This article is reproduced from the public account: Fudan DISC
01
Background Introduction

Figure 1: Examples of social movements such as #MeToo, Roe v. Wade, and Black Lives Matter (Image source from the internet).
In the past few decades, social media has witnessed numerous social movements, such as #MeToo and #BlackLivesMatter. Twitter provides a powerful platform for groups calling for change. After incidents occur, related information and opinions spread on Twitter, influencing public sentiment and shaping the social agenda, often leading to actual offline actions. Although most social movements are reported as peaceful, the scale of participation can sometimes escalate to violence and destruction, potentially causing negative impacts. Therefore, predicting trends of such events and taking proactive measures becomes crucial.
Recently, large language models (LLMs) have demonstrated strong capabilities in human-like intelligence, and user simulation based on LLMs has seen successful explorations in areas such as collaborative development and recommendation systems. However, applying LLMs to large-scale social movement simulations still faces several challenges:
(1) How to simulate users on social media to replicate their behaviors and actions within the community?
(2) Considering that using LLMs to drive thousands of users is inefficient and costly, how to simulate a large number of participants?
(3) Can simulations truly replicate reality, and how to comprehensively assess the effectiveness of the simulations?
To address these issues, the latest work from the Fudan University Data Intelligence and Social Computing Laboratory (Fudan DISC) discusses how to simulate the opinion dynamics in social movements. We propose a hybrid simulation framework that models two types of users on social media to tackle the cost and efficiency challenges associated with simulating a large number of participants; we constructed an online social media simulation environment that mimics Twitter’s information organization and dissemination mechanisms, laying the foundation for simulation evaluation; and we developed an evaluation benchmark SoMoSiMu-Bench, designing evaluation strategies at both micro and macro levels, focusing on individual user alignment and system result replication, and evaluated it on three real-world datasets (MeToo, Roe, and Black Lives Matter).
Arxiv link:https://arxiv.org/abs/2402.16333Project homepage:https://xymou.github.io/social_simulation/

02
Method Design
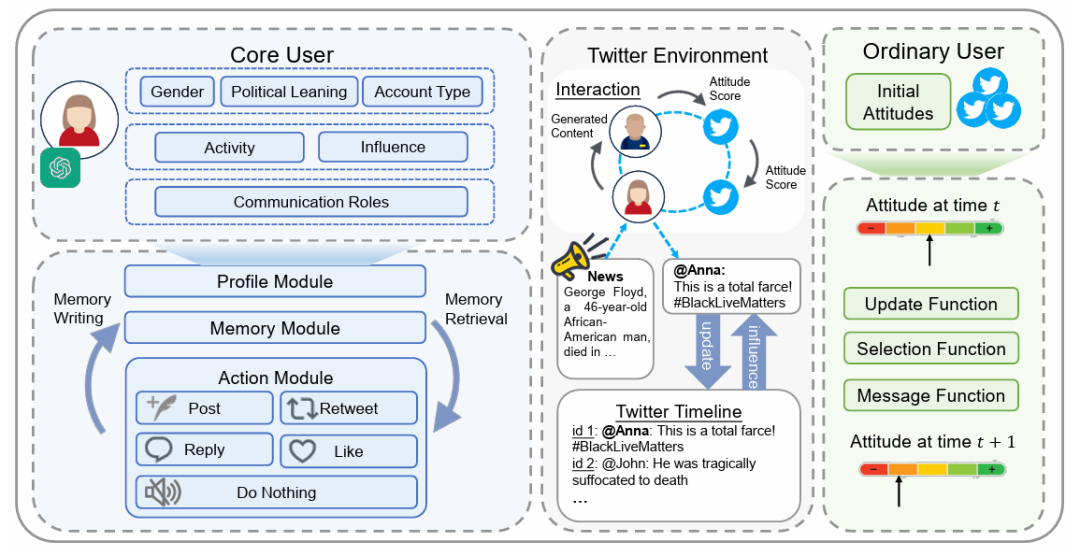
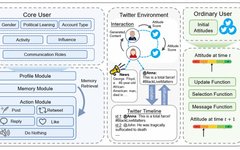
Figure 2: The proposed overall framework. The left part shows the architecture of the LLM agent used for core user simulation; the right part illustrates the ABM mechanism modeling the public opinion dynamics of ordinary users. The initial state of users is determined by real Twitter data. In each round, core user agents take actions based on contextual information, and their attitudes are further communicated to ordinary users after being converted into attitude scores.
Research Question 1: How to simulate large-scale participants in social movements?
User participation in social networks typically follows a Pareto distribution, where a small number of users generate the majority of content. Therefore, more detailed modeling should be conducted for active and influential users, such as opinion leaders, while the silent majority can be controlled through simpler models. The overall framework is illustrated in Figure 2, where social media users are divided into core users and ordinary users. These two types of users are driven by different models to address the cost and efficiency issues of using thousands of LLMs.
-
Core User Construction: Driven by LLMs, detailed modeling of their characteristics, memory, and behaviors;
-
Ordinary User Construction: Driven by traditional agent-based models (ABMs), such as bounded confidence models, focusing only on changes in their opinions;
-
Core User – Core User Interaction: Content generated by LLM agents influences the context of other agents that can see their content;
-
Ordinary User – Ordinary User Interaction: Attitude scores of agents are communicated to a set of agents determined by the selection function through the messaging function in the ABM;
-
Core User – Ordinary User Interaction: Using external LLMs to convert content generated by LLM agents into attitude scores before communicating them to ordinary user agents.
Research Question 2: How to simulate core users and replicate their behaviors?
By endowing LLMs with the functionalities required for simulating core users, we construct the agent architecture. The left side of Figure 2 shows the architecture of the core user agent based on LLMs. Driven by LLMs, the agent is equipped with a profiling module, memory module, and action module.
-
Profiling Module: Describes the profile of the corresponding user of the agent, including demographic information such as name, gender, political inclination, social characteristics like activity and influence, and dissemination role information to characterize their dissemination behavior;
-
Memory Module: Operates the agent’s memory, including three operations: memory writing, memory retrieval, and memory reflection;
-
Action Module: Considers actions highly relevant to information and attitude dissemination to form the action space, including: posting original content (post), retweeting (retweet), replying (reply), liking (like), and doing nothing (do nothing).
To simulate user responses after events occur, an information push mechanism and a Twitter-like simulation environment were constructed, pushing triggering events in natural language; in each round, core user agents think and take actions based on (1) the agent’s profiling information; (2) the agent’s memory; (3) triggering event information (if any in that round); (4) tweets that the agent can see based on the social network; (5) replies from other agents or system notifications.
Research Question 3: How to assess the effectiveness of the simulation?
To comprehensively evaluate the effectiveness of the simulation, while focusing on individual user consistency and system results, we constructed the SoMoSiMu-Bench evaluation framework.
-
Micro-consistency Evaluation: Conduct single-round simulations by providing real contextual information to each core user agent and evaluate their consistency with corresponding users in terms of stance, content, and behavior:
-
Stance Consistency: Evaluates the stance consistency of generated content and real content towards a given subject, reporting accuracy and F1 score;
-
Content Consistency: Classifies generated content and real content into 5 categories based on content themes, reporting accuracy and F1 score, while calculating the semantic similarity between generated content and real content.
-
Behavior Consistency: Since only posting original content and retweeting can be observed in the real dataset, to facilitate evaluation, the action space is reduced to these two categories, reporting accuracy and F1 score.
-
Macro-system Evaluation: Quantifies attitude changes in continuous multi-round simulations based on events, while assessing the similarity between simulation results and real situations in terms of static attitude distribution and the time series of average attitudes:
-
Static Attitude Distribution: Calculates attitude bias and diversity at each time step and computes the differences ΔBias and ΔDiv. with real data.
-
Time Series of Average Attitudes: Calculates the dynamic time warping (DTW) and Pearson correlation coefficient between the simulated average attitude time series and the real average attitude time series.
03
Experimental Analysis
Experimental Setup
-
Data Setup: Experiments were conducted on three datasets: MeToo, Roe, and Black Lives Matter, each containing two events (or phases), with parameter calibration of the ABM model in the mixed framework on event 1 of each dataset, and validation on event 2;
-
Model Selection: In the mixed framework, the LLM driving core users is GPT-3.5-turbo, while the ABMs driving ordinary users include Bounded Confidence Model (BC), Bounded Confidence Model-Multiple (HK), Relative Agreement Model (RA), Social Judgement Model (SJ), and Lorenz Model. These traditional ABM models also serve as baseline models for comparison with the methods presented in this paper.
Micro Evaluation
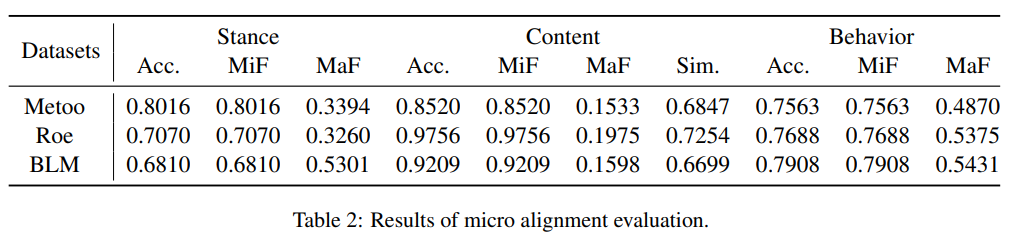
Table 2 shows the results of individual-level alignment evaluation. In terms of stance, for MeToo and BLM, both real and simulated user stances are concentrated on support and neutrality, with the average accuracy of simulations reaching over 70%, but LLMs have shortcomings in simulating neutral stances, leading to lower MaF. This may be because LLMs tend to generate content with clear stances; in terms of content types, the simulation of sharing opinions and quoting third-party content types is relatively accurate, but it is challenging to reproduce personal experience narratives (testimonials), which is due to the lack of real experience information of corresponding users offline, making it difficult to model these experiences through simple profiling and memory modules; in terms of behavior simulation, the overall accuracy exceeds 75%, and LLMs can generally distinguish user behavior tendencies, thanks to the profiling module’s description of their behavioral habits related to dissemination roles.
Macro Evaluation
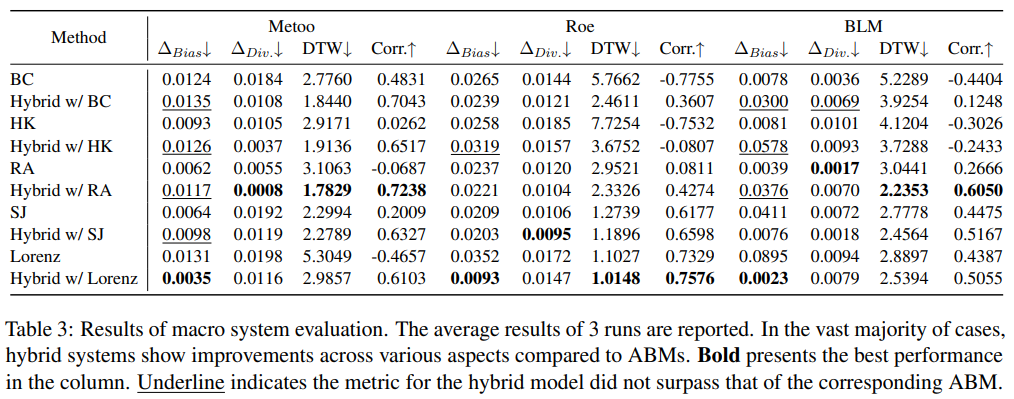
Table 3 shows the results of system evaluation. Overall, the hybrid framework proposed in this paper can improve the performance of pure ABM simulations, with a notable advantage over the mixed models with RA and Lorenz models, likely due to the advantages of these two models in simulating polarization; hybrid models generally exhibit higher attitude biases, which is also because LLMs are more inclined to generate content with clear attitudes, leading to a higher average attitude level; thanks to the accurate portrayal of core users by LLM agents, even in some cases where ABMs struggle to model overall attitude trends, the hybrid model can correctly capture the direction and magnitude of attitude changes.
Further Thoughts: How to Promote More Harmonious Change?
Using the simulation framework constructed in this paper, it is possible to further assess whether the simulation can replicate more complex phenomena such as echo chambers and explore the improvements that different information push mechanisms may bring, providing more insights for platform designers.
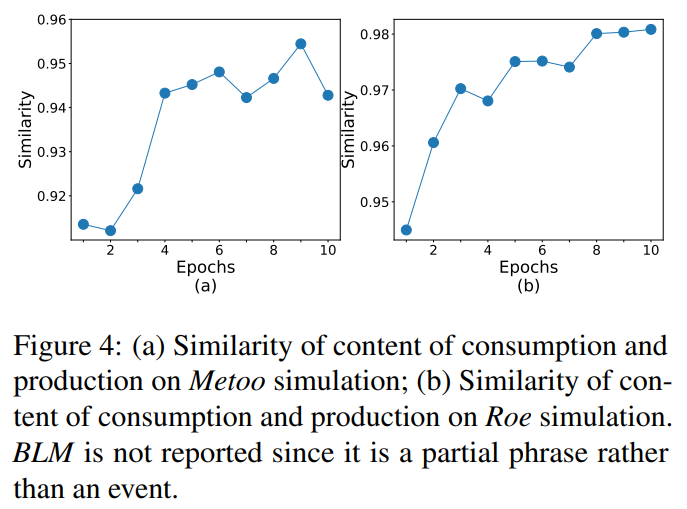
First, by quantifying the similarity between produced content (i.e., content published by users) and consumed content (i.e., content published by users’ followers) over time, we can observe whether the simulation can replicate the echo chamber effect. The results in Figure 4 indicate that the constructed simulation framework can effectively reproduce the echo chamber effect.
In response, three strategies are proposed to mitigate the echo chamber effect without harming users’ rights to voice:
-
S1: Actively push tweets with opposing viewpoints to users;
-
S2: Actively push tweets with neutral viewpoints to users;
- S3: The platform provides a public topic hashtag and encourages users to use this hashtag for discussion.
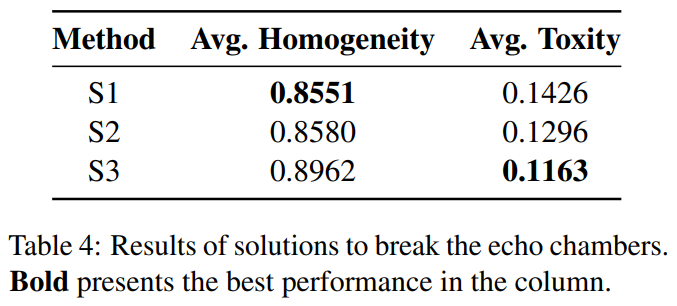
After implementing these three strategies, the simulation results on the MeToo dataset are shown in Table 4. It can be observed that S1 can minimize the echo chamber effect to the greatest extent, but the direct introduction of opposing viewpoints significantly increases the toxicity of community content; S3 establishes an open discussion space that facilitates more peaceful communication, with the lowest level of toxicity.
04
Conclusion
This work proposes a hybrid framework for simulating large-scale social movement participants, using LLMs and ABMs to drive core users and ordinary users, and constructs a Twitter-like simulation environment and a multi-faceted evaluation framework SoMoSiMu-Bench to assess the differences between simulation results and real situations. Overall, this work can serve as a foundation for public opinion simulation after emergencies and provide insights for the continuous optimization of social platforms.
END

Click “Read Original” to jump to the project homepage