
Previous Review
Recommended Article: Control Strategy for Air Combat Swarm Based on Hierarchical Reinforcement Learning
Recommended Article: Software-Defined Command and Control System Architecture Design Method
This article was published in “Command Information Systems and Technology”, 2023, Issue 5Authors: Wen Yongming, Li Boyan, Zhang Ningning, Li Xiaojian, Xiong Chuyi, Liu JiexiaCitation format:Wen Yongming, Li Boyan, Zhang Ningning, et al. Multi-Agent Formation Control Based on Deep Reinforcement Learning [J]. Command Information Systems and Technology, 2023, 14(5): 75-79
Abstract
The problem of multi-agent formation control is solved using deep reinforcement learning algorithms. A distributed formation control architecture is constructed based on the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm, and is solved with a centralized training-distributed execution framework. To address the instability of the multi-agent environment, a corresponding reward function is constructed based on the local information of individual agents. For large-scale formation control, algorithm training and evaluation are implemented in multiple multi-agent environments. Experimental results show that the multi-agents using this algorithm can complete collaborative tasks, and all agents can obtain reasonable collaborative control strategies.
0
Introduction
The Multi-Agent System (MAS) consists of several independently controlled agents connected via wireless networks, widely studied and making progress in issues such as control, formation, allocation, games, and distributed estimation. Based on known system dynamics models, researchers have conducted extensive research on the fundamental theories of multi-agent systems. Traditional system identification experiments determine analytical models based on input-output data, but in practical applications, modeling complex processes is difficult and expensive. Furthermore, traditional control methods face limitations when interacting with complex environments, as fixed strategies cannot be applied to different environments or task scenarios. Deep reinforcement learning focuses on the policy model of a single agent, borrowing optimal control ideas from partially observable Markov decision processes, where agents interact with the environment to maximize long-term cumulative rewards. There is a close relationship between control optimization and policy learning. Therefore, deep reinforcement learning technology has broad application prospects in system control.
Deep reinforcement learning algorithms are divided into two categories: value-based reinforcement learning algorithms and policy-based reinforcement learning algorithms. 1) Q-learning and deep Q-learning algorithms are the most commonly used and straightforward value-based algorithms, which obtain optimal policies through action value functions. By having each agent learn an independent optimal equation, value-based algorithms are directly applied to multi-agent systems. However, during the learning process, when neighboring agents update, the current agent’s rewards and state transitions may also change. In this case, the environment becomes unstable and no longer satisfies the Markov property, ultimately leading to the non-convergence of value-based algorithms. 2) Policy-based algorithms are another class of deep reinforcement learning algorithms, which approximate stochastic policies through independent neural networks. The Actor-Critic (AC) algorithm combines both value-based and policy-based algorithms, where the actor represents the policy function generating actions, and the critic represents the value approximator evaluating action rewards. The Deep Deterministic Policy Gradient (DDPG) algorithm is a model-free AC algorithm that combines deterministic policy gradients and deep Q-learning algorithms, where both the actor and critic are approximated using deep neural networks. The Multi-Agent Deep Deterministic Policy Gradient method (MADDPG) extends DDPG to a multi-agent collaborative task environment, where agents intelligently acquire local information. MADDPG is an AC model redesigned for multi-agent scenarios, aiming to solve complex problems in changing environments and among multiple agents.
1
Theoretical Foundation
1.1 Algebraic Graph Theory


1.2 Problem Description

2
Formation Collaborative Control Framework Based on MADDPG Iteration
2.1 Traditional Control Design

2.2 Formation Collaborative Control Algorithm Framework Design

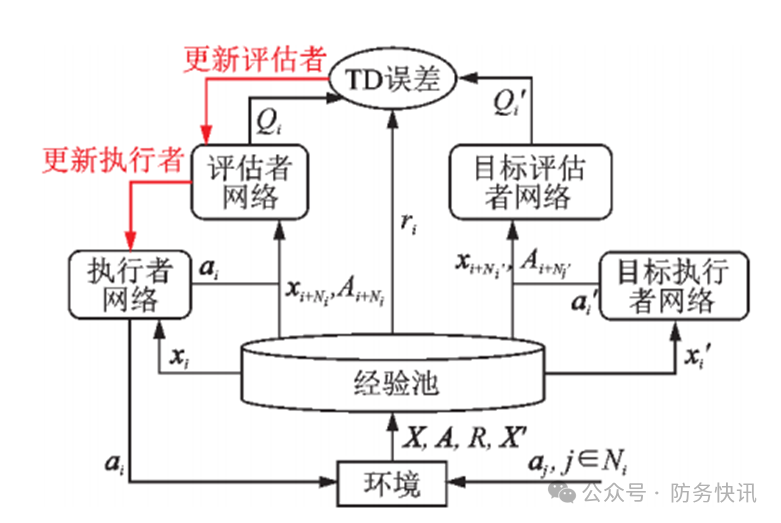
Figure 1 Formation Control Algorithm Framework
2.3 Learning Objective Design


2.4 Formation Collaborative Control Algorithm Process


3
Experimental Results and Analysis
3.1 Experimental Setup

Figure 2 Experimental Interaction Topology
3.2 Results and Analysis
This article runs and evaluates the proposed algorithm in the environment shown in section 3.1, with simulation results shown in Figure 3, and Figure 4 presents a comparison of the agents’ motion trajectories before and after training.
The long-term cumulative reward scores of the four agents are shown in Figure 3(a). During the learning process, the scores gradually increase and converge to below 6 after 50,000 iterations, indicating that the MAS can effectively eliminate initial errors after 50,000 iterations; simultaneously, this score also signifies the cost required for the MAS to achieve ideal formation and reach the target position. Figure 3(b) shows the stable rewards when the agents converge during the last 50 training iterations. As shown in the figure, the four agents can quickly achieve stable formation, and the tracking error also indicates that rewards and penalties can converge to near zero within 1 second.
The initial, 1s, 2s, 3s, and 4s formation states of the four agents before and after training are shown in Figure 4. The blue point in the figure represents the leader, corresponding to the blue point labeled 0 in Figure 2, while the pink, gray, and green points correspond to points 1, 2, and 3 in Figure 2, respectively. The experimental results indicate that due to the lack of prior knowledge of the environment, the MAS deviates from the formation on the first attempt. As agents accumulate experience through repeated trial and error in the environment, the MAS converges to form a stable formation. Ultimately, the leader can reach the target position while the followers maintain a stable formation position with the leader.
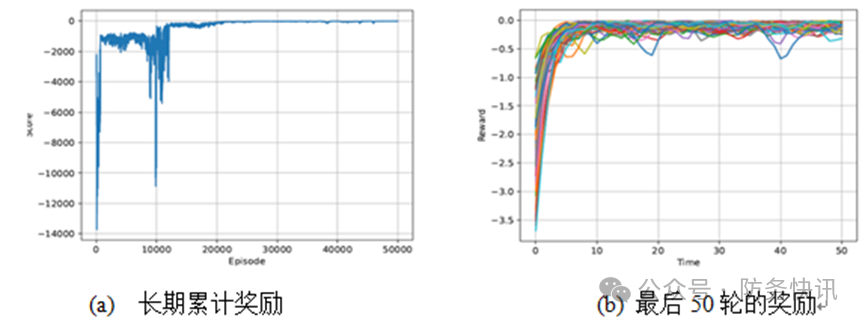
Figure 3 Simulation Results in Experimental Environment

Figure 4 Comparison of Agent States Before and After Training
4
Conclusion
This article adopts a multi-agent policy gradient algorithm, combined with a centralized training and distributed execution framework, to study and solve the problem of multi-agent collaborative formation control, designing and constructing a distributed formation control framework based on the Multi-Agent Deep Deterministic Policy Gradient algorithm, and providing the training process of the algorithm. Through simulation training and evaluation of the multi-agent cooperative environment, the effectiveness of the proposed algorithm is verified. The experimental results show that the algorithm can enable agents to collaboratively complete tasks in the absence of prior knowledge of the dynamic model, aiding in solving control problems that are too complex for mathematical modeling to identify.
Recommended Related Literature:
-
Huang Hongyu, Liang Yongsheng, Fu Shenghao, et al. Intelligent Scheduling Method for Airport Aircraft Taxiing Based on Multi-Agent Reinforcement Learning [J]. Command Information Systems and Technology, 2023, 14(5): 30-36.
-
Liu Wei, Zhang Yongliang, Cheng Xu. Overview of Human-Machine Intelligent Adversarial Combat Based on Deep Reinforcement Learning [J]. Command Information Systems and Technology, 2023, 14(2): 28-37.
-
Li Yanshan, Su Weipeng, He Jiafan, et al. Spatiotemporal Graph Convolutional Network for Tactical Recognition of Dual-Plane Formation [J]. Command Information Systems and Technology, 2023, 14(3): 25-30.
-
Cui Huachao, Qi Zhigang, Wang Tao, et al. Command Information Systems and Combat Command Structure of the US Aircraft Carrier Formation [J]. Command Information Systems and Technology, 2022, 13(4): 8-13.
-
Huang Ying, Duan Jikun. Similarity Assessment of Blue Force Air Formation Based on Improved Analytic Hierarchy Process [J]. Command Information Systems and Technology, 2022, 13(4): 58-62.
-
Zhang Guilin, Wu Wei, Xu Jian, et al. Target Recognition Reasoning for Maritime Formation Based on Rule Engine [J]. Command Information Systems and Technology, 2022, 13(3): 28-31.
-
Liu Ming, Lu Sheng, Ding Kun, et al. Application of Knowledge Graph in Maritime Formation Adversarial Scenarios [J]. Command Information Systems and Technology, 2022, 13(2): 67-72.
-
He Jiafan, Wang Man, Fang Feng, et al. Application of Deep Reinforcement Learning Technology in Intelligent Aerial Combat [J]. Command Information Systems and Technology, 2021, 12(5): 6-13.
-
Qi Zhigang, Hui Xincheng, Zhang Wei. Application of Space-Based Reconnaissance Information in Aircraft Carrier Formation Information Systems [J]. Command Information Systems and Technology, 2021, 12(4): 18-22.
-
Sun Yu, Li Qingwei, Xu Zhixiong, et al. Training Model for Air Combat Game Adversarial Strategy Based on Multi-Agent Deep Reinforcement Learning [J]. Command Information Systems and Technology, 2021, 12(2): 16-20.

Reply with the following keywords to view a series of articles:
|
Hot Topics:ABMS|Unmanned Autonomous Systems|Joint All-Domain Command|Urban Operations |
|
Strategic Planning:Development Planning|Regulations|Think Tank Reports |
|
Operational Concepts:Mosaic Warfare|Multi-Domain Operations|Distributed Lethality |
|
Cutting-Edge Technologies:Artificial Intelligence|Cloud Computing|Big Data|Internet of Things|Blockchain|5G |
|
System Equipment:Army|Navy|Air Force|Space Force|Cyber Space|NC3|Air Defense and Missile Defense|Logistics Support |
|
Aerial Traffic:NextGen|SESAR|Drones |



For more information, scan the QR code to follow us.