Click the "Xiaobai Studies Vision" above, select "Star" or "Top" to receive essential information promptly.

1: CNN can be understood as a fully connected layer with local order and weight sharing. Thus, CNN has two features that fundamentally differ from fully connected layers: weight sharing and local connectivity. This greatly reduces the number of parameters while ensuring that fundamental features are not lost.
2: The steps of attention involve obtaining the attention matrix through the dot product of Q and K, representing the similarity between the two; that is, the more similar Q and K are, the larger the dot product. After scaling and applying softmax, we obtain the attention score, which is then multiplied by V to obtain the result after applying attention.
The essence of attention is to calculate the similarity between Q and K, emphasizing the parts of Q that are similar to K.
The fundamental difference can also be understood as CNN extracting features, while attention emphasizes features. The two can be quite different. If we say that all models are doing something around features, it is clearly unreasonable to say that they are all the same.
Update: Due to new understanding of CNN, I am updating my previous answer, but I will not delete my earlier response. I will add further supplements and explanations regarding this topic in the future, and everyone is welcome to bookmark it.
First, to conclude, CNN can be seen as a simplified version of Self-Attention, or Self-Attention can be viewed as a generalization of CNN.

Previously, when comparing CNN and self-attention, we subconsciously thought of CNN as being used for image processing and self-attention for NLP, thus creating the illusion that these two methods are unrelated. Now, we will discuss the differences and connections between CNN and self-attention from the perspective of image processing for a better comparison. The process of using self-attention for image processing:
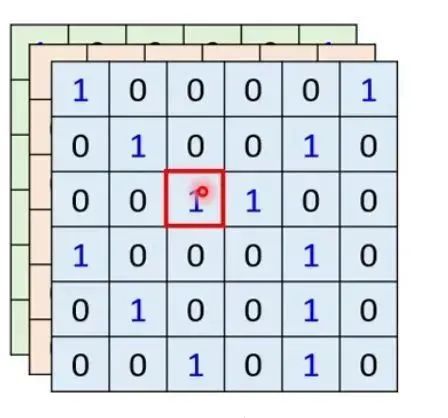
Now, if we use CNN to process an image, we select different convolution kernels to process the image. Each pixel (pixel value) only needs to consider the other pixels within that convolution kernel; it only needs to consider the receptive field and does not need to consider all the information in the entire image.
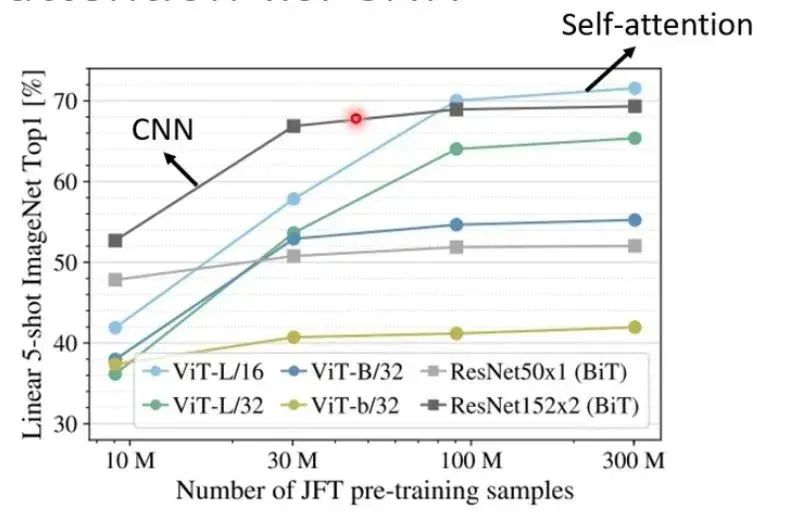
Thus, we can arrive at a general conclusion: CNN can be seen as a simplified version of self-attention, where CNN only needs to consider information within the convolution kernel (receptive field), while self-attention needs to consider global information.
Conversely, we can also understand that self-attention is a more complex version of CNN. CNN needs to define the receptive field and only considers information within that receptive field, while the range and size of the receptive field must be set manually. For self-attention, using attention to find related pixels is like having the receptive field automatically learned; that is, for each pixel, it determines which other pixels should be considered based on their relevance.
In simple terms, CNN learns information only from the pixels within the convolution kernel, while self-attention learns information from all pixels in the entire image. (This only considers a single layer of convolution; if there are multiple layers of convolution, CNN can achieve effects similar to self-attention.)
Now that we know the connection between self-attention and CNN, what conclusions can we draw?
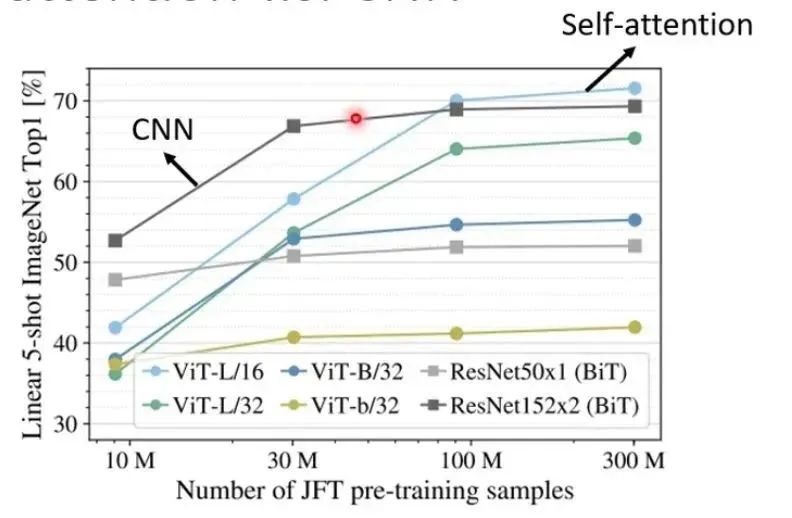
We understand that CNN is a special case of Self-Attention, or Self-Attention is a generalization of CNN; CNN is very flexible, and by imposing certain restrictions on Self-Attention, they become similar. (Conclusion derived from the paper: https://arxiv.org/abs/1911.03584)
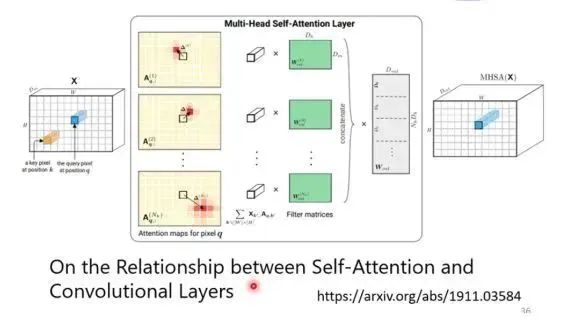
The convolutional layer of CNN can be seen as K composed of parameters and Q generated by different data, reflecting the relationship between the data and the parameters.
This means that self-attention constructs different spaces through parameters, allowing data to present different self-correlation properties in different spaces.
On the other hand, CNN convolution constructs certain fixed features through parameters and processes the data based on its performance on these features.
The self-attention mechanism is focused on itself, calculating with itself, allowing each word to incorporate global information, aiming to help local features better represent themselves with the help of global information.
Thus, CNN goes from local to global, while the self-attention mechanism assists local features from a global perspective. If one must relate CNN to attention, I personally understand it as local attention (note that there is no self).
Assuming that for a layer of self-attention, there are four candidate features a, b, c, d that can be input simultaneously, but only the combined representations ac and bd contribute to downstream tasks. Self-attention will focus on these two combinations while masking others; for instance, [a,b,c] -> [a’,0,c’]. Ps. a’ represents the output representation of a.
For a layer of CNN, it is more straightforward; it simply maps [a,b,c] -> [a’,b’,c’]. Can CNN achieve the same functionality as self-attention? Absolutely, just add another layer of CNN with two filters, one filtering ac and the other filtering bd, and that’s it.
Of course, CNN can also fit distributions without doing this; however, self-attention must do this, which constitutes a stronger inductive bias.
Good news! The "Xiaobai Studies Vision" knowledge community is now open to the public👇👇👇
Download 1: Chinese Tutorial for OpenCV-Contrib Extension Modules
Reply "Chinese Tutorial for Extension Modules" in the background of "Xiaobai Studies Vision" official account to download the first Chinese tutorial on OpenCV extension modules covering installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the background of "Xiaobai Studies Vision" official account to download 31 practical projects including image segmentation, mask detection, lane detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition to help quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "20 OpenCV Practical Projects" in the background of "Xiaobai Studies Vision" official account to download 20 practical projects based on OpenCV for advancing OpenCV learning.
Group Chat
Welcome to join the reader group of the official account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, and note: "nickname + school/company + research direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, your request will not be approved. After successfully adding, you will be invited to relevant WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed from the group. Thank you for your understanding~