
Author|xys430381_1
Table of Contents
-
Overview
-
Why Visual Attention is Needed -
Classification of Attention and Basic Concepts -
Soft Attention
-
The application of two-level attention models in deep convolutional neural network for fine-grained image classification—CVPR2015 -
1. Spatial Transformer Networks—2015 NIPS -
2. SENET—2017 CPVR -
3. Residual Attention Network—2017 -
Non-local Neural Networks, CVPR2018 -
Interaction-aware Attention, ECCV2018 -
CBAM: Convolutional Block Attention Module, ECCV2018 -
DANet: Dual Attention Network for Scene Segmentation, CPVR2019 -
CCNet -
OCNet -
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond -
Attention-Augmented Convolution -
PAN: Pyramid Attention Network for Semantic Segmentation—CVPR2018 -
Multi-Context Attention for Human Pose Estimation -
Tell Me Where to Look: Guided Attention Inference Network -
Hard Attention
-
A study on guiding the learning of visual question answering tasks by introducing hard attention mechanisms -
1. Diversified visual attention networks for fine-grained object classification—2016 -
2. Deep networks with internal selective attention through feedback connections—NIPS 2014 -
3. Fully Convolutional Attention Networks for Fine-Grained Recognition -
4. Temporal Attention (RNN) -
Self-Attention
-
Related Works
-
Disadvantages and Improvement Strategies of Self-Attention
-
Summary of Self-Attention
Why Visual Attention is Needed
The basic idea of attention mechanisms in computer vision is to allow the system to learn to focus on important information while ignoring irrelevant data. Why is it necessary to ignore irrelevant information?
Classification of Attention and Basic Concepts
What is ‘attention’ in neural networks? How is it used? Here is a detailed explanation: http://www.sohu.com/a/198312880_390227 This article is divided into: Hard Attention, Soft Attention, as well as Gaussian Attention and Spatial Transformation
Divided by the differentiability of attention:
-
Hard-attention is a 0/1 problem, determining which areas are attended and which areas are ignored. Hard attention has been well-known for its application in images for many years: Image Cropping (image cropping). The difference between hard attention (strong attention) and soft attention is that strong attention focuses more on points, meaning that every point in the image has the potential to extend attention, and strong attention is a random prediction process emphasizing dynamic changes. Of course, the key point is that strong attention is a non-differentiable attention, and the training process is often completed through reinforcement learning (Reference: Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in neural information processing systems. 2014.)
Hard attention can be implemented in Python (or Tensorflow) as:
g = I[y:y+h, x:x+w]The only issue with the above is that it is non-differentiable; if you want to learn model parameters, you must use a score-function estimator. I briefly introduced this in my previous article.
-
Soft-attention is a continuous distribution problem between [0,1], indicating the degree to which each area is attended, represented by a score from 0 to 1.  The key point of soft attention is that this attention focuses more on regions or channels and is deterministic, meaning it can be directly generated through the network after learning. The most critical aspect is that soft attention is differentiable, which is very important. Differentiable attention can calculate gradients through neural networks and learn attention weights through forward and backward propagation. However, this type of soft attention is computationally wasteful. The black parts of the input have no effect on the result but still need to be processed. It is also over-parameterized: the sigmoid activation function used to implement attention is independent of each other. It can select multiple targets at once, but in practice, we often want selectivity and can only focus on a single element in the scene. The following two mechanisms introduced by DRAW and Spatial Transformer Networks solve this problem well. They can also adjust the input size to further enhance performance.
The key point of soft attention is that this attention focuses more on regions or channels and is deterministic, meaning it can be directly generated through the network after learning. The most critical aspect is that soft attention is differentiable, which is very important. Differentiable attention can calculate gradients through neural networks and learn attention weights through forward and backward propagation. However, this type of soft attention is computationally wasteful. The black parts of the input have no effect on the result but still need to be processed. It is also over-parameterized: the sigmoid activation function used to implement attention is independent of each other. It can select multiple targets at once, but in practice, we often want selectivity and can only focus on a single element in the scene. The following two mechanisms introduced by DRAW and Spatial Transformer Networks solve this problem well. They can also adjust the input size to further enhance performance.
Divided by the domain of attention:
-
Spatial Domain -
Channel Domain -
Layer Domain -
Mixed Domain -
Time Domain: There is another special implementation of strong attention in the time domain, but because strong attention is implemented using reinforcement learning, the training is different.
A concept: Self-attention is the autonomous learning between feature maps, distributing weights (which can be spatial, temporal, or between channels).
Soft Attention
The application of two-level attention models in deep convolutional neural network for fine-grained image classification—CVPR2015
1. Spatial Transformer Networks—2015 NIPS
Spatial Transformer Networks (STN) model [4] is an article from NIPS 2015. This article uses attention mechanisms to transform spatial information from the original image to another space while retaining key information.
This article argues that previous pooling methods were too brute force, directly merging information would lead to key information being unrecognizable, thus proposing a module called a spatial transformer, which corresponds to spatial transformations of spatial domain information in the image, allowing for the extraction of key information.
Spatial transformers are essentially implementations of attention mechanisms, as the trained spatial transformer can identify areas in the image that need to be focused on, and this transformer can also perform rotation and scaling transformations, allowing for the extraction of important local information through transformation.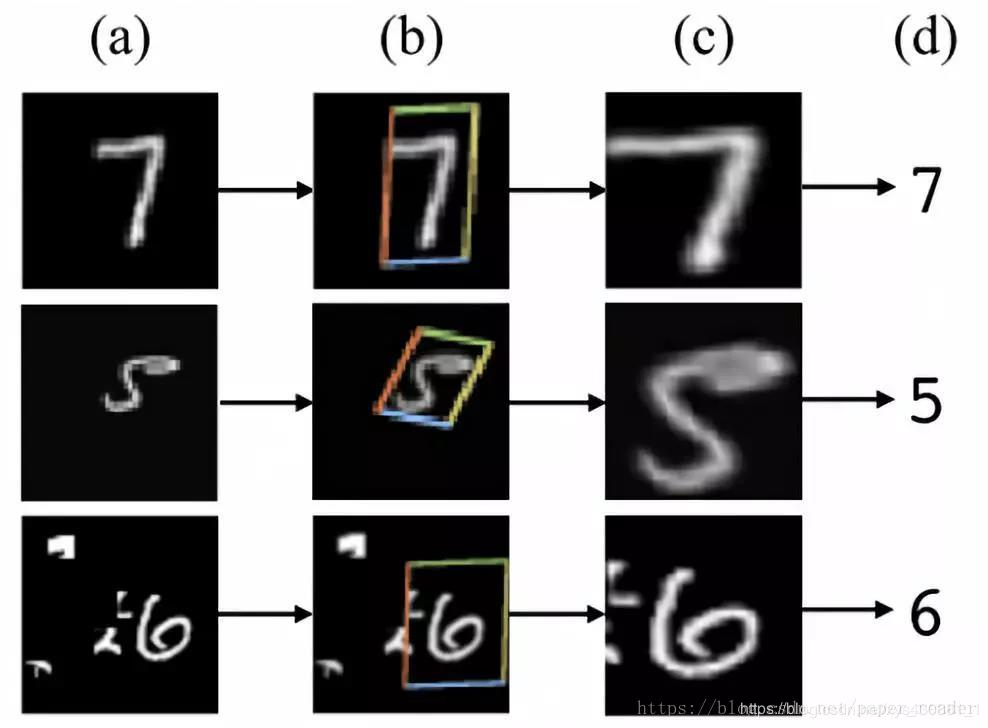 For example, this intuitive experimental diagram:
For example, this intuitive experimental diagram:
(a) Column shows the original image information, where the first handwritten digit 7 has no transformation, the second handwritten digit 5 has undergone some rotation, and the third handwritten digit 6 has some noise; (b) Column in color boxes represents the learned bounding boxes of the spatial transformer, each box corresponds to a spatial transformer learned from the image; (c) Column shows the feature map after transformation by the spatial transformer, where the key area of 7 is selected, 5 is rotated to the upright image, and the noise information of 6 is not recognized.
2. SENET (Channel Domain)—2017 CPVR
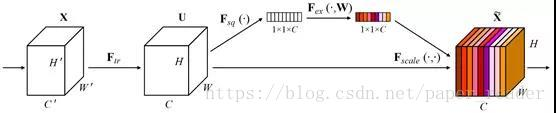 The middle module is the innovative part of SENet, which is the attention mechanism module. This attention mechanism is divided into three parts: squeeze, excitation, and scale. The process:
The middle module is the innovative part of SENet, which is the attention mechanism module. This attention mechanism is divided into three parts: squeeze, excitation, and scale. The process:
-
Perform Global Average Pooling on the input features to obtain 1_1_Channel -
Then bottleneck features interact, first compress the number of channels, then reconstruct back to the number of channels -
Finally, connect a sigmoid to generate channel-wise attention weights from 0 to 1, and finally scale them back to the original input features
For details, see “Paper Reading Notes—SENET” https://blog.csdn.net/xys430381_1/article/details/89158063
3. Residual Attention Network (Mixed Domain)—2017
The attention mechanism in the article is based on the soft attention basic masking mechanism, but different is that this attention mechanism’s mask draws on the idea of residual networks, not only adding a mask based on the information of the current network layer but also passing down the information from the previous layer, thus preventing the problem of insufficient information after masking leading to a shallow network.
The proposed attention mask is not just attention to spatial or channel domains; this mask can be seen as the weight of each feature element. By finding the corresponding attention weight for each feature element, both spatial and channel attention mechanisms can be formed simultaneously.
Many people may wonder why this approach should be a very natural transition from spatial or channel attention, why hasn’t anyone thought of single-domain attention? The reasons are:
-
If you assign a mask weight to each feature element, the information after masking will be very little, which may directly destroy the deep feature information of the network; -
Moreover, if you can add attention mechanisms, the identity mapping property of the residual unit will be destroyed, making training difficult.
The innovative point of the attention mechanism proposed in this article is the introduction of residual attention learning, which not only uses masked feature tensors as input to the next layer but also uses unmasked feature tensors as input to the next layer, allowing for richer features to be obtained, thus better attending to key features. The model structure in the article is very clear, overall structure is a three-stage attention module (3-stage attention module). Each attention module can be divided into two branches (see stage2), the upper branch is called the trunk branch, which is the basic structure of residual networks (ResNet). The lower branch is the soft mask branch, which contains the main part of the residual attention learning mechanism. Through down sampling and up sampling, as well as residual units, the attention mechanism is formed.
The model structure in the article is very clear, overall structure is a three-stage attention module (3-stage attention module). Each attention module can be divided into two branches (see stage2), the upper branch is called the trunk branch, which is the basic structure of residual networks (ResNet). The lower branch is the soft mask branch, which contains the main part of the residual attention learning mechanism. Through down sampling and up sampling, as well as residual units, the attention mechanism is formed.
The innovative residual attention mechanism in the model structure is: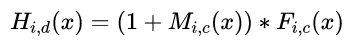 H is the output of the attention module, F is the feature of the image tensor from the previous layer, and M is the soft mask attention parameter. This forms the residual attention module, which can input both the image features and the features after enhanced attention into the next module. The function F can choose different functions to obtain results from different attention domains:
H is the output of the attention module, F is the feature of the image tensor from the previous layer, and M is the soft mask attention parameter. This forms the residual attention module, which can input both the image features and the features after enhanced attention into the next module. The function F can choose different functions to obtain results from different attention domains:
-
f1 is the sigmoid activation function applied directly to the image feature tensor, which is the mixed domain attention;
-
f2 applies global average pooling directly to the image feature tensor, thus obtaining channel domain attention (similar to SENet);
-
f3 is the activation function that calculates the average value of the image feature tensor in the channel domain, which ignores the channel domain information, thus obtaining spatial domain attention.
Non-local Neural Networks, CVPR2018
A masterpiece from FAIR, mainly inspired by traditional methods using non-local similarity for image denoising.
The main idea is simple: in CNNs, convolution units only focus on the neighborhood kernel size area. Even though the receptive field grows larger in later stages, it ultimately still performs operations in local areas, thus ignoring the contributions from other distant areas (such as far pixels) to the current region.
So non-local blocks aim to capture these long-range relationships: for 2D images, it is the relationship weight of any pixel in the image to the current pixel; for 3D videos, it is the relationship weight of all pixels in all frames to the current frame’s pixel.
The network framework diagram is also simple and straightforward: The article discusses various implementation methods, here we briefly talk about the Matmul method that is best implemented in the DL framework:
The article discusses various implementation methods, here we briefly talk about the Matmul method that is best implemented in the DL framework:
-
First, perform linear mapping on the input feature map X (which is essentially a 1x1x1 convolution to compress the channel number), then obtain the features θ, ϕ, g -
By reshape operation, forcibly merge the above three features except for the channel dimension, then perform matrix dot product operation to obtain something similar to the covariance matrix (this process is very important, calculating the self-correlation in the features, that is, obtaining the relationship of each pixel in each frame to all other pixels in all frames). -
Then perform Softmax operation on the self-correlation features by column or row (depending on the form of matrix g) to obtain weights between 0 and 1, which is the self-attention coefficients we need. -
Finally, multiply the attention coefficients back to the feature matrix g, then expand the channel number, and perform residual connection with the original input feature map X to complete the bottleneck.
The attention map visualization effect embedded in the action recognition framework:
The arrows in the figure indicate the contribution relationship of certain pixels in previous frames to the pixel of the foot joint in the last image (current frame). Since it is soft attention, each pixel in each frame has a contribution relationship, the yellow arrows in the figure describe the relationships with the highest responses.
Summary
Pros: Non-local blocks are very general and can be easily embedded into any existing 2D and 3D convolution networks to improve or visualize understanding of related CV tasks. For example, a recent article has already applied non-local to the Video ReID task.
Cons: The results in the article suggest placing non-local as far forward in the layers as possible, but in fact for 3D tasks, the early layers have a relatively large temporal T, and the construction and dot product operation in that step requires a lot of parameters and consumes a lot of GPU memory.
Interaction-aware Attention, ECCV2018
An article from Meitu and the Chinese Academy of Sciences.
This article discusses a lot about multi-scale feature fusion, telling a whole story, but in short, the main contribution is to design a new loss based on PCA on the covariance matrix of the non-local block for better feature interaction. The authors believe that during this process, features will interact better in the channel dimension, hence the name Interaction-aware attention.
So the question arises, how to obtain attention weights through PCA?
The article does not directly use feature value decomposition of the covariance matrix to implement it, but uses the following equivalent form:
CBAM: Convolutional Block Attention Module (Channel Domain + Spatial Domain), ECCV2018
This is based on the Squeeze-and-Excitation module in SE-Net to further extend it.
Specifically, the article views channel-wise attention as teaching the network to look at ‘what’; while spatial attention is seen as teaching the network to look at ‘where’, thus it has the advantage over the SE Module.
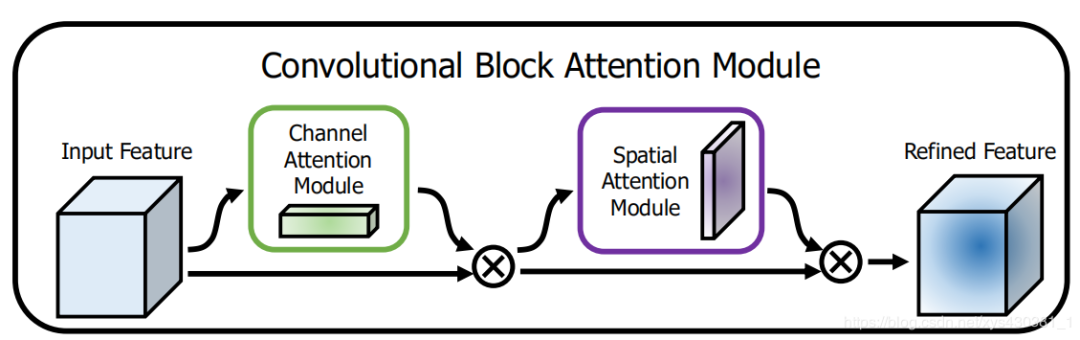
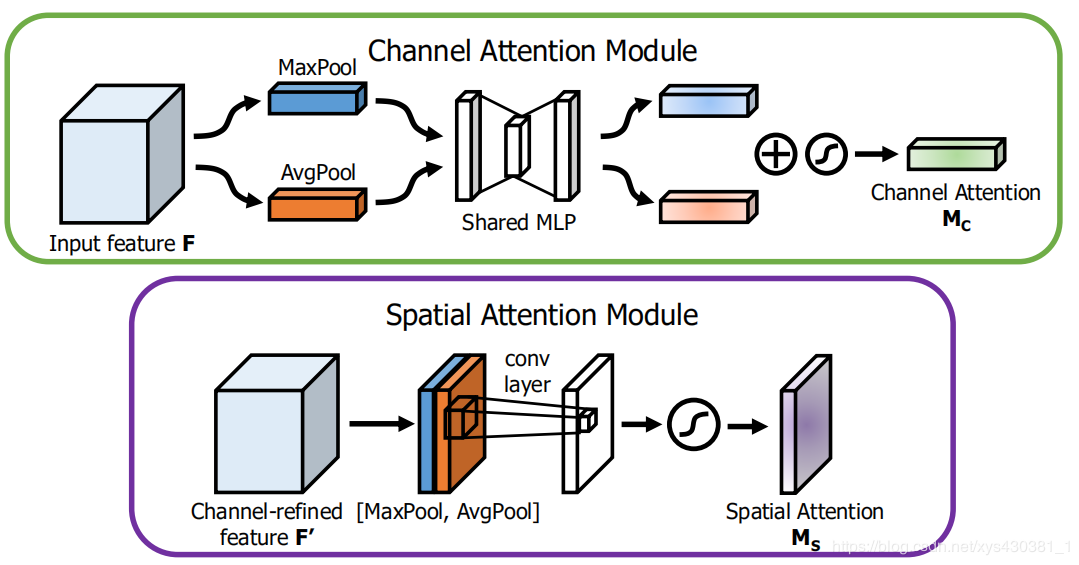
Channel Attention Formula:
Spatial Attention Formula: (Spatial domain attention is obtained by performing AvgPool and MaxPool on the channel axis)
CBAM is particularly lightweight and convenient for deployment on end devices.
DANet: Dual Attention Network for Scene Segmentation (Spatial Domain + Channel Domain), CPVR2019
Code: https://github.com/junfu1115/DANet Recently posted on arXiv, applying the concept of Self-attention to image segmentation, allowing for more precise segmentation through long-range contextual relationships.
The main idea is also the fusion deformation of the above articles CBAM and non-local:
Perform spatial-wise self-attention on deep feature maps, while also performing channel-wise self-attention, and finally fuse the two results through element-wise summation.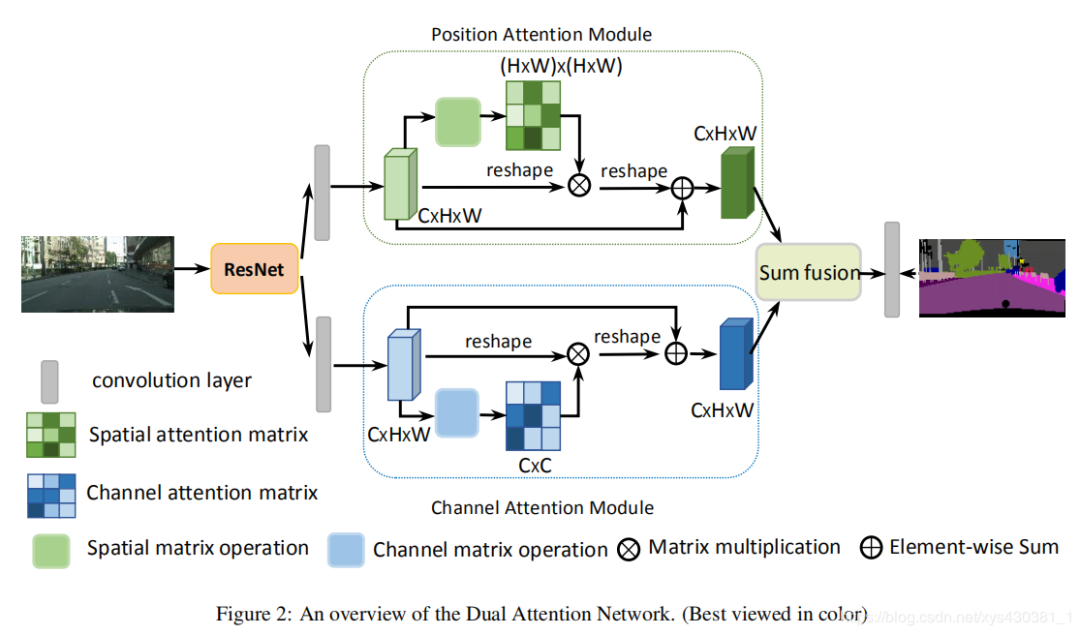 The benefit of this approach is:
The benefit of this approach is:
On the idea of performing spatial and channel self-attention separately in CBAM, it directly uses the Matmul form of the self-correlation matrix from non-local for computation, avoiding the complex operations of manually designed pooling and multi-layer perceptron.
CCNet
The highlight of this article is the clever method of reducing the parameter count. In the above DANet, the attention map calculates the similarity between all pixels and all pixels, with spatial complexity of (HxW)x(HxW), while this article adopts a criss-cross idea, calculating the similarity only between each pixel and the pixels in its same row and column, thus indirectly calculating the similarity between every pixel and every pixel, reducing spatial complexity to (HxW)x(H+W-1), as shown in the figure below: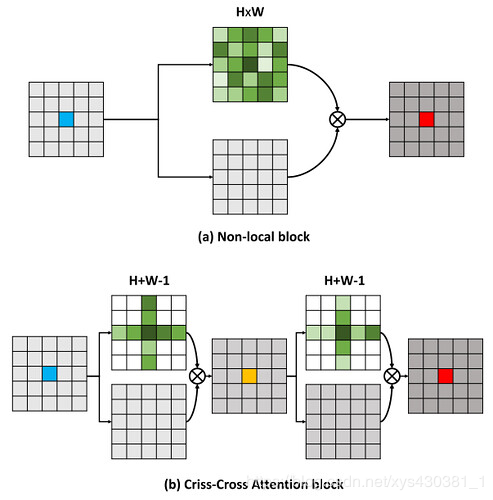 The overall network architecture is the same as DANet, but the attention module differs, as shown in the following figure: when calculating the matrix multiplication, each pixel only extracts the corresponding pixels in the feature map at the cross position for dot product, calculating similarity.
The overall network architecture is the same as DANet, but the attention module differs, as shown in the following figure: when calculating the matrix multiplication, each pixel only extracts the corresponding pixels in the feature map at the cross position for dot product, calculating similarity.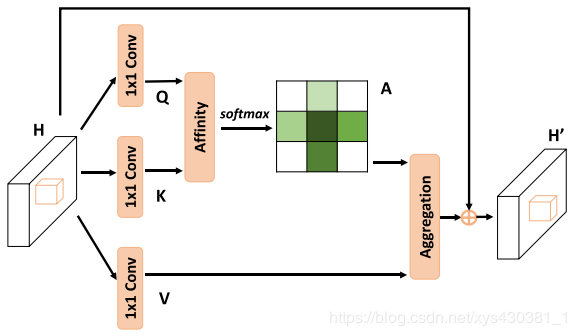 The attention map obtained from this attention calculation is shown in the figure below R1, where each element only has similarity with the cross, and through two rounds of this calculation, each element will obtain the similarity of the entire image, as shown in R2.
The attention map obtained from this attention calculation is shown in the figure below R1, where each element only has similarity with the cross, and through two rounds of this calculation, each element will obtain the similarity of the entire image, as shown in R2. The reason for obtaining this result is shown in the figure below: after one round of calculation, each pixel can obtain the similarity in its cross, while pixels in different columns and rows (not in its cross) have no similarity, but these pixels in different rows and columns also perform similarity calculations, calculating the similarity in their crosses, thus the two crosses must intersect, during the second attention calculation, through the intersection point, it is equivalent to indirectly calculating the similarity between these two different column and row pixels.
The reason for obtaining this result is shown in the figure below: after one round of calculation, each pixel can obtain the similarity in its cross, while pixels in different columns and rows (not in its cross) have no similarity, but these pixels in different rows and columns also perform similarity calculations, calculating the similarity in their crosses, thus the two crosses must intersect, during the second attention calculation, through the intersection point, it is equivalent to indirectly calculating the similarity between these two different column and row pixels.
The experimental results have reached SOTA levels, but the accuracy of methods that do not calculate attention for all pixels is higher.
OCNet
OCNet: Object Context Network for Scene Parsing (Microsoft Research) paper analysis https://blog.csdn.net/mieleizhi0522/article/details/84873101 Image semantic segmentation (13) – OCNet: Target semantic network for scene parsing https://blog.csdn.net/kevin_zhao_zl/article/details/88732455
The abstract of the paper focuses on the semantic aggregation strategy in semantic segmentation, that is, instead of predicting pixel by pixel, it clusters similar pixels together for semantic segmentation, thus proposing a target semantic pooling strategy, which obtains the label of a certain pixel belonging to that object by utilizing the information of pixels belonging to the same object, where the pixel set is called the target semantics. The specific implementation is influenced by self-attention mechanisms and includes two steps: 1) Calculate the similarity between a single pixel and all pixels to obtain the target semantics and the mapping of each pixel; 2) Obtain the label of the target pixel. The results are more accurate than existing semantic aggregation strategies such as PPM and ASPP that do not distinguish between individual pixels and target semantics.
It must be said that this paper collides with DANet, and the core content is the same.
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
GCNet network structure integrates non-local network and Squeeze-Excitation networks. We know that non-local networks (NLNet) can capture long-distance dependencies. It can be found that the network structure of NLNet uses self-attention mechanisms to model pixel relationships. **In this paper, the global context of non-local networks is almost the same in different positions, indicating that it learns global context without position dependence, thus leading to a large amount of computational waste. The author here proposes a simplified model to obtain global context information.** The modeling method used is query-independent (which can be understood as no query dependence). At the same time, this simplified structure can be shared with the SENet network structure. Therefore, the author combines these three methods to generate a global context (GC) block.
Attention-Augmented Convolution
A dialogue between the new and old generations of neural networks (with implementation) https://mp.weixin.qq.com/s/z2scG7VvguXXZVpRhyLpxw
PyTorch implementation address: https://github.com/leaderj1001/Attention-Augmented-Conv2d
PS: The inspiration is to add multiple attention heads on the basis of the convolution operator (each self-attention head is a no-local block), and then concatenate these heads together.
Mechanism
Convolution operations have a significant flaw in that they only work on local neighbors, thus missing global information. On the other hand, self-attention is a recent advancement in capturing long-range interactions but is still primarily applied in sequence modeling and generative modeling tasks. In this paper, we investigate the problem of using self-attention (as a replacement for convolution) for discriminative visual tasks. We propose a novel two-dimensional relative self-attention mechanism, and research shows that this is sufficient to replace convolution as a standalone primitive in image classification tasks. In contrast experiments, we found that the best results are obtained when combining convolution and self-attention. Thus, we propose using this self-attention mechanism to enhance the convolution operator, specifically by concatenating the convolution feature map with a set of feature maps generated through self-attention.


A single attention head
Given an input tensor of shape (H, W, F_in), we flatten it into a matrix and perform multi-head attention as proposed in the Transformer architecture. The output of a single head h’s self-attention mechanism is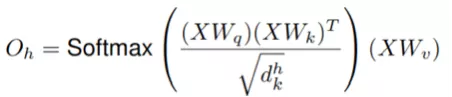
Where, is a learnable linear transformation that maps input X to query Q, key K (xys: when performing self-correlation via matrix multiplication, one is called query, the other is called key) and value V. The outputs of all heads can be concatenated:
We conducted extensive experiments using different scales and types of models (including ResNet and a current best mobile-restricted network), and the results show that attention augmentation can achieve stable improvements in ImageNet image classification and COCO object detection tasks, while ensuring that the number of parameters remains roughly the same. Notably, our method achieved a top-1 accuracy on ImageNet that is 1.3% better than the ResNet50 baseline, and our method also exceeded the RetinaNet baseline by 1.4 mAP on COCO object detection. Attention augmentation requires very little computational burden to achieve systematic improvements and clearly outperforms popular Squeeze-and-Excitation channel attention methods in all experiments. An astonishing result from the experiments is that the fully self-attention model (a special case of attention augmentation) performed only slightly worse than the corresponding fully convolutional model, indicating that self-attention itself is a powerful basic method for image classification.
PAN: Pyramid Attention Network for Semantic Segmentation (Layer Domain)—CVPR2018
Highlight 1: The paper combines the attention mechanism with a pyramid structure as a highlight, allowing for the extraction of relatively precise dense features from lower layers based on high-level semantic guidance, replacing the complex dilated convolutions and multiple encoder-decoder operations in other methods, breaking away from the commonly used U-Net structure. Highlight 2: A global pooling operation is employed for weighting the lower-level features, playing a role in feature selection.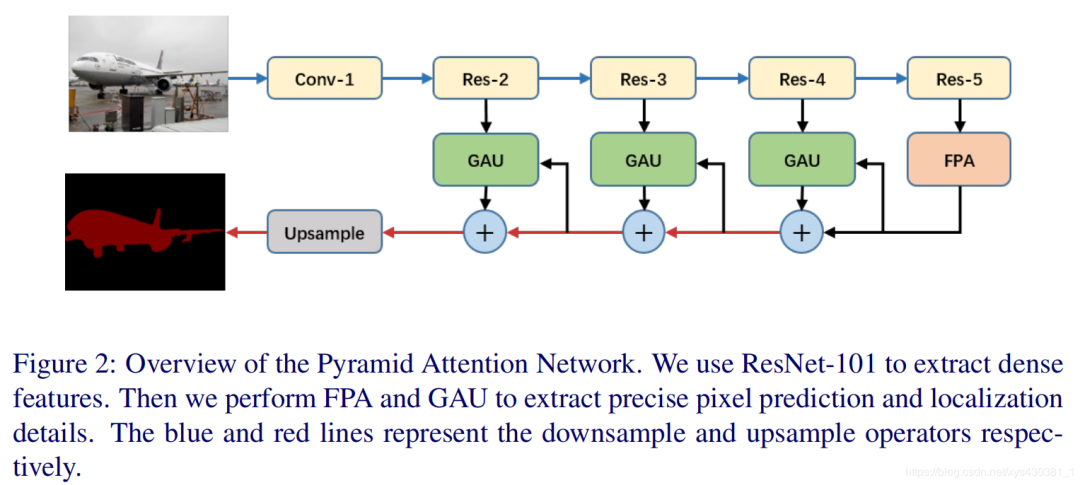 Module 1: FPA (Feature Pyramid Attention)
Module 1: FPA (Feature Pyramid Attention)
-
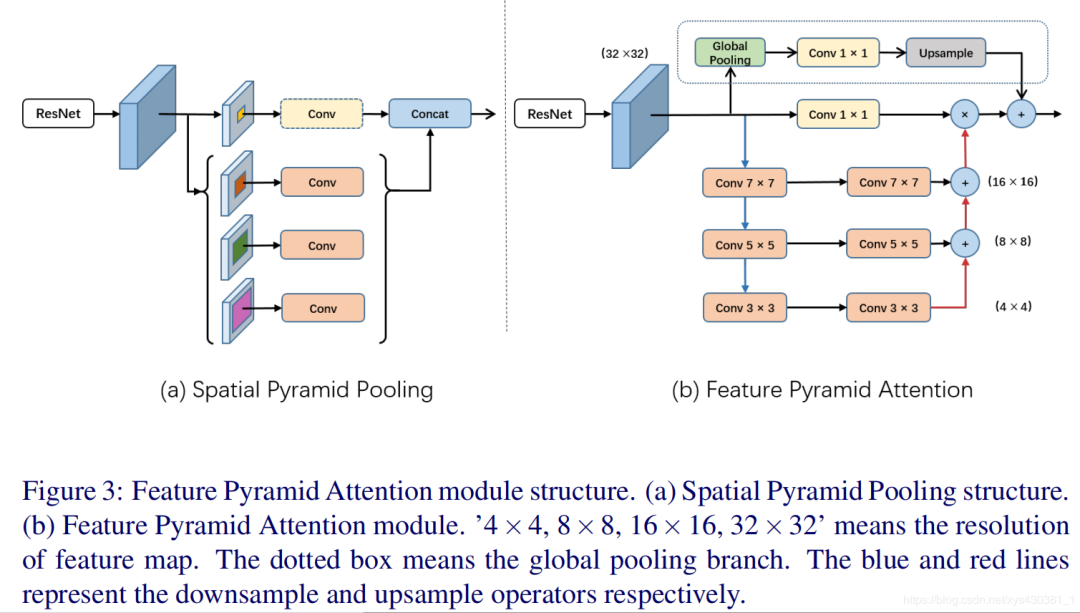
Problem Solved: Different scale sizes of images and different sizes of objects pose difficulties for object segmentation. -
Existing Methods: Similar to PSPNet and DeepLab, spatial pyramid pooling is used to achieve different scales and multi-dilated pyramid pooling ASPP structure, Problem 1: Pooling easily loses local information, Problem 2: ASPP, being a sparse operation, causes checkerboard artifacts, Problem 3: Simply concatenating multiple scales lacks contextual information, leading to suboptimal performance (the diagram below illustrates existing methods), this part mainly deals with operations on high-level features. -
Proposed Solution: As shown in the right figure, after extracting high-level features, no pooling operation is performed; instead, three continuous convolutions achieve higher-level semantics. We know that higher-level semantics will be closer to ground truth, focusing on some object information, so higher-level semantics are used as guidance for attention, and a 1×1 convolution is performed without changing the size to multiply, thus strengthening the weights of the areas containing object information, resulting in outputs with attention, while the pyramid convolution structure uses different sized convolution kernels, representing different receptive fields, thus solving the problem of different objects at different scales.
 Module 2:
Module 2:
-
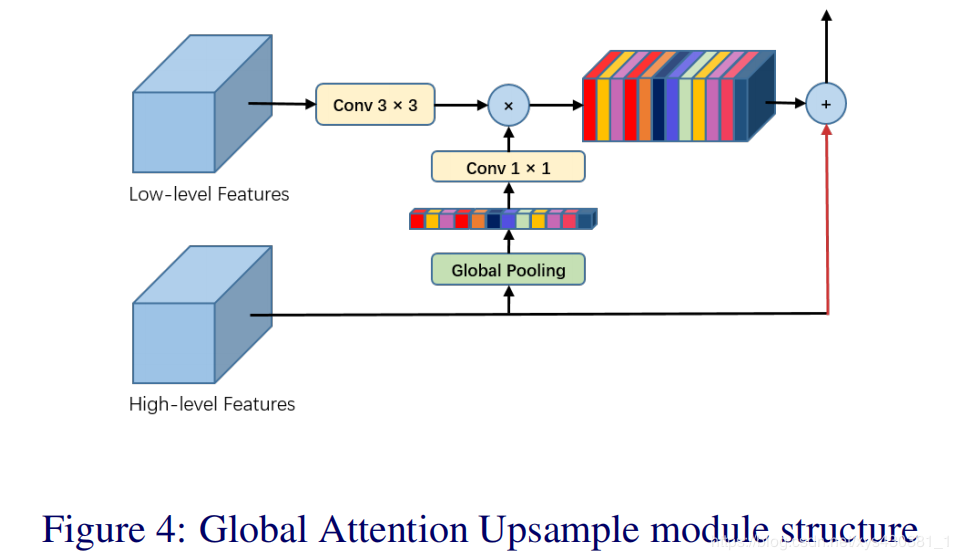
Problem Solved: High-level features can often achieve effective classification, but it is difficult to reconstruct the original image’s resolution or make fine predictions. -
Existing Methods: Similar to SegNet, Refinenet, and Tiramisu structures, etc., all adopt U-Net structures, using decoder layers or transposed convolutions to accumulate bottom-up features layer by layer to recover image details. The paper mentions that while this can achieve a combination of bottom-level and high-level features and image reconstruction, it incurs a computation burden. -
Proposed Solution: As shown in the figure below, the decoder structure is discarded, and the original form directly uses the bottom-level features combined with the high-level features obtained from FPA, but when skipping the bottom-level features, the paper sets corresponding weights guided by the high-level features, ensuring consistency between the weights of bottom-level and high-level features. The high-level features use Global Pooling to obtain weights, while the bottom-level features go through a convolution layer to achieve the same number of maps as the high-level features, and then the two are multiplied and added together. This reduces the complexity of the decoder while also providing a new form of high-bottom fusion. Specifically: -
We perform a 3×3 convolution operation on the low-level features to reduce the number of channels in the CNN feature map. -
The global context information generated from high-level features goes through 1×1 convolution, batch normalization, and non-linear transformation operations, and then is multiplied with low-level features. -
Finally, high-level features are added to the weighted low-level features and undergo a gradual upsampling process. -
Our GAU module can not only adapt more effectively to feature mapping at different scales but also provide guidance information for low-level feature mapping in a simple manner.
Multi-Context Attention for Human Pose Estimation
Tell Me Where to Look: Guided Attention Inference Network
Hard Attention
A study on guiding the learning of visual question answering tasks by introducing hard attention mechanisms
Soft attention mechanisms have achieved widespread application and success in the field of computer vision. However, we find that research on hard attention mechanisms in computer vision tasks is still relatively sparse. Hard attention mechanisms can select important features from input information, thus regarded as a more efficient and direct method than soft attention mechanisms. In this article, we will introduce a study on guiding the learning of visual question answering tasks by introducing hard attention mechanisms. Additionally, combining L2 regularization to filter feature vectors can efficiently promote the filtering process and achieve better overall performance without a dedicated learning process.
1. Diversified visual attention networks for fine-grained object classification—2016
2. Deep networks with internal selective attention through feedback connections (Channel Domain)—NIPS 2014
Proposed a Deep Attention Selective Network (dasNet). After training is complete, attention is dynamically adjusted through reinforcement learning (Separable Natural Evolution Strategies). Specifically, the attention adjusts the weights of each conv filter (similar to SENet, both are channel dimensions). The policy is a neural network, and the RL part of the algorithm is as follows: Each iteration in the while loop represents one SNES iteration, M represents the trained CNN, u and Sigma are the hyperparameters corresponding to the policy distribution, p is the sampled p policy parameters, and n is the randomly selected n images.
Each iteration in the while loop represents one SNES iteration, M represents the trained CNN, u and Sigma are the hyperparameters corresponding to the policy distribution, p is the sampled p policy parameters, and n is the randomly selected n images.
3. Fully Convolutional Attention Networks for Fine-Grained Recognition
This paper utilizes a reinforcement learning-based visual attention model to simulate the learning of locating object parts and classifying objects within scenes. This framework simulates the recognition process of the human visual system by learning a task-driven strategy, going through a series of glimpses to locate parts of objects. So, what is a glimpse here? Each glimpse corresponds to a part of an object. The original image and the previous glimpse’s position are used as input, with the next glimpse position as output, serving as the next object’s part. Each glimpse’s position is treated as an action, and the image and previous glimpse’s position serve as the state, with rewards measuring classification accuracy. This method can simultaneously locate multiple parts, while previous methods could only locate one part at a time.
4. Temporal Attention (RNN)
This concept is quite broad, as computer vision only recognizes single images and does not inherently have a temporal dimension. However, this article proposes a model based on Recurrent Neural Networks (RNN) with attention mechanisms for recognition.
RNN models are suitable for scenarios where data has temporal characteristics, such as using RNN to generate attention mechanisms that perform well in natural language processing tasks. This is because natural language processing involves text analysis, and the generation of text has a temporal dependency, such as one word following another, which indicates a temporal dependency.
However, image data itself does not have inherent temporal characteristics; a single image is often a sample at a single point in time. But in video data, RNNs serve as a good data model, thus enabling the use of RNN to generate recognition attention.
This model is specifically referred to as temporal attention, as it adds a new temporal dimension to the previously introduced spatial, channel, and mixed domains. The generation of this dimension is based on the temporal characteristics of sampling points.
In the Recurrent Attention Model, attention mechanisms are viewed as sampling a point in a region of an image, where this sampling point is the point of attention. In this model, the attention is no longer a differentiable attention information, thus it is also a hard attention (hard attention) model. The training of this model requires reinforcement learning, which takes longer.
This model requires understanding not so much the RNN attention model, as this model is explained in more detail in natural language processing, but rather how this model converts image information into temporal sampling signals:
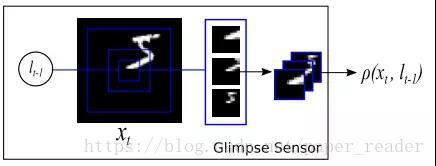 This is the key point in the model, called Glimpse Sensor, which I translate as a scanner. The key point of this sensor is to first determine the points (pixels) in the image that need attention, at which point this sensor begins to collect three types of information, all of the same amount: one is very detailed (the innermost frame) information, one is medium local information, and one is rough thumbnail information.
This is the key point in the model, called Glimpse Sensor, which I translate as a scanner. The key point of this sensor is to first determine the points (pixels) in the image that need attention, at which point this sensor begins to collect three types of information, all of the same amount: one is very detailed (the innermost frame) information, one is medium local information, and one is rough thumbnail information.
These three sampled information are generated in the sampled image, and at the next moment, as t increases, the sampling position will change again. As for how l changes with t, this is what needs to be trained using reinforcement learning.
Self-Attention
Applications of self-attention mechanisms in computer vision https://cloud.tencent.com/developer/news/374449 Using Attention to Explore CV, an Overview of Self-Attention Semantic Segmentation Progress https://mp.weixin.qq.com/s/09_rc9J-4cEs7GrYQaL16Q
Self-attention mechanisms are improvements to attention mechanisms that reduce dependence on external information and are better at capturing internal correlations of data or features.
In neural networks, we know that convolutional layers obtain output features through the linear combination of convolution kernels and original features. Since convolution kernels are usually local, to increase the receptive field, convolutional layers are often stacked, but this approach is not efficient. At the same time, many tasks in computer vision are affected by insufficient semantic information, which impacts the final performance. Self-attention mechanisms capture global information to obtain a larger receptive field and contextual information.
Self-attention mechanisms (self-attention) have made significant progress in sequence models; on the other hand, contextual information is crucial for many visual tasks, such as semantic segmentation and object detection. Self-attention mechanisms provide an effective modeling approach for capturing global contextual information through the triplet (key, query, value). Next, I will first introduce several corresponding works, then analyze their respective advantages and disadvantages and improvement directions.
Related Works
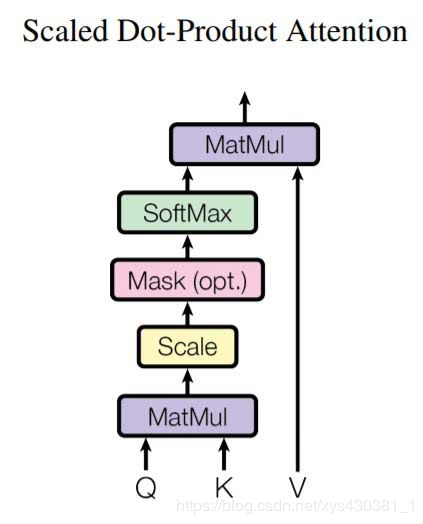
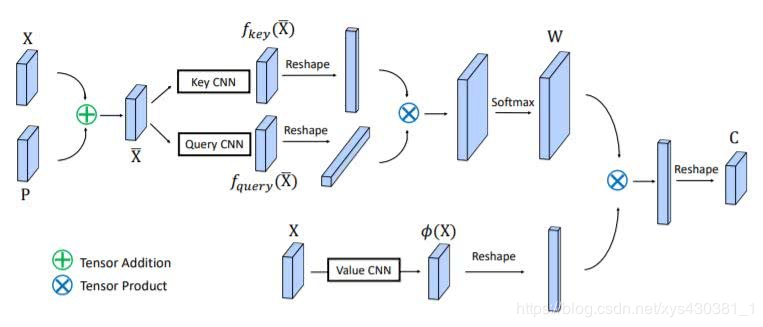
Attention is all you need is the first work to propose using self-attention mechanisms to replace recurrent neural networks in sequence models, achieving great success. One important module is the scaled dot-product attention module. The article proposes a modeling approach to capture long-distance dependencies through the triplet (key, query, value), as shown in the figure below, where the key and query obtain the corresponding attention weights through dot multiplication, and finally, the obtained weights are dot-multiplied with the value to get the final output.
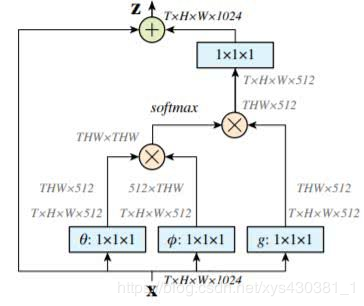
Non-local neural network inherits the modeling approach of the triplet (key, query, value) and proposes an efficient non-local module. As shown in the figure below, after adding the non-local module to the Resnet network, both object detection and instance segmentation performance improved by over one point (mAP), indicating the importance of contextual information modeling.
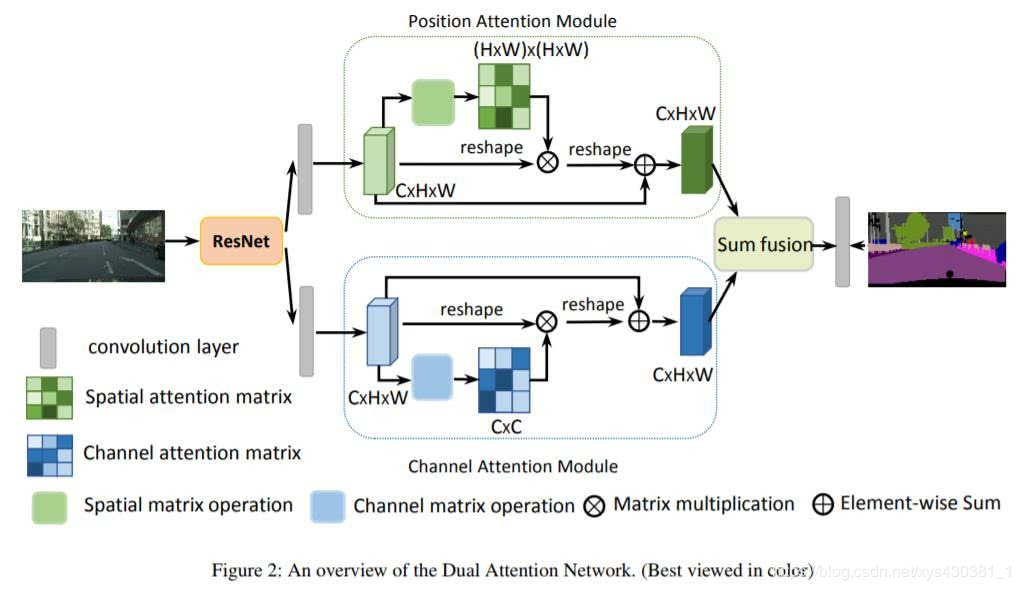
Danet is a work from the Chinese Academy of Sciences Automation. Its core idea is to supervise semantic segmentation tasks through contextual information. The authors use two forms of attention, as shown in the figure below, which are spatial and channel attention, and then perform feature fusion, finally connecting to the semantic segmentation head network. The idea is simple and has achieved good results.
Ocnet is a work from Microsoft Research Asia. It also adopts the triplet (key, query, value) to better supervise semantic segmentation tasks by capturing global contextual information. Unlike Danet, it only uses spatial information. It also achieves good results.
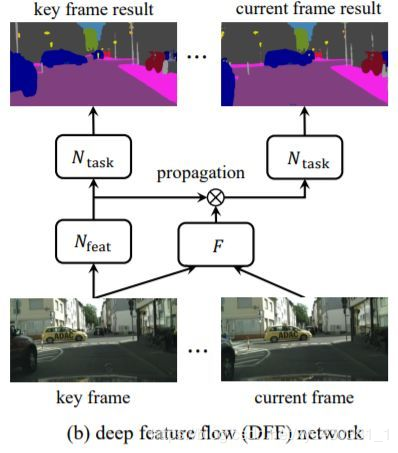
DFF is a work from the visual computing group of Microsoft Research Asia. It models the motion information between different frames of video through optical flow, proposing a very elegant video detection framework DFF. One important operation is warp, which aligns points between each other. Since then, many works on video detection have emerged, such as FGFA, Towards High Performance, etc., most of which are based on the warp feature alignment operation. Generally, we assume that the motion information of flow will not be too far, which easily inspires us to find the corresponding motion feature points through the neighborhood of each point. The specific approach will not be introduced here; you are welcome to think about it (related operations and self-attention mechanisms).
Disadvantages and Improvement Strategies of Self-Attention
Previously, I introduced the uses of self-attention mechanisms. Next, I will analyze its disadvantages and corresponding improvement strategies. Since every point needs to capture global contextual information, this leads to high computational complexity and memory capacity of the self-attention mechanism module. If we can know some prior information, such as the aforementioned feature alignment usually being within a certain neighborhood, we can perform operations limited to a certain neighborhood. Additionally, how to achieve efficient sparsity and the relationship with graph convolution are open questions that welcome active thinking.
Next, I will introduce some other improvement strategies. Senet inspires us that information on the channel is very important, as shown in the figure below.
CBAW proposed a module combining spatial and channel information, achieving good results in various tasks.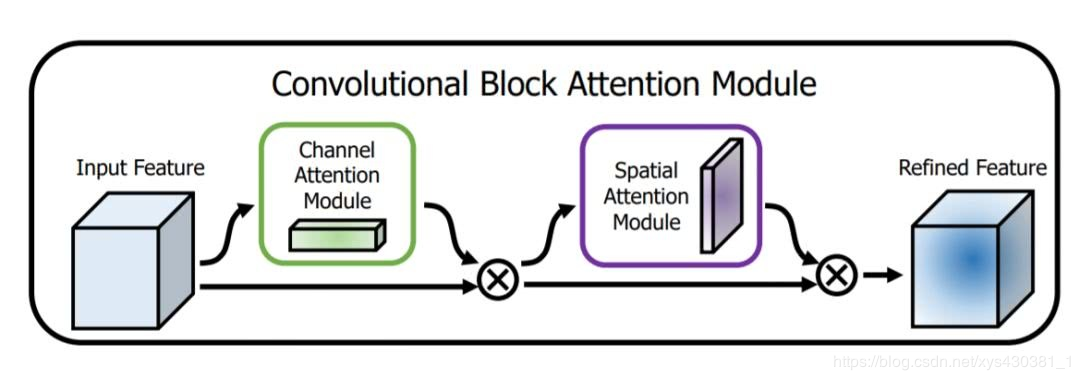
Finally, I will introduce a work from Baidu IDL that combines channel as spatial modeling. Essentially, this directly incorporates channel information during the reshape of (key, query, value) triplet, but it brings a significant problem of greatly increasing computational complexity. We know that grouped convolutions are an effective way to reduce the number of parameters, and this method also adopts a grouping approach. However, even with grouping, it still cannot fundamentally solve the problem of high computational complexity and parameter count. The authors cleverly adjusted the order of calculating key, query, and value using Taylor series expansion, effectively reducing the corresponding computational complexity. The table below shows the optimized computational load and complexity analysis, and the figure shows the overall framework of the CGNL module.
Summary of Self-Attention
As an effective way to model context, self-attention mechanisms have achieved good results in many visual tasks. At the same time, the drawbacks of this modeling approach are also evident: one is that it does not consider information on the channel, and the second is that computational complexity remains high. Corresponding improvements should focus on how to effectively combine spatial and channel information, and how to capture information sparsely. The benefits of sparsity are that it can be more robust while maintaining lower computational load and memory capacity. Lastly, the relationship between self-attention mechanisms and graph convolution, as well as a deeper understanding of self-attention mechanisms, are important directions for future research.
Recommended Articles on Attention Mechanisms
Microsoft Research Asia: An Empirical Study of Spatial Attention Mechanisms in Deep Networks http://www.myzaker.com/article/5cb40c5a8e9f09734a62fab1/
Paper: An Empirical Study of Spatial Attention Mechanisms in Deep Networks https://arxiv.org/abs/1904.05873
Paper Reading: Attention Mechanisms in Image Classification https://blog.csdn.net/Wayne2019/article/details/78488142 Introduces Spatial Transformer Networks, Residual Attention Network, Two-level Attention, SENet, Deep Attention Selective Network
Visual Attention in Computer Vision https://blog.csdn.net/paper_reader/article/details/81082351
Quick Understanding of the Application of Attention Mechanisms in Image Processing https://blog.csdn.net/weixin_41977512/article/details/83243160 Mainly explains the 2017 CPVR article: Residual Attention Network for Image Classification
Summary of Articles on Attention Mechanisms https://blog.csdn.net/humanpose/article/details/85332392
Latest Progress of Self-Attention Mechanisms in Computer Vision https://blog.csdn.net/SIGAI_CSDN/article/details/82664511
ECCV2018 – Attention Model CBAM https://blog.csdn.net/qq_14845119/article/details/81393127
[Paper Reproduction] CBAM: Convolutional Block Attention Module https://blog.csdn.net/u013738531/article/details/82731257
BAM: Bottleneck Attention Module Algorithm Notes https://blog.csdn.net/qq_32768091/article/details/86612132
Fine-grained Image Classification Based on Attention Mechanisms https://blog.csdn.net/step_forward_ml/article/details/80630682 Discusses RACNN
Additionally, there are methods such as MACNN.