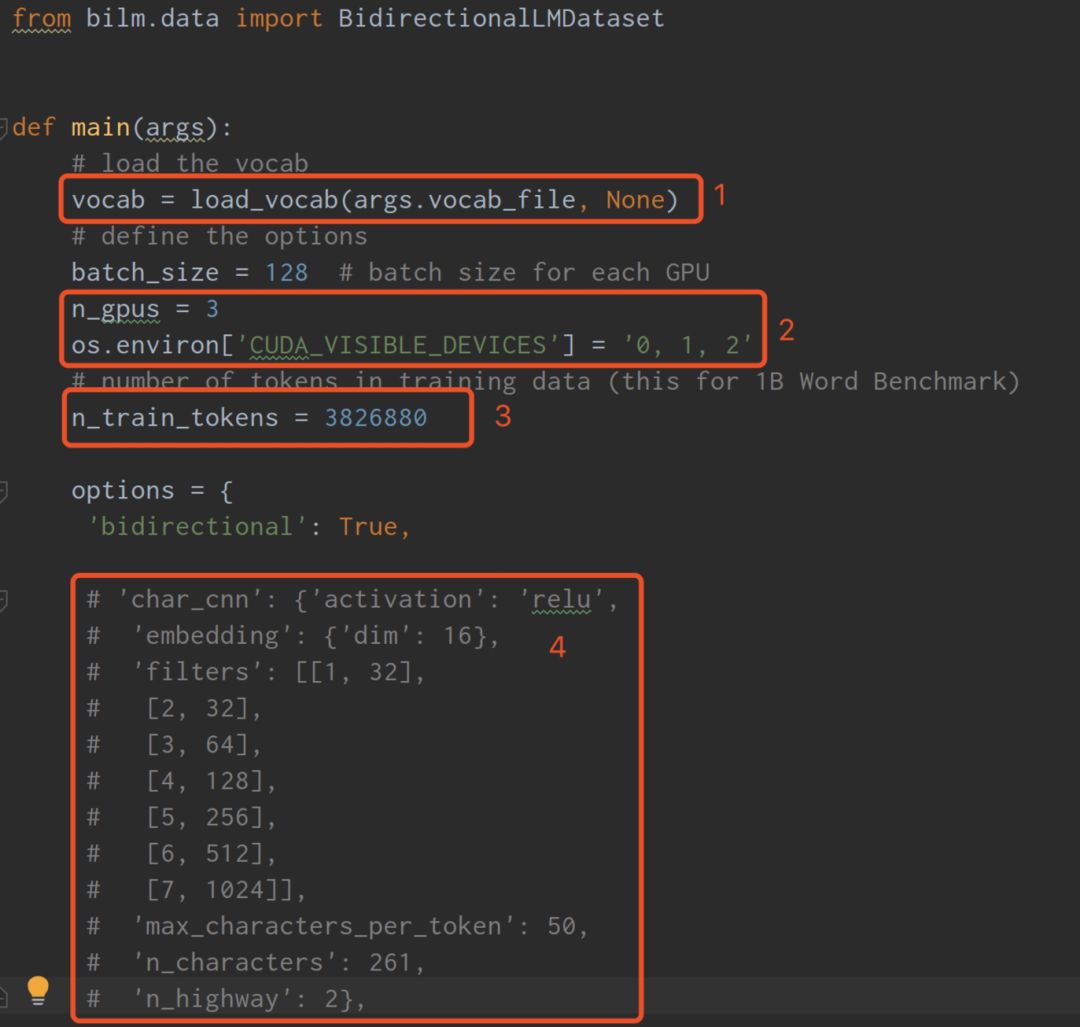
Explanation:
1. Change the second parameter of the load_vocab function to None.
2. Set the number of visible GPUs for the Elmo program.
3. n_train_tokens: Its size indirectly affects the number of iterations of the program, which can be set according to the size of the corpus.
4. Comment out this part completely.
(2) Modify bilm/train.py file
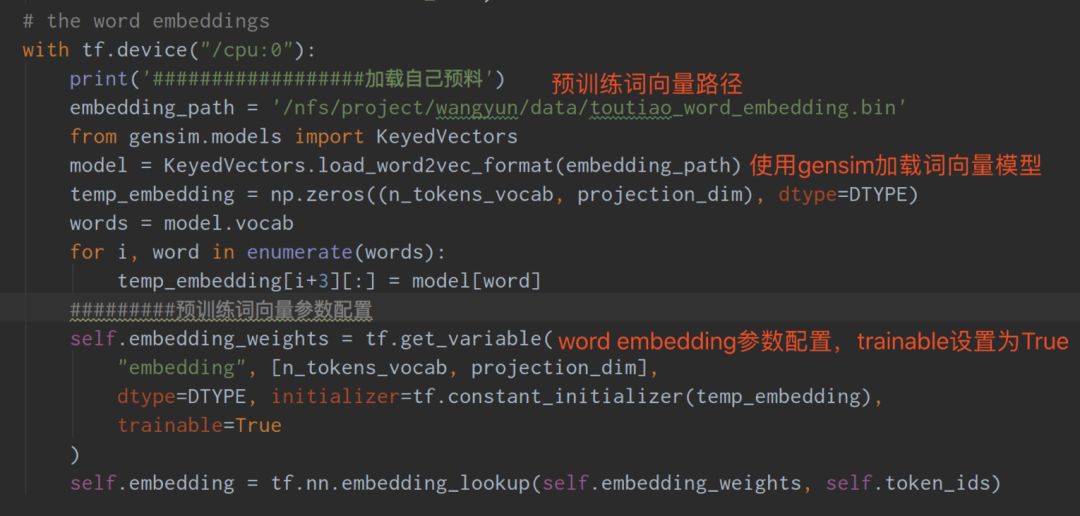
As shown in the image, first modify the loading of the pre-trained word vector information, initialize Word Embeddings, and set the parameter trainable to True. Secondly, modify another part as shown in the image to save the final model.embedding_weights to an HDF5 file.

(3) In the bilm-tf directory, start the training program. The start command is as follows:
nohup python -u bin/train_elmo.py \
–train_prefix=’/nfs/project/wangyun/data/toutiao_word_corpus.txt’\
–vocab_file/nfs/project/wangyun/data/vocab.data \
–save_dir/nfs/project/wangyun/bilm-tf/model >output 2>&1 &
The parameter train_prefix is the path to the training corpus.
The parameter vocab_file is the path to the prepared vocabulary.
The parameter save_dir is the path where the model is saved during execution.
After a long time, upon completion, the model files will be generated as follows:
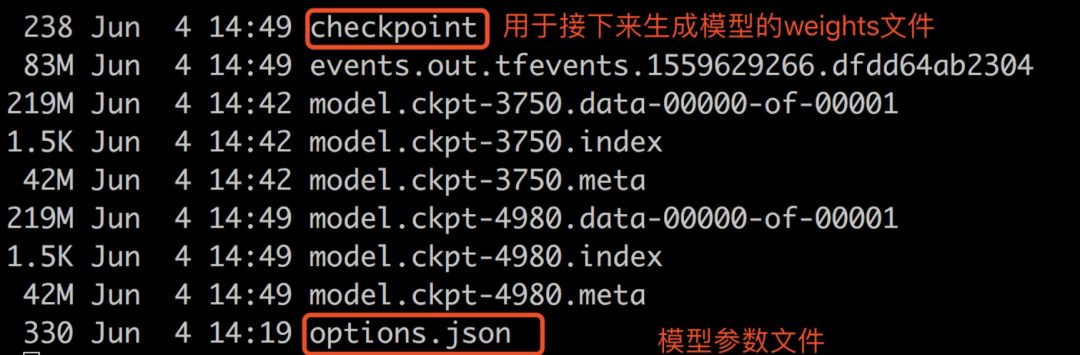
(4) In the bilm-tf directory, run bin/dump_weights.py to convert the checkpoint into an HDF5 file.
python -u bin/dump_weights.py \
–save_dir/nfs/project/wangyun/bilm-tf/model2 \
–outfile/nfs/project/wangyun/bilm-tf/model2/weights.hdf5
The final model file will be as follows:
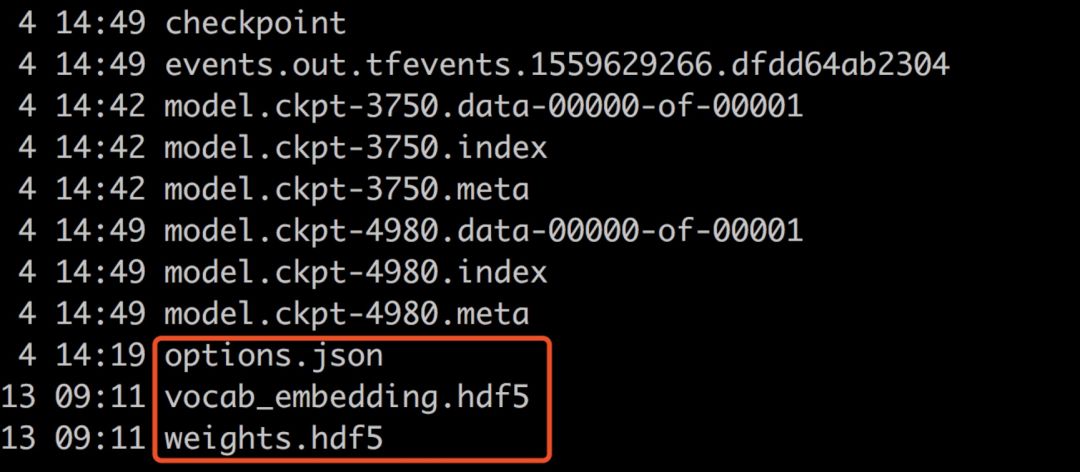
Thus, the Elmo Chinese model training is complete. We have obtained the vocab.data corresponding vocab_embedding.hdf5 file, as well as the Elmo model corresponding weights.hdf5 file and options.json file. You can use the usage_token.py file to train and obtain word vectors.
(5) Modify the usage_token.py file and run it to obtain word vectors.
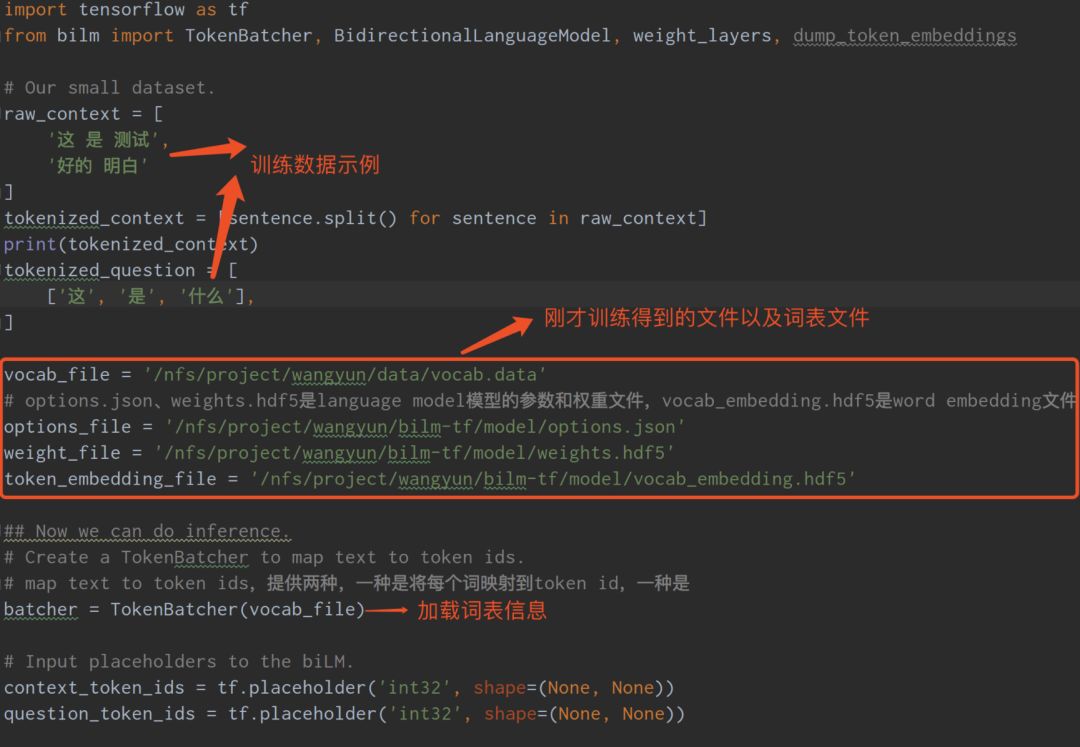

Run python usage_token.py: to obtain the word vector data.
5. Bert Sentence and Word Vector Training
Bert training of sentence and word vectors mainly utilizes the bert-as-service library for training. Install the bert-as-service environment on the server and start the service to complete the training of sentence vectors and context-related word vectors similar to Elmo, as shown in the image below:

Note that the obtained results are Word piece Embeddings rather than Word Embedding. When using Bert, the fine-tuning effect using the Bert model is much better than using Bert Embedding. Therefore, we will not provide a detailed introduction to Bert Embedding. If you wish to use it, please refer to the following two URLs for detailed instructions:
https://github.com/hanxiao/bert-as-service
https://bert-as-service.readthedocs.io/en/latest/tutorial/token-embed.html
6. Flair Embedding
FlairEmbedding is a feature from the Flair community project, which includes:
(1) Flair is a powerful NLP library that allows state-of-the-art models to be applied to text, including NER named entity recognition, PoS part-of-speech tagging, semantic disambiguation, and classification.
(2) Flair supports multiple languages and currently supports one model for multiple languages, allowing it to predict NER tasks and PoS tasks for input text in multiple languages using just one model.
Finally, Flair is also a word embedding library, currently supporting Flair Embedding, Bert Embedding, Elmo Embedding, Glove Embedding, Fasttext Embedding, etc. At the same time, the Flair library also supports combining various Word Embeddings. By loading the pre-trained models provided by the Flair community, you can obtain word embeddings. Below, we will see how to use it, and the pre-trained models will be provided later.
First, let’s look at how to use Flair Embedding:
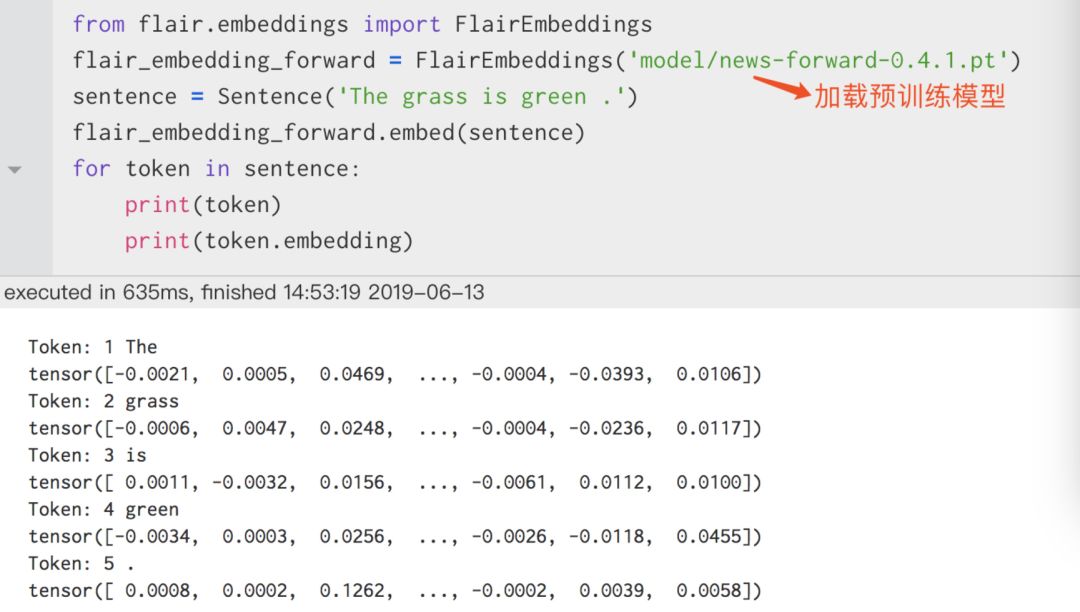
Using it is very convenient. The usage of Bert, Elmo, Glove, and Fasttext Embedding is also quite similar. Next, let’s see how to combine various Embedding models:
Flair not only provides Word Embeddings but also provides Character Embeddings (using characters as features) and Byte Pair Embeddings (which splits words into subsequences, with a granularity larger than characters).
Note: To download the Flair pre-trained models, you need to have access to the internet; otherwise, you will not be able to download the models.
For more detailed algorithm introductions, data, and source code, please visit:
https://github.com/zlsdu/Word-Embedding
Useful | Ten Pre-trained Models in NLP
FastText Principles and Practical Text Classification, this article is sufficient.
